用Python分析淘宝用户行为
数据来源:
阿里云 天池数据集https://tianchi.aliyun.com/dataset/dataDetail?dataId=46
阿里巴巴提供的移动端淘宝用户的行为数据集,包含2014-11-18至2014-12-18共计一千多万条数据。
数据集的每一列描述如下:
| 列名 | 说明 |
|---|---|
| user_id | 用户身份(脱敏) |
| item_id | 商品id(脱敏) |
| behavior_type | 用户行为类型(点击,收藏,加入购物车,购买) 对应数字1,2,3,4 |
| user_geohash | 地理位置 |
| item_category | 商品类别ID |
| time | 用户行为发生时间 |
分析思路如下:
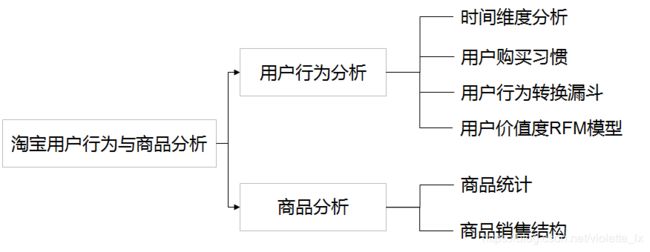
根据分析结果做出以下判断:
- PV、UV和平均访问深度都存在周期性的变化,在每周的周五会出现波谷,PV的波峰出现在每周六,UV无明显波峰。
- 从10号开始PV和UV逐渐上升,在12日当天都达到顶峰,然后回落。在10-12日,用户搜索、加购行为较往日有所增加,而购买行为在12日当天明显增加,是平时购买量的三倍左右。
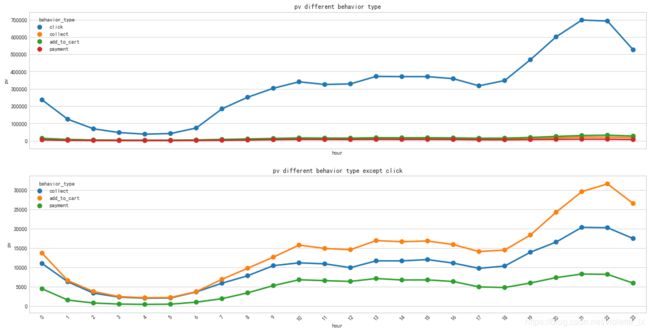
- 用户工作日和周末的使用时间较为相似,都集中在18:00-23:00,在21:00-22:00区间内达到最高值,但用户在周末午间的用户行为略微少于工作日。
- 大部分用户的日均消费次数在10次以内,约一半的用户日均消费次数集中在0.66-2.67次,双十二当天用户日均消费次数明显增加。
- 用户付费率达到88.86%,用户复购率为91.45%,需要结合更多数据进一步分析未付费用户的流失节点。
- 双十二当天的ARPPU约为日常的 2倍,活动结束后应做好活跃用户的引流,保持用户增长。
- PV—收藏行为的转化率为4.46%,PV-加购行为的转化率4.46%,收藏加购—购买行为的转化率为19.27%。由于用户浏览-收藏加购这部分转化率较低,需要更多的用户行为埋点数据进一步分析咨询、收藏、加购、直接购买、下单和支付步骤的转化率指标。
- 根据最近一次消费时间和消费频率得到的RFM用户模型,可以结合用户画像进行精细化运营。如重点关注RF评分都高的重要价值用户,针对R高F低的重要发展用户发放优惠券、举办活动等增加用户粘性。
- 高点击量的产品,如点击量最高的产品209323160的加购和收藏量都很高,但销量并不在前十。而销量最高的产品,点击、加购、收藏都不再前十榜单中。需要结合具体的商品类别和用户行为数据进一步分析,增加高曝光产品的购买转化率,提高销量高产品的宣传。
- 在不同的时间点和不同的日期,商品销量具有不同的表现,可进一步对时间和活动进行商品挖掘,更加精细化地投放商品广告。
- 根据帕累托分析,45.04%的商品实现了80%的销量。可以针对头部商品和长尾效应进一步精细化商品运营。
运营建议和反馈:
- 确认是否有需求提高周五的数值,需要对周五PV、访问深度降低的情况进一步探究变化原因。
- 11.28,11.29日的UV明显偏低,确认是否有业务活动或竞品的影响,需要结合前期更多的数据挖掘异常原因。
- 需要重点关注双十二拉新用户后续的留存和转化,关注活动的长期效应。
- 根据用户活动时间点,可以选择PV较高的时间段(18:00~23:00)推送广告或者活动,针对不同时间点核心购买人群推送不同的商品。
- 用户点击、加购、收藏行为在12.12活动前两天呈明显上升趋势,建议前2-3天开始活动预热刺激搜索加购,活动当天重点刺激购买行为。
- 用户行为数据指标不足,考虑是否增加埋点,根据对标竞品的各步骤的转化率衡量产品个步骤转化率的情况。
- 可以根据双十二当天成交数据,挖掘平时销量低但活动期间销量高的商品种类,如3064、13230、5894等商品,在活动期间重点销售。
数据预处理
#导入需要的包
import pandas as pd
import datetime
import matplotlib.pyplot as plt
import matplotlib.dates as mdate
import seaborn as sns
#读取数据并粗略观察
df=pd.read_csv(r'D:\数据分析\数据分析\tianchi\taobao.csv',engine='python')
#路径有中文,选择python engine
print(df.info())
print(df.head())
#按照时间保留一周的数据
df['time']=pd.to_datetime(df['time'],format='%Y-%m-%d')
t1=datetime.datetime(2014,12,8)
t2=datetime.datetime(2014,12,15)
mask=(df['time']>t1)&(df['time']经过日期筛选和数据标准化,最终得到8164040条数据,各列的数据类型和数据格式如下:

用户行为分析
一、时间维度分析
1、流量指标
(1) PV、UV环比增长
PV:页面浏览量,全部用户在24小时内看了多少页面,用户每打开一个页面就记做一次,多次打开同一页面算作多次。这里我们将用户所有的操作(click, collect, add to cart,payment)次数进行求和,按照日期统计作为当日的PV值。
UV:独立访客,24小时内访问网站的用户数,同一个人多次访问也算一个,通过访问的客户端计算。我们通过用户唯一标志user_id进行计数求和,按照日期通知作为当日的UV值。
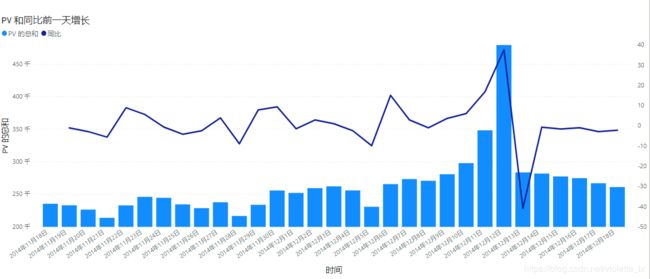
条形图反映了每天的PV值,折线图为环比昨日PV的值:(今日PV-昨日PV)/昨日PV,UV同理。
从周期性分析,PV和UV值都存在周期性的波动以周为统计周期,PV在11.21,11.28,12.5这三个周五都呈现波谷,而11.23,11.30,12.7这三个周日都为一周内的PV最高峰。但UV的情况有所不同,UV在11.22,11.28,11.29,12.5这四天,呈现周期内的波谷。结合访问深度(PV/UV)的数据来看,11.21,11.28,12.5三个周五也都呈现周期性最低点。需要结合更长的时间线分析整体趋势是否存在这样的周期性变化,如果存在变化背后的原因是什么,可具体分析周五活跃用户和不活跃用户之间的区别,并结合商品进行分析,看是否需要提高周五的活跃用户数量。观察异常情况,环比昨日,同比上周分析,11.28,11.29日的UV明显偏低,需要结合当时的业务表现再具体探索。
在11.21日出现PV周期性减少,UV小幅波动,而访问深度明显降低的情况

(2)平均访问深度(PV/UV)

(3)PV、UV及同比增长
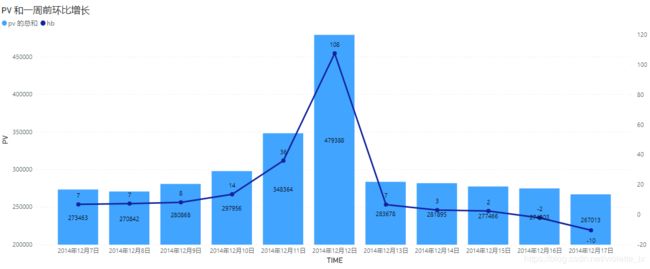
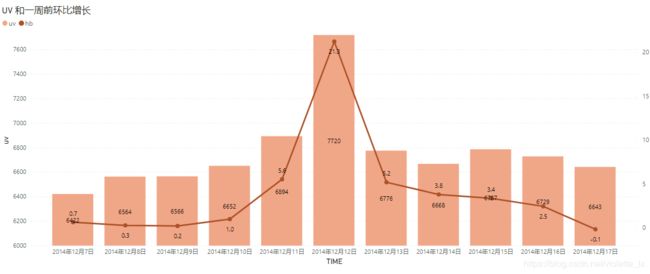
以一周为时间周期,比较双十二活动前后5天的PV和UV环比变化。 由下图可知,双十二活动前后PV和UV的总体波动趋势相似,从10号开始有明显的增幅,在12日PV和UV都达到顶峰,然后回落,双十二活动明显促进UV、PV增长。
#UV
uv_daily=df.groupby('time')['user_id'].apply(lambda x:x.drop_duplicates().count())
uv_daily=uv_daily.reset_index().rename(columns={'user_id':'uv'})
