最近看到了一个比较好的神经网络和深度学习的网站,http://neuralnetworksanddeeplearning.com/,其实也不算是网站,算是Michael Nielsen的书籍电子版,写的算是比较生动简介,我这部分系列的文章算是一个跟书笔记,也算是半吊子翻译和代码注释工,恩,背景介绍到这里(大神直接看原文就行了,可以不用看后面的渣文了)。
没接触神经网络之前,我觉得神经网络非常神奇,各种层次网络结构和之前接触的机器学习有所不同,Michael Nielsen的书写的非常浅显易懂,也让我渐渐明白了,其实神经网络和之前了解的监督机器学习方法并没有本质不同,尽管使用了不同的模型,但是归根到底还是训练参数的过程,而之前机器学习的方法在这里也是可以使用的。当然,神经网络里面有其自身的启发式算法,如BP算法遗传算法等,但这也不算复杂难懂,总之,神经网络之所以难理解我觉得主要在于其训练过程比常见的机器学习方法要稍微复杂一点,但是原理并不是那么难以明白。
跟着Michael Nielsen的书的节奏,开始探秘神经网络
step1:从感知器谈到神经元
最早的神经元是被称之为感知器,在20世纪五六十年代由Frank Rosenblatt发明,看一眼感知器的组成:

简单的说,就是给定一系列二进制序列,x1-x3,输出一个指定的二进制值output,当然这里的输入可多可少,为了举例方便,这里就只是说三个输入,我们给三个输入值各给定一个权重weight,然后取定一个阈值threshold,所以将output定义为:
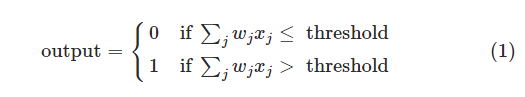
如上面的式子,当权重和输入值的乘积和超过阈值的时候就输出1,反之输出0,这就是感知器全部的工作原理了。也许问题就来了,这玩意儿有啥用,感觉没有任何的有用之处。慢着,其实上面已经算是一个决策机了,其输入是影响因子,权重是影响因子对于结果的重要性,然后阈值决定了做出决定的难易度。下面会有个例子介绍这个玩意儿的有意思之处。
假设你要去参加一个圣诞趴,有三个因素需要考虑:
1,天气是不是好
2,有没有男票(或者女票)一起去
3,交通是不是方便
我们把这三个值设定为x1,x2,x3,当x1=1的时候表示天气是好的,当x1=0的时候表示天气不好,其他两个可以类推:x2=1表示有男票(女票)一起去,x2=1表示没有,x3类似。假如你非常想参加圣诞趴但是非常忌惮天气,你可以将threahold设置为5,w1为6,w2为2,w3为2,这个表示,只要天气好,其他两个因素就都无所谓了,当然你也可以将threshold设置为3,表示如果天气好,或者如果有男票(女票)且交通便利,这两种情况只要发生了一种,就可以去参加了
当然又会有声音出现:这玩意儿我小学就会了,你现在给我算这个干甚?慢着,且慢慢徐来。上面表示这个感知器已经能够做一些基本决定了,而且通过变换权重和阈值我们会有不同的决策系统,这算不上神奇,但是我们可以联想到我们的大脑,一个神经元是个很小的东西,只能靠生物电传递一些电位信息,但是我们人类大脑的数亿计的神经元组合起来就能完成很多复杂的功能。也就是说,当感知器多了之后,我们就相当于有了许多的决策机,当把这么多的决策机组合起来做决策之后,效果是惊人的,这也是神经网络算法的基本思路。
回到感知器身上,为了表述简单,我们将感知器的基本模型改为:
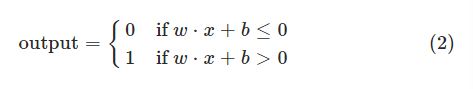
其中b=-threshold,直白的说,b值表示的是这个感知器得到positive(正)的难易程度,如果b是非常大的正值,则表示这个感知器很容易做出positive(也就是得到1)的决策,如果b是非常小的负值,则表示这个感知器很容易做出negetive(也就是0)的决策,后面都会用b来代替threshold,在表述中,也将使用biase(偏移)来表示b
谈了这么久感知器,现在就应该谈到了神经元了,在常见的ANN(人工神经网络)中,使用最多的是sigmoid神经元,那么为什么使用sigmoid神经元而不是使用感知器呢,原因是在训练的过程中,需要反复修改w和b,但是对于感知器而言,由于结果只有两个值(0-1),往往一个小的改动对于整个网络的改动会非常之大,出于平滑的考虑,使用了sigmoid 神经元,其实sigmoid神经元也不算什么稀奇的东西,在logistic回归中,sigmoid函数早就被使用了,首先来看看sigmoid方法是什么,方法定义
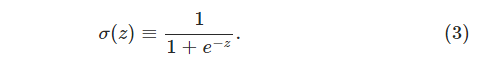
其图形是这样的

