用全局平均池化和1x1卷积代替全连接层的AlexNet在Cifar10上实现86%的准确率
新人刚学神经网络没多久……还处于木工乱搞阶段
啥都想搞来试一试
最近因为新型肺炎在家没啥事做
第一次使用全局平均以及用1x1卷积代替全连接层
在这里做个记录
重新实现了一下AlexNet,就当复习一遍了
顺便在AlexNet基础上加上了很多其他技术
BN,GAP,ExponentialDecay,Warmup
当然还了解到一切其他的比如可分离卷积,不过没有添加进去(不敢乱用)
由于现在只能用几年前的笔记本跑,跑不出大网络,所以网络输入为128x128的
为了节约内存,在数据增强部分再resize为128*128
由于环境为jupyter,所以整个代码写在一起
数据读取部分和可视化部分代码:
代码接口仿照MNIST
从MNIST测试好移到cifar10只需要mnist替换成cifar10,函数什么的都是一样的
单线程,很慢,光是在数据处理上一个epoch就要耗费一两百秒
等这个网络跑完我就去学多线程(间歇性凌云壮志)
%matplotlib inline
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import os
import time
import pickle
from sklearn.utils import shuffle
from tensorflow.contrib.layers import xavier_initializer
trained_model_path='D:\\log\\cifar-10-batches-py\\trained_model_path_AlexNet'
data_path='D:\\log\\cifar-10-batches-py'
name=["airplane","automobile","bird","cat","deer","dog","frog","horse","ship","truck"]
def imshows(images,labels,index,amount): #显示图片和对应标签,从index开始往后amount张
fig=plt.gcf()
fig.set_size_inches(10,20)
for i in range(amount):
title=name[np.argmax(labels[index+i])] #onehot标签
ax=plt.subplot(5,6,i+1)
ax.set_title(title)
ax.imshow(images[index+i])
plt.show()
class Batcher(): #数据分batch
def __init__(self,images,labels,num_examples,is_enhance):
self.tf_variables_init=False
self.labels=labels[0:num_examples]
self.images=images[0:num_examples]
self.num_examples=num_examples
self.batch_index=0
self.enhance_graph=tf.Graph() #单独在另外一个计算图处理,实测不分开跑得巨慢无比)
with self.enhance_graph.as_default(): #数据增强
self.image=tf.placeholder(tf.float32)
self.is_enhance=tf.constant(is_enhance,dtype=tf.bool)
self.cropped=tf.random_crop(self.image,[24,24,3])
self.flipped=tf.image.random_flip_left_right(self.cropped)
self.flipped=tf.image.random_flip_up_down(self.flipped)
self.brightness=tf.image.random_brightness(self.flipped,max_delta=0.3)
self.contrast=tf.image.random_contrast(self.brightness,lower=0.7,upper=1.4)
self.saturation=tf.image.random_saturation(self.contrast,lower=0.7,upper=1.4)
self.result=tf.cond(self.is_enhance,lambda:self.saturation,lambda:self.cropped)
self.reshape=tf.image.resize_images(self.result,[128,128])
self.standardization=tf.image.per_image_standardization(self.reshape)
def next_batch(self,batch_size,extra_original_images=True):
images_list=np.zeros([batch_size,128,128,3])
labels_list=np.zeros([batch_size,10])
with tf.Session(graph=self.enhance_graph) as sess:
for i in range(batch_size):
images_list[i]=sess.run(self.standardization,feed_dict={self.image:self.images[self.batch_index]})
labels_list[i][self.labels[self.batch_index]]=1
self.batch_index+=1
if self.batch_index==self.num_examples:
self.batch_index=0
self.images,self.labels=shuffle(self.images,self.labels)
return images_list,labels_list
class cifar10_reader():
def __init__(self,data_path,num_examples_for_training=50000,num_examples_for_test=10000):
self.data_path=data_path
self.num_examples_for_training=num_examples_for_training
self.num_examples_for_test=num_examples_for_test
self.load_cifar10_data(self.data_path)
def unpickle(self,filename):
with open(filename,'rb') as file:
dict=pickle.load(file,encoding="iso-8859-1")
images=dict.get("data").reshape(10000,3,32,32).transpose(0,2,3,1)
labels=np.array(dict.get("labels"))
return images,labels
def load_cifar10_data(self,data_path):
images_list=[]
labels_list=[]
for i in range(5):
filename=os.path.join(data_path,"data_batch_%d"%(i+1))
print("extracting from "+filename)
images,labels=self.unpickle(filename)
images_list.append(images)
labels_list.append(labels)
