linux内核调度器 调度原理(2.6.24笔记整理)
linux内核调度器 调度原理(2.6.24笔记整理)
https://blog.csdn.net/janneoevans/article/details/8125106
2012年10月29日 17:04:09 大猫Kevin 阅读数:5844
Kevin.Liu 2012/10/20 ~2012/10/27 内核版本:2.6.24
博客:http://janneo.blog.sohu.com
Linux2.6.24内核,调度器章节的笔记
linux调度原理
linux调度器
本文只是为了方便今后复习整理的读书笔记,仅仅是将现有的知识用我自己的语言(和图画)进行重新表述,没有什么所谓的原创,都是参考他人的或者参考linux内核源码及文档。
博客中图片丢失,排版也不方便,因此建议下载pdf文档,地址:http://download.csdn.net/detail/janneoevans/4699128
主要参考《深入理解Linux内核架构》(Wolfgang Mauerer)一书。
另外还参考了:
| 对switch_to的理解 |
http://home.ustc.edu.cn/~hchunhui/linux_sched.html#sec9 和 郭海林 同学的ppt |
| 主调度器执行的时机 |
http://www.linuxdiyf.com/linux/201107/648.html |
| 进程的状态切换 |
http://www.ibm.com/developerworks/linux/library/l-task-killable/ |
| 虚拟运行时间部分 |
http://blog.csdn.net/ustc_dylan/article/details/4140245 |
| 组调度 |
http://book.51cto.com/art/201005/200918.htm |
题外话
此文对linux内核的理解或者表述很有可能出现多处谬误,希望您在读的时候保持怀疑的态度。如果发现错误了希望您能帮我指出,免得此文误导更多人,谢谢!
注意:文中出现的名字“队列”仅仅是一个普通中文名词,表示具有先后顺序的一串事物,不是指抽象数据结构中先进先出的结构体queue.
本文章也是“吃百家饭”而成的,可以任意转载,不要求注明原作者,但是你得保证我在更新了文章中的错误时,你也能够及时更新你转载的副本,否则错误会蔓延下去。
目录
Linux2.6.24内核,调度器章节的笔记...1
1. 调度器相关的功能结构概述...2
1.1. 运行(Run Queue)队列...2
1.2. 核心调度器...3
1.1.1. 主调度器...3
1.1.2. 周期性调度器...4
1.3. 调度器类...5
2. 就绪进程在队列中如何排序的...7
2.1. 实时进程...7
2.2. 普通进程...8
2.2.1. 模型建立...9
2.2.2. 抽象模型的总结...18
2.2.3. 真实模型概述...18
2.2.4. 对应关系...21
2.2.5. 真实模型详述...22
3. 进程优先权...30
4. 核心调度器...35
4.1. 周期性调度器...36
4.2. 主调度器...42
4.2.1. 代码块1.43
4.2.2. 代码块2.43
4.2.3. 代码块3.44
4.2.4. 代码块4.45
4.2.5. 总结...46
4.2.6. switch_to.47
5. 进程的状态切换...54
Linux2.6.24内核,调度器章节的笔记
本文只是为了方便今后复习整理的读书笔记,仅仅是将现有的知识用我自己的语言(和图画)进行重新表述,没有什么所谓的原创,都是参考他人的或者参考linux内核源码及文档。
主要参考《深入理解Linux内核架构》(Wolfgang Mauerer)一书。
另外还参考了:
| 对switch_to的理解 |
http://home.ustc.edu.cn/~hchunhui/linux_sched.html#sec9 和 郭海林 同学的ppt |
| 主调度器执行的时机 |
http://www.linuxdiyf.com/linux/201107/648.html |
| 进程的状态切换 |
http://www.ibm.com/developerworks/linux/library/l-task-killable/ |
| 虚拟运行时间部分 |
http://blog.csdn.net/ustc_dylan/article/details/4140245 |
| 组调度 |
http://book.51cto.com/art/201005/200918.htm |
题外话
此文对linux内核的理解或者表述很有可能出现多处谬误,希望您在读的时候保持怀疑的态度。如果发现错误了希望您能帮我指出,免得此文误导更多人,谢谢!
