#Python算法实现-贝叶斯模型-贝叶斯回归
之前,我们留了个问题:“我的回复时间受聊天的对象的影响吗?”我们针对每个对话的人都进行了模型参数估计。但是有时候我们想了解更多的影响因素,比如:星期几,时刻等。可以运用 GLM(通用线性模型)更好地了解这些因素的影响。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc3 as pm
import scipy
import scipy.stats as stats
import seaborn.apionly as sns
import statsmodels.api as sm
import theano.tensor as tt
from sklearn import preprocessing
%matplotlib inline
plt.style.use('bmh')
colors = ['#348ABD', '#A60628', '#7A68A6', '#467821', '#D55E00',
'#CC79A7', '#56B4E9', '#009E73', '#F0E442', '#0072B2']
messages = pd.read_csv('data/hangout_chat_data.csv')
线性回归
当响应y是 −∞ 到 ∞ 上的连续变量时,可以考虑使用线性回归,表示为:
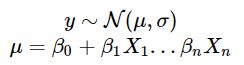
解读为:响应y通常服从均值为 μ,标准差为 σ 的正态分布,μ 描述为一组解释变量 Xβ 的线性函数,零线截距为 β0.
连接函数
在不是对 −∞ 到 ∞上连续变量进行建模的场合,你需要使用连接函数来转换响应域。对于泊松分布,一种权威的连接函数是 log 连接函数,可以表示为:
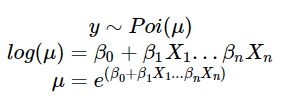
这被认为是一个固定效用模型,对系数 β 的估计是基于整个对话人群,而不是基于单个的人估计独自的参数(如第三节中的合并和局部融合模型)。
固定效用泊松回归
为了用PyMC3建立泊松回归,我们需要对 μ 使用log连接函数。PyMC3中的潜在数据模型使用了theano 库,因此需要使用下面的 theano 张量方法 theano.tensor.exp()。
X = messages[['is_weekend','day_of_week','message_length','num_participants']].values
_, num_X = X.shape
with pm.Model() as model:
intercept = pm.Normal('intercept', mu=0, sd=100)
beta_message_length = pm.Normal('beta_message_length', mu=0, sd=100)
beta_is_weekend = pm.Normal('beta_is_weekend', mu=0, sd=100)
beta_num_participants = pm.Normal('beta_num_participants', mu=0, sd=100)
mu = tt.exp(intercept
+ beta_message_length*messages.message_length
+ beta_is_weekend*messages.is_weekend
+ beta_num_participants*messages.num_participants)
y_est = pm.Poisson('y_est', mu=mu, observed=messages['time_delay_seconds'].values)
start = pm.find_MAP()
step = pm.Metropolis()
trace = pm.sample(200000, step, start=start, progressbar=True)
[-----------------100%-----------------] 200000 of 200000 complete in 137.5 sec
_ = pm.traceplot(trace)

从上面的结果中可以看到,零线截距 β0 估值在 2.4 到 2.8,那么这说明什么呢?
