【Cassandra从入门到放弃系列 二】Column-based存储模式
在正式的了解Cassandra之前,有必要了解下Cassandra的存储模式,即Column-based存储模式。典型的
NoSql按数据存储方式主要分为三类:
- Key-Value数据库,如Redis,Key-Value数据库会以键值对的方式来对数据进行存储。其内部常常通过哈希表这种结构来记录数据。在使用时,用户只需要通过Key来读取或写入相应的数据即可。因此其在对单条数据进行CRUD操作时速度非常快。而其缺陷也一样明显:只能通过键来访问数据。除此之外,数据库并不知道有关数据的其它信息。因此如果我们需要根据特定模式对数据进行筛选,那么Key-Value数据库的运行效率将非常低下,这是因为此时Key-Value数据库常常需要扫描所有存在于Key-Value数据库中的数据,因此在一个服务中,Key-Value数据库常常用来作为服务端缓存使用,以记录一系列经由较为耗时的复杂计算所得到的计算结果
- Document-based数据库,如MongoDB,(与Key-value)类似,Value是结构化的, 和Key-Value数据库之间的不同主要在于,其所存储的数据将不再是一些字符串,而是具有特定格式的文档,如XML或JSON等。这些文档可以记录一系列键值对,数组,甚至是内嵌的文档。Document-based数据库常常会支持索引。我们刚刚提到过,Key-Value数据库在执行数据的查找及筛选时效率非常差。而在索引的帮助下,Document-based数据库则能够很好地支持这些操作了
- Column-based数据库,如Cassandra、HBase等。列存储模式适用于海量数据NoSql下的的大数据使用。
当然 Key-Value,Document-based以及Column-based实际上是对NoSQL数据库的一种较为泛泛的分类。不同的数据库提供商所提供的NoSQL数据库常常具有略为不同的实现方式,并提供了不同的功能集合,进而会导致这些数据库类型之间的边界并不是那么清晰。
Column-based存储模式
在存储结构上区别于行存储模式,行存储模式就是我们传统意义上使用的关系型数据库,例如Mysql、SqlServer,这类数据库是按照行来组织数据的,而列存储模式就是按照列来组织数据的(图片来源)
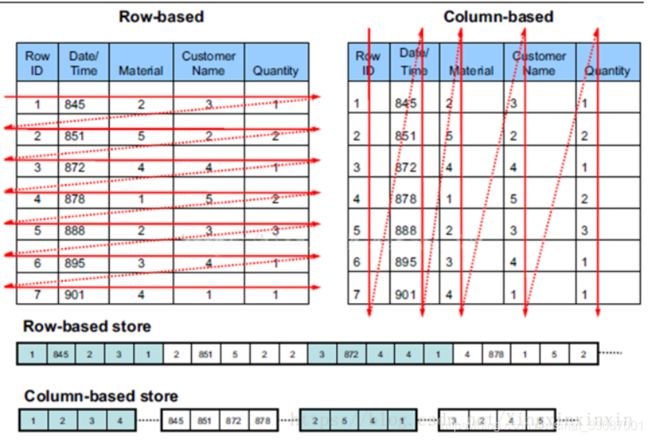
行式存储下一张表的数据都是放在一起的,但列式存储下都被分开保存了。那么问题来了,为什么我们要按列模式组织数据呢?这个就需要按照性能对比和需求来源来讲了。简单来说,如果我们需要读取一条记录信息,那么按照行存储模式从磁盘里找到偏移量然后进行连续读取就可以了,但是如果有一种聚合计算的场景,例如说我们想把上表中的Quantity做sum计算:
- 如果要按照行存储模式,就需要将数据全部读到磁盘【大量IO】并且进行筛选,取出所有Quantity数据然后求和,那么这样势必增加了IO的开销和降低查询速率;
- 如果要按照列存储模式,那么只需要找到Quantity对应的列的偏移量然后读到磁盘【少量IO】计算就行了。
这只是个简单例子,下边举一个具体的例子来详细区分二者。
与关系型数据库的性能对比
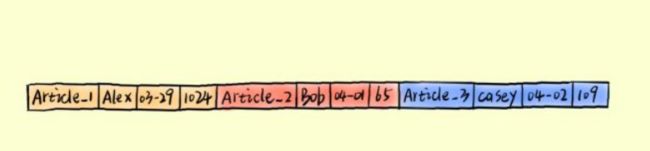
以下部分内容来源于(example来源)对于这样一组数据,我们来分别看看列存储和行存储的使用对比,突出下列存储的优势:
[
{
"author": "Alex",
"publish_time": 1508423456,
"like_num": 1024
},{
"author": "Bob",
"publish_time": 1504423069,
"like_num": 65
},{
"author": "Casey",
"publish_time": 1512523069,
"like_num": 109
}
]
如果想要完成这样一种场景,写入数据到数据库中,并计算所有人的like_num,并且假设磁盘一次读取3个方块。那么操作方式是什么呢?
