决策树(Decision Tree)--原理及Python代码实现
友情提示:仔细阅读、用笔计算,才能更好的理解。
1. 基本流程
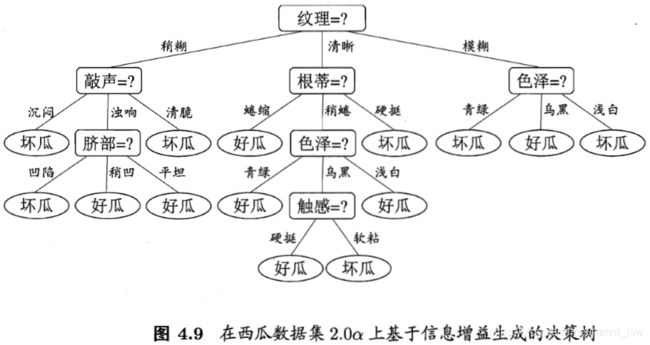
决策树(Decision Tree)是一类常见的机器学习方法。一般的,一颗决策树包含一个根节点、若干个内部节点何若干个叶节点。西瓜问题的决策树如下:
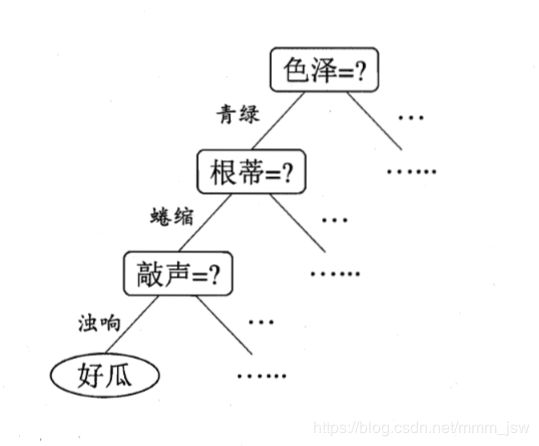
决策树学习的目的是为了产生一颗泛化能力强,即处理未见实例能力强的决策树,其基本流程遵循简单且直观的“分而治之”(divide—and—conquer)策略。决策树学习的基本算法如图所示:

决策树是由递归生成的,再决策树基本算法中,有三种情形会导致递归返回:
(1)当前结点包含的样本全属于同一类别,无需划分;
(2)当前属性集为空,或是所有样本在所有属性上取值相同,无法划分;
(3)当前结点包含的样本集合为空,不能划分。
2. 划分选择
决策树学习的关键是从属性集中选择最优的划分属性。一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”(purity)越来越高。
2.1. 信息增益
ID3(Iterative Dichotomiser—迭代二分器)就是以信息增益为准则来选择划分属性。“信息熵”(information entropy)是度量样本集合纯度中常用的一种指标。
假设当前样本集合D中第k类样本所占的比例为Pk(k = 1,2,…,|y|),信息熵的计算公式如图所示:

