关于SQL易忘的十五个知识点
主要记录SQL尤其是MySQL中,一些看了就忘,需要经常查的小知识点~
快速查询
- 1. 下划线_通配符与百分号%通配符的区别
- 2. 匹配不区分大小写
- 3. MySQL正则表达式
- 4. LIKE和REGEXP的区别
- 5. 匹配
- 6. 文本处理函数
- 7. 日期和时间处理函数
- 8. 数值处理函数
- 9. 聚集函数
- 10. HAVING和WHERE的区别
- 11. 组合查询UNION
- 12. 全文本搜索
- 13. 数据插入
- 14. 更新数据、删除数据
- 15. 主键、索引和外键
- 参考资料
1. 下划线_通配符与百分号%通配符的区别
下划线的用途与%一样,但是%能匹配0个字符不一样,_总是匹配一个字符,不能多也不能少。

2. 匹配不区分大小写
通过使用BINARY可以区分,如:
WHERE prod_name REGEXP BINARY 'JetPack .000'
3. MySQL正则表达式
正则表达式的作用是匹配文本,将一个模式(正则表达式)与一个文本串进行比较。MySQL
用WHERE子句对正则表达式提供了初步的支持,允许你指定正则表达式,过滤SELECT检索出的数据。
4. LIKE和REGEXP的区别
LIKE匹配整个列。如果被匹配的文本在列值中出现,LIKE将不会找到它,相应的行也不被返回(除非使用通配符)。而REGEXP在列值内进行匹配,如果被匹配的文本在列值中出现,REGEXP将会找到它,相应的行将被返回。这是一个非常重要的差别。
5. 匹配
匹配字符

匹配特殊字符
为了匹配特殊字符,必须用\为前导。\-表示查找-,\.表示查找.。这种处理就是所谓的转义(escaping),正则表达式内具有特殊意义的所有字符都必须以这种方式转义。这包括.、|、[]以及迄今为止使用过的其他特殊字符。
\也用来引用元字符(具有特殊含义的字符)。

例:

定位符

例:

注:^的双重用途
^有两种用法。在集合中(用[和]定义),用它来否定该集合,否则,用来指串的开始处。
6. 文本处理函数
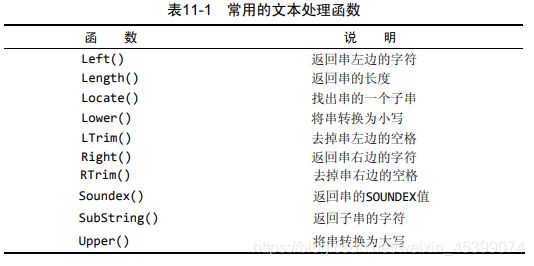
SOUNDEX是一个将任何文本串转换为描述其语音表示的字母数字模式的算法。使用Soundex()函数进行搜索,它匹配所有发音类似于Y.Lie的联系名:

拼接:将值联结到一起构成单个值。
解决办法是把两个列拼接起来。在MySQL的SELECT语句中,可使用Concat()函数来拼接两个列。
SELECT Concat(ven_name, '(', vend_country, ')')
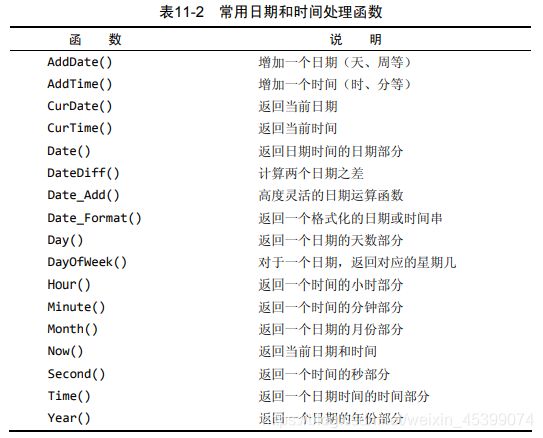
7. 日期和时间处理函数

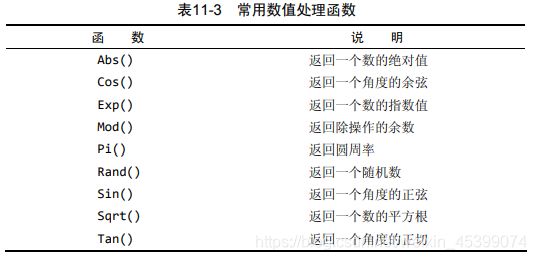
8. 数值处理函数
9. 聚集函数
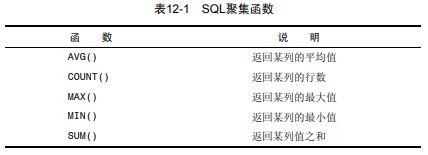
其中,在用于文本数据时,如果数据按相应的列排序,则MAX()返回最后一行,MIN()返回第一行。
COUNT()函数有两种使用方式。使用COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值。使用COUNT(column)对特定列中具有值的行进行计数,忽略NULL值。
10. HAVING和WHERE的区别
“Where” 是一个约束声明,使用Where来约束来之数据库的数据,Where是在结果返回之前起作用的,且Where中不能使用聚合函数。
“Having”是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作,在Having中可以使用聚合函数。
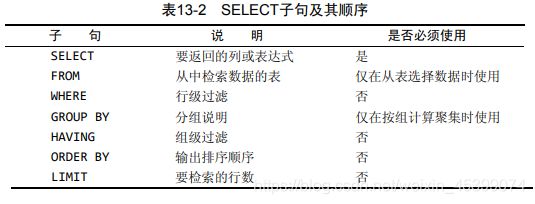
11. 组合查询UNION
UNION 返回匹配行,不保留重复行
UNION ALL 返回匹配行,包括重复行
UNION中的每个查询必须包含相同的列、表达式或聚集函数(不过各个列不需要以相同的次序列出)。
在用UNION组合查询时,只能使用一条ORDER BY子句,它必须出现在最后一条SELECT语句之后。对于结果集,不存在用一种方式排序一部分,而又用另一种方式排序另一部分的情况,因此不允许使用多条ORDER BY子句。
12. 全文本搜索

