meta-learning 2018文章总结
元学习论文总结||小样本学习论文总结
2017-2019年计算机视觉顶会文章收录 AAAI2017-2019 CVPR2017-2019 ECCV2018 ICCV2017-2019 ICLR2017-2019 NIPS2017-2019
作者:Flood Sung
链接:https://zhuanlan.zhihu.com/p/40600485
目录
1 前言
2 Paper List
3 State-of-the-Art
4 最新的Meta Learning Idea都是什么呢?
4.1 Discriminative k-shot learning using probabilistic models
4.2 Few-shot image recognition by predicting parameters from activations
4.3 Dynamic Few-Shot Visual Learning without Forgetting
4.4 Meta-learning with differentiable closed-form solvers
4.5 TADAM: Task dependent adaptive metric for improved few-shot learning
4.6 Meta-Learning with Latent Embedding Optimization
5 小结一下
1 前言
Meta Learning确实是近年来深度学习领域最热门的研究方向之一,其最主要的应用就是Few Shot Learning,在之前本专栏也探讨过Meta Learning的相关研究:
Flood Sung:最前沿:百家争鸣的Meta Learning/Learning to learn
现在一年过去了,太快了,Meta Learning上又有什么新的进展呢?可以给我们什么样的启发呢?让我们今天来好好看看。
2 Paper List
我这里收罗一些近段时间来的Meta Learning Papers。我们知道,Meta Learning从结合角度上看可以分成三大块:Supervised Learning,Unsupervised Learning/Generative Model以及Reinforcement Learning。那么本文仅探讨Meta Learning在Supervised Learning上的应用,其实也就是Few Shot Learning。
下面是Paper List:
[1] Bauer, Matthias, et al. "Discriminative k-shot learning using probabilistic models."arXiv preprint arXiv:1706.00326(2017).
[2] Qiao, Siyuan, et al. "Few-shot image recognition by predicting parameters from activations."CoRR, abs/1706.034661 (2017).
[3] Gidaris, Spyros, and Nikos Komodakis. "Dynamic Few-Shot Visual Learning without Forgetting."Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[4] Bertinetto, Luca, et al. "Meta-learning with differentiable closed-form solvers."arXiv preprint arXiv:1805.08136(2018).
[5] Oreshkin, Boris N., Alexandre Lacoste, and Pau Rodriguez. "TADAM: Task dependent adaptive metric for improved few-shot learning."arXiv preprint arXiv:1805.10123(2018).
[6] Rusu, Andrei A., et al. "Meta-Learning with Latent Embedding Optimization."arXiv preprint arXiv:1807.05960(2018).
从上面的list大家可以看到,Meta Learning在Few Shot Learning问题发展很快,最新的paper也就是这个月发布的。
3 State-of-the-Art
目前最新的Few Shot Learning在miniImagenet效果的算法排行:
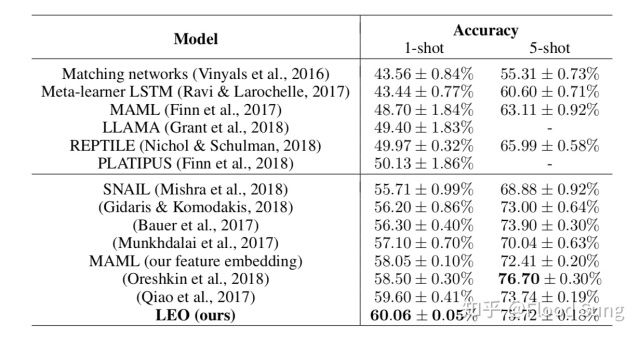
截图自Meta-Learning with Latent Embedding Optimization
发展特别快,从去年的50%提升了10个点到60%了。但是这里最主要的提升原因还在于使用了更大的网络如Resnet来提取特征,去年由于大家默认使用4层卷积来提取特征,很大程度上限制了效果,今年大家就都放开了用更大的网络,只要效果好就行。上图MAML使用Resnet在5way 1shot上面也能取得58.05%的准确率。当然,通过上面这个表我们也相信目前的效果还远远没有到极限,还可以更好。
4 最新的Meta Learning Idea都是什么呢?