uv_daily.set_index('time',inplace=True)
#同比
uv_daily['uv_lastday']=uv_daily.shift(1)
uv_daily['tb']=100*(uv_daily['uv']-uv_daily['uv_lastday'])/uv_daily['uv_lastday']
formater="{0:.02f}".format
uv_daily['tb']=uv_daily['tb'].map(formater).astype('float')
#环比
uv_daily['uv_7days']=uv_daily['uv'].shift(7)
uv_daily['hb']=100*(uv_daily['uv']-uv_daily['uv_7days'])/uv_daily['uv_7days']
formater="{0:.02f}".format
uv_daily['hb']=uv_daily['hb'].map(formater).astype('float')
#PV
pv_daily=df.groupby('time')['user_id'].count()
pv_daily=pv_daily.reset_index().rename(columns={'user_id':'pv'})
pv_daily.set_index('time',inplace=True)
pv_daily['pv_lastday']=pv_daily.shift(1)
pv_daily['tb']=100*(pv_daily['pv']-pv_daily['pv_lastday'])/pv_daily['pv_lastday']
formater="{0:.02f}".format
pv_daily['tb']=pv_daily['tb'].map(formater).astype('float')
pv_daily['pv_7days']=pv_daily.pv.shift(7)
pv_daily['hb']=100*(pv_daily['pv']-pv_daily['pv_7days'])/pv_daily['pv_7days']
formater="{0:.02f}".format
pv_daily['hb']=pv_daily['hb'].map(formater).astype('float')
pv_daily(4)基于PV分析用户行为
由用户行为的日期折线图可以看出,用户行为也具有周期性特点,在11.21,11.28,12.5这三个周五都是一周内的最低值,12月10日至12月12日,用户点击量、收藏量、加购量都明显增长,在12月12日达到最大值,而购买量则在12月12日当日大幅度增加。
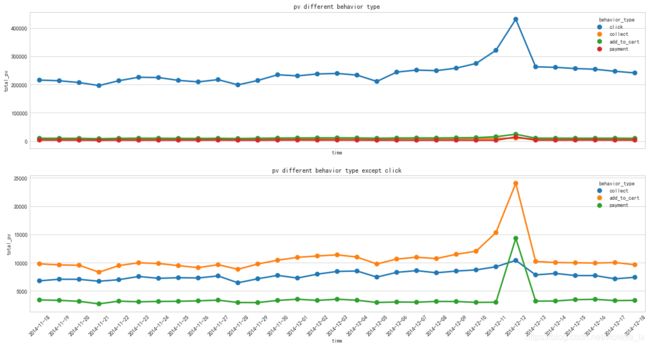
data=df
#按照日期和用户行为进行分组
pv_detail=data.groupby(['behavior_type','time'])['user_id'].count()
pv_detail=pv_detail.reset_index().rename(columns={'user_id':'total_pv'})
pv_detail['time']=pv_detail['time'].dt.strftime('%Y-%m-%d')
pv_detail['behavior_type']=pv_detail['behavior_type'].map({1:'click',2:'collect',3:'add_to_cart',4:'payment'})
#可视化
fig,axes=plt.subplots(2,1,sharex=True,figsize=(20,10))
sns.pointplot(x='time',y='total_pv',hue='behavior_type',data=pv_detail,ax=axes[0])
sns.pointplot(x='time',y='total_pv',hue='behavior_type',data=pv_detail[pv_detail.behavior_type!='click'],ax=axes[1])
axes[0].set_title('pv different behavior type')
axes[1].set_title('pv different behavior type except click')
(5)用户使用时间分析
按照工作日与周末分别计算用户行为发生时段,并通过归一化进行比较,由图可知:
用户行为主要发生在19:00-23:00,在18:00-22:00存在上升期,在21:00-22:00左右达到峰值。工作日与周末用户行为发生时段基本一致,但与工作日相比,周末用户在上午7:00-9:00的浏览相对高一些,在12:00-13:00区间浏览量相对较少,在18:00以后则基本保持一致。这可能是由于周末用户可选择网购的时间比较充沛,会在中午进行其他活动导致午间用户行为降低。
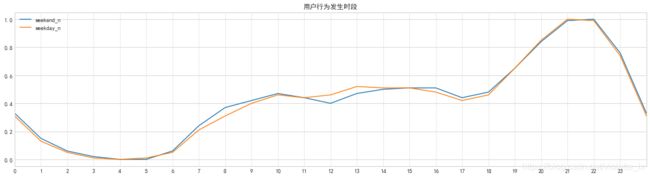
按照一天的24小时划分,可以发现用户晚上的支付PV略微高于白天,但白天的点击-支付的转化率会高于夜间(需要排除白天的购买行为是由白天的点击转化,而非晚间的),针对这种情况可以从商品角度提取不同时段高销量高转化的产品,测试是否分时段投放更有效。
#生成工作日时间序列
day=pd.bdate_range('20141118','20141218')
#周末用户行为~表示取非
data_time=data[~data['time'].isin(day)].groupby('hour').user_id.count()
data_time=data_time.reset_index().rename(columns={'user_id':'weekend'})
#工作日用户行为
data_time['weekday']=data[data['time'].isin(day)].groupby('hour').user_id.count()
#归一化函数 可以调用sklearn里面的
def data_norm(df,*cols):
df_n=df.copy()
for col in cols:
h=df_n[col].max()
l=df_n[col].min()
df_n[col + '_n']=round((df_n[col]-l)/(h-l),2)
return df_n
#归一化
data_time_z = data_norm(data_time,'weekend','weekday')
data_time_z.loc[24]=data_time_z.loc[0]
#画图
data_time_z[['weekend_n','weekday_n']].plot(xlim=[0,24],xticks=list(range(0,24,1)),figsize=(20,5),title='用户行为发生时段')
plt.grid(False, linestyle = "--",color = "gray", linewidth = 0.5,axis = 'x',alpha=0.5)#网格线
2、转化指标
(1)新增用户留存分析
新增用户留存率:首次使用后第N天内有使用行为的用户/首次登录日的用户

(2)活跃用户留存分析
活跃用户留存率:首次购买后第N天内重复购买行为的用户/首次购买日期的用户