注意:文中出现的名字“队列”仅仅是一个普通中文名词,表示具有先后顺序的一串事物,不是指抽象数据结构中先进先出的结构体queue.
本文章也是“吃百家饭”而成的,可以任意转载,不要求注明原作者,但是你得保证我在更新了文章中的错误时,你也能够及时更新你转载的副本,否则错误会蔓延下去。
目录
Linux2.6.24内核,调度器章节的笔记... 1
1. 调度器相关的功能结构概述... 2
1.1. 运行(Run Queue)队列... 2
1.2. 核心调度器... 3
1.1.1. 主调度器... 3
1.1.2. 周期性调度器... 4
1.3. 调度器类... 5
2. 就绪进程在队列中如何排序的... 7
2.1. 实时进程... 7
2.2. 普通进程... 8
2.2.1. 模型建立... 8
2.2.2. 抽象模型的总结... 17
2.2.3. 真实模型概述... 18
2.2.4. 对应关系... 21
2.2.5. 真实模型详述... 22
3. 进程优先权... 30
4. 核心调度器... 34
4.1. 周期性调度器... 36
4.2. 主调度器... 42
4.2.1. 代码块1. 43
4.2.2. 代码块2. 43
4.2.3. 代码块3. 43
4.2.4. 代码块4. 45
4.2.5. 总结... 45
4.2.6. switch_to. 47
5. 进程的状态切换... 54
1. 调度器相关的功能结构概述
在学习调度器前,先从整体上做一个了解,对整体构成有一个清晰的认识,然后在深入细节,才不会像我一样在学习的过程中迷失在细节里。
1.1. 运行(Run Queue)队列
原理概述
linux内核用结构体rq(struct rq)将处于就绪(ready)状态的进程组织在一起。
rq结构体包含cfs和rt成员,分别表示两个就绪队列:cfs就绪队列用于组织就绪的普通进程(这个队列上的进程用完全公平调度器进行调度);rt就绪队列用于用于组织就绪的实时进程(该队列上的进程用实时调度器调度)。
在多核系统中,每个CPU对应一个rq结构体。
Figure.就绪队列简要示意图

细节
cfs队列实际上是用红黑树组织的,rt队列是用链表组织的。
在这里只需要知道如下性质就行了:红黑树是一种二叉搜索树,大小关系是:左孩子<父节点<右边,即最左边的节点的值最小(如果对该内容感兴趣可以参考数据结构和算法分析相关书籍)。
有几个CPU就会有几个rq结构体,所有的结构体保存在 一个数组中(即runqueues)。
1.2. 核心调度器
原理概述
进程调度与两个调度函数有关:scheduler_tick()和schedule(),这两者分别被称作周期性调度器(或周期性调度函数)和主调度器(或主调度函数)。两者合在一起被称作通用调度器(或者核心调度器)(这里一定要分清几个名词分别代表什么意思,不要像我第一次读到书中这个部分时一样,搞定一头雾水,完全不知所云)
1.1.1. 主调度器
在我们通常的概念中:调度器就负责将CPU使用权限从一个进程切换到另一个进程。完成这个工作的这其实就是Linux内核中所谓的主调度器。

上图中,三种不同颜色的长条分别表示CPU分配给进程A、B、C的一小段执行时间,执行顺序是:A,B,C。竖直的虚线表示当前时间,也就是说;A已经在CPU上执行完CPU分配给它的时间,马上轮到B执行了。这时主调度器shedule就负责完成相关处理工作然后将CPU的使用权交给进程B。
总之,主调度器的工作就是完成进程间的切换。
1.1.2. 周期性调度器
再来看看周期性调度器都干些什么吧。同样是刚才的那幅图,不过现在我们关注的不是从进程A切换到进程B这个过程,而是把A在CPU上执行的过程放大后观察细节。
在A享用它得到的CPU时间的过程中,系统会定时调用周期性调度器(即定时执行周期性调度函数scheduler_tick())。
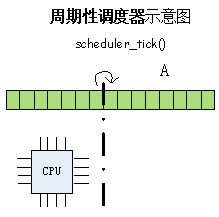