下面就让我们一起来分析一下上面列举的8篇文章,肯定不全,但是基本涵盖了Meta Learning在Few Shot Learning问题上的前沿。
注意:下文的分析更多的从Reviewer的角度去分析,由于本文不是tutorial性质的文章,会有很多概念是直接说而不加解释,需要知友对本领域有一定了解。
4.1 Discriminative k-shot learning using probabilistic models
一般对于Meta Learning问题,我们把training set也构造成test task的形式,实现episodic training。比如training set里面有60个类,但是我们test task是5way 1shot,那么我们就每次从training set中随机采样5个类,每一个类选一个图片作为我们task的训练样本,从而模拟test的过程。
那么这篇文章的想法是为什么不先把整个training set作为整理来训练,然后再研究如何迁移到few shot learning上。

所以这里就先使用整个training set做representation learning,学习一个好的Feature Encoder,然后就固定这一部分(也就是卷积层)不变,在神经网络最后分别引出两个softmax层,一个是针对旧的classes也就是training set,一个则是针对新的k-shot learning classes。那么这里最主要的问题就是两个不同softmax层对应的参数 如何联系起来?
作者想,那我们通过概率模型的方式来思考这个问题,我们把一开始representation learning阶段学到的 作为后验概率MAP,然后我们寻求学习一个共同的参数 来生成 及 ,这样就可以让 和 实现联系,也就是
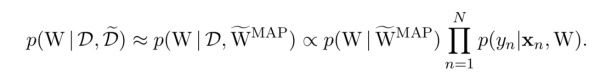
那么在具体的神经网络训练中,实际上就是一个joint training过程,文章中作者使用高斯分布来生成W,那么训练中就是构造出这样的损失函数让 生成的 逼近representation learning中生成的 同时使得 生成生成的 能够使K-shot learning损失最小。
评价一下这篇文章的方法就是感觉方法能够work最主要的还是因为第一阶段的representation learning阶段学习一个好的feature encoder,而后面对于softmax层的迁移感觉能学到的信息有限,作者做了一个很强的假设就是 能够直接代表可观察的训练数据 ,这是否合理是需要论证的。
然后这篇文章看起来取得了很好的效果,实际上是因为将validation set里面的20类数据也拿来做representation learning了,这个是不符合其他paper的设定的,实际上本人之前的Relation Network如果把validation set直接也拿来训练,可以取得比这篇paper更好的效果。
总的来说这篇文章可以获得的启发很有限,由于其实验设定存在不公平之处,实际上不需要引用这篇文章的数据。
4.2 Few-shot image recognition by predicting parameters from activations
这篇文章的基本思路和上一篇的思路是一样的,希望能够先大规模的训练training set,然后再利用学习到的feature来处理few shot learning的情况。而这里面的核心问题也就是上一篇文章遇到的,如何构造出最后的全连接softmax层。
那么这篇文章就做的更简单了,直接用倒数的activation输出层来生成最后的参数,针对每一个类生成一组对应的参数:

这样的处理方法是简单又合理的,因为不同类别的图像对应的activation 输出都不一样,而且通过t-SNE处理显示是具备类别区分能力的,我们这里无外乎只是需要构造出一个输出神经网络。

Activation输出的t-SNE显示
那么这篇文章同样的在miniimagenet实验中使用了80个类的数据(包含validation set)来训练,所以目前benchmark上的比较因为这个细节会很容易误导,有的paper没有使用validation set,有的有,而使用了必然效果更好。
总结一下这篇文章的思路比上一篇的简洁,结果上也上一篇好一些。
4.3 Dynamic Few-Shot Visual Learning without Forgetting