重点关注12.12拉新得到的用户的次日留存和三日留存,发现次日留存和三日留存都低于平均值,需要再根据这一部分的用户行为和商品情况进行进一步的分析,关注活动拉新用户的留存问题。

#n日转化率函数
#定义为第i天购买过的用户 在第i-n天内产生过购买行为
import warnings
warnings.filterwarnings('ignore')
def cal_PRretention(data,n): #n为n日留存
user=[]
data=data[data['behavior_type']==4]
date=pd.Series(data.time.unique()).sort_values()[:-n] #时间截取至最后一天的前n天
retention_rates=[]
for i in date:
new_user=set(data[data.time==i].user_id.unique())-set(user) #识别新用户,将最初用户设定为0
user.extend(new_user) #将新用户加入用户群中
#第n天留存情况
user_nday=data[data.time<=i+timedelta(n)][data.time>i].user_id.unique() #第n天登录的用户情况
a=0
for user_id in user_nday:
if user_id in new_user:
a+=1
retention_rate=a/len(new_user) #计算该天第n日留存率
retention_rates.append(retention_rate) #汇总n日留存数据
data_retention=pd.Series(retention_rates,index=date)
return data_retention
PR7=cal_PRretention(df,7)
PR3=cal_PRretention(df,3)
PR1=cal_PRretention(df,1)
PR=pd.concat([PR1,PR3,PR7],axis=1)
PR=PR.rename(columns={0:'次日留存',1:'三日留存',2:'七日留存'})
PR.plot(style = '--.',alpha = 0.8,grid = True,figsize = (15,10),
subplots = True,#是否分别绘制子图,False则绘制在一张图上
layout = (3,1),#更改子图布局,按顺序填充
sharex = False)#是否共享坐标二、用户消费习惯分析
(1)日均消费次数分析
对产生过购买行为的用户分析日均消费可知,绝大多数用户日均消费次数在10次以下,一半的用户日均消费次数集中在0.66-2.67次,存在极少量的用户最高日均消费次数达到126次。
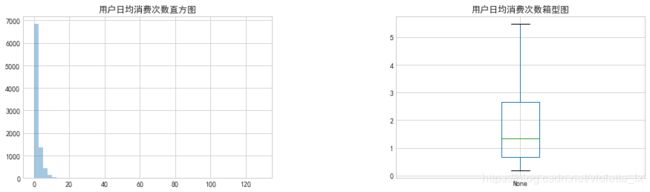
双十二当天用户消费次数直方图和箱型图,可以看出双十二当天用户消费次数集中在1-4次,存在小部分用户当日消费次数超过20次。
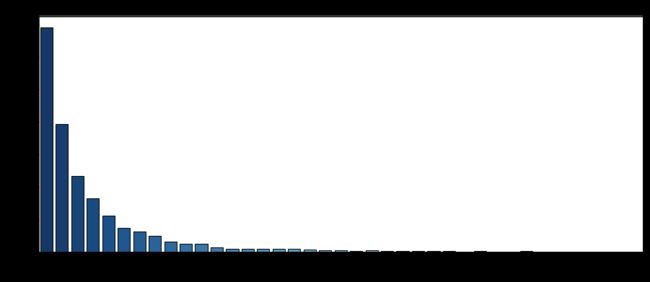
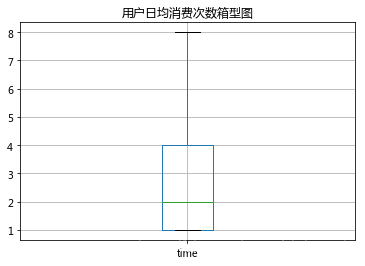
#用户日均消费次数分析(总次数/消费天数)
data_user_buy=data[data.behavior_type==4].groupby('user_id')
data_user_buy=data_user_buy.apply(lambda x:x.behavior_type.count()/len(x.drop_duplicates(subset='time').count()))
fig=plt.figure(figsize=(10,3))
plt.subplots_adjust(wspace=0.5,hspace=0)
ax1=fig.add_subplot(121)
sns.distplot(data_user_buy,kde=False,ax=ax1)
plt.title('用户日均消费次数直方图')
ax2=fig.add_subplot(122)
data_user_buy.plot.box(grid=True,showfliers = False,ax=ax2)
plt.title('用户日均消费次数箱型图')
#双十二当天
data_user_buy=data[(data.behavior_type==4)&(data.time=='20141212')].groupby('user_id').count()
plt.figure(figsize=(15,6))
sns.countplot(x='time',data=data_user_buy,palette='Blues_r')
plt.xlabel('消费次数')
plt.ylabel('用户数量')
plt.title('用户双十二当天消费次数')(2)ARPPU
ARPU:一个时间段内运营商从每个用户所得到的的收入
ARPPU:平均用户收入,平均每付费用户收入
因为数据集没有订单金额,所以用消费总次数/总消费人数来表示ARPPU,可以发现除12月12日当天,每位用户的日均消费次数集中在2-2.2之间波动,在12日当天达到峰值约3.7次。
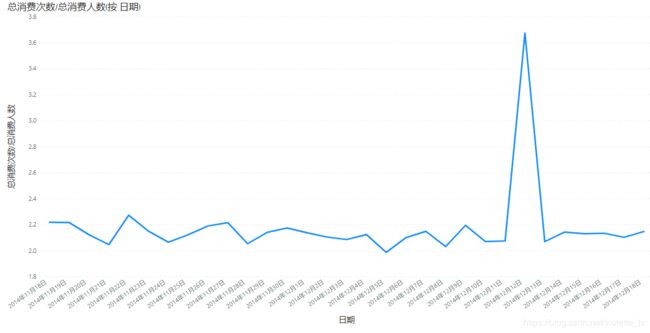
(3)用户复购率
复购率:重复购买客户数量/客户样本数量,复购率91.45%说明用户黏性非常好,绝大多数付费用户产生重复购买情况。
#用户复购情况(一天多次购买也算重复购买)
#重复购买用户总数/总消费人数
date_rp=data[data.behavior_type==4].groupby('user_id').count()['behavior_type']#['time'].apply(lambda x:len(x.unique()))
x=date_rp[date_rp>=2].count()
print('repeat purchase:%.2f%%'%(date_rp[date_rp>=2].count()/date_rp.count()*100))(4)用户付费率
用户付费率:产生购买行为的用户/所有用户,用户付费率为88.86%,用户付费比率很高,说明用户转化比较好。
user_count=len(data.user_id.unique())
buyuser_count=len(data[data.behavior_type==4].user_id.unique())
print('afford_rate %.2f%%' %(100*buyuser_count/user_count))
三、用户行为转换漏斗
将加购和收藏作为点击与购买的中间层次,统计用户点击、加购收藏、购买的每一层转换率。点击到加购的转换率为4.46%,到收藏的转换率为3.22%。可以通过购物推荐算法优化搜索引擎等方式帮助用户更好找到所需商品。从用户加入购物车和收藏夹到用户购买的转换率为19.27%,可以通过发送提醒,加购收藏有礼等活动提高这一层的转换率。
但实际用户可以不通过加购和收藏环节直接进行购买,这个转换率的分析不是很准确。如进一步分析,应分析加购后购买,收藏后购买,直接由点击转换购买三部分的转换率。

一个更合理的转化过程如图所示,从咨询、收藏、加购、直接购买等方式来分析转化率,成交转化率可以再精细化分为类目、品牌、单品、渠道、事件等转化率。(图片思路来自《数据化管理》,这本书写零售和电商写的很详细啊!)