xtrain,ytrain=np.concatenate(images_list),np.concatenate(labels_list)
print("extracting from "+os.path.join(data_path,"test_batch"))
xtest,ytest=self.unpickle(os.path.join(data_path,"test_batch"))
self.train=Batcher(xtrain,ytrain,self.num_examples_for_training,is_enhance=True)
self.test=Batcher(xtest,ytest,self.num_examples_for_test,is_enhance=False)
cifar10=cifar10_reader(data_path,5000,5000) #可以读入一个子集
学习率策略:指数衰减+预热
tf.reset_default_graph()
def exponential_decay_with_warmup(warmup_step,learning_rate_base,global_step,learning_rate_step,learning_rate_decay,staircase=False):
warmup_step=tf.constant(warmup_step)
linear_increase=learning_rate_base*tf.cast(global_step/warmup_step,tf.float32)
exponential_decay=tf.train.exponential_decay(learning_rate_base,
global_step-warmup_step,
learning_rate_step,
learning_rate_decay,
staircase=staircase)
learning_rate=tf.cond(global_step<=warmup_step,lambda:linear_increase,lambda:exponential_decay)
return learning_rate
网络结构:
class CNN():
def __init__(self,drop_rate=0.0,is_training=False,regularizer=None,regularizer_name='losses',average_class=None):
self.layer_index=1
self.drop_rate=drop_rate
self.is_training=is_training
self.Rname=regularizer_name
if regularizer is None:
self.regularizer=None
else:
self.regularizer=regularizer
if average_class is None:
self.ema=None
else:
self.ema=average_class.apply
def Xavier(self): #for Conv
return tf.contrib.layers.xavier_initializer()
def MSRA(self,shape): #for FC
if len(shape)==2:
return tf.truncated_normal_initializer(stddev=2/shape[1])
else:
return tf.truncated_normal_initializer(stddev=2/(shape[0]*shape[1]*shape[2]))
def Relu(self,tensor):
with tf.variable_scope("L%d_Relu"%self.layer_index,reuse=tf.AUTO_REUSE):
self.layer_index+=1
return tf.nn.relu(tensor)
def Conv2d(self,tensor,output_channel,ksize,strides,padding="VALID"):
with tf.variable_scope("L%d_Conv2d"%self.layer_index,reuse=tf.AUTO_REUSE):
self.layer_index+=1
input_channel=tensor.shape.as_list()[-1]
kernel_shape=[ksize,ksize,input_channel,output_channel]
kernel=tf.get_variable("kernel",kernel_shape,initializer=self.Xavier())
conv2d=tf.nn.conv2d(tensor,kernel,strides=[1,strides,strides,1],padding=padding)
bias=tf.get_variable("bias",[output_channel],initializer=tf.constant_initializer(0.0))
bias_add=tf.nn.bias_add(conv2d,bias)
return bias_add
def MaxPooling2d(self,tensor,ksize,strides,padding="VALID"):
with tf.variable_scope("L%d_MaxPooling2d"%self.layer_index,reuse=tf.AUTO_REUSE):
self.layer_index+=1
return tf.nn.max_pool(tensor,ksize=[1,ksize,ksize,1],strides=[1,strides,strides,1],padding=padding)
def BatchNormalization(self,tensor):
with tf.variable_scope("L%d_BatchNorm"%self.layer_index,reuse=tf.AUTO_REUSE):
self.layer_index+=1
return tf.layers.batch_normalization(tensor,training=self.is_training)
def Dropout(self,tensor,drop_rate):
with tf.variable_scope("L%d_Dropout"%self.layer_index,reuse=tf.AUTO_REUSE):
self.layer_index+=1
return tf.layers.dropout(tensor,drop_rate,training=self.is_training)
def GlobalAvgPooling2d(self,tensor):
with tf.variable_scope("L%d_GlobalAvgPooling2d"%self.layer_index,reuse=tf.AUTO_REUSE):
self.layer_index+=1
tensor_shape=tensor.shape.as_list()
ksize=[1,tensor_shape[1],tensor_shape[2],1]
gap=tf.nn.avg_pool(tensor,ksize=ksize,strides=[1,1,1,1],padding="VALID")
return tf.reshape(gap,[-1,tensor_shape[-1]])
def FullCon(self,tensor,output_dim):
with tf.variable_scope("L%d_FullCon"%self.layer_index,reuse=tf.AUTO_REUSE):
self.layer_index+=1