这篇文章和前面两篇的基本思想也非常类似,也是直接用已有的大的数据集训练,核心还是在于如何处理新task 新class的输出。
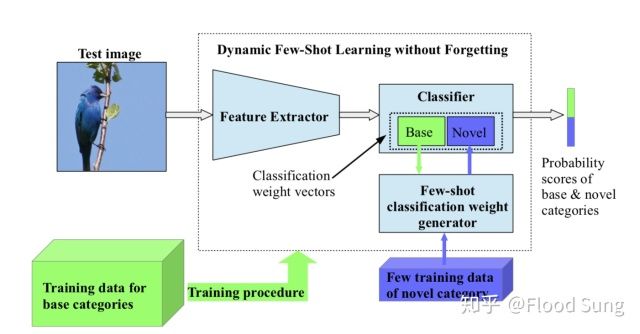
那么这篇文章的idea和上一篇其实没有本质的区别,或者说几乎就是一样的,先用training set训练出一个feature extractor,然后对于新的few shot training data,通过一个few-shot classification weight generator来生成对应的参数weight。一点具体处理的小细节就是这个weight generator还把base weight作为输入,同时计算最后的概率输出不是直接相乘,而是使用cosine similarity相似度来算(这里的根本原因是base weight和novel weight的生成方式不同,量级可能差很多,而只用cosine similarity则不需要考虑这个量级的问题),最后就是作者在使用多个few shot样本时不仅仅是简单粗暴的对feature取平均,而且使用了attention注意力机制来选择对应的base weight,效果会更好。
最后说一下整个训练过程,不是完全的端到端过程而是分两步训,这个其实和前面两篇文章也一样,先训练出feature extractor,然后再固定它,训练后面的weight generator。个人认为这样做是比较丑的,而且并不利于效果的提升。
相比上面两篇文章,整体感觉这篇文章的处理会更好一些,特别是最后使用了attention-based weight generator,比较明显可以提升效果。那么实际实验上这篇文章只使用了64类,和其他方法是公平比较的,虽然看结果比前两篇略低,但估计如果是使用80类做training结果会更好。
4.4 Meta-learning with differentiable closed-form solvers
这篇文章的思路就和前面三篇的思路不一样了,采用我们通常理解的meta learning的问题设定,使用episodic training的方式。
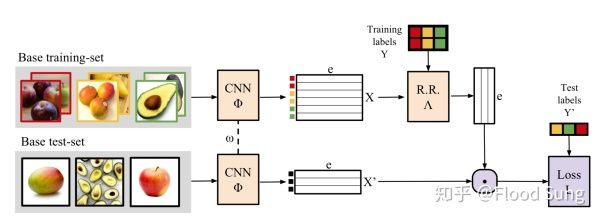
那么基于Meta Learning的方式,这篇文章的idea核心在于如何提取training set中的X和Y的信息,并直接迁移到test-set中使用,也就是上图中的 的处理及下面 和 的处理。很显然的,我们可以使用最最简单粗暴的做法,直接构造一个带条件condition的神经网络f,使得
这样做的话也就是SNAIL的做法,由于SNAIL把网络弄的很大,并且使用了attention注意力机制,效果其实已经非常好,那么这篇文章就是我们能不能不那么粗暴的做,而改用数学一点的方式优雅的来做它。因此,这篇文章就构造了一个ridge regression的闭式解:

并通过一定的数学处理Woodbury formula,得到
![]()
然后 和 的处理就是直接点乘搞定。
通过数学的方式在这里最大的优势是降维,能够把高维的输入数据通过矩阵运算直接变成低维数据。
总的来说这篇文章就是提出了一种不同的处理先验知识(X和Y)的数学做法,有一定的用处,但是可能实际意义并没有那么大,效果上看也只能说一般。很值得考虑的一个问题就是纯粹用神经网络来学习先验知识难道不是更好吗?通过数学的方式人为的构造一种生成先验知识的方式是否有意义值得探讨。
4.5 TADAM: Task dependent adaptive metric for improved few-shot learning
这篇文章的idea是在一般metric based few shot learning的基础上做一些改进,提升一般模型的generalization。

首先文章采用Prototypical Network的思想,构造class representation来进行metric计算,然后文章做出如下三点改进方式:
1)Metric Scaling:在similarity metric的基础上学习一个scaling factor ,这样能够更好的使得输出的metric在合适的范围内
