数据预处理-异常值识别
系统总结了常用的异常值识别思路,整理如下:
空间识别
分位数识别
代表的执行方法为箱式图:
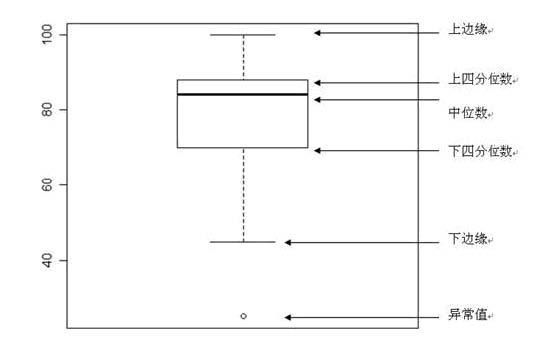
上四分位数Q3,又叫做升序数列的75%位点
下四分位数Q1,又叫做升序数列的25%位点
箱式图检验就是摘除大于Q3+3/2*(Q3-Q1),小于Q1-3/2*(Q3-Q1)外的数据,并认定其为异常值;针对全量样本已知的问题比较好,缺点在于数据量庞大的时候的排序消耗
R语言中的quantile函数,python中的percentile函数可以直接实现。
距离识别
最常用的就是欧式距离,
比如:两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的欧氏距离: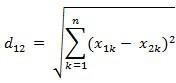
可以直观感受的到,图中,距离蓝色B点距离为基准衡量的话,红色A1,红色A2,红色A3为距离较近点,A4为距离较远的异常点。

但是这样看问题会有一个隐患,我们犯了“就点论点”的错误没有考虑到全局的问题,让我在看下面这张图:

还是刚才那张图,橙色背景为原始数据集分布,这样看来A4的位置反而比A1、A3相对更靠近基准点B,所以在存在纲量不一致且数据分布异常的情况下,可以使用马氏距离代替欧式距离判断数据是否离群。
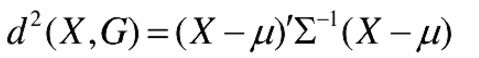
其中,μ为feature的均值,X为观察值,Σ为feature的协方差矩阵
马氏距离除了用来判断点是否异常,也可以用来判断两个数据集相识度,在图像识别,反欺诈识别中应用的也是非常普遍;问题在于太过于依赖Σ,不同的base case对应的Σ都是不一致的,不是很稳定
密度识别
密度识别的方式方法比较多,这边就提供其中比较经典的,首先我们可以通过密度聚类中大名鼎鼎的dbscan入手,这边只讲思路,详细的算法过程另行介绍。
简单的来讲,下面这张图可以协助理解

我们可以通过随机选择联通点,人为设置联通点附近最小半径a,半径内最小容忍点个数b,再考虑密度可达,形成蓝色方框内的正常数据区域,剩下的黄色区域内的点即为异常点。
除此之外,密度识别里面还有一种方式,是参考单点附近的点密度判断,伪代码如下:
1 |
1.从特征集合中任选历史上没有被选择过的两维 |
这边参考了Clique的映射+Denclue的密度分布函数的思路,注意问题就是计算量大,所以对小样本的适用程度更高一些,针对大样本多特征的数据可以考虑对样本进行子集抽样,再根据子集进行1-5,汇总后整体进行6-7步骤,实际检验效果仍然可以达到不抽样的85%以上
拉依达准则
这个方法更加偏统计一些,设计到一些距离的计算,勉强放在空间识别里面
