R语言 判别分析:线性判别、K最邻近、有权重的K最邻近、朴素贝叶斯
关注微信公共号:小程在线
关注CSDN博客:程志伟的博客
class包:提供Knn()函数
kknn包:提供kknn()函数及miete数据集(房租信息)
kknn函数:实现有权重的K最近邻
knn函数:实现K最近邻算法
klaR包:提供NavieBayes()函数
lda函数:线性判别
MASS包:提供lda()和qda()函数
NavieBayes()函数:实现朴素贝叶斯算法
#####################判别分析#############################
> #读取数据
> library(kknn)
> data("miete")
> head(miete)
nm wfl bj bad0 zh ww0 badkach fenster kueche mvdauer bjkat
1 693.29 50 1971.5 0 1 0 0 0 0 2 4
2 736.60 70 1971.5 0 1 0 0 0 0 26 4
3 732.23 50 1971.5 0 1 0 0 0 0 1 4
4 1295.14 55 1893.0 0 1 0 0 0 0 0 1
5 394.97 46 1957.0 0 0 1 0 0 0 27 3
6 1285.64 94 1971.5 0 1 0 1 0 0 2 4
wflkat nmqm rooms nmkat adr wohn
1 1 13.865800 1 3 2 2
2 2 10.522857 3 3 2 2
3 1 14.644600 1 3 2 2
4 2 23.548000 3 5 2 2
5 1 8.586304 3 1 2 2
6 3 13.677021 4 5 2 2
> summary(miete)
nm wfl bj bad0 zh
Min. : 127.1 Min. : 20.00 Min. :1800 0:1051 0:202
1st Qu.: 543.6 1st Qu.: 50.25 1st Qu.:1934 1: 31 1:880
Median : 746.0 Median : 67.00 Median :1957
Mean : 830.3 Mean : 69.13 Mean :1947
3rd Qu.:1030.0 3rd Qu.: 84.00 3rd Qu.:1972
Max. :3130.0 Max. :250.00 Max. :1992
ww0 badkach fenster kueche mvdauer bjkat wflkat
0:1022 0:446 0:1024 0:980 Min. : 0.00 1:218 1:271
1: 60 1:636 1: 58 1:102 1st Qu.: 2.00 2:154 2:513
Median : 6.00 3:341 3:298
Mean :10.63 4:226
3rd Qu.:17.00 5: 79
Max. :82.00 6: 64
nmqm rooms nmkat adr wohn
Min. : 1.573 Min. :1.000 1:219 1: 25 1: 90
1st Qu.: 8.864 1st Qu.:2.000 2:230 2:1035 2:673
Median :12.041 Median :3.000 3:210 3: 22 3:319
Mean :12.647 Mean :2.635 4:208
3rd Qu.:16.135 3rd Qu.:3.000 5:215
Max. :35.245 Max. :9.000
> #对数据进行分层抽样
> library(sampling)
> n <- round(2/3*nrow(miete)/5)
> n
[1] 144
> sub_train <- strata(miete,stratanames = 'nmkat',size = rep(n,5),method = 'srswor')
> #显示nmkat取值、在数据集中的序号、别抽到的概率、所在层
> head(sub_train)
nmkat ID_unit Prob Stratum
1 3 1 0.6857143 1
3 3 3 0.6857143 1
8 3 8 0.6857143 1
20 3 20 0.6857143 1
27 3 27 0.6857143 1
28 3 28 0.6857143 1
> tail(sub_train)
nmkat ID_unit Prob Stratum
1058 2 1058 0.626087 5
1061 2 1061 0.626087 5
1062 2 1062 0.626087 5
1064 2 1064 0.626087 5
1067 2 1067 0.626087 5
1080 2 1080 0.626087 5
> #将下面代码就行修改
> #> data_train <- getdata(miete[,c(-1,-3,-12)],sub_train$ID_unit)
> #> data_test <- getdata(miete[,c(-1,-3,-12)],-sub_train$ID_unit)
> #构建训练集和测试集
> # 总的id
> d1<-as.factor(row.names(miete))
> # 训练集的id
> d2<-as.factor(sub_train$ID_unit)
> # 测试集的id
> d3<-as.factor(setdiff(d1,d2))
> # 训练集操作
> t1<-miete[d2,]
> data_train<-t1[,c(-1,-3,-12)]
> # 测试集操作
> t2<-miete[d3,]
> data_test<-t2[,c(-1,-3,-12)]
> dim(data_train);dim(data_test)
[1] 720 14
[1] 362 14
> head(data_test)
wfl bad0 zh ww0 badkach fenster kueche mvdauer bjkat nmqm rooms
70 42 0 1 0 0 0 0 6 4 18.270238 2
49 84 0 1 0 1 0 0 12 4 13.004643 4
53 95 0 1 0 0 0 0 40 2 7.581579 4
79 77 0 1 0 1 0 0 3 4 5.006623 3
88 77 0 1 0 0 0 0 1 5 9.405714 3
100 56 0 1 1 0 0 0 35 3 6.822143 2
nmkat adr wohn
70 3 2 3
49 4 2 2
53 3 2 3