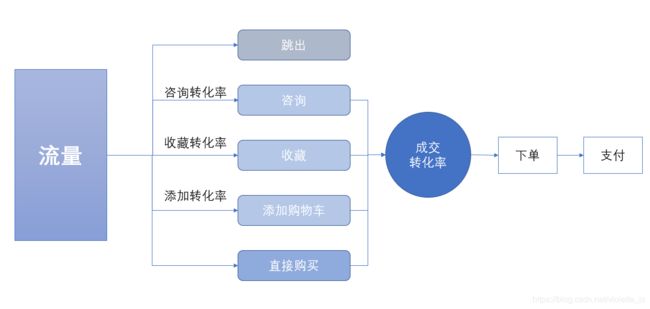
五、用户价值度RFM模型分析
RFM分析是根据客户活跃程度和交易金额的贡献,进行客户价值细分的方法。具体参见:http://www.woshipm.com/data-analysis/708326.html
- R(Recency):客户最近一次交易时间的间隔。
- F(Frequency):客户在最近一段时间内交易的次数。
- M(Monetary):客户在最近一段时间内交易的金额。
因为缺少交易金额,提取交易总次数作为F参数,距离12-15日的消费时间间隔为R值,F值越大说明用户交易越频繁,R值越大说明用户发生交易的时间越近
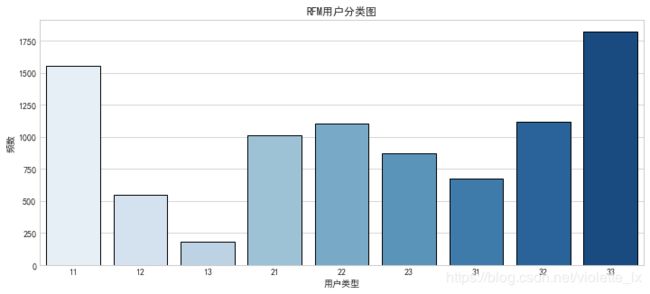
由联合分布图可以看出用户消费频次集中在0-100次的区间,消费间隔主要为10天以内。按照用户数量均匀分为1-3类,用户类型的第一个数值表示R值,R值越大,表示客户交易发生的日期越近,第二个数值为F值,F值越大,表示客户交易越频繁。在RFM用户分类中,33对应的用户消费时间近、消费频次高,是高价值的用户。13对应的用户是消费时间远,消费频次高的用户,是重点保持的用户。
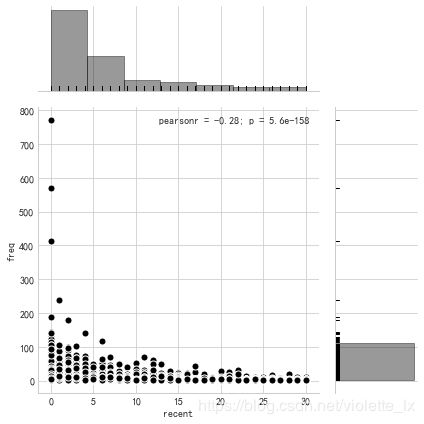
datenow=datetime.datetime(2014,12,15)
#每位用户最近购买时间
recent_buy_time=data[data.behavior_type==4].groupby('user_id').time.apply(lambda x:datenow-x.sort_values().iloc[-1])
recent_buy_time=recent_buy_time.reset_index().rename(columns={'time':'recent'})
recent_buy_time.recent=recent_buy_time.recent.map(lambda x:x.days)
# #每个用户消费频数
buy_freq=data[data.behavior_type==4].groupby('user_id').time.count().reset_index().rename(columns={'time':'freq'})
rfm=pd.merge(recent_buy_time,buy_freq,left_on='user_id',right_on='user_id',how='outer')
# recent表示距离上次购买间隔天数,数值越小越好,因此较小数值赋值3(更重要)
rfm['R_value']=pd.qcut(rfm.recent,3,labels=['3','2','1'])
# freq表示消费次数,数值越大越好,因此较大数值赋值2(更重要)
rfm['F_value']=pd.qcut(rfm.freq,3,labels=['1','2','3'])
rfm['rfm']=rfm['R_value'].str.cat(rfm['F_value'])#str.cat拼接字符串
rfm.head()
#绘制联合分布图
plt.rcParams["patch.force_edgecolor"] = True
sns.jointplot(x=rfm['recent'],y=rfm['freq'],#x轴 y轴
data=rfm,#设置数据
color='k',
s=50,edgecolor='w',linewidth=1,#散点大小、边缘、线性
kind='scatter',#kind : {“scatter”|“reg”|“resid”|“kde”|“hex”}
space=0.2,#散点图和布局图间距
size=6,#图表大小
ratio=3,#散点图和布局图高度比
marginal_kws=dict(bins=7,rug=True))#柱状图箱数
#绘制统计直方图
sns.countplot(x='rfm',data=rfm,palette='Blues')
plt.title('RFM用户分类图')
plt.xlabel('用户类型')
plt.ylabel('频数')
商品分析
这一部分我没有再重新更改,是由12.08-12.15之间的数据进行分析。
一、商品统计
(1)商品品类分析

#统计商品品类
data_buy=data[data['behavior_type']==4]
data_category=data_buy.groupby(['item_category']).time.count()
data_category.sort_values(ascending=False,inplace=True)
#统计销量最高商品品类的item_id
max_cat=data_category[:1].index.values
data_item=data_buy[data_buy.item_category.isin(max_cat)].groupby(['item_id']).time.count()
data_item.sort_values(ascending=False,inplace=True)
fig,axes = plt.subplots(1,2,figsize=(20,5))
plt.subplots_adjust(wspace=0.3,hspace=0.3)
plt.subplot(121)
data_category[:10].plot.barh()
plt.title('商品种类销量前十')
plt.subplot(122)
data_item[:10].plot.barh()
plt.title('销量最高种类的十种畅销品')(2)商品的浏览,收藏,加购物车,购买的前十名

#提取数据
data_item=data.groupby(['behavior_type','item_id']).time.count()
data_item=data_item.reset_index().rename(columns={'time':'total_num'})
data_click=data_item[data_item.behavior_type==1].sort_values(by='total_num',ascending=False)[:10].set_index('item_id')