在此版本的内核中,这个周期为10ms(这个10ms是这样得来的:内中定义了一个宏变量:HZ=100,它表示每秒钟周期性调度器执行的次数,那么时间间隔t=1/HZ=1/100s=10ms。10ms是个什么概念呢,我们粗略地计算一下:如果周期性调度程序每次执行100条指令,每秒执行100次,那么一秒钟周期性调度器在CPU上执行的指令就是1万条。如果主频为1GHz的处理器每秒钟执行10亿条指令,就相当于,周期性调度器消耗的CPU只占CPU总处理能力的 1万/10亿=10万分之一,微乎其微)。为了方便理解,上图将A获得的时间段分成长度为10ms的小片(注意:只是为了方便讲解,假想成这样的,内核并没有做这样的划分)。
周期性调度器每10ms执行一次,那它都干了些什么呢?它只是更新了一些统计信息。例如:进程A的结构体的成员sum_exec_runtime记录了A在CPU上运行的总时间,周期性调度器会更新该时间为:sum_exec_runtime+=10ms(这种说法不准确,细节信息后续内容会讲到)。
我第一次在书中看到周期性调度器的时候,就没法儿理解,它又不负责进程切换,怎么能称之为调度器呢,这未免也太误导读者了吧。要记住一点:它不负责进程切换。
细节
周期性调度器是用中断实现的:系统定时产生一个中断,然后在中断过程中执行scheduler_tick()函数,执行完毕后将CPU使用权限还给A(有可能不会还给A了,细节后续在讨论),下一个时间点到了,系统会再次产生中断,然后去执行scheduler_tick()函数。(中断过程对进程A是透明的,所以A是一个傻子,它以为自己连续享用了自己得到的CPU时间段,其实它中途被scheduler_tick()中断过很多次)。
小结:
主调度器负责将CPU的使用权从一个进程切换到另一个进程。周期性调度器只是定时更新调度相关的统计信息。
1.3. 调度器类
原理概述
内核中定义了很多用于处理不同类型进程(普通进程、实时进程、idle进程)的处理函数,例如:将普通进程放入就绪队列的函数:enqueue_task_fair(),将实时进程放入就绪队列的函数enqueue_task_rt()。
调度器需要用到这些函数,如果需要将睡眠的进程重新放入就绪队列,会调用enque_task_XXX()函数。那么,调用哪一个?答:先判断该进程是什么类型的进程,如果是普通进程就调用enqueue_task_fair(),如果是实时进程就调用enqueue_task_rt()。(如下图)
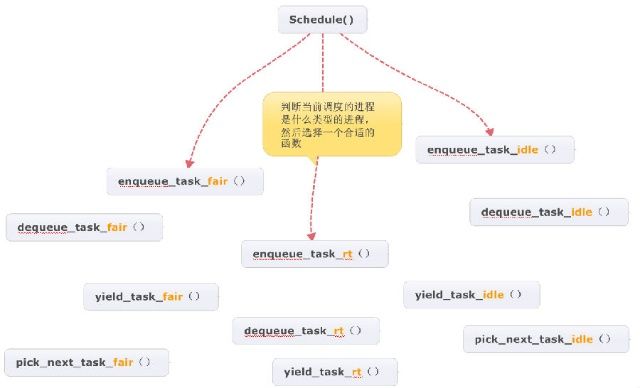
这固然可行,但是内核不是这样做的。Linux内核把这些用于处理普通进程的函数用结构体实例fair_sched_class(该结构体的成员全是指向函数的指针)组织起来,把用于处理实时进程的函数用结构体实例rt_sched_class组织起来,把用于处理idle进程的函数用idle_sched_class组织起来。
然后将普通进程关联到fair_sched_class(task_A->sched_class= fair_sched_class),实时进程关联到rt_sched_class,idle进程关联到idle_sched_class,那么需要用到相关函数的时候就不需要判断进程是什么类型的了,而是直接调用该进程关联的函数就行了(如:task_A->sched_class->enqueue_task(rq,p, wakeup, head);)。

2. 就绪进程在队列中如何排序的
对linux内核调度器有了大概的了解,现在我们接着进入细节的学习。
首先看一看各个进程在就绪队列中究竟是怎样进行先后排序的(即,如何决定进程被调度的先后顺序)。
2.1. 实时进程
原理概述
所有就绪的的实时进程都被组织在rq结构体中的rt(struct rt_rq)就绪队列上,它的排序非常简单。
相同优先等级的实时进程被组织在同一个双向链表中。在本版本的内核中,实时进程的优先等级从[0~99],共100个等级,因此就有100个这样的链表。每个链表的表头记录在rt.active.queue中。
active是rt(struct rt_rq)的一个成员,是struct rt_prio_array类型的:
kernel/sched.c
struct rt_rq {
struct rt_prio_array active;
...