不幸的是,解释泊松回归的参数比简单线性回归(y=β X)更费劲,在这个线性回归中,我们可以说 x 每增加一个单位,y 增加 β 个单位。但是,泊松回归中我们需要考虑连接函数。following cross validated post详细推导了下面的公式。
对泊松模型,x 变化一个单位,相应地 y 变化 y( e^β – 1)
从中得出的主要结论是,x 变化的影响取决于当前的 y 值,不像简单线性回归,x 同样的变化却引起 y 的不一致变化。
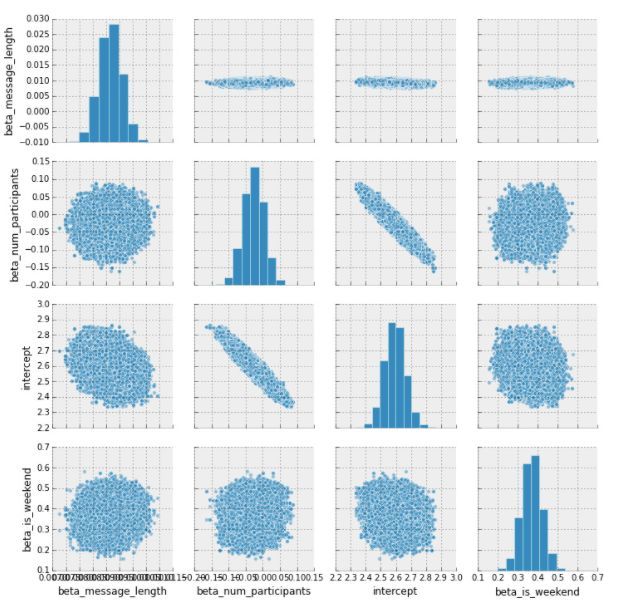
边缘密度图和二元联合密度图
下图显示了边缘密度图(对角线上)和二元联合密度图(上下窗格)。这个图对于理解协变量的相互作用很有用,在上例中,可以看到,若参与的人数增加,则零线截距下降。
_ = sns.pairplot(pm.trace_to_dataframe(trace[20000:]), plot_kws={'alpha':.5})
混合效用泊松回归
对上面的模型进行小的扩展,引入一个随机截距参数,这样可以针对每个人估计一个基线参数 β0,而其他参数则针对整个群体进行估计。对于每个人i的每条消息j,可以表示为:
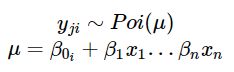
通过对每个人i引入这个随机效用参数 β0,可以使模型针对每个人建立不同的基线,同时对整个群体估计协变量的效用。
# Convert categorical variables to integer
le = preprocessing.LabelEncoder()
participants_idx = le.fit_transform(messages['prev_sender'])
participants = le.classes_
n_participants = len(participants)
with pm.Model() as model:
intercept = pm.Normal('intercept', mu=0, sd=100, shape=n_participants)
slope_message_length = pm.Normal('slope_message_length', mu=0, sd=100)
slope_is_weekend = pm.Normal('slope_is_weekend', mu=0, sd=100)
slope_num_participants = pm.Normal('slope_num_participants', mu=0, sd=100)
mu = tt.exp(intercept[participants_idx]
+ slope_message_length*messages.message_length
+ slope_is_weekend*messages.is_weekend
+ slope_num_participants*messages.num_participants)
y_est = pm.Poisson('y_est', mu=mu, observed=messages['time_delay_seconds'].values)
start = pm.find_MAP()
step = pm.Metropolis()
trace = pm.sample(200000, step, start=start, progressbar=True)
[-----------------100%-----------------] 200000 of 200000 complete in 207.3 sec
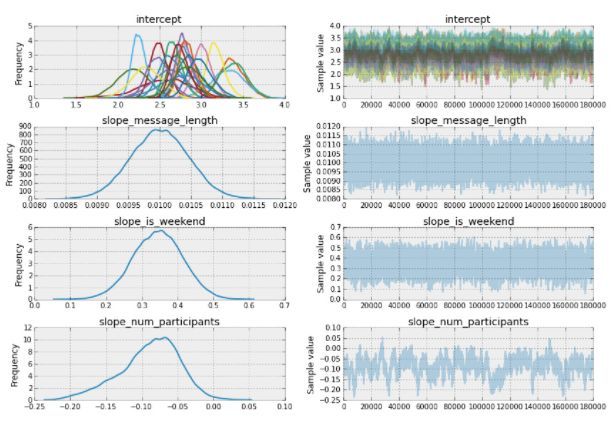
上面结果的截距很有趣:
每个人有不同的基本回复速率(正如第3节中两个模型展示的那样)
长消息需要较长时间编写,通常需要较长回复时间
如果你周末给我发消息,你很可能得到较慢的回复
我倾向于在群组聊天中回复更快
经过对每个协变量的效用进行计算,模型估计出参数 β0 的值如下。
_ = plt.figure(figsize=(5, 6))
_ = pm.forestplot(trace[20000:], varnames=['intercept'], ylabels=participants)
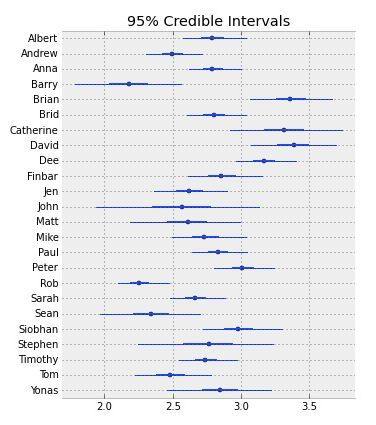
—End—