79 1 2 2
88 3 2 2
100 1 2 2
> ############################1.线性判别##########################
> library(MASS)
> fit_lda1 <- lda(nmkat ~.,data_train)
> names(fit_lda1)
[1] "prior" "counts" "means" "scaling" "lev" "svd"
[7] "N" "call" "terms" "xlevels"
> #各类别的先验概率
> fit_lda1$prior
1 2 3 4 5
0.2166667 0.2069444 0.1944444 0.1916667 0.1902778
> #各类别的样本量
> fit_lda1$counts
1 2 3 4 5
156 149 140 138 137
> #各变量的均值
> fit_lda1$means
wfl bad01 zh1 ww01 badkach1 fenster1
1 55.64744 0.076923077 0.5769231 0.16025641 0.4038462 0.04487179
2 60.64430 0.020134228 0.8322148 0.05369128 0.5503356 0.05369128
3 66.70000 0.021428571 0.8214286 0.05000000 0.4857143 0.05714286
4 73.74638 0.007246377 0.8913043 0.05072464 0.6956522 0.03623188
5 91.87591 0.007299270 0.9489051 0.00729927 0.7664234 0.03649635
kueche1 mvdauer bjkat.L bjkat.Q bjkat.C bjkat^4
1 0.03846154 15.666667 -0.23598103 -0.11330544 0.053512738 0.15748520
2 0.06711409 11.234899 -0.09545786 -0.18380097 -0.029514096 0.19912893
3 0.05714286 12.350000 -0.11610792 -0.16054602 0.028749445 0.16738427
4 0.11594203 9.507246 -0.05369868 -0.13520021 -0.030786443 0.12187985
5 0.25547445 5.065693 -0.02879018 -0.01831756 0.003808388 0.07862765
bjkat^5 nmqm rooms adr.L adr.Q wohn.L
1 -0.113066295 8.384154 2.141026 -0.009065472 -0.7850929 0.10425292
2 -0.038472894 10.892131 2.422819 -0.014237049 -0.7918373 0.10915071
3 -0.032396955 12.326318 2.592857 -0.025253814 -0.7727557 0.09091373
4 0.001369436 14.434710 2.797101 0.015371887 -0.7898717 0.19983453
5 -0.039083918 17.154980 3.321168 0.015484090 -0.7717979 0.29419771
wohn.Q
1 -0.4003974
2 -0.3972886
3 -0.4315768
4 -0.3816234
5 -0.2532927
> fit_lda1
Call:
lda(nmkat ~ ., data = data_train)
Prior probabilities of groups:
1 2 3 4 5
0.2166667 0.2069444 0.1944444 0.1916667 0.1902778
Group means:
wfl bad01 zh1 ww01 badkach1 fenster1
1 55.64744 0.076923077 0.5769231 0.16025641 0.4038462 0.04487179
2 60.64430 0.020134228 0.8322148 0.05369128 0.5503356 0.05369128
3 66.70000 0.021428571 0.8214286 0.05000000 0.4857143 0.05714286
4 73.74638 0.007246377 0.8913043 0.05072464 0.6956522 0.03623188
5 91.87591 0.007299270 0.9489051 0.00729927 0.7664234 0.03649635
kueche1 mvdauer bjkat.L bjkat.Q bjkat.C bjkat^4
1 0.03846154 15.666667 -0.23598103 -0.11330544 0.053512738 0.15748520
2 0.06711409 11.234899 -0.09545786 -0.18380097 -0.029514096 0.19912893
3 0.05714286 12.350000 -0.11610792 -0.16054602 0.028749445 0.16738427
4 0.11594203 9.507246 -0.05369868 -0.13520021 -0.030786443 0.12187985
5 0.25547445 5.065693 -0.02879018 -0.01831756 0.003808388 0.07862765
bjkat^5 nmqm rooms adr.L adr.Q wohn.L
1 -0.113066295 8.384154 2.141026 -0.009065472 -0.7850929 0.10425292
2 -0.038472894 10.892131 2.422819 -0.014237049 -0.7918373 0.10915071
3 -0.032396955 12.326318 2.592857 -0.025253814 -0.7727557 0.09091373
4 0.001369436 14.434710 2.797101 0.015371887 -0.7898717 0.19983453