写入性能对比
首先需要把数据写入到数据库中,这个过程中Row-base模式获胜:
Row-based存储模式写入
如果按照行模式组织的话,应该是如下方式的连续写入磁盘中的:
Column-based存储模式写入
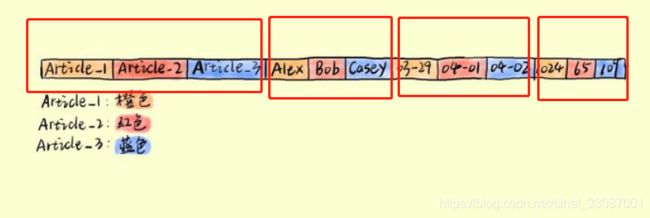
如果按照列模式组织的话,应该是如下方式的连续写入磁盘中的【注意,磁头不一定是连续的】
写入性能对比总结
总体而言,行存储模式在写入的时候速度更快,数据完整性能得到保证。
-
行存储的写入是一次完成。如果这种写入建立在操作系统的文件系统上,可以保证写入过程的成功或者失败,数据的完整性因此可以确定。
-
列存储由于需要把一行记录拆分成单列保存,写入次数明显比行存储多(意味着磁头调度次数多,而磁头调度是需要时间的,一般在1ms~10ms),再加上磁头需要在盘片上移动和定位花费的时间,实际时间消耗会更大。所以,行存储在写入上占有很大的优势。
-
数据修改时:这实际也是一次写入过程。不同的是,数据修改是对磁盘上的记录做删除标记。行存储是在指定位置写入一次,列存储是将磁盘定位到多个列上分别写入,这个过程仍是行存储的列数倍。所以,数据修改也是以行存储占优。
总而言之,写入时行存储模式的关系型数据库更占优。
读取性能对比
按照需求,需要把对应的blog数据的点赞数获取出来进行统计和聚合。
Row-based存储模式读取
Row-based存储模式,在那么读取的时候需要连续取出所有数据,因为为了缩短处理时间,我们一般不会在磁盘里做数据过滤,而是把数据都读到内存里来。
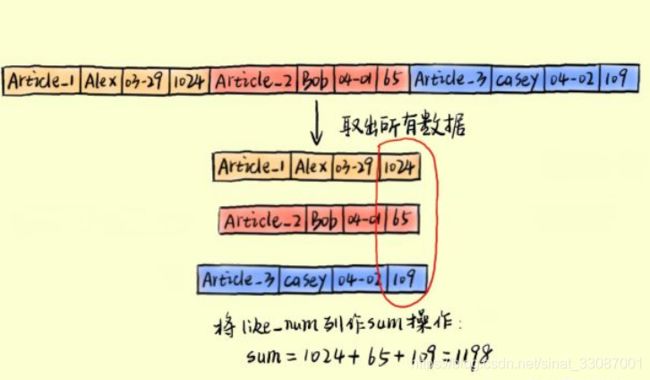
那么行存储模式下,需要进行3次IO读取,然后对like_sum列做计算
Column-based存储模式读取
Column-based存储模式读取的时候只需要一次IO读取即可。
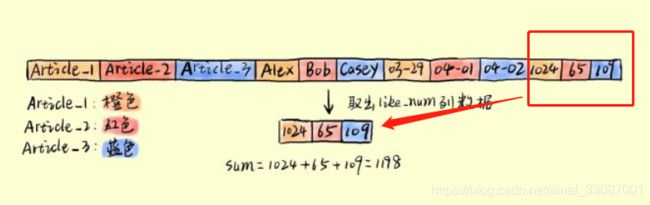
读取性能对比总结
总体而言,行存储模式在读取的时候速度更快,没有数据冗余、容易解析、方便压缩能得到保证。
- 数据读取时,行存储通常将一行数据完全读出,如果只需要其中几列数据的情况,就会存在冗余列,出于缩短处理时间的考量,消除冗余列的过程通常是在内存中进行的。
- 列存储每次读取的数据是集合的一段或者全部,不存在冗余性问题。
- 两种存储的数据分布。由于列存储的每一列数据类型是同质的,不存在二义性问题。比如说某列数据类型为整型(int),那么它的数据集合一定是整型数据。这种情况使数据解析变得十分容易。相比之下,行存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗CPU,增加了解析的时间。所以,列存储的解析过程更有利于分析大数据。