input_dim=tensor.shape.as_list()[-1]
weight=tf.get_variable("weight",[input_dim,output_dim],initializer=self.MSRA([input_dim,output_dim]))
bias=tf.get_variable("bias",[output_dim],initializer=tf.constant_initializer(0.01))
if self.regularizer:
tf.add_to_collection(self.Rname,regularizer(weight))
if self.ema and self.is_training==0:
return tf.matnul(tensor,self.ema(weight))+self.ema(bias)
else:
return tf.matmul(tensor,weight)+bias
def AlexNet(self,tensor):
conv=self.Conv2d(tensor,output_channel=96,ksize=11,strides=4,padding="VALID")
BN=self.BatchNormalization(conv)
relu=self.Relu(BN)
pool=self.MaxPooling2d(relu,ksize=3,strides=2,padding="VALID")
conv=self.Conv2d(pool,output_channel=256,ksize=5,strides=1,padding="SAME")
BN=self.BatchNormalization(conv)
relu=self.Relu(BN)
pool=self.MaxPooling2d(relu,ksize=3,strides=2,padding="VALID")
conv=self.Conv2d(pool,output_channel=384,ksize=3,strides=1,padding="SAME")
BN=self.BatchNormalization(conv)
relu=self.Relu(BN)
conv=self.Conv2d(relu,output_channel=384,ksize=3,strides=1,padding="SAME")
BN=self.BatchNormalization(conv)
relu=self.Relu(BN)
conv=self.Conv2d(relu,output_channel=256,ksize=3,strides=1,padding="SAME")
BN=self.BatchNormalization(conv)
relu=self.Relu(BN)
pool=self.MaxPooling2d(relu,ksize=3,strides=2,padding="VALID")
Global_avg_pool=self.GlobalAvgPooling2d(pool)
full=self.FullCon(Global_avg_pool,512)
BN=self.BatchNormalization(full)
relu=self.Relu(BN)
dropout=self.Dropout(relu,drop_rate=self.drop_rate)
full=self.FullCon(dropout,256)
BN=self.BatchNormalization(full)
relu=self.Relu(BN)
dropout=self.Dropout(relu,drop_rate=self.drop_rate)
full=self.FullCon(dropout,10)
return full
然后是一些超参数,以及优化器,损失函数等等
x=tf.placeholder(tf.float32,[None,128,128,3])
y=tf.placeholder(tf.float32,[None,10])
is_training=tf.placeholder(tf.bool)
train_epoches=85
batch_size=64
batch_num=int(cifar10.train.num_examples/batch_size)
#预热的指数衰减学习率
global_step=tf.Variable(0,trainable=False)
warmup_step=batch_num*3
learning_rate_base=0.015
learning_rate_decay=0.95
learning_rate_step=batch_num
learning_rate=exponential_decay_with_warmup(warmup_step,learning_rate_base,global_step,learning_rate_step,learning_rate_decay)
#滑动平均
ema_decay=0.999
ema=tf.train.ExponentialMovingAverage(ema_decay,global_step)
ema_op=ema.apply(tf.trainable_variables())
#正则化和前向预测
regularizer=tf.contrib.layers.l2_regularizer(0.004)
forward=CNN(drop_rate=0.25,is_training=is_training,regularizer=regularizer).AlexNet(x)
prediction=tf.nn.softmax(forward)
correct_prediction=tf.equal(tf.argmax(prediction,1),tf.argmax(y,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
#损失函数和优化器
momentum=0.9
cross_entropy=tf.losses.softmax_cross_entropy(onehot_labels=y,logits=forward,label_smoothing=0.01)
l2_regularizer_loss=tf.add_n(tf.get_collection("losses"))
loss_function=cross_entropy+l2_regularizer_loss
update_ops=tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
optimizer=tf.train.MomentumOptimizer(learning_rate,momentum).minimize(loss_function,global_step=global_step)
#模型可持久化
if not os.path.exists(trained_model_path):
os.makedirs(trained_model_path)
saver=tf.train.Saver(tf.global_variables())
开始进行训练:
acc_Xavier_list=[0.0]
loss_Xavier_list=[0.0]
step=0
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
trained_model_state=tf.train.get_checkpoint_state(trained_model_path)
if trained_model_state and trained_model_state.model_checkpoint_path:
saver.restore(sess,trained_model_state.model_checkpoint_path)
start_time=time.time()
print("training start!")