5 -0.039083918 17.154980 3.321168 0.015484090 -0.7717979 0.29419771
wohn.Q
1 -0.4003974
2 -0.3972886
3 -0.4315768
4 -0.3816234
5 -0.2532927
Coefficients of linear discriminants:
LD1 LD2 LD3 LD4
wfl 0.060132965 0.026719778 0.01623211 -0.0001588888
bad01 0.183794417 1.618516774 0.19641105 -0.4194358217
zh1 0.144370594 -1.418506813 -0.33062418 -0.4431515370
ww01 -0.312648201 0.378690539 -0.82384090 1.6315813647
badkach1 0.225632434 0.279944241 -1.17357888 0.5486835576
fenster1 0.063422366 -0.430194179 0.53253424 -0.7735389574
kueche1 0.206967799 0.962199352 -0.60661745 -1.3404546843
mvdauer -0.003722578 -0.005581735 0.02749353 0.0443173127
bjkat.L 0.093612418 -0.238045891 -0.34433616 -0.4090478086
bjkat.Q -0.126820269 0.351221286 0.01807868 -0.8727242056
bjkat.C -0.130034438 0.783834929 1.42782762 -0.1273525761
bjkat^4 -0.324588339 -0.230475173 0.17279663 -0.7049687536
bjkat^5 -0.242146129 -0.303624065 0.49681661 0.3164478032
nmqm 0.386251893 -0.011760297 0.08939692 0.1186454076
rooms 0.195274078 -0.601439513 -0.14982530 -0.1564289343
adr.L -1.629909354 0.670104728 -3.79537471 2.5545277034
adr.Q -0.645420248 0.169387746 0.57020529 0.4311319766
wohn.L 0.328225174 0.403076098 -0.43450727 0.2871776246
wohn.Q -0.117194352 0.076668423 -0.28131663 -0.5787510142
Proportion of trace:
LD1 LD2 LD3 LD4
0.9750 0.0145 0.0065 0.0040
> #另一种实现方法
> fit_lda2 <- lda(data_train[,-12],data_train[,12])
> fit_lda2
Call:
lda(data_train[, -12], data_train[, 12])
Prior probabilities of groups:
1 2 3 4 5
0.2166667 0.2069444 0.1944444 0.1916667 0.1902778
Group means:
wfl bad0 zh ww0 badkach fenster kueche
1 55.64744 1.076923 1.576923 1.160256 1.403846 1.044872 1.038462
2 60.64430 1.020134 1.832215 1.053691 1.550336 1.053691 1.067114
3 66.70000 1.021429 1.821429 1.050000 1.485714 1.057143 1.057143
4 73.74638 1.007246 1.891304 1.050725 1.695652 1.036232 1.115942
5 91.87591 1.007299 1.948905 1.007299 1.766423 1.036496 1.255474
mvdauer bjkat nmqm rooms adr wohn
1 15.666667 2.512821 8.384154 2.141026 1.987179 2.147436
2 11.234899 3.100671 10.892131 2.422819 1.979866 2.154362
3 12.350000 3.014286 12.326318 2.592857 1.964286 2.128571
4 9.507246 3.275362 14.434710 2.797101 2.021739 2.282609
5 5.065693 3.379562 17.154980 3.321168 2.021898 2.416058
Coefficients of linear discriminants:
LD1 LD2 LD3 LD4
wfl 0.058274265 0.026581902 -0.02064524 -0.0001174871
bad0 0.137868576 1.650656213 -0.59096909 0.6018053170
zh 0.136047136 -1.526527081 0.48965931 0.3074164084
ww0 -0.305368459 0.495068681 1.15483610 -1.4958478494
badkach 0.219923203 0.414029221 1.33933838 -0.3203832167
fenster 0.050643136 -0.709690537 -0.48756790 0.7037612341
kueche 0.111668906 1.097164642 0.06409716 1.7493134726
mvdauer -0.004541142 -0.006717243 -0.02226311 -0.0533731169
bjkat 0.017078305 -0.116117354 0.09796824 0.0122905946
nmqm 0.379507938 -0.013211688 -0.06893267 -0.1360574504
rooms 0.209607325 -0.610650914 0.21136687 0.1380030913