- 从数据的压缩以及更性能的读取来对比,由于同一个数据列的数据重复度很高,因此,列式数据库压缩时有很大的优势
总而言之,读取时列存储模式的关系型数据库更占优。
优缺点及适用场景
综合上边读取和写入的考量,可以综合确定两种模式的优缺点以及他们的适用场景:
行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略;数量大可能会影响到数据的处理效率
- 数据是按行存储的
- 没有索引的查询使用大量I/O。比如一般的数据库表都会建立索引,通过索引加快查询效率
- 建立索引和物化视图需要花费大量的时间和资源
- 面对查询需求,数据库必须被大量膨胀才能满足需求
列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网,犹为重要。
- 数据按列存储,即每一列单独存放
- 数据即索引
- 只访问查询涉及的列,可以大量降低系统I/O
- 每一列由一个线程来处理,即查询的并发处理性能高
- 数据类型一致,数据特征相似,可以高效压缩。比如有增量压缩、前缀压缩算法都是基于列存储的类型定制的,所以可以大幅度提高压缩比,有利于存储和网络输出数据带宽的消耗
这个时候就需要看具体的使用场景了,首先明确两类系统:OLTP和OLAP,他们需要的是不同的数据库。
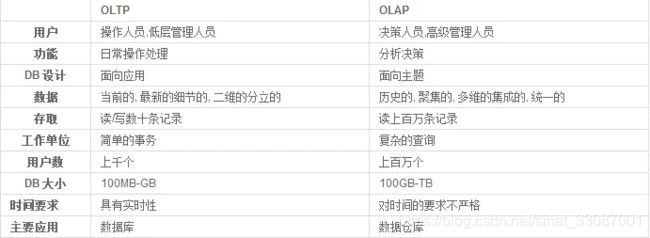
关于二者的区别可以参照这篇文章:
https://www.jianshu.com/p/b1d7ca178691
在OLTP中建议使用传统的关系型数据库,在OLAP中建议使用列式存储的数据仓库,例如Cassandra:
- 一个OLAP类型的查询可能需要访问几百万甚至几十亿个数据行,且该查询往往只关心少数几个数据列。例如,查询今年销量最高的前20个商品,这个查询只关心三个数据列:时间(date)、商品(item)以及销售量(sales amount)。商品的其他数据列,例如商品URL、商品描述、商品所属店铺,等等,对这个查询都是没有意义的。而列式数据库只需要读取存储着“时间、商品、销量”的数据列,而行式数据库需要读取所有的数据列。因此,列式数据库大大地提高了OLAP大数据量查询的效率
了解了需求和存储模式后下篇blog介绍Cassandra的数据结构,看看它是如何在保障列式快速读取的优势下又兼顾写数据的速度。