Tensorflow案例4:Mnist手写数字识别(线性神经网络)及其局限性
学习目标
- 目标
- 应用matmul实现全连接层的计算
- 说明准确率的计算
- 应用softmax_cross_entropy_with_logits实现softamx以及交叉熵损失计算
- 说明全连接层在神经网络的作用
- 应用全连接神经网络实现图像识别
- 应用
- Mnist手写数字势识别
1、 数据集介绍

文件说明:
- train-images-idx3-ubyte.gz: training set images (9912422 bytes)
- train-labels-idx1-ubyte.gz: training set labels (28881 bytes)
- t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
- t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
网址:http://yann.lecun.com/exdb/mnist/
1.1 特征值

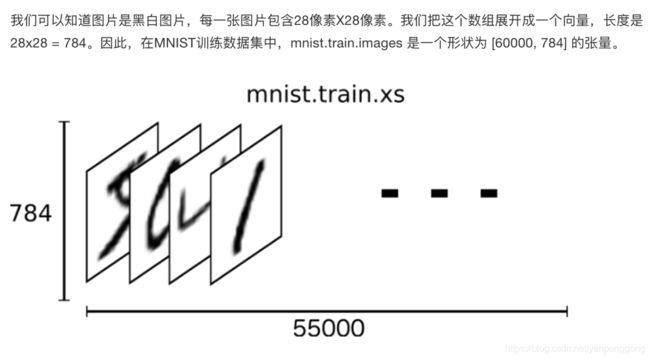
1.2 目标值
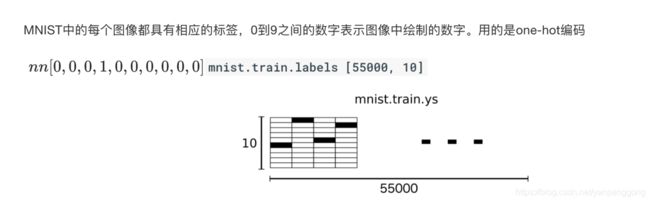
1.3 获取接口
TensorFlow框架自带了获取这个数据集的接口,所以不需要自行读取。
- from tensorflow.examples.tutorials.mnist import input_data
- mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
- mnist.train.next_batch(100)(提供批量获取功能)
- mnist.train.images、labels
- mnist.test.images、labels
- mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
2、 实战:Mnist手写数字识别
2.1 网络设计
我们采取只有一层,最后一个输出层的神经网络。也称之为全连接(full connected)层神经网络。

2.1.1 全连接层计算
- tf.matmul(a, b,name=None)+bias
- return:全连接结果,供交叉损失运算
2.2 流程
1、准备数据
2、全连接结果计算
3、损失优化
4、模型评估(计算准确性)
mnist = input_data.read_data_sets("./data/mnist/input_data/", one_hot=True)
# 1、准备数据
# x [None, 784] y_true [None. 10]
with tf.variable_scope("mnist_data"):
x = tf.placeholder(tf.float32, [None, 784])
y_true = tf.placeholder(tf.int32, [None, 10])
# 2、全连接层神经网络计算
# 类别:10个类别 全连接层:10个神经元
# 参数w: [784, 10] b:[10]
# 全连接层神经网络的计算公式:[None, 784] * [784, 10] + [10] = [None, 10]
# 随机初始化权重偏置参数,这些是优化的参数,必须使用变量op去定义
with tf.variable_scope("fc_model"):
weight = tf.Variable(tf.random_normal([784, 10], mean=0.0, stddev=1.0), name="w")
bias = tf.Variable(tf.random_normal([10], mean=0.0, stddev=1.0), name="b")
# fc层的计算
# y_predict [None, 10]输出结果,提供给softmax使用
y_predict = tf.matmul(x, weight) + bias
# 3、softmax回归以及交叉熵损失计算
with tf.variable_scope("softmax_crossentropy"):
# labels:真实值 [None, 10] one_hot
# logits:全脸层的输出[None,10]
# 返回每个样本的损失组成的列表
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true,
logits=y_predict))
# 4、梯度下降损失优化
with tf.variable_scope("optimizer"):
# 学习率
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
2.3 完善模型功能
- 1、增加准确率计算
- 2、增加变量tensorboard显示
- 3、增加模型保存加载
- 4、增加模型预测结果输出
2.3.1 如何计算准确率