adr -0.940986465 0.721633927 2.96937918 -1.8682410267
wohn 0.201982053 0.443293384 0.40608410 0.2930551074
Proportion of trace:
LD1 LD2 LD3 LD4
0.9787 0.0131 0.0050 0.0032
> #可视化
> plot(fit_lda1)
> #可以看出1,5比较分散,234混在一起
> plot(fit_lda1,dimen=1)
Error in plot.new() : figure margins too large
> #可以看出1,5比较分散,234混在一起
> plot(fit_lda1,dimen=2)
Warning message:
In doTryCatch(return(expr), name, parentenv, handler) :
display list redraw incomplete
> #进行预测
> pre_lda1 <- predict(fit_lda1,data_test)
> table(pre_lda1$class)
1 2 3 4 5
82 80 59 81 60
> #计算混淆矩阵,正确率为68+45+39+55+53)/362=71.82%
> table(data_test$nmkat,pre_lda1$class)
1 2 3 4 5
1 68 14 1 1 0
2 12 45 8 3 0
3 2 21 39 9 1
4 0 0 11 55 6
5 0 0 0 13 53
> #计算错误率:0.281768
> errol_lda1 <- sum(as.numeric(as.numeric(pre_lda1$class)!=as.numeric(data_test$nmkat)))/nrow(data_test)
> errol_lda1
[1] 0.281768
> #######################2.朴素贝叶斯########################
> #1.公式formula格式
> library(klaR)
> fit_Bayes1 <- NaiveBayes(nmkat ~.,data_train)
> names(fit_Bayes1)
[1] "apriori" "tables" "levels" "call" "x" "usekernel"
[7] "varnames"
> fit_Bayes1$apriori
grouping
1 2 3 4 5
0.2166667 0.2069444 0.1944444 0.1916667 0.1902778
> #通过分析bad0,0表示有浴室,房租差距不大
> #wohn和adr,1表示环境不好,3表示环境好,3随租金呈上升趋势
> fit_Bayes1$tables
$wfl
[,1] [,2]
1 55.64744 24.33842
2 60.64430 20.58472
3 66.70000 20.29449
4 73.74638 23.18226
5 91.87591 31.57751
$bad0
var
grouping 0 1
1 0.923076923 0.076923077
2 0.979865772 0.020134228
3 0.978571429 0.021428571
4 0.992753623 0.007246377
5 0.992700730 0.007299270
......
$rooms
[,1] [,2]
1 2.141026 0.9601661
2 2.422819 1.0791714
3 2.592857 0.8724103
4 2.797101 0.9677985
5 3.321168 1.1176019
$adr
var
grouping 1 2 3
1 0.019230769 0.974358974 0.006410256
2 0.020134228 0.979865772 0.000000000
3 0.035714286 0.964285714 0.000000000
4 0.000000000 0.978260870 0.021739130
5 0.007299270 0.963503650 0.029197080
$wohn
var
grouping 1 2 3
1 0.09615385 0.66025641 0.24358974
2 0.09395973 0.65771812 0.24832215
3 0.09285714 0.68571429 0.22142857
4 0.03623188 0.64492754 0.31884058
5 0.02189781 0.54014599 0.43795620
> fit_Bayes1$levels
[1] "1" "2" "3" "4" "5"
> fit_Bayes1$call
NaiveBayes.default(x = X, grouping = Y)
> fit_Bayes1$varnames
[1] "wfl" "bad0" "zh" "ww0" "badkach" "fenster" "kueche"
[8] "mvdauer" "bjkat" "nmqm" "rooms" "adr" "wohn"
> #2.各类别密度下可视化
> plot(fit_Bayes1,vars = 'wf1',n=50,col=c(1,'darkgrey',1,'darkgrey',1))
> plot(fit_Bayes1,vars = 'mvdauer',n=50,col=c(1,'darkgrey',1,'darkgrey',1))
Hit

> plot(fit_Bayes1,vars = 'nmqm',n=50,col=c(1,'darkgrey',1,'darkgrey',1))
Hit

> #3.默认格式
> fit_Bayes2 <-NaiveBayes(data_train[,-12],data_train[,12])
> #4.对测试集预测
> pre_Bayes1 <- predict(fit_Bayes1,data_test)
There were 50 or more warnings (use warnings() to see the first 50)
> pre_Bayes1
$class
70 49 53 79 88 100 104 107 112 121 144 151 166 185 205 211 214 221 226
4 4 1 2 2 1 1 2 5 1 3 5 4 3 4 1 5 5 1
.....