};
struct rt_prio_array的定义如下:
kernel/sched.c
struct rt_prio_array {
DECLARE_BITMAP(bitmap, MAX_RT_PRIO+1); /* include 1 bit fordelimiter */
struct list_head queue[MAX_RT_PRIO];
};
它包含两个成员,一个数组queue,用来存放各个优先级的实时进程的链表头。另一个是一个位图。位图中每一位对应一个实时进程的链表,如果优先级为5的链表上没有进程,那么为图中第5位就为0,反之则为1。如下图:
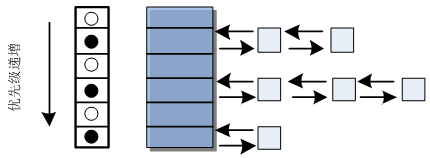
调度器选择实时进程进程执行时,先在优先级高的链表上查找,如果没有再依次找优先级低的。在同一个优先级中,进程被调度的先后顺序就是它在链表中的先后顺序。
2.2. 普通进程
原理概述
所有就绪的普通进程被组织在rq结构体中的cfs(struct cfs_rq)就绪队列上。这里为了方便把它称作"队列",它实际上是用红黑树进行组织的,红黑树是一种二叉搜索树:左孩子的值小于父节点,右孩子的值大于父节点,即最小的会出现在红黑树最左边。如下图所示:
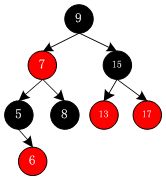
红黑树的具体细节不做讨论,只需要记住排在最左边进程最先执行就行了。接下来的讨论中我们不关心它如何使使用红黑树进行组织的,只是简单地把它看做是一个具有先后顺序的队列就行了(再次提醒,这里的“队列”仅仅指具有先后顺序的一串事物,不是指抽象数据结构中先进先出的结构体queue)。
这个版本的linux内核中用于决定就绪进程在就绪队列中先后顺序的机理很简单,也很巧妙。直接讲它怎么实现的,对于读者来说要听明白应该也是轻而易举的;但是对于表述能力如此差的我来说,要讲明白则太过于勉强了,所以我就从最简单的"模型"开始一步一步构建"真实模型"。
提示:这一部分内容对调度器的理解不是特别重要,在这里却占用了很多的篇幅,如果不感兴趣最好是直接跳过,直接从进程优先权看起,或者先看完后面的内容,再回头看这部分。
以下内容,为了讲解方便,可能运用了类似于时间片的讲述方法,可能会让读者误以为该版本linux内核采用了时间片的管理方式。因此,需要特别声明一下,早期的内核中有时间片的概念,但是该版本的内核已经没有时间片的概念了。
细节
2.2.1. 模型建立
A. runtime公平模型
原理概述
这个模型的主要目的是要让各个进程尽可能的公平享用CPU时间。其机理如下:
CPU的总时间按就绪的进程数目等分给每个进程,每个进程在就绪队列中的先后顺序由它已享用的CPU时间(runtime)决定,已享用CPU时间短的排在队列的排前面,反之则排在队列后面。
为了好好阐述这个模型是怎么运作的,我们模拟一下进程被调度的过程:调度器每次在所有可运行的进程中挑一个runtime值最小的,让它运行4ms(进程也可以在这4ms还没用完的时候中途释放CPU),刚刚被选中的进程运行完4ms后,调度器再重新挑一个runtime值最小的。规定每次最多执行4ms是为了防止某个进程一直占用CPU不释放而提出的。记住我们这个模型的机理,下面根据一个例子看看具体调度流程什么怎样的:
a)初始的时候,三个进程都没有运行因此,runtime都等于0
| 进程 |