for epoch in range(0,train_epoches):
for batch in range(batch_num):
xs,ys=cifar10.train.next_batch(batch_size)
sess.run([optimizer,ema_op],feed_dict={x:xs,y:ys,is_training:True})
if batch %100==0:
xs,ys=cifar10.test.next_batch(100)
loss,acc=sess.run([loss_function,accuracy],feed_dict={x:xs,y:ys,is_training:False})
decay=min(0.96,(1+step)/(10+step))
acc_Xavier_list.append(decay*acc_MSRA_list[-1]+(1-decay)*acc)
loss_Xavier_list.append(decay*loss_MSRA_list[-1]+(1-decay*loss))
step+=1
print("Epoch:%d Speed:%.2f seconds per epoch -> Accuracy:%.3f Loss:%.3f"%(epoch+1,(time.time()-start_time)/(1+epoch),acc,loss))
print("learning rate:%.7f "%(sess.run(learning_rate)))
saver.save(sess,os.path.join(trained_model_path,"trained_model_%d"%(epoch+1)))
print("model_%d saved"%(epoch+1))
print("training finished after %.2f seconds"%(time.time()-start_time))
因为损失和准确率很不稳,为了便于得到平滑曲线直观比较,采用滑动平均来进行计算
之前在卷积自编码器上测试过Xavier MSRA HE三种初始化策略的好坏
此次实验也用5000+1000的小规模数据测试了MSRA和Xavier两种初始化方式对网络训练的影响
总共85Epoch,峰值的时候竟然也有68%的准确率
我刚开始照着书上的写在没有数据增强的情况下也差不多68%(实际上写了,只不过写错了,导致并没有数据增强,我就说书上怎么随便泡泡就73%+了)
在训练过程中中断,微调参数后继续训练,这样能达到71%
当然在数据增强后能达到86%了hhh
这次使用全局平均池化+两个小的全连接层,效果看起来挺好,起码5000的训练集大小都能68%+
当然……前面也说了,忘了准确率很不稳定,可能和我测试集图片也随机剪裁有关,滑动平均的结果来看也是能突破60%的
至于结果
首先是预处理上两种方式(暂时测试两组,有空试试其他组合)
卷积层Xavier+全连接层MSRA
卷积层MSRA+全连接层MSRA
取了前面80个Epoch的数据
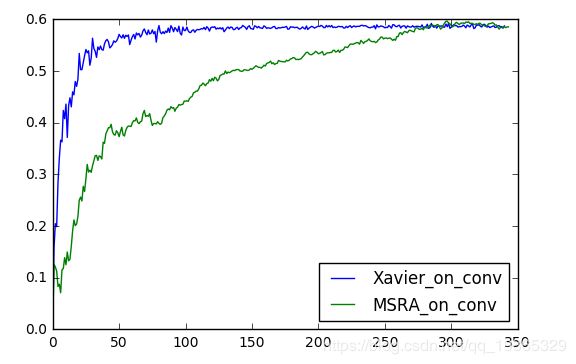
显然初始化对网络收敛影响是比较大的,对准确率的影响这里并没有体现
最终采用Xavier对网络进行初始化
现在50000+10000进行最终训练
由于中途电脑过热给关掉了…
所以运行时间的统计出了点点问题
不过电脑配置本来也差(7200U+940mx)
![]()
最高的时候达到了86.6%
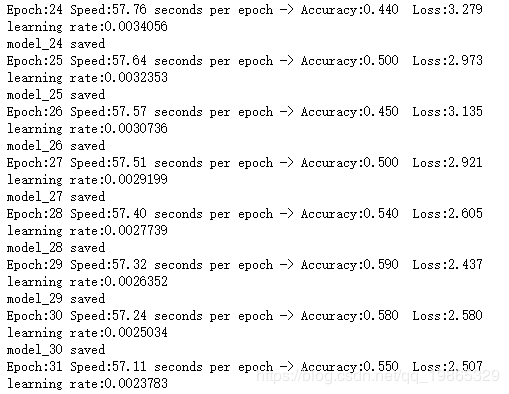
最后几个epoch数据:

由于波动比较大,所以采用了滑动平均的数据来绘制曲线

从这个趋势上来看似乎没有收敛
另外
在测试集上我又运行了一遍
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
trained_model_state=tf.train.get_checkpoint_state(trained_model_path)
if trained_model_state and trained_model_state.model_checkpoint_path:
saver.restore(sess,trained_model_state.model_checkpoint_path)
xs,ys=cifar10.train.next_batch(500)
print(sess.run(accuracy,feed_dict={x:xs,y:ys,is_training:False}))
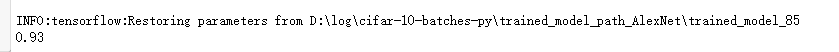
看起来过拟合了
这么说通过更加合理的参数,准确率应该是可以进一步提高的
不过现在限于硬件水平暂时搁置一下了,等开学去机房看看能跑到多少