data_collect=data_item[data_item.behavior_type==2].sort_values(by='total_num',ascending=False)[:10].set_index('item_id')
data_cart=data_item[data_item.behavior_type==3].sort_values(by='total_num',ascending=False)[:10].set_index('item_id')
data_pay=data_item[data_item.behavior_type==4].sort_values(by='total_num',ascending=False)[:10].set_index('item_id')
#可视化
fig,axes = plt.subplots(2,2,figsize=(20,10))
plt.subplots_adjust(wspace=0.3,hspace=0.3)
plt.subplot(221)
data_click['total_num'].plot.barh()
plt.title('商品点击量前十')
plt.subplot(222)
data_collect['total_num'].plot.barh()
plt.title('商品收藏量前十')
plt.subplot(223)
data_cart['total_num'].plot.barh()
plt.title('商品加入购物车前十')
plt.subplot(224)
data_pay['total_num'].plot.barh()
plt.title('商品购买量前十')(3) 分时段统计最高销量种类
可以发现在12:00-17:00和17:00-24:00的最高销量的商品存在部分重叠现象,但销量排名不完全相同。可以根据不同的时间段推送当前时间段销量更高的产品,或者从转化率的角度,可以将商品广告安排在转化率较高的时间段。
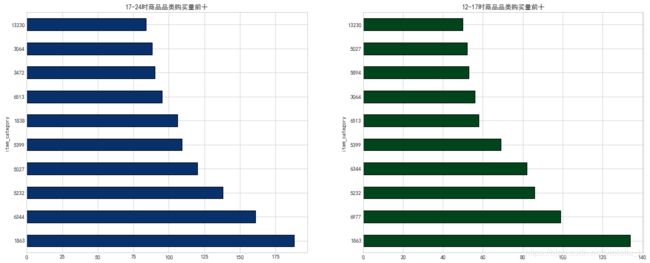
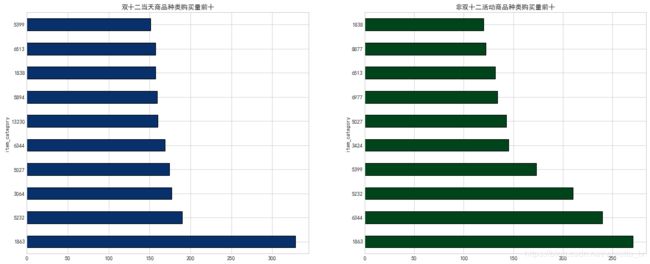
(4)分日期统计最高销量种类
分日期挖掘商品种类,可以发现活动的爆款商品及日常销量不高但活动期间销量较高的商品。比如1863类的产品虽然平时销量也是第一,但双十二当天销量远远超过其他种类,3064类商品日常销量并不在前十,但双十二当天销量排名第三,非常具有爆款潜质。
(3)帕累托分析
对于item_id进行分析发现45.04%的商品实现了80%的销量。
data_pareto=data[data['behavior_type']==4].groupby(['item_id']).time.count()
data_pareto=data_pareto.reset_index().sort_values('time',ascending=False)
p=data_pareto['time'].cumsum()/data_pareto['time'].sum()
key = p[p>0.8].index[0]
print('%.2f%%的商品实现了80%%的销量'%(100*key/data_pareto.shape[0]))二、商品销售结构
这里我将所有商品分为六大类别,随机对每一个category_id分配了一种类别,以此来模拟进行商品类型销售分析。
(1)商品类别销售占比
由分析可知,F类型的商品销量最高占比19%,B类型的商品销量最低占比15%。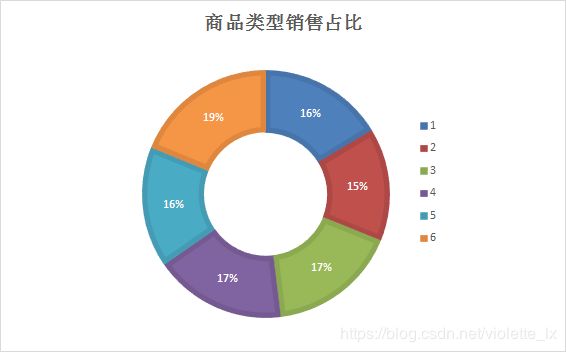
#随机生成类别的标签
cat=data.item_category.unique()
r=np.random.randint(1,7,len(cat))
category=pd.DataFrame({'item_category':cat,'class_id':r})
data_category=pd.merge(category,data,how='inner',on='item_category')
#matplotlib画饼图太丑了 这个我导出到excel画的环形图
data_class=data_category[data_category['behavior_type']==4][['time','class_id','user_id']]
data_class=data_class.groupby('class_id').time.count()
plt.axis('equal') # 保证长宽相等
plt.pie(data_class,
labels = data_class.index,#colors='Blues',
autopct='%.2f%%',
pctdistance=0.6,#越大离中心越远
labeldistance = 1.2,
shadow = True,
startangle=0,
radius=1.5,
frame=False)(2)商品每日销售比例
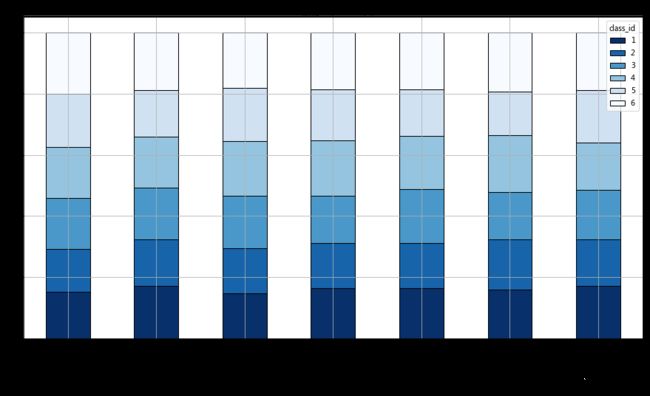
#商品类别堆叠柱状图
day_class=data_category[data_category['behavior_type']==4][['time','class_id','user_id']]
day_class['time']=day_class['time'].apply(lambda x:x.__format__('%Y/%m/%d'))
dc=pd.pivot_table(day_class,values='user_id',index='time',columns='class_id',aggfunc='count')
dc=dc.div(dc.sum(axis=1),axis=0).applymap(lambda x:(100*x))
dc=dc.round(2)
dc.plot(kind='bar',grid=True,colormap='Blues_r',stacked=True,
figsize=(15,8),edgecolor='black',rot='45',title='商品销量堆叠直方图')#stacled=True 堆叠柱状图
end
以下为之前的版本,留在这里作为对比。学习使人进步,找不到工作令人不快乐!!!