这种判别处理原理及方法仅局限于对正态或近似正态分布的样本数据处理,它是以数据充分大为前提的,当数据较少的情况下,最好不要选用该准则。
正态分布(高斯分布)是最常用的一种概率分布,通常正态分布有两个参数μ和σ为标准差。N(0,1)即为标准正态分布。
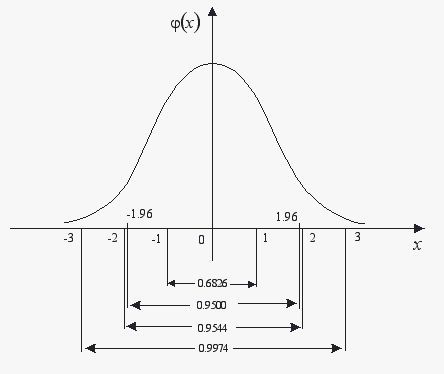
从上面这张图可以看出,当数据对象值偏离均值3倍标准差的时候,该数据合理的出现可能性小于3‰,所以可以直接认定,数据偏离均值±3倍标准差时,为异常点。但是最后再次强调一遍:它是以数据充分大为前提的,当数据较少的情况下,最好不要选用该准则。
计量识别
G-test或者说是likelihood Ratio方法
G-test这类方法运用在医学方面较多,常用于检验观测变量值是否符合理论期望的比值。现在也用在电商、出行、搜索领域检验一些无监督模型的质量、数据质量。
当我们新上一个模型,部分用户的反馈特别异常,我们不知道是不是异常数据,在接下来的分析中需不需要剔除,我们可以用统计学方法予以取舍。
其中O为观测值,E为期望值,假如我们的网站每天24个小时的订单量分布稳定,分时段计算出一个均值,E1,E2,..E24,新模型产出后,我们问题用户群对应的24个小时的订单分布值O1,O2,…..O24,套用上面的公式,我们就可以计算出一个G值出来。
然后在根据G-test的base值,观察目标用户可信的最大置信度,判断置信度是否符合我们的最低要求;likelihood Ratio方法类似,相关论文可以直接搜索。
模型拟合
这类方法属于简单有监督识别,常见的包括贝叶斯识别,决策树识别,线性回归识别等等。
需要提前知道两组数据:正常数据及非正常类数据,再根据它们所对应的特征,去拟合一条尽可能符合的曲线,后续直接用该条曲线去判断新增的数据是否正常。
举个例子:
金融借贷中,我们事先活动一批正常借贷用户,和逾期不还用户,我们通过打分卡模型去识别已知用户的特征,假设得到芝麻分、手机使用时长、是否为男性为关键特征。接下来判断未知标签的新增数据是否为正常用户的话,直接根据之前判断出来的拟合打分卡曲线去做0-1概率预估就行了。
但是模型拟合的方式使用情况较为局限,绝大多数异常识别问题是无法拿到前置的历史区分数据,或者已分好的数据不能够覆盖全量可能,导致时间判断误差较大,顾一般只做emsemble model的其中一种组合模块,不建议做主要依赖标注。
明尼苏达州大学有过一篇异常论文识别的总结,里面关于有监督模型、半监督模型、无监督模型等模型拟合讲的非常细致,如果感兴趣可以研究一下,附上论文Survey:http://cucis.ece.northwestern.edu/projects/DMS/publications/AnomalyDetection.pdf