2)Task Conditioning:构造一个TEN network,通过输入样本数据来得到task representation,并利用此作为condition来改变feature extractor的输出。简单的说就是使得每一个task的feature extractor都不一样,具备adaptation的能力。
3)Auxiliary task co-training: 这里作者采用前面分析的几篇文章的做法,也使用所有训练数据来训练feature extractor,并把这个作为一个辅助任务,这样能够提升特征提取能力。
总的来说,这篇文章主要在细节上做了改进,但确实取得了挺不错的效果,非常值得借鉴的思想还是task conditioning,这意味着我们应该构建更meta的神经网络,使得最终得到的分类器的自适应能力足够强,这样更有希望使得效果更好。
4.6 Meta-Learning with Latent Embedding Optimization
这篇是Deepmind Oriol Vinyals 团队最新推出的Meta Learning文章。这篇文章的核心idea则建立在Chelsea Finn的MAML的基础上。因为之前MAML出现的问题是不能很好的处理高维数据,导致即使把网络的层数加大,MAML的效果也上不去,因此这篇文章就专注于解决这个问题。

那么这篇文章的做法是构造一个latent embedding space,先对输入的图像x进行encode得到latent code z,然后再decode出最后分类用的参数w,并直接用w和z使用MAML的方式进行训练。然后这里的x是已经经过feature extractor得到的feature,640d,采用之前几篇paper使用的方法,用整个training set来预训练这个feature extractor。这篇文章idea的核心在于学习了一个stochastic model parameter generator,其实搞得挺复杂的,那么我们自然想问的是这样做到底意义在哪里?为什么能够使得效果提升?
首先采用了预训练的feature extractor之后,MAML都可以提升到58.05%的程度,LEO只是再进一步提升了一点点。那么整个parameter generator我们也可以不加随机,而直接变成参数生成,但为什么加随机?在我看来是能够更好的实现对特征空间的适应,或者说可以一定程度上减少过拟合的情况。其实目前的few shot learning,很多方法都大同小异,在omniglot数据集上基本上已经是攻克了的,那么为什么miniimagenet还差很多呢?因为给的训练数据太少,也才64个类,这就会很容易出现严重的过拟合能力。而这篇文章这么做,搞得这么复杂,在我看来pretraining feature extractor占了一大半的贡献,然后stochastic占了一小部分贡献。最后,对于MAML的看法, 我认为这个方法存在一定的不可控,比如要做多少步梯度下降才合适呢?多了肯定过拟合,少了可能效果不够好,这是MAML的一种缺陷。相反metric-based learning的方法的问题是模型训练好就固定了,面对新的task,不具备进一步学习(continual learning)的能力,这也是有待提升的。
5 小结一下
以上我们分析了目前Meta Learning的几篇最新的文章,从中我们其实看到了很多共性的地方,比如都想到使用整个训练集来预训练一个feature extractor。同时我们也看到了很多差异,很多细节上的差异,角度各不相同。我们这里稍微总结一下meta learning还需要进一步的提升的方向:
1)让模型更加的meta,更加的adaptive!
2)进一步优化Feature Extractor的效果,可能这个才是性能提升的关键!
3)进一步通过各种方式减少过拟合,这是miniimagenet效果要提升的关键!
4)我们看到了很多文章都使用parameter generating的方式,一般我们会认为生成参数这种参数空间特别大的问题是比较困难的,但是大家却在不断的用,也说明这种meta 方式其实是可行的,如果能找到更好的生成稳定参数的方法,或许也能大幅度提升效果。
总的来说,目前的Meta Learning算法上还有很多提升空间,不管是optimization-based learning还是metric-based learning,都是要学习一个更好的meta knowledge,更充分的使用meta knowledge才行!最后,希望本文能够对做相关研究的朋友有所启发和帮助!