10 11 12 13 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
5 5 5 2 4 4 3 5 5 3 5 2 1 1 2 4 2 3 1
30
1
Levels: 1 2 3 4 5
$posterior
1 2 3 4 5
70 2.416666e-02 2.273255e-01 2.551058e-01 3.240992e-01 1.693029e-01
....
204 5.656179e-02 4.580094e-01 2.514542e-01 1.954695e-01 3.850509e-02
206 7.575586e-05 2.298567e-03 5.326445e-03 1.455069e-01 8.467923e-01
207 8.560613e-03 1.816113e-01 1.722996e-01 5.692817e-01 6.824674e-02
208 8.306373e-03 1.316462e-01 1.547190e-01 3.276939e-01 3.776345e-01
[ reached getOption("max.print") -- omitted 162 rows ]
> #计算混淆矩阵
> table(data_test$nmkat,pre_Bayes1$class)
1 2 3 4 5
1 54 26 0 0 4
2 11 37 9 5 6
3 11 20 23 12 6
4 5 1 11 35 20
5 0 0 3 10 53
> #计算错误率 [1] 0.441989
> errol_Bayes1 <- sum(as.numeric(as.numeric(pre_Bayes1$class)!=as.numeric(data_test$nmkat)))/nrow(data_test)
> errol_Bayes1
[1] 0.441989
> ###########################3.K最近邻####################
> library(class)
> fit_pre_knn <- knn(data_train[,-12],data_test[,-12],cl=data_train[,12])
> fit_pre_knn
[1] 3 4 3 1 3 1 1 2 2 1 3 5 4 4 4 2 5 3 1 3 2 3 1 1 4 2 1 1 3 1 2 3 2 3 3
[36] 1 5 1 4 1 4 4 4 5 4 5 3 2 2 3 1 1 1 3 2 1 4 3 2 3 5 3 2 5 1 3 1 1 1 1
[71] 5 4 2 3 2 5 4 3 4 2 2 1 3 2 3 2 5 2 3 4 4 2 3 2 2 1 1 4 5 3 1 4 3 5 2
[106] 5 1 1 4 2 3 2 1 1 3 4 5 4 5 3 5 1 4 3 2 3 1 1 5 1 4 5 1 2 3 4 4 5 5 1
[141] 2 5 5 5 1 4 2 3 3 5 2 5 3 4 4 1 1 5 5 4 5 3 1 2 5 4 3 2 3 2 1 1 2 2 2
[176] 4 4 2 3 1 2 2 1 1 5 3 4 5 1 2 4 1 5 4 5 2 2 4 4 5 4 4 1 1 2 2 1 2 2 4
[211] 2 1 4 4 1 4 5 2 4 4 3 4 5 4 2 1 4 4 4 5 2 1 4 4 1 1 3 1 5 3 3 3 5 3 2
[246] 4 3 3 2 4 4 1 5 3 3 3 1 1 1 1 2 4 2 1 2 2 5 5 1 1 3 4 4 5 3 3 2 5 5 1
[281] 3 1 1 1 1 4 5 4 1 3 3 3 5 5 4 4 5 5 4 4 1 5 2 5 5 3 2 3 5 5 5 4 4 5 5
[316] 3 4 1 1 3 2 1 3 5 2 2 2 2 1 4 4 1 1 1 3 3 3 5 1 5 3 4 2 5 5 2 4 3 2 5
[351] 5 3 4 3 1 1 1 5 3 3 2 1
Levels: 1 2 3 4 5
> table(data_test$nmkat,fit_pre_knn)
fit_pre_knn
1 2 3 4 5
1 84 0 0 0 0
2 0 68 0 0 0
3 0 0 72 0 0
4 0 0 0 72 0
5 0 0 0 0 66
> errol_knn <- sum(as.numeric(as.numeric(fit_pre_knn)!=as.numeric(data_test$nmkat)))/nrow(data_test)
> errol_knn
[1] 0
> error_knn = rep(0,20)
> for (i in 1:20) {
+ fit_pre_knn = knn(data_train[,-12],data_test[,-12],cl=data_train[,12],k=i)