变维识别
首先,我们来看一下PCA的伪代码
1 |
1.去除平均值,方便后续协方差,方差矩阵的计算 |
pca的核心思路在于尽可能通过feature的组合代替原始feature,使得原始数据的方差最大化。
通过pca可以得到第一主成分、第二主成分…。
对于正常数据集来说,正常数据量远远大于异常数据,所以正常数据所贡献的方差远远大于异常数据;通过pca得到的排名靠前的主成分解释了原始数据较大的方差占比,所以理论上讲,第一主成分反映了正常值的方差,最后一个主成分反映了异常点的方差。通过第一主成分对原始数据进行映射后,原始数据中的正常样本和异常样本的属性不会随之改变。
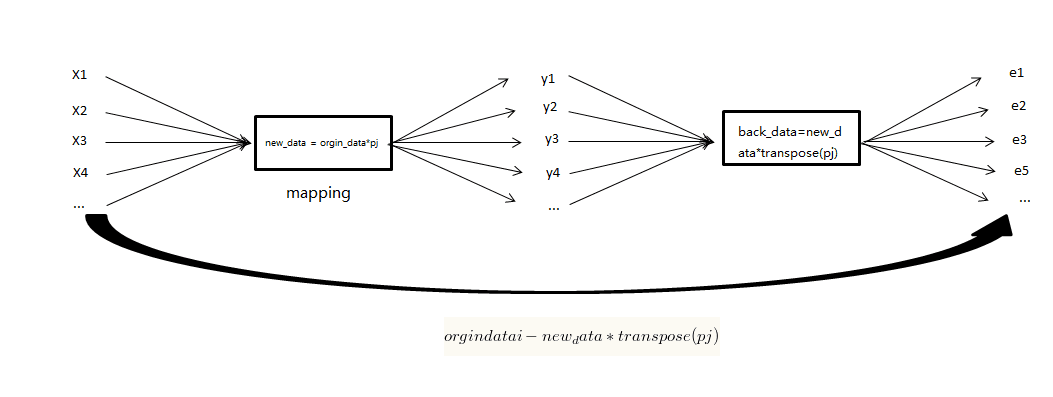
存在一个p个维度的数据集orgin_data,X为其协方差矩阵,通过奇异值分解可以得到:
![]()
其中,D为对角阵,其每一个值为X所对应的特征值;P的每一列为X的所对应的特征向量,并将D中的特征值从大到小排列,相应的改变P所对应的列向量。
我们选取top(j)个D中的特征值,及其P所对应的特征向量构成(p,j) 维的矩阵 pj ,再将目标数据集orgin_data进行映射:new_data = orgin_data*pj;new_data是一个 (N,j) 维的矩阵。如果考虑拉回映射的话(也就是从主成分空间映射到原始空间),重构之后的数据集合是:back_data=transpose(pj*transpose(new_data))=new_data*transpose(pj),是使用 top-j 的主成分进行重构之后形成的数据集,是一个 (N,p) 维的矩阵。
所以,我们有如下的outlier socres的定义:
![]()
ev(j) subject to.
![]()
解释一下上面两个公式,先计算score中orgindata的列减去前j个主成分映射回原空间的newdata下的欧式范数值;再考虑不同主成分所需乘以的权重,这边,我们认为,第一主成分所代表的数据中正常数据更多,所以权重越小;当j取到最后一维的主成分下,我们认为权重最高,达到1。
对于outlier socres过高的点,即为异常点。
神经网络识别
之前比较火的神经网络分析,同样可以用来做有监督的异常点识别,这边介绍一下Replicator Neural Networks (RNNs)。
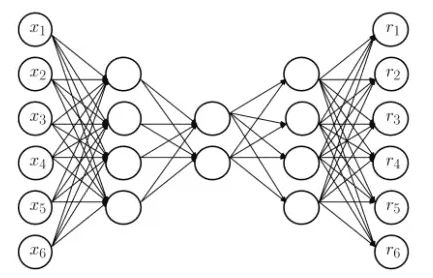
这边我们通过图像可以看出:
1.输入层中,输入变量个数与输出层中,输出变量一致
2.中间层的节点数小于输入输出层节点
3.整个训练过程是一个先压缩后解压的过程
常规的,我们通过mse来看模型的误差