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
根据分析结果做出以下判断:
- 从10号开始PV和UV逐渐上升,在12日当天都达到顶峰,然后回落。在10-12日,用户搜索、加购行为较往日有所增加,而购买行为在12日当天明显增加,是平时购买量的三倍左右。
- 用户使用时间集中在18:00-23:00,在21:00-22:00区间内达到最高值,广告投放、活动运营可以集中在这个时间段进行。
- 大部分用户的日均消费次数在10次以内(进一步排除活动影响可比较非活动周数据),双十二当天用户日均消费次数明显增加。
- 用户付费率达到67.72%,七天内用户复购率为75.91%。
- 双十二当天的ARPPU约为日常的 2倍,活动结束后应做好活跃用户的引流,保持用户增长。
- PV—收藏加购行为的转化率为7.53%,收藏加购—购买行为的转化率为2.14%,用户浏览页面行为次数远大于其他行为,需要根据更多的用户行为数据进一步分析各阶段的转化率指标。
- 根据最近一次消费时间和消费频率得到的RFM用户模型,可以结合用户画像进行精细化运营。如重点关注RF评分都高的重要价值用户,针对R高F低的重要发展用户举办活动增加用户粘性等。
- 高点击量的产品,如点击量最高的产品209323160的加购和收藏量都很高,但销量并不在前十。而销量最高的产品,点击、加购、收藏都不再前十榜单中。需要结合具体的商品类别和用户行为数据进一步分析,增加高曝光产品的购买转化率,提高销量高产品的宣传。
- 根据帕累托分析,45.04%的商品实现了80%的销量。可以针对头部用户和长尾效应进一步精细化商品运营。
运营建议:
- 可以选择用户最有购买意愿的时间段(18:00~23:00)推送广告或者活动;
- 用户点击、加购、收藏行为在活动前两天呈明显上升趋势,建议在活动前两天开始各种预热活动,活动当天重点刺激购买行为。
- 可以根据每种商品类别中销量最高的商品重点进行广告投放,进一步刺激购买。
数据预处理
#导入需要的包
import pandas as pd
import datetime
import matplotlib.pyplot as plt
import matplotlib.dates as mdate
import seaborn as sns
#读取数据并粗略观察
df=pd.read_csv(r'D:\数据分析\数据分析\tianchi\taobao.csv',engine='python')
#路径有中文,选择python engine
print(df.info())
print(df.head())
#按照时间保留一周的数据
df['time']=pd.to_datetime(df['time'],format='%Y-%m-%d')
t1=datetime.datetime(2014,12,8)
t2=datetime.datetime(2014,12,15)
mask=(df['time']>t1)&(df['time']经过日期筛选和数据标准化,最终得到8164040条数据,各列的数据类型和数据格式如下:
用户行为分析
一、时间维度分析
(1)按日期统计PV、UV
PV:页面浏览量,全部用户在24小时内看了多少页面,用户每打开一个页面就记做一次,多次打开同一页面算作多次。这里我们将用户所有的操作(click, collect, add to cart,payment)次数进行求和,按照日期统计作为当日的PV值。
UV:独立访客,24小时内访问网站的用户数,同一个人多次访问也算一个,通过访问的客户端计算。我们通过用户唯一标志user_id进行计数求和,按照日期通知作为当日的UV值。
由下图可知,每日的PV和UV的总体波动趋势相似,从9号开始有明显的增幅,在12日PV和UV都达到顶峰。
从7号开始pv和uv开始大幅度攀升,在12号到达最大值,然后回落。如果和之前周报比较能排除周五对数值的影响,可以初步判断双十二活动明显促进UV、PV增长。
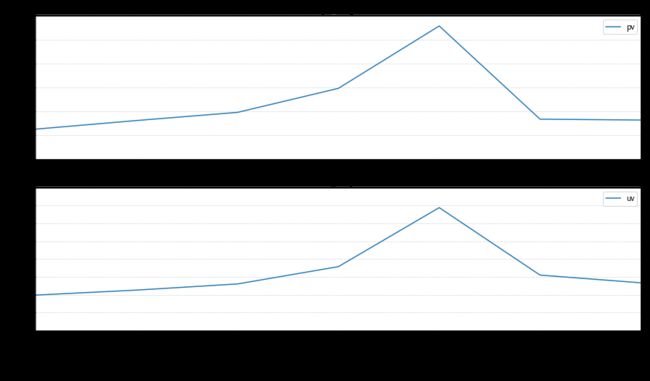
pv_daily=data.groupby('time')['user_id'].count()
pv_daily=pv_daily.reset_index().rename(columns={'user_id':'pv'})
pv_daily.set_index('time',inplace=True)
uv_daily=data.groupby('time')['user_id'].apply(lambda x:x.drop_duplicates().count())
uv_daily=uv_daily.reset_index().rename(columns={'user_id':'uv'})
uv_daily.set_index('time',inplace=True)
fig=plt.figure(figsize=(15,8))
plt.subplots_adjust(wspace=0,hspace=0.2)
ax1=fig.add_subplot(211)
ax1.set_title('pv_daily')
pv_daily.plot(ax=ax1,ylim=[200000,500000])
plt.grid(True, linestyle = "--",color = "gray", linewidth = "0.5",axis = 'y',alpha=0.5)
plt.xlabel('tt')
ax2=plt.subplot(212,sharex=ax1)
ax2.set_title('uv_daily')
uv_daily.plot(ax=ax2,ylim=[6000,8000])
plt.grid(True, linestyle = "--",color = "gray", linewidth = "0.5",axis = 'y',alpha=0.5)#网格线(2)基于PV分析用户行为
由图可以看出,12月10日至12月12日,用户点击量、收藏量、加购量都明显增长,在12月12日达到最大值,而购买量则在12月12日当日大幅度增加。
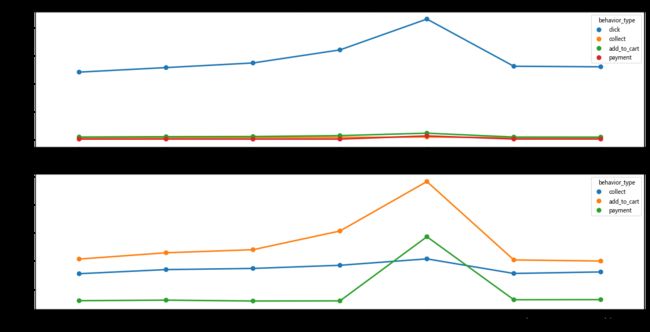
#按照日期和用户行为进行分组
pv_detail=data.groupby(['behavior_type','time'])['user_id'].count()
pv_detail=pv_detail.reset_index().rename(columns={'user_id':'total_pv'})
pv_detail['time']=pv_detail['time'].dt.strftime('%Y-%m-%d')
pv_detail['behavior_type']=pv_detail['behavior_type'].map({1:'click',2:'collect',3:'add_to_cart',4:'payment'})
#可视化
fig,axes=plt.subplots(2,1,sharex=True,figsize=(20,10))
sns.pointplot(x='time',y='total_pv',hue='behavior_type',data=pv_detail,ax=axes[0])
sns.pointplot(x='time',y='total_pv',hue='behavior_type',data=pv_detail[pv_detail.behavior_type!='click'],ax=axes[1])
axes[0].set_title('pv different behavior type')
axes[1].set_title('pv different behavior type except click')
(3)用户使用时间分析
由图可知,用户行为在18:00-22:00存在上升期,在22:00左右达到峰值。
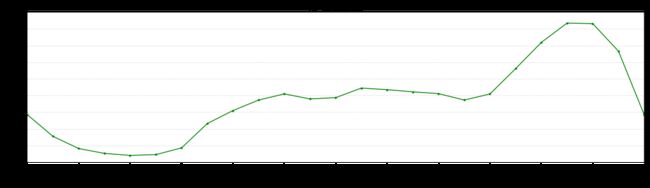
data_time=data.groupby('hour').count()
data_time.loc[24]=data_time.iloc[0].values#为了图片24点有数值