- equal_list = tf.equal(tf.argmax(y, 1), tf.argmax(y_label, 1))
- accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))
完整代码
# -*- coding=utf-8 -*-
import os
# os.environ["TF_CPP_MIN_LOG_LEVEL"]='1' # 这是默认的显示等级,显示所有信息
# os.environ["TF_CPP_MIN_LOG_LEVEL"]='2' # 只显示 warning 和 Error
# os.environ["TF_CPP_MIN_LOG_LEVEL"]='3' # 只显示 Error
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 定义一个是否训练/预测的标志
tf.app.flags.DEFINE_integer("is_train", 1, "训练or预测")
# 训练步数
tf.app.flags.DEFINE_integer("train_step", 0, "训练模型的步数")
# 定义模型的路径
tf.app.flags.DEFINE_string("model_dir", " ", "模型保存的路径+模型名字")
FLAGS = tf.app.flags.FLAGS
# 此模型终端的运行方法
# python3 day02_05nn_mnist_FullDemo.py --is_train=1 --train_step=2000 # 训练
# python3 day02_05nn_mnist_FullDemo.py --is_train=0 # 预测
# tensorboard 终端查看
# tensorboard --logdir="./temp/summary/"
def full_connected_nn():
"""
全连接层神经网络进行Mnist手写数字识别训练
:return:
"""
mnist = input_data.read_data_sets("../data/mnist/input_data", one_hot=True)
# 1、获得数据,定义特征值和目标值张量
with tf.variable_scope("data"):
# 定义特征值占位符
x = tf.placeholder(tf.float32, [None, 784], name="feature")
# 定义目标值占位符
y_true = tf.placeholder(tf.int32, [None, 10], name="label")
# 2、根据识别的类别数、建立全连接层网络
# 手写数字10个类别
# 设计了一层的神经网络,最后一层,10个神经元
# 确定网络的参数weight [784, 10], bias [10]
# 要进行全连接层的矩阵运算 [None, 784] * [784, 10] + [10] = [None, 10]
with tf.variable_scope("fc_model"):
# 随机初始化权重和偏置参数,要使用变量OP 定义
weights = tf.Variable(tf.random_normal([784, 10], mean=0, stddev=0.1), name="weights")
bias = tf.Variable(tf.random_normal([10], mean=0, stddev=1.0), name="bias")
# 全连接层运算 10个神经元 y_predict=[None, 10]
y_predict = tf.matmul(x, weights) + bias
# 3、根据输出结果与真实结果建立softmax、交叉熵损失计算
with tf.variable_scope("soft_cross"):
# 先进行网络输出的值的概率计算softmax,再进行交叉熵损失计算
all_loss = tf.nn.softmax_cross_entropy_with_logits(labels=y_true, logits=y_predict, name="compute_loss")
# 求出平均损失
loss = tf.reduce_mean(all_loss)
# 4、定义梯度下降优化器进行优化
with tf.variable_scope("GD"):
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 5、求出每次训练的准确率为
with tf.variable_scope("accuracy"):
# 求出每个样本是否相等的一个列表
equal_list = tf.equal(tf.argmax(y_true, 1), tf.argmax(y_predict, 1))
# 计算相等的样本的比例
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))
# 6、tensorflowboard展示的数据
# 1)收集要在tensorflowboard观察的张量值
# 数值型 --> scalar 准确率, 损失值
tf.summary.scalar("loss", loss)
tf.summary.scalar("accuracy", accuracy)
# 维度高的张量值
tf.summary.histogram("w", weights)
tf.summary.histogram("b", bias)
# 2)合并变量
merged = tf.summary.merge_all()
# 7、创建保存模型的OP
saver = tf.train.Saver()
# 8、开启会话进行训练
with tf.Session() as sess:
# 初始化变量OP
sess.run(tf.global_variables_initializer())
# 创建tensorboard的events文件
filte_writer = tf.summary.FileWriter("./temp/summary/", graph=sess.graph)
# 9、加载本地模型继续训练或者拿来进行预测测试集
checkoutpoint = tf.train.latest_checkpoint("./temp/model/fc_nn_model")
# 判断模型是否存在
if checkoutpoint:
saver.restore(sess, checkoutpoint)
# 判断是训练还是预测
if FLAGS.is_train == 1:
# 循环训练
# for i in range(FLAGS.train_step):
for i in range(2000):
# 每批次给50个样本
mnist_x, mnist_y = mnist.train.next_batch(50)
# 查看数据的尺寸
# print(mnist_x.shape)
_, loss_run, accuracy_run, summary = sess.run([train_op, loss, accuracy, merged],
feed_dict={x: mnist_x, y_true: mnist_y})
# 打印每步训练的效果
print("第{0}步的50个样本损失为:{1}, 准确率为:{2}".format(i, loss_run, accuracy_run))
# 3) 写入运行的结果到文件当中
filte_writer.add_summary(summary, i)
# 每隔100步保存一次模型的参数
if i % 100 == 0:
# saver.save(sess, FLAGS.model_dir)
saver.save(sess, save_path="./temp/fc_nn_model/fc_nn_model")
else:
# 进行预测
# 导入模型
# 加载模型,从模型当中找出与当前训练的模型代码当中(名字一样的OP操作),覆盖原来的值
checkoutpoint = tf.train.latest_checkpoint("./temp/fc_nn_model/")
# 判断模型是否存在
if checkoutpoint:
saver.restore(sess, checkoutpoint)
# 预测100个样本
N = 200
a = 0
for i in range(N):
image, label = mnist.test.next_batch(1)
# 真实的图片数字
result_true = tf.argmax(label, 1).eval()
# 神经网络预测的数字
result_predict = tf.argmax(sess.run(y_predict, feed_dict={x: image, y_true: label}), 1).eval()
# 直接运行网络的输出预测结果
print("第{0}样本,真实的图片数字为:{1}, 神经网络预测的数字为:{2}".format(
i,
result_true,
result_predict)
)
if result_true == result_predict:
a += 1
test_accuracy = (a / N) * 100
print("测试正确率:", test_accuracy, "%")
else:
print("模型不存在,checkoutpoint 请输出入正确的模型路径")
return None
if __name__ == '__main__':
start_time = time.time()
full_connected_nn()
end_time = time.time()
all_time = end_time - start_time
print("time:{:.2f} s" .format (all_time))
3、线性神经网络局限性
任意多个隐层的神经网络和单层的神经网络都没有区别,而且都是线性的,而且线性模型的能够解决的问题也是有限的
1、 更复杂抽象的数据
一个单隐含层有更多的神经元,你就能捕捉更多的特征。而且有更多隐层,意味着你能从数据集中提取更多复杂的结构。
1.1 增加网络深度
1.2 使用非线性激活函数
2、神经网络更多特性
2.1黑盒子特点
- 增加网络的深度的确能够达到效果,但是增加多少?这是一个不确定的问题,或者可以改变神经元的一些特点,改变结构同时增加网络深度,这些都有很多结构进行了尝试。
- 不清楚网络内部每个神经元到底在什么事情
2.2 更多发展
更多神经元 + 更深的网络 = 更复杂的抽象。这也是简单的神经元如何变得更聪明,并在图像识别、围棋这些特定问题上表现如此之好的原因。
2.2.1 神经网络拓展介绍
- 神经网络的种类
- 基础神经网络:线性神经网络,BP神经网络,Hopfield神经网络等
- 进阶神经网络:玻尔兹曼机,受限玻尔兹曼机,递归神经网络等
- 深度神经网络:深度置信网络,卷积神经网络,循环神经网络,LSTM网络等