+ errol_knn[i] =sum(as.numeric(as.numeric(fit_pre_knn)!=as.numeric(data_test$nmkat)))/nrow(data_test)
+ }
> errol_knn
[1] 0.0000000 0.1629834 0.1353591 0.1850829 0.1546961 0.1823204 0.1767956
[8] 0.1906077 0.2209945 0.2320442 0.2458564 0.2679558 0.2596685 0.2651934
[15] 0.2734807 0.2734807 0.3038674 0.2928177 0.3232044 0.3259669
> plot(errol_knn,type = 'l',xlab = 'K')
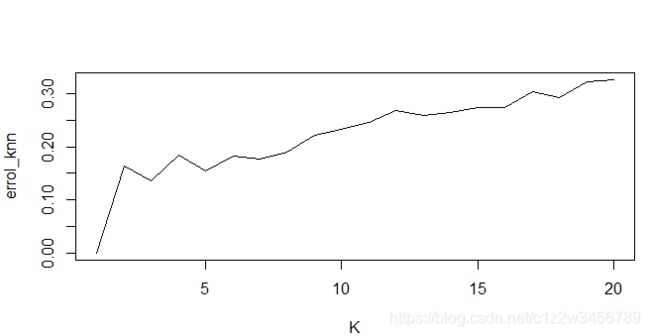
> ######有权重的K####
> library('kknn')
> fit_pre_kknn <- kknn(nmkat~.,data_train,data_test[,-12],k=5)
> #fit为判定结果
> summary(fit_pre_kknn)
Call:
kknn(formula = nmkat ~ ., train = data_train, test = data_test[, -12], k = 5)
Response: "ordinal"
fit prob.1 prob.2 prob.3 prob.4 prob.5
1 3 0.00000000 0.25672296 0.76636967 1.00000000 1
2 4 0.00000000 0.00000000 0.02451458 1.00000000 1
3 3 0.00000000 0.08072417 0.74327704 0.74327704 1
4 1 0.56585629 0.97548542 1.00000000 1.00000000 1
.....
163 2 0.48513212 1.00000000 1.00000000 1.00000000 1
164 2 0.00000000 0.97548542 0.97548542 1.00000000 1
165 4 0.00000000 0.00000000 0.40962913 0.51486788 1
166 4 0.00000000 0.08072417 0.33744713 0.82257926 1
[ reached 'max' / getOption("max.print") -- omitted 196 rows ]
> fit <- fitted(fit_pre_kknn)
> fit
[1] 3 4 3 1 3 1 1 2 2 1 3 4 4 3 4 2 5 3 3 3 3 3 1 1 4 2 1 1 3 2 2 3 2 3 3
[36] 1 5 1 4 3 4 4 4 5 4 5 3 2 2 3 1 2 1 3 1 1 4 3 2 3 5 3 2 5 2 3 1 1 1 1
[71] 5 3 2 3 2 5 4 3 4 2 2 2 3 2 3 2 5 2 3 4 4 2 3 2 2 1 1 4 5 3 1 3 2 5 2
[106] 5 1 1 4 2 3 2 3 1 2 4 5 4 5 3 5 2 4 3 2 3 1 1 5 1 4 5 2 2 2 4 4 5 5 1
[141] 2 5 5 5 1 4 2 4 3 5 1 5 3 3 4 1 2 5 5 4 5 3 2 2 4 4 3 2 3 2 1 1 2 2 2
[176] 4 4 2 3 1 2 3 1 1 5 4 4 5 1 4 4 1 5 4 5 2 2 4 4 5 4 4 1 1 2 2 1 2 2 4
[211] 2 1 3 4 1 4 5 2 3 4 3 4 5 4 2 1 4 4 4 4 2 1 4 4 1 1 3 1 5 3 3 3 5 3 2
[246] 4 3 3 1 4 4 1 4 3 3 3 1 1 1 1 3 4 2 1 1 2 5 5 1 1 2 4 4 5 3 3 2 5 5 1
[281] 3 1 1 1 1 4 5 4 1 2 3 1 5 5 4 4 5 5 4 4 1 4 2 5 5 3 2 3 5 3 5 4 4 5 5
[316] 3 3 1 1 3 2 1 4 5 2 2 2 2 1 4 2 1 2 1 3 3 3 5 1 5 3 4 2 5 5 2 4 3 2 5
[351] 5 3 4 3 1 1 1 5 3 3 2 1
Levels: 1 < 2 < 3 < 4 < 5
> table(data_test$nmkat,fit)
fit
1 2 3 4 5
1 72 9 3 0 0
2 4 60 3 1 0
3 1 5 63 3 0
4 0 1 7 64 0
5 0 0 1 5 60
> errol_kknn <- sum(as.numeric(as.numeric(fit)!=as.numeric(data_test$nmkat)))/nrow(data_test)
> errol_kknn
[1] 0.1187845