查询扩展

表中的行越多(这些行中的文本就越多),使用查询扩展返回的结果越好。
布尔文本搜索
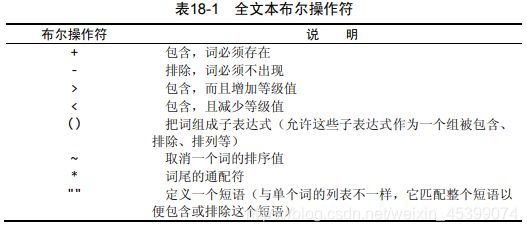

在布尔方式中,不按等级值降序排序返回的行。
13. 数据插入
插入一行

插入多行
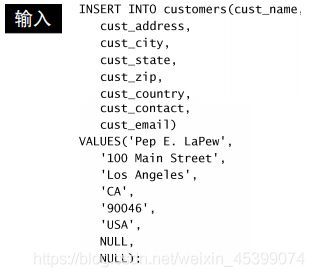
插入检索出的数据

14. 更新数据、删除数据
#更新多个列
UPDATE customers
SET cust_name = 'The Fudds',
cust_email = '[email protected]'
WHERE cust_id = 10005 ; #不要省略WHERE子句
#删除某个列的值
UPDATE customers
SET cust_email = NULL #其中NULL用来去除cust_email列中的值。
WHERE cust_id = 10005 ;
#删除数据
DELETE FROM customers
WHERE cust_id = 10005 ;
#DELETE不需要列名或通配符。DELETE删除整行而不是删除列,但DELETE不删除表本身。为了删除指定的列,请使用UPDATE语句。
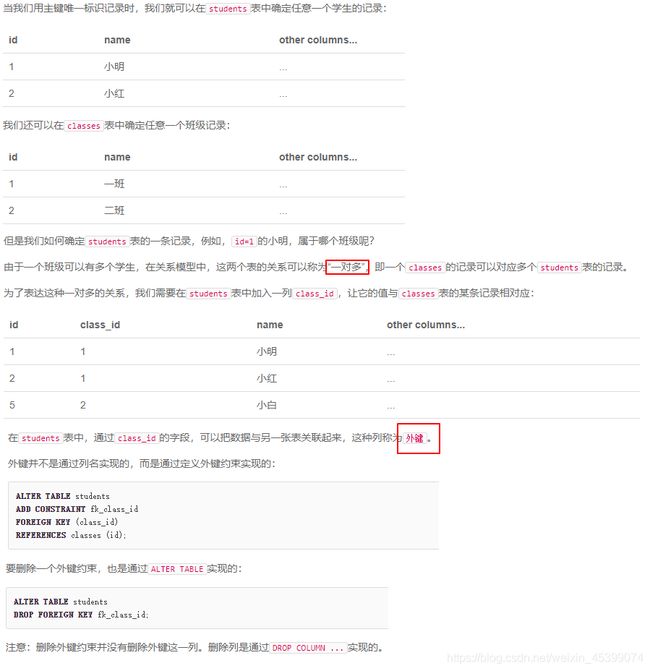
15. 主键、索引和外键
主键的作用:
- 惟一地标识一行。
- 作为一个可以被外键有效引用的对象。
索引:索引分为主键索引、唯一索引、普通索引、全文索引、组合索引等
- 主键索引(PRIMARY KEY):不可以为空,可以做外键,一张表中只能有一个主键索引。
ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
- 唯一索引(UNIQUE):被索引的数据列不允许包含重复的值,但允许有空值。
ALTER TABLE `table_name` ADD UNIQUE (`column`)
- 普通索引(INDEX):用来加速数据访问速度而建立的索引。多建立在经常出现在查询条件的字段和经常用于排序的字段。被索引的数据列允许包含重复的值。
ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
- 全文索引(FULLTEXT):仅可用于 MyISAM 表,针对较大的数据,生成全文索引很耗时好空间。
ALTER TABLE `table_name` ADD FULLTEXT ( `column` )
- 组合索引:为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则。
ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
主键和索引:主键是为了标识数据库记录唯一性,不允许记录重复,且键值不能为空,主也是一个特殊索引。数据表中只允许有一个主键,但是可以有多个索引。
外键:
参考资料
《MySQL必知必会》Ben Forta 著,刘晓霞 钟鸣 译
SQL教程 廖雪峰。