使用Python进行数据降维|线性降维
前言
为什么要进行数据降维?直观地好处是维度降低了,便于计算和可视化,其深层次的意义在于有效信息的提取综合及无用信息的摈弃,并且数据降维保留了原始数据的信息,我们就可以用降维的数据进行机器学习模型的训练和预测,但将有效提高训练和预测的时间与效率。
降维方法分为线性和非线性降维,非线性降维又分为基于核函数和基于特征值的方法(流形学习),代表算法有
- 线性降维方法:PCA ICA LDA LFA
- 基于核的非线性降维方法KPCA KFDA
- 流形学习:ISOMAP LLE LE LPP
本文主要对线性降维方法中的PCA、ICA、LDA的Python实现进行讲解。
请注意本文将不对各种数据降维方法的原理与理论推导过程做过多的讲解,旨在用尽可能少的语言说清楚以及如何用Python实现,先实现再理解,并在读完代码之后自行查阅相关文献理解其不同的思想。但读者应具有一定的统计学、代数学、机器学习的基础。
主成分分析PCA
主成分分析(Principal Component Analysis),是一种常用的数据降维方法。通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量就叫主成分。关于主成分分析的思想与理论推导过程在互联网上很容易找到完美的证明,用人话说来就是找到一个轴,将你的数据映射到这个轴上之后所计算的方差最大,再换句人话说就是从原始数据的一堆变量中提取出一部分变量,而这部分变量能完美解释原始数据中包含的信息(或保留原始的数据特性)
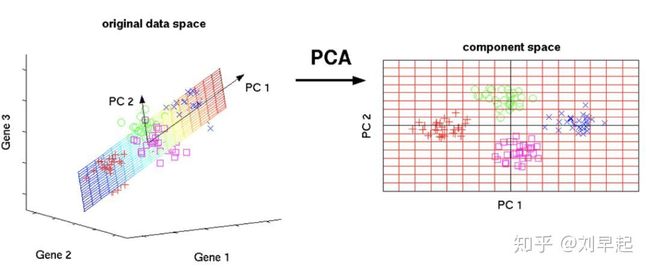
注意:
- 进行主成分分析前需对数据进行归一化处理
PCA流程:
- 对数据行归一化处理
- 计算归一化后的数据集的协方差矩阵与其特征值、特征向量
- 对特征值从大到小排序并保留最大的个特征向量
- 将数据转换到个特征向量构建的新空间中
优点:
- 无参数限制
- 提取了主要信息并且结果容易理解
缺点:
- 方差小的主成分可能含有对样本差异的重要信息
- 在某些情况下,PCA方法得出的主元可能并不是最优的
相关Python代码
sklearn.decomposition.PCA
Python实现示例(已注释)
#来看个官网最简单的例子
>>> import numpy as np
>>> from sklearn.decomposition import PCA
#创建数据 矩阵形式
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
#设定两个主成分
>>> pca = PCA(n_components=2)
#用X训练
>>> pca.fit(X)
PCA(n_components=2)
#查看每个主成分解释程度
>>> print(pca.explained_variance_ratio_)
[0.9924... 0.0075...]
>>> print(pca.singular_values_)
[6.30061... 0.54980...]
#降维
>>> pca = PCA(n_components=1, svd_solver='arpack')
>>> pca.fit(X)
PCA(n_components=1, svd_solver='arpack')
>>> print(pca.explained_variance_ratio_)
[0.99244...]
>>> print(pca.singular_values_)
[6.30061...]
线性判别分析LDA
线性判别分析(Linear Discriminant Analysis)是一种有监督的(supervised)线性降维算法。与PCA保持数据信息不同,LDA的核心思想:往线性判别超平面的法向量上投影,使得区分度最大(高内聚,低耦合)。LDA是为了使得降维后的数据点尽可能地容易被区分!