> ###############推荐系统综合实例#####################
数据集地址:https://grouplens.org/datasets/movielens/100k/ 选择ml-100K.zip

> data <- read.csv("G:\\R语言\\大三下半年\\数据挖掘:R语言实战\\数据挖掘:R语言实战(案例数据集)\\ml-100k\\movie.csv",header=F)
> data <- data[,-4]
> names(data) <- c('userid','itemid','rating')
> head(data);dim(data)
userid itemid rating
1 196 242 3
2 186 302 3
3 22 377 1
4 244 51 2
5 166 346 1
6 298 474 4
[1] 100000 3
> ##编写函数
> MovieLnes_KNN=function(Userid,Itemid,n,K)#编写一个总函数可以反复使用
+ {
+ sub=which(data$userid==Userid)#获取待测用户在数据集中各条信息所在的行标签,存于sub
+ if(length(sub)>=n)
+ sun_n=sample(sub,n)
+ if(length(sub)
+ known_itemid=data$itemid[sun_n]#获取已评分电影的ID
+ unknown_itemid=Itemid#获取带预测电影的ID
+ known_itemid
+ unknown_itemid
+ unknown_sub=which(data$itemid==unknown_itemid)
+ user=data$userid[unknown_sub[-1]]#获取已评价电影的用户ID
+ user
+ data_all=matrix(0,1+length(user),2+length(known_itemid))#设置data.all的行数、列数,所有值暂取0
+ data_all=data.frame(data_all)
+ names(data_all)=c("userid",paste("unknown_itemid_",Itemid),paste("itemid_",known_itemid,sep=""))
+ item=c(unknown_itemid,known_itemid)
+ data_all$userid=c(Userid,user)#对变量赋值
+ data_all
+ for(i in 1:nrow(data_all))#对data_all按行进行外层循环
+ {
+ data_temp=data[which(data$userid==data_all$userid[i]),]
+ for(j in 1:length(item))#对data—all按列进行内层循环
+ {if(sum(as.numeric(data_temp$itemid==item[j]))!=0)#判断该位置是否有取值
+ {data_all[i,j+1]=data_temp$rating[which(data_temp$itemid==item[j])]
+ }
+ }
+ }
+ data_all
+ data_test_x=data_all[1,c(-1,-2)]#获取测试集的已知部分
+ data_test_y=data_all[1,2]#获取测试集的待预测值
+ data_train_x=data_all[-1,c(-1,-2)]#获取训练集的已知部分
+ data_train_y=data_all[-1,2]#获取训练集的待预测值
+ dim(data_test_x);length(data_test_y)
+ dim(data_train_x);length(data_train_y)
+ fit=knn(data_train_x,data_test_x,cl=data_train_y,k=K)#进行knn判别
+ list("data_all:"=data_all,"True Rating:"=data_test_y,"Predcit Rating:"=fit,"User ID:"=Userid,"Item ID:"=Itemid)
+ }
#用户1对20部电影的评分
> user1=NULL
> for(Item in 1:20)
+ user1=c(user1,MovieLnes_KNN(Userid=1,Itemid=Item,n=50,K=10)$'True Rating:')
Warning message:
In knn(data_train_x, data_test_x, cl = data_train_y, k = K) :
k = 10 exceeds number 9 of patterns
> user1
[1] 5 3 4 3 3 5 4 1 5 3 2 5 5 5 5 5 3 4 5 4
#显示评分为5的电影
> which(user1==5)
[1] 1 6 9 12 13 14 15 16 19