data_time['user_id'].plot(kind='line',style='-g.',rot=45,xlim=[0,24],xticks=list(range(0,24,2)),
figsize=(8,4),title='用户行为发生时段',ylim=[0,225000])#,yticks=list(range(0,2500,250)),
plt.grid(True, linestyle = "--",color = "gray", linewidth = "0.5",axis = 'y',alpha=0.5)#网格线
二、用户消费习惯分析
(1)日均消费次数分析
对产生过购买行为的用户分析日均消费可知,绝大多数这类用户日均消费次数在5次以下,大多数用户日均消费集中在0.3-1次,用户最高日均消费次数是33次。

双十二当天用户消费次数直方图和箱型图,可以看出双十二当天用户消费次数集中在1-4次,存在小部分用户当日消费次数超过20次。
#用户日均消费次数分析(总次数/消费天数)
data_user_buy=data[data.behavior_type==4].groupby('user_id')
data_user_buy=data_user_buy.apply(lambda x:x.behavior_type.count()/len(x.drop_duplicates(subset='time').count()))
fig=plt.figure(figsize=(10,3))
plt.subplots_adjust(wspace=0.5,hspace=0)
ax1=fig.add_subplot(121)
sns.distplot(data_user_buy,kde=False,ax=ax1)
plt.title('用户日均消费次数直方图')
ax2=fig.add_subplot(122)
data_user_buy.plot.box(grid=True,showfliers = False,ax=ax2)
plt.title('用户日均消费次数箱型图')
#双十二当天
data_user_buy=data[(data.behavior_type==4)&(data.time=='20141212')].groupby('user_id').count()
plt.figure(figsize=(15,6))
sns.countplot(x='time',data=data_user_buy,palette='Blues_r')
plt.xlabel('消费次数')
plt.ylabel('用户数量')
plt.title('用户双十二当天消费次数')(2)ARPPU
ARPU:一个时间段内运营商从每个用户所得到的的收入
ARPPU:平均用户收入,平均每付费用户收入
因为数据集没有订单金额,所以用消费总次数/总消费人数来表示ARPPU,可以看出12.08-12.11日,每位用户的日均消费次数在2-2.25之间波动,在12日当天达到峰值约3.7次。
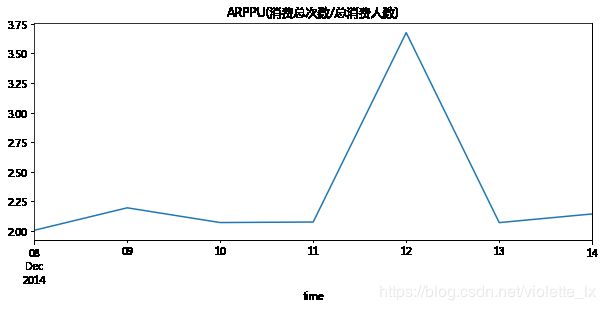
(3)用户复购率
复购率:重复购买客户数量/客户样本数量,复购率为75.91%说明用户黏性比较好,多数付费用户产生重复购买情况。
#用户复购情况(一天多次购买也算重复购买)
#重复购买用户总数/总消费人数
date_rp=data[data.behavior_type==4].groupby('user_id').count()['behavior_type']#['time'].apply(lambda x:len(x.unique()))
x=date_rp[date_rp>=2].count()
print('repeat purchase:%.2f%%'%(date_rp[date_rp>=2].count()/date_rp.count()*100))(4)用户付费率
用户付费率:产生购买行为的用户/所有用户,用户付费率为67.72%,说明用户付费比率非常高
user_count=len(data.user_id.unique())
buyuser_count=len(data[data.behavior_type==4].user_id.unique())
print('afford_rate %.2f%%' %(100*buyuser_count/user_count))
三、用户行为转换漏斗
将加购和收藏作为点击与购买的中间层次,统计用户点击、加购收藏、购买的每一层转换率。点击到加购的转换率为4.57%,到收藏的转换率为2.96%。可以通过购物推荐算法优化搜索引擎等方式帮助用户更好找到所需商品。从用户加入购物车和收藏夹到用户购买的转换率为2.14%,可以通过发送提醒,加购收藏有礼等活动提高这一层的转换率。
但实际用户可以不通过加购和收藏环节直接进行购买,这个转换率的分析不是很准确。如进一步分析,应分析加购后购买,收藏后购买,直接由点击转换购买三部分的转换率。
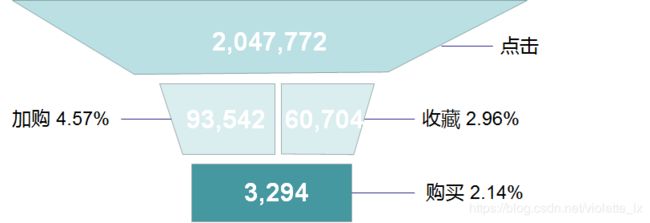
五、用户价值度RFM模型分析
RFM分析是根据客户活跃程度和交易金额的贡献,进行客户价值细分的方法。具体参见:http://www.woshipm.com/data-analysis/708326.html
- R(Recency):客户最近一次交易时间的间隔。
- F(Frequency):客户在最近一段时间内交易的次数。
- M(Monetary):客户在最近一段时间内交易的金额。
因为缺少交易金额,提取交易总次数作为F参数,距离12-15日的消费时间间隔为R值,F值越大说明用户交易越频繁,R值越大说明用户发生交易的时间越近
由联合分布图可以看出用户消费频次集中在0-25次的区间内,最后一次交易集中在3天(和双十二活动日期相符)。
按照用户数量均匀分为1-3类,用户类型的第一个数值表示R值,R值越大,表示客户交易发生的日期越近,第二个数值为F值,F值越大,表示客户交易越频繁。在RFM用户分类中,33对应的用户消费时间近、消费频次高,是高价值的用户。13对应的用户是消费时间远,消费频次高的用户,是重点保持的用户。
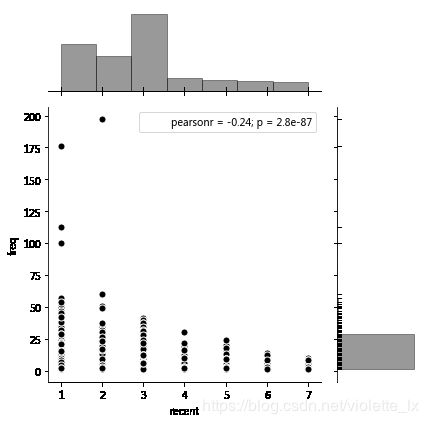
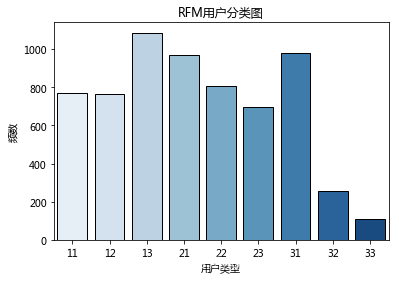
datenow=datetime.datetime(2014,12,15)
#每位用户最近购买时间
recent_buy_time=data[data.behavior_type==4].groupby('user_id').time.apply(lambda x:datenow-x.sort_values().iloc[-1])
recent_buy_time=recent_buy_time.reset_index().rename(columns={'time':'recent'})
recent_buy_time.recent=recent_buy_time.recent.map(lambda x:x.days)
# #每个用户消费频数
buy_freq=data[data.behavior_type==4].groupby('user_id').time.count().reset_index().rename(columns={'time':'freq'})
rfm=pd.merge(recent_buy_time,buy_freq,left_on='user_id',right_on='user_id',how='outer')
# recent表示距离上次购买间隔天数,数值越小越好,因此较小数值赋值3(更重要)
rfm['R_value']=pd.qcut(rfm.recent,3,labels=['3','2','1'])
# freq表示消费次数,数值越大越好,因此较大数值赋值2(更重要)
rfm['F_value']=pd.qcut(rfm.freq,3,labels=['1','2','3'])
rfm['rfm']=rfm['R_value'].str.cat(rfm['F_value'])#str.cat拼接字符串
rfm.head()
#绘制联合分布图
plt.rcParams["patch.force_edgecolor"] = True
