TensorFlow笔记之MNIST例程详解
MNIST被称为这方面的HelloWorld,此程序修改自github
程序如下
# -*- coding:utf-8 -*-
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
dir='/home/kaka/Documents/input_data'
# 1.Import data
mnist = input_data.read_data_sets(dir, one_hot=True)
#Print the shape of mist
print (mnist.train.images.shape,mnist.train.labels.shape)
print(mnist.test.images.shape, mnist.train.labels.shape)
print(mnist.validation.images.shape, mnist.validation.labels.shape)
# 2.Create the model
# y=wx+b
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.matmul(x, W) + b
# Define loss and optimizer
y_ = tf.placeholder(tf.float32, [None, 10])
# The raw formulation of cross-entropy,
#
# tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(tf.nn.softmax(y)),
# reduction_indices=[1]))
#
# can be numerically unstable.
#
# So here we use tf.nn.softmax_cross_entropy_with_logits on the raw
# outputs of 'y', and then average across the batch.
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
# Init model
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
# Train
for i in range(100000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
if(i%10000==0):
print(i)
# Test trained model
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images,
y_: mnist.test.labels}))整个程序分为一下几个部分:
1.导入tensorflow包
值得注意的是
from tensorflow.examples.tutorials.mnist import input_data里面包含了一些输入的方法
2.导入数据
mnist = input_data.read_data_sets(dir, one_hot=True)来看看read_data_sets()的定义
def read_data_sets(train_dir,
fake_data=False,
one_hot=False,
dtype=dtypes.float32,
reshape=True,
validation_size=5000,
seed=None):
if fake_data:
def fake():
return DataSet(
[], [], fake_data=True, one_hot=one_hot, dtype=dtype, seed=seed)
train = fake()
validation = fake()
test = fake()
return base.Datasets(train=train, validation=validation, test=test)
TRAIN_IMAGES = 'train-images-idx3-ubyte.gz'
TRAIN_LABELS = 'train-labels-idx1-ubyte.gz'
TEST_IMAGES = 't10k-images-idx3-ubyte.gz'
TEST_LABELS = 't10k-labels-idx1-ubyte.gz'
local_file = base.maybe_download(TRAIN_IMAGES, train_dir,
SOURCE_URL + TRAIN_IMAGES)
with open(local_file, 'rb') as f:
train_images = extract_images(f)
local_file = base.maybe_download(TRAIN_LABELS, train_dir,
SOURCE_URL + TRAIN_LABELS)
with open(local_file, 'rb') as f:
train_labels = extract_labels(f, one_hot=one_hot)
local_file = base.maybe_download(TEST_IMAGES, train_dir,
SOURCE_URL + TEST_IMAGES)
with open(local_file, 'rb') as f:
test_images = extract_images(f)
local_file = base.maybe_download(TEST_LABELS, train_dir,
SOURCE_URL + TEST_LABELS)
with open(local_file, 'rb') as f:
test_labels = extract_labels(f, one_hot=one_hot)
if not 0 <= validation_size <= len(train_images):
raise ValueError(
'Validation size should be between 0 and {}. Received: {}.'
.format(len(train_images), validation_size))
validation_images = train_images[:validation_size]
validation_labels = train_labels[:validation_size]
train_images = train_images[validation_size:]
train_labels = train_labels[validation_size:]
train = DataSet(
train_images, train_labels, dtype=dtype, reshape=reshape, seed=seed)
validation = DataSet(
validation_images,
validation_labels,
dtype=dtype,
reshape=reshape,
seed=seed)
test = DataSet(
test_images, test_labels, dtype=dtype, reshape=reshape, seed=seed)
return base.Datasets(train=train, validation=validation, test=test)大致过程就是,检查目录下有没有想要的数据,没有的话下载,然后进行解压,返回一个Datasets包含train, validation, test
mnist数据如下
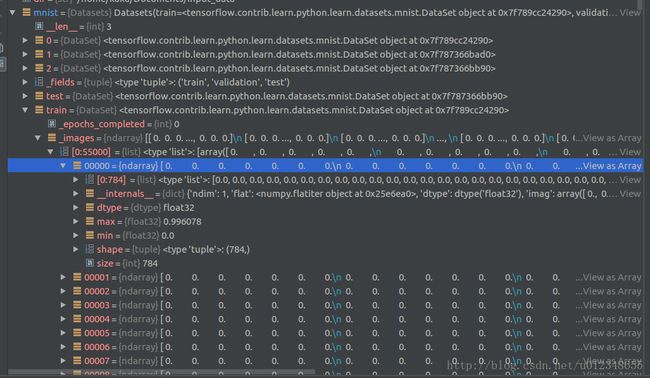
可以看出mnist包含三个数据集,其中train有55000条数据,其每条数据为28*28的图片转换成以为数组并归一化的数据。
3.定义模型
# Create the model
# y=wx+b
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.matmul(x, W) + bwx相乘如图所示,然后对结果的每一列加上一个偏执bi。
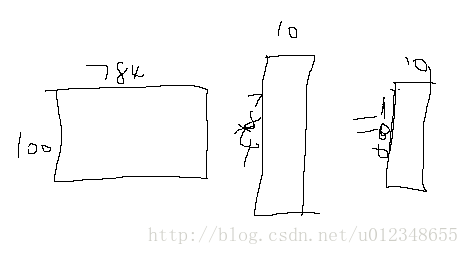
4.设置优化方法
# Define loss and optimizer
y_ = tf.placeholder(tf.float32, [None, 10])
# The raw formulation of cross-entropy,
#
# tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(tf.nn.softmax(y)),
# reduction_indices=[1]))
#
# can be numerically unstable.
#
# So here we use tf.nn.softmax_cross_entropy_with_logits on the raw
# outputs of 'y', and then average across the batch.
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)4.1 y_用于存储误差。
4.2 计算平均交叉熵
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))这里面的操作包括
1.对某一张图片的输出作softmax
关于softmax有一个很形象的图片:

然后根据公式 计算交叉熵
计算交叉熵
2.交叉熵函数,![]() 表示真实值,yi为预测值,label为有十个元素的一维数组,属于某一类,某个值就为1,-log函数的特性为,越接近0数值越大,越接近1,数值越小。然后对所有元素的值进行相加,在计算中使用的loss为交叉熵的平均值。此部分更多详见
表示真实值,yi为预测值,label为有十个元素的一维数组,属于某一类,某个值就为1,-log函数的特性为,越接近0数值越大,越接近1,数值越小。然后对所有元素的值进行相加,在计算中使用的loss为交叉熵的平均值。此部分更多详见
5.初始化模型
# Init model
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()新版本使用global_variables_initializer().run()来对数据进行初始化
6.训练模型
# Train
for i in range(100000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
if(i%10000==0):
print(i)训练时选择100个数据为一组输入
这里选择了100000次训练= =
#####7.评估模型
# Test trained model
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images,
y_: mnist.test.labels}))correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))可以看做一个比较预测值和真实值的函数,如果相等,则返回1
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))用计算准确度函数代替上面的优化方法。
计算输出。