我们来大致了解一下RNN的运行逻辑,首先,最左边的为输入层即为原始数据,最右层的为输出层即为输出数据。中间各层的激活函数不同,入参经过激活函数所得到的出参的值也不一致,但是在同一层激活函数都是一致的。
对于我们异常识别而言,第二层和第四层 (k=2,4),激活函数选择为![]()
tanh图像如下,可以将原始数据压缩在-1到1之间,使得原始数据有界。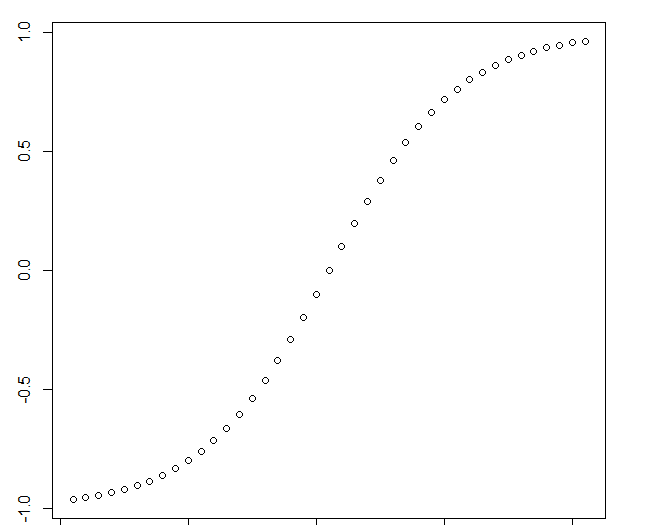
对于中间层 (k=3) 而言,激活函数是一个类阶梯 (step-like) 函数。![]()
其中,N为阶梯分层数,a3为提升的效率。N的个数越多,层次分的更多。
比如N=5的形式下:
比如N=3的形式下:

这样做的好处就是,随着N的增加可以将异常点或者异常点群集中在某一个离散阶梯范围内。
通过对RNN的有监督训练,构造异常样本分类器,进行异常值识别。
isolation forest
2010年南大的周志华教授提出了一个基于二叉树的异常值识别算法,在工业界来说,效果是非常不错的,最近我也做了一个流失用户模型,实测效果优秀。
和random forest一样,isolation forest是由isolation tree构成,先看一下isolation tree的逻辑:
1 |
method: |
大致的思路如下图:
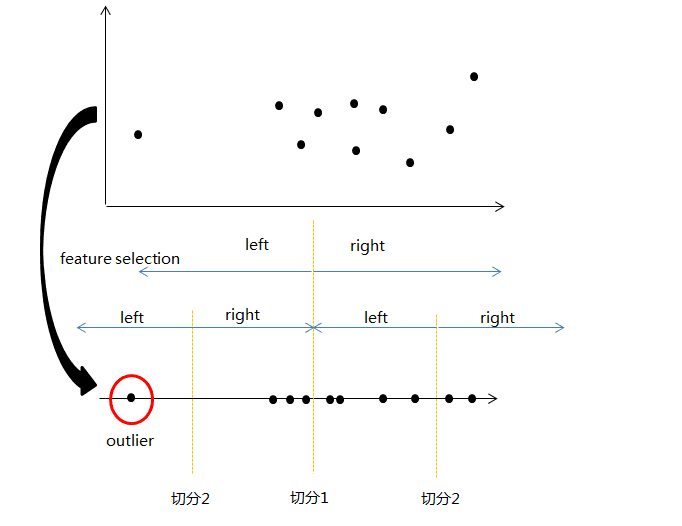
理论上,异常数据一般都是离群数据,非常容易在早期就被划分到最终子节点。所以,通过计算每个子节点的深度h(x),来判断数据为异常数据的可能性。论文中,以s(x,n)为判断数据是否异常的衡量指标。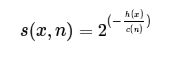
![]()
其中,h(x)为x对应的节点深度,c(n)为样本可信度,s(x,n)~[0,1],正常数据来讲s(x,n)小于0.8,s(x,n)越靠近1,数据异常的可能性越大。
单棵树的可信性不足,所以我们通过用emsemble model的思路,去构造一个forest的树群来提高准确性。
但是作为isolation forest的时候,需要对原s(x,n)的公式有所更改,通过E(h(x))来替代h(x),其中E(h(x))为数据x在各棵树上的h(x)的平均。
同时,
1.因为树的个数大大增加,所以需要控制计算的开销,所以每个棵树我们可以采取数据抽样的方式,使得抽样数据集远远小于原始数据集,且根据周志华老师的论文,采样大小超过256效果就提升不大了。
2.我们可以控制深度,使得没棵树的最大深度limit length=ceiling(log2(样本大小)),当树深度大于最大深度时,其产生的子节点绝大多数均为正常数据节点,失去异常检验的意义。