Inception:谷歌公开的一个图像识别模型
2.3 两大挑战:计算能力和训练数据
在此文章中,我们看到了一些 TensorFolw Playground 演示解释了神经网络的机制和能力。就像你看到的那样,这一技术的基础非常简单。每一个神经元只将一个数据点分类成两个类别中的一个。然而,通过有更多的神经元和深度层,一个神经网络能提取出训练数据集中隐藏的见解和复杂模式,并且建立抽象的层级结构。
接下来的问题是,为什么如今还不是每个人都在使用这一伟大的技术?这是因为神经网络还有两大挑战。
- 第一个是训练深度神经网络需要大量的算力。
- 第二,它们需要大量的训练数据集。一个强力的 GPU 服务器可能要花费数天、甚至数周的时间,才能使用数百万张图像的数据集训练出一个深度网络。
而且,为了得到最好的训练结果,需要结合不同的网络设计与算法,并进行大量的试错。如今,一些研究者会使用几十个 GPU 服务器,甚至超级计算机来进行大规模分布式的训练。但在不久的将来,全面管理的分布式训练与预测服务——比如谷歌 TensorFlow 云机器学习平台——可能会解决这些问题,为大家提供成本合理的基于云的 CPU 和 GPU,而且也可能会把大型的或深度的神经网络的能力开放给每一个人。