sns.jointplot(x=rfm['recent'],y=rfm['freq'],#x轴 y轴
data=rfm,#设置数据
color='k',
s=50,edgecolor='w',linewidth=1,#散点大小、边缘、线性
kind='scatter',#kind : {“scatter”|“reg”|“resid”|“kde”|“hex”}
space=0.2,#散点图和布局图间距
size=6,#图表大小
ratio=3,#散点图和布局图高度比
marginal_kws=dict(bins=7,rug=True))#柱状图箱数
#绘制统计直方图
sns.countplot(x='rfm',data=rfm,palette='Blues')
plt.title('RFM用户分类图')
plt.xlabel('用户类型')
plt.ylabel('频数')
商品分析
一、商品统计
(1)商品品类分析
#统计商品品类
data_buy=data[data['behavior_type']==4]
data_category=data_buy.groupby(['item_category']).time.count()
data_category.sort_values(ascending=False,inplace=True)
#统计销量最高商品品类的item_id
max_cat=data_category[:1].index.values
data_item=data_buy[data_buy.item_category.isin(max_cat)].groupby(['item_id']).time.count()
data_item.sort_values(ascending=False,inplace=True)
fig,axes = plt.subplots(1,2,figsize=(20,5))
plt.subplots_adjust(wspace=0.3,hspace=0.3)
plt.subplot(121)
data_category[:10].plot.barh()
plt.title('商品种类销量前十')
plt.subplot(122)
data_item[:10].plot.barh()
plt.title('销量最高种类的十种畅销品')(2)商品的浏览,收藏,加购物车,购买的前十名
#提取数据
data_item=data.groupby(['behavior_type','item_id']).time.count()
data_item=data_item.reset_index().rename(columns={'time':'total_num'})
data_click=data_item[data_item.behavior_type==1].sort_values(by='total_num',ascending=False)[:10].set_index('item_id')
data_collect=data_item[data_item.behavior_type==2].sort_values(by='total_num',ascending=False)[:10].set_index('item_id')
data_cart=data_item[data_item.behavior_type==3].sort_values(by='total_num',ascending=False)[:10].set_index('item_id')
data_pay=data_item[data_item.behavior_type==4].sort_values(by='total_num',ascending=False)[:10].set_index('item_id')
#可视化
fig,axes = plt.subplots(2,2,figsize=(20,10))
plt.subplots_adjust(wspace=0.3,hspace=0.3)
plt.subplot(221)
data_click['total_num'].plot.barh()
plt.title('商品点击量前十')
plt.subplot(222)
data_collect['total_num'].plot.barh()
plt.title('商品收藏量前十')
plt.subplot(223)
data_cart['total_num'].plot.barh()
plt.title('商品加入购物车前十')
plt.subplot(224)
data_pay['total_num'].plot.barh()
plt.title('商品购买量前十')(3)帕累托分析
对于item_id进行分析发现45.04%的商品实现了80%的销量。
data_pareto=data[data['behavior_type']==4].groupby(['item_id']).time.count()
data_pareto=data_pareto.reset_index().sort_values('time',ascending=False)
p=data_pareto['time'].cumsum()/data_pareto['time'].sum()
key = p[p>0.8].index[0]
print('%.2f%%的商品实现了80%%的销量'%(100*key/data_pareto.shape[0]))二、商品销售结构
这里我将所有商品分为六大类别,随机对每一个category_id分配了一种类别,以此来模拟进行商品类型销售分析。
(1)商品类别销售占比
由分析可知,F类型的商品销量最高占比19%,B类型的商品销量最低占比15%。
#随机生成类别的标签
cat=data.item_category.unique()
r=np.random.randint(1,7,len(cat))
category=pd.DataFrame({'item_category':cat,'class_id':r})
data_category=pd.merge(category,data,how='inner',on='item_category')
#matplotlib画饼图太丑了 这个我导出到excel画的环形图
data_class=data_category[data_category['behavior_type']==4][['time','class_id','user_id']]
data_class=data_class.groupby('class_id').time.count()
plt.axis('equal') # 保证长宽相等
plt.pie(data_class,
labels = data_class.index,#colors='Blues',
autopct='%.2f%%',
pctdistance=0.6,#越大离中心越远
labeldistance = 1.2,
shadow = True,
startangle=0,
radius=1.5,
frame=False)(2)商品每日销售比例
#商品类别堆叠柱状图
day_class=data_category[data_category['behavior_type']==4][['time','class_id','user_id']]
day_class['time']=day_class['time'].apply(lambda x:x.__format__('%Y/%m/%d'))
dc=pd.pivot_table(day_class,values='user_id',index='time',columns='class_id',aggfunc='count')
dc=dc.div(dc.sum(axis=1),axis=0).applymap(lambda x:(100*x))
dc=dc.round(2)
dc.plot(kind='bar',grid=True,colormap='Blues_r',stacked=True,
figsize=(15,8),edgecolor='black',rot='45',title='商品销量堆叠直方图')#stacled=True 堆叠柱状图