从图中容易看出,如果我们把sigmoid函数值小于0.5的定义为0,将大于0.5的函数值定义为1,那么这就和感知器是一样了的,但是sigmoid函数对于细微的参数改变,其函数值改变也是细微的,另外如果w*x+b是非常大的正值的话,那么sigmoid函数值也偏向于1,如果w*x+b值是很小的负值的话那么sigmoid函数是偏向于0的,这些都是我们想要的特性。如此一来,sigmoid神经元的计算方法就变成了:
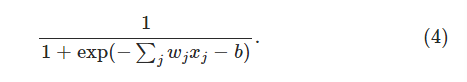
step2:神经网络结构:
有了上面的基础,我们知道sigmoid神经元了,这个是神经网络的基本结构,接下来就可以构建基本简单的神经网络了。

如上图所示,基本的神经网络分为三层,第一层称之为输入层,第二层称之为hidden layer(隐藏层),第三层称之为输出层。需要说明的是
1,输入层虽然也被画成了神经元的样子,但是其实是一个常数(x1,x2,x3...),中间层和输出层都是实在的神经元,也就是带权重因此以及偏移biase
2,输入层和输出层以及中间层的神经元个数都是可以自定义的
3,隐藏层(hidden layer)如图中中间的层,其层数是可以自定义的,中间层越多训练就会越复杂,但是不是说加了中间层就会有好的效果,有时候甚至会相反
4,输出层的个数表示了判别的个数,比如下文要介绍的手写数字识别,那么output层就可以输出为10个数字(0-9)
神经网络训练的过程可以描述为:
1,初始化神经网络参数:包括神经网络的层数,每个层的神经元个数,w,b的初值等(这个过程其实也是相当难,并没有什么原则,比较靠经验)
2,将训练数据输入神经网络,将其输入结果与所希望得到的结果相比较,修改w,b参数以求更好地精度,修改w,b有多种算法可以实现,下文介绍的是比较简单易用的梯度下降法
3,重复2步骤直到精度比较好的结果
其实这么看,神经网络和一般的机器学习方法并没有太大的区别,但是神经网络的妙处就在,经过hidden layer处理了一遍之后,其实hidden layer到output layer的数据已经算是处理过后的了,也就是不是原始数据了,然后对处理后的数据进行训练、会达到不错的效果
下面我们就一个识别手写数字的例子做一个简单的神经网络的实现。
本例子中使用的手写图片数据来自http://yann.lecun.com/exdb/mnist/数据集,每张图片大小是28X28=784,使用其灰度值作为标注,结果输出为0-9的数字。
根据上面的思考,我们可以考虑使用三层神经网络,第一层为输入层,一共784个神经元;第二层是hidden层,我们可以自定义(以15举例),然后输出层是10个神经元,大概结构如下图:

那么这个网络如何得到结果呢,在输入数值之后,结汇相应的得到10个值,如果哪个数值输出最大,那么我们就可以说这个数字识别的结果是这个数值对应的output标签。
网络设计完毕了,现在就应该考虑使用什么方法来进行参数校正了,这里采用的方法是梯度下降法,关于梯度下降法我不想多做介绍,任何一个机器学习或者人工智能的领域这都是基本的方法,简单的说,原理大概可以描述为:调整参数设计,使整体误差最小。梯度下降的方法会将全部的数值都带进去计算,这样会增加计算量,本例中采用了随机梯度下降的方法,也就是每次迭代过程中随机选择一小波数据进行训练。计算方法如下:

在神经网络中,计算梯度下降时使用了BP算法,也就是反向信息传播算法(backpropagation),其实理解backpropagation算法也不算难,不过是一个链式求导法则罢了,推导可参看【1】,里面有详细的公式,关于这个BP算法的举例可以参考【2】,注意【2】中在从后端往前端推导的时候使用了之前的更新值w和b,但是在下面的代码里面,从后往前的推导还是使用最开始的w和b,我觉得Michael(也就是这段代码和这本书的实现者)的考虑是本例子中采用了mini-batch的梯度下降法,每个batch运行完之后才会对w和b进行一次更新,这样可以减小运算量,因为如果每一组数据带入进去都运算一遍的话,运算量还是很大的,当然【3】给我们展示了不一样的BP算法的视角,虽然整个链式法则没有变,但是里面的是为每个layer都计算误差,然后更新的结果是从头往尾更新,这一点和这本书的版本以及网上的一些版本不太一致,读者可以自行评估,当然【3】里面的图示还是很清晰的。
具体代码实现如下
# -*- coding: cp936 -*-
"""
network.py
author: Michael Nielsen
note by luchi
date:2016-1-3
~~~~~~~~~~
A module to implement the stochastic gradient descent learning
algorithm for a feedforward neural network. Gradients are calculated
using backpropagation. Note that I have focused on making the code
simple, easily readable, and easily modifiable. It is not optimized,
and omits many desirable features.
"""
#### Libraries
# Standard library
import random
# Third-party libraries
import numpy as np
class Network(object):
def __init__(self, sizes):
""" 初始化神经网络,sizes输入格式为【第一层的神经元个数,第二层的神经元个数,第三个神经元】
的个数】biase为每个神经元的偏移量,weight是神经元的权重数组"""
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]
def feedforward(self, a):
""" 计算神经网络的输出值,np.dot表示矩阵点乘 """
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a)+b)
return a
def SGD(self, training_data, epochs, mini_batch_size, eta,
test_data=None):
"""使用堆积梯度下降法训练神经网络的主要方法,训练数据集的格式是(x,y)其中x是输入\
y是训练数据的标签,需要说明的是x是一个784维度数组"""
if test_data: n_test = len(test_data)
n = len(training_data)
for j in xrange(epochs):
random.shuffle(training_data)
mini_batches = [
training_data[k:k+mini_batch_size]
for k in xrange(0, n, mini_batch_size)]
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)
if test_data:
print "Epoch {0}: {1} / {2}".format(
j, self.evaluate(test_data), n_test)
else:
print "Epoch {0} complete".format(j)
def update_mini_batch(self, mini_batch, eta):
"""随机梯度下降法,主要使用了self.backprop,也就是BP算法计算每个w和b的梯度值"""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]
def backprop(self, x, y):
"""返回梯度值(nable_b,nable_w)表示C-x的梯度值,可以看做是cost函数对w,b的求导结果"""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# feedforward
activation = x
activations = [x] # list to store all the activations, layer by layer
zs = [] # list to store all the z vectors, layer by layer
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# backward pass
delta = self.cost_derivative(activations[-1], y) * \
sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
# Note that the variable l in the loop below is used a little
# differently to the notation in Chapter 2 of the book. Here,
# l = 1 means the last layer of neurons, l = 2 is the
# second-last layer, and so on. It's a renumbering of the
# scheme in the book, used here to take advantage of the fact
# that Python can use negative indices in lists.
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)
def evaluate(self, test_data):
"""测试数据的正确性"""
test_results = [(np.argmax(self.feedforward(x)), y)
for (x, y) in test_data]
return sum(int(x == y) for (x, y) in test_results)
def cost_derivative(self, output_activations, y):
"""返回cost值,也就是计算出的值和想要得到的结果的值"""
return (output_activations-y)
#### Miscellaneous functions
def sigmoid(z):
"""sigmoid方法"""
return 1.0/(1.0+np.exp(-z))
def sigmoid_prime(z):
"""sigmoid的求导."""
return sigmoid(z)*(1-sigmoid(z))
测试结果如下如下:
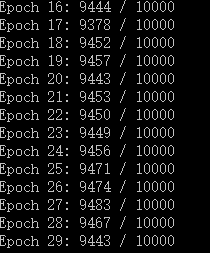
课件识别率是非常之高的。代码其中的BP算法没有做详细介绍, 下次肚子墨水多点之后再看看吧
全部的代码和数据见下面链接:http://pan.baidu.com/s/1qWRNgJy
参考文献:
【1】BP算法 http://blog.csdn.net/zhouchengyunew/article/details/6267193
【2】BP算法浅谈 http://blog.csdn.net/pennyliang/article/details/6695355
【3】图解神经网络 http://techeffigytutorials.blogspot.co.uk/2015/01/neural-network-illustrated-step-by-step.html