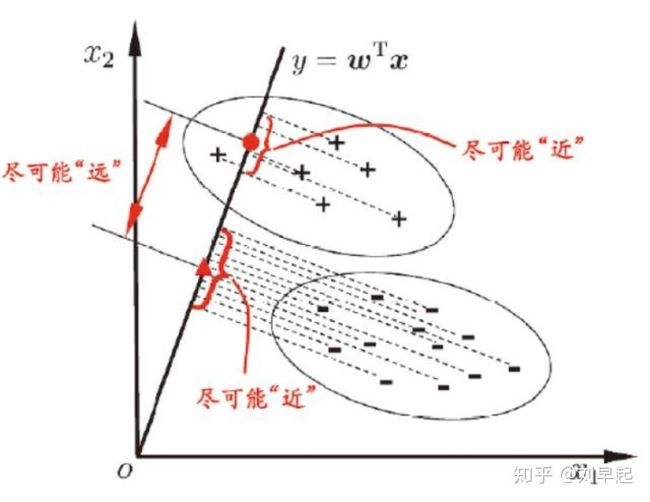
与PCA比较
- PCA为无监督降维,LDA为有监督降维
- LDA降维最多降到类别数K-1的维数,PCA没有这个限制。
- PCA希望投影后的数据方差尽可能的大(最大可分性),而LDA则希望投影后相同类别的组内方差小,而组间方差大。
相关Python代码
sklearn.discriminant_analysis.LinearDiscriminantAnalysis
Python实现示例(已注释)
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
%matplotlib inline
from sklearn.datasets.samples_generator import make_classification
#生成数据
X, y = make_classification(n_samples=1000, n_features=3, n_redundant=0, n_classes=3, n_informative=2,
n_clusters_per_class=1,class_sep =0.5, random_state =10)
#LDA降维
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
lda = LinearDiscriminantAnalysis(n_components=2)
lda.fit(X,y)
X_new = lda.transform(X)
plt.scatter(X_new[:, 0], X_new[:, 1],marker='o',c=y)
plt.show()独立成分分析ICA
独立成分分析(Independent component analysis)是一种利用统计原理进行计算的方法,它是一个线性变换,这个变换把数据或信号分离成统计独立的非高斯的信号源的线性组合。之前介绍的PCA、LDA都是以观测数据点呈高斯分布模型为基本假设前提的,而ICA将适用于非高斯分析数据集,是PCA的一种有效扩展。
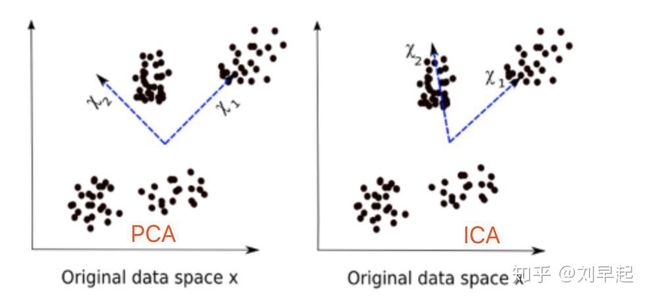
与PCA比较
- ICA寻找的是最能使数据的相互独立的方向,而PCA仅要求方向是不相关的
- PCA认为主元之间彼此正交,样本呈高斯分布;ICA则不要求样本呈高斯分布
相关Python代码
sklearn.decomposition.FastICA
Python实现示例(已注释)
import numpy as np
import matplotlib.pyplot as plt
from scipy import signal
from sklearn.decomposition import FastICA, PCA
# 生成观测模拟数据
np.random.seed(0)
n_samples = 2000
time = np.linspace(0, 8, n_samples)
s1 = np.sin(2 * time) # 信号源 1 : 正弦信号
s2 = np.sign(np.sin(3 * time)) # 信号源 2 : 方形信号
s3 = signal.sawtooth(2 * np.pi * time) # 信号源 3: 锯齿波信号
S = np.c_[s1, s2, s3]
S += 0.2 * np.random.normal(size=S.shape) # 增加噪音数据
S /= S.std(axis=0) # 标准化
# 混合数据
A = np.array([[1, 1, 1], [0.5, 2, 1.0], [1.5, 1.0, 2.0]]) # 混合矩阵
X = np.dot(S, A.T) # 生成观测信号源
# ICA模型
ica = FastICA(n_components=3)
S_ = ica.fit_transform(X) # 重构信号
A_ = ica.mixing_ # 获得估计混合后的矩阵
# PCA模型
pca = PCA(n_components=3)
H = pca.fit_transform(X) # 基于PCA的成分正交重构信号源
# 图形展示
plt.figure()
models = [X, S, S_, H]
names = ['Observations (mixed signal)',
'True Sources',
'ICA recovered signals',
'PCA recovered signals']
colors = ['red', 'steelblue', 'orange']
for ii, (model, name) in enumerate(zip(models, names), 1):
plt.subplot(4, 1, ii)
plt.title(name)
for sig, color in zip(model.T, colors):
plt.plot(sig, color=color)
plt.subplots_adjust(0.09, 0.04, 0.94, 0.94, 0.26, 0.46)
plt.show()以上就是早起的统计工具箱第二期的内容,当然想要完全学会还需要自行查阅更多文献,而更多的数据降维方法、还有上一期未介绍完的python统计检验我们之后再聊。