在对样本集D进行划分时,需要考虑样本集的不同离散属性a(如:西瓜色泽包含青绿、乌黑、浅白属性),不用的分支结点中样本数越多的影响越大,于时可计算用属性a对样本D进行划分所获得的“信息增益”(information gain),公式如下:
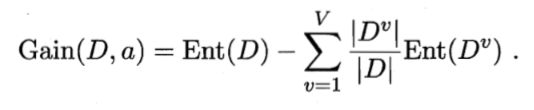
决策树的生成
下面以表4.1中的西瓜数据2.0为例,用以学习一棵能预测没剖开的是不是好瓜的决策树:
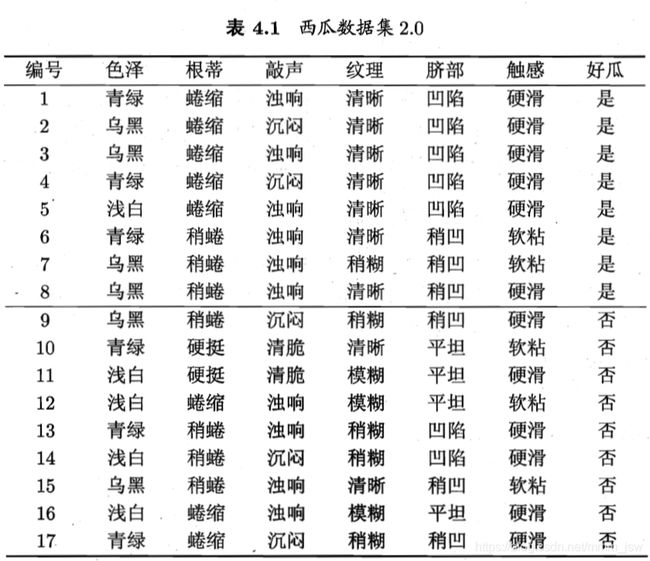
显然,|y|=2。
step1
在决策树开始时,根结点包含D中的所有样例,其中正例占p1=8/17,反例占p2=9/17。根据公式得到根节点的信息熵为:
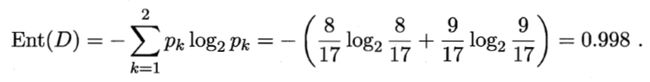
step2
计算出当前属性集合{色泽,根蒂,敲声,纹理,脐部,触感}中每个属性的信息增益。以属性“色泽”为例,它有3个可能的取值{青绿,乌黑,浅白}。
- "色泽"属性有3个子集,记为D1(色泽=青绿),D2(色泽=乌黑),D3(色泽=浅白)。
- D1中包含编号{1,4,6,10,13,17}6个样例,其中正例p1=3/6,p2=3/6;
D2中包含编号{2,3,7,8,9,15}6个样例,其中正例p1=4/6,p2=2/6;
D3中包含编号{5,11,12,14,16}5个样例,其中正例p1=1/5,p2=4/5。 - 计算用“色泽”划分之后所获得的3个分支结点的信息熵

- 计算出属性“色泽”的信息增益

step3:
纹理的属性划分: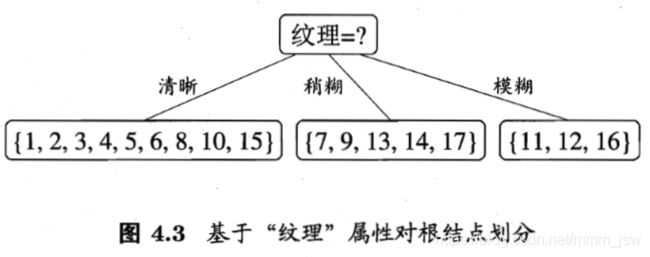
- 属性"纹理"的信息增益最大,于是被选为划分属性,包含{1,2,3,4,5,6,8,10,15}9个样例p1=5/7,p2=2/7,纹理的信息熵为:属性"纹理"的信息增益最大,于是被选为划分属性,包含{1,2,3,4,5,6,8,10,15}9个样例p1=5/7,p2=2/7,纹理的信息熵为:
E n t ( D w ) = − [ 5 / 7 ⋅ l o g ( 5 / 7 ) + 2 / 7 ⋅ l o g ( 2 / 7 ) ] Ent(Dw) = -[5/7·log(5/7)+2/7·log(2/7)] Ent(Dw)=−[5/7⋅log(5/7)+2/7⋅log(2/7)] - 基于"纹理"可用属性集合{色泽,根蒂,敲声,脐部,触感},计算各属性的信息增益:2.基于"纹理"可用属性集合{色泽,根蒂,敲声,脐部,触感},计算各属性的信息增益:

三个取得最大信息增益,选其中之一作为划分属性即可。
step4
重复上述步骤得到基于信息增益 生成的决策树

2.2. 增益率
在上述的介绍中,若把“编号”也作为一个候选划分属性,信息增益最大将产生17个分支,这些分支结点的纯度已经到达最大。这样的决策树不具有泛化能力,无法对新样本进行有效预测。
实际上,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,C4.5决策树算法改为使用“增益率”(gain ratio)来选择最有划分属性。
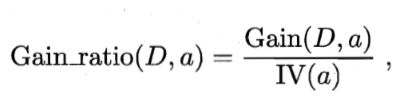
其中,IV(a)为属性a的“固有值”。属性a的可能取值数目越多(即V越大),则IV(a)通常越大。
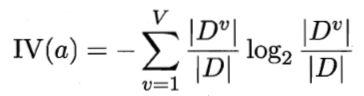
注意
C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
2.3. 基尼指数
CART(Classification and Regression Tree)决策树,使用“基尼指数”(Gini index)来选择划分属性。
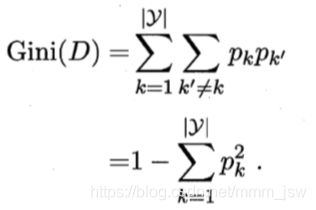
公式反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率。基尼指数越小,则数据集D的纯度越高。
属性a的基尼指数定义为:

在候选属性集合A中,选择使得划分后基尼指数最小的属性作为最优划分属性,即
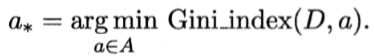
3. 剪枝处理
在决策树学习中,结点划分过程不断重复,会造成决策树分支过多,剪枝(pruning)时决策树对付“过拟合”的主要手段。决策树剪枝的基本策略有“预剪枝”(prepruning)和“后剪枝”(post-pruning)。
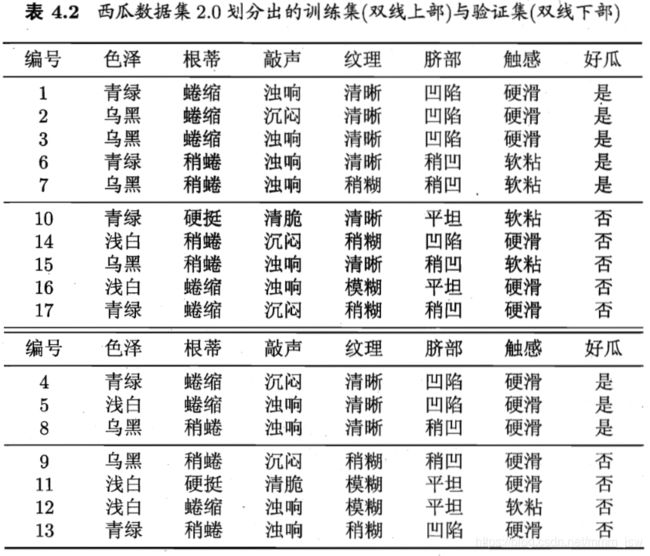
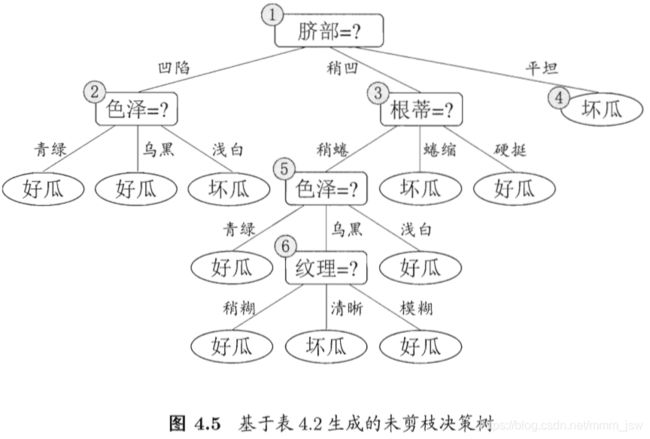
3.1 预剪枝
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。
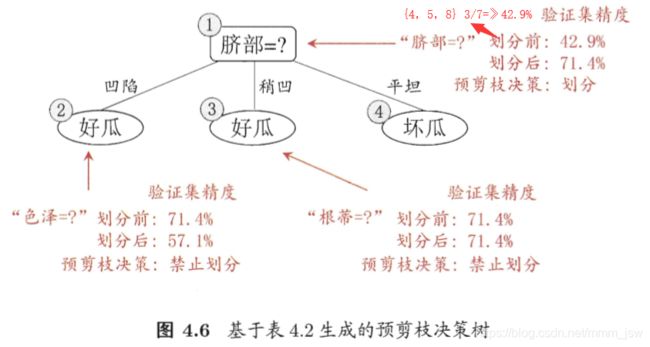
预剪枝使得决策树的很多分支都没有“展开”,这不仅降低了过拟合的风险,还显著减少了决策树的训练时间开销和测试时间开销。但另一方面,有些分支的当前划分虽不能提升泛化能力、甚至可能导致泛化性能暂时下降,但在其基础上进行的后续划分却有可能导致性能显著提高;预剪枝基于“贪心”本质禁止这些分支展开,给预剪枝带来了欠拟合的风险。
3.2 后剪枝
后剪枝是先从训练集生成一颗完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
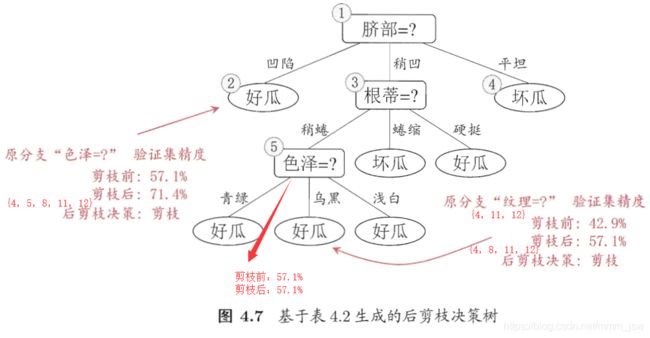
一般情形下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预先剪枝决策树。但后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中地所有非叶结点进行逐一考察,因此时间开销比未剪枝决策树和预剪枝决策树都要大得多。
4. 连续与缺失值
4.1. 连续值处理
连续属性的可取值数目不有限,不能直接根据连续属性的可取值来对结点进行划分。这时需要使用连续属性离散化的技术,最简单的策略是采用二分法对连续属性进行处理,这正是C4.5决策树算法中采用的机制。
把区间[ai , ai+1) 的中位点作为划分点,可考察包含n-1个元素的候选划分点集合。
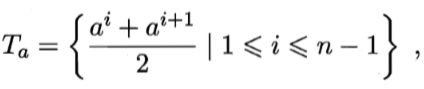
信息增益的计算:
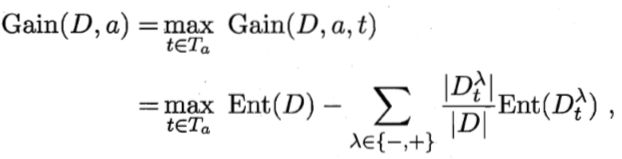
其中Gain(D,a, t)是样本D基于划分点t二分后的信息增益,选择使Gain(D,a, t)最大化的划分点。
实例
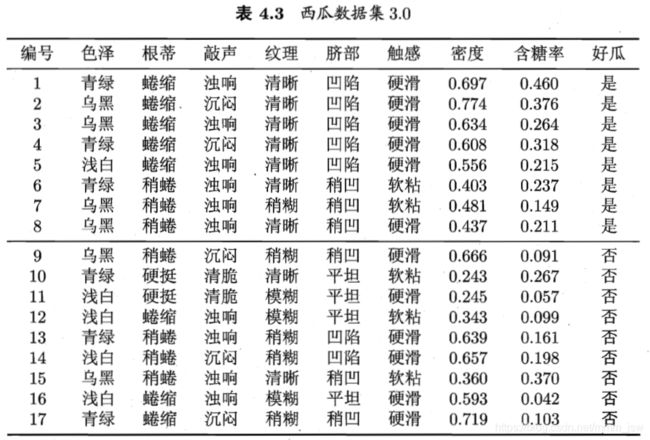
密度、含糖率候选值:


各属性的增益率:

递归生成的决策树:

4.2. 缺失值处理
现实任务中,在属性数目较多的情况下,往往会有大量样本出现缺失值,如果舍弃缺失值会造成数据信息极大的浪费,有必要考虑利用有缺失值属性的训练样例来进行学习。

需要解决的问题:
(1)如何在属性缺失的情况下进行划分属性选择?
(2)给定划分属性,若样本在该属性上的缺失,如何对样本进行划分?
给定公式如下:

信息增益计算式:

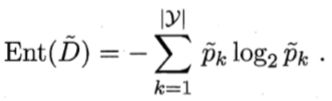
表4.4数据计算
step1:

step2:


step3:

step4:

生成的决策树:
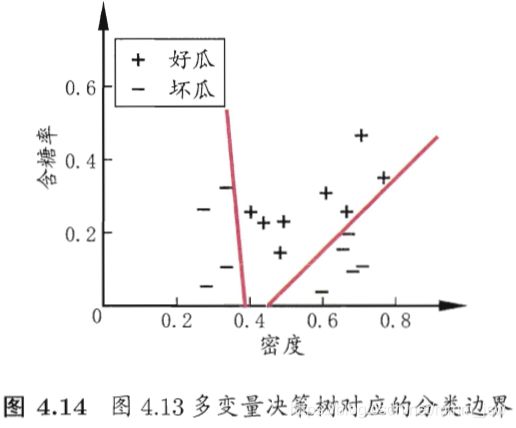
5. 多变量决策树
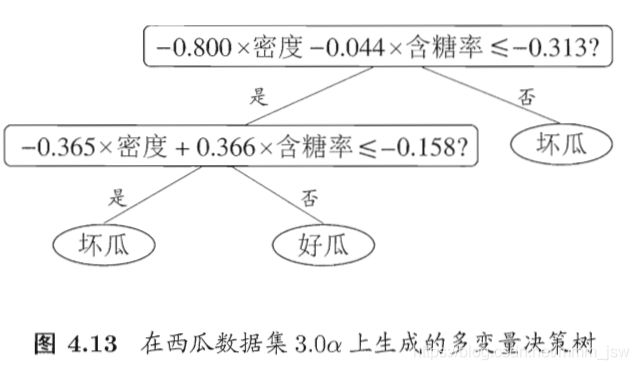
“多变量决策树”(multivariate decision tree)能实现“斜划分”。

在多变量决策树的学习过程中,不是为每个叶节点寻找一个最优划分属性,而是试图建立一个合适的线性分类器。
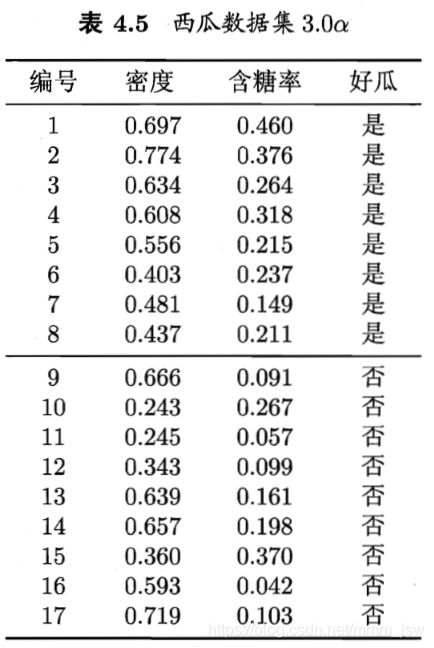
6. 决策树的Python实现
- 基于信息熵进行划分选择的决策树算法,为表4.3中数据生成一棵决策树。
- 基于基尼指数进行划分选择的决策树算法,为表4.2中数据生成预剪枝、后剪枝决策树,并于未剪枝决策树进行比较。
7. 参考
- 《机器学习》—— 周志华
- 《机器学习》周志华习题4.3答案
- 《机器学习》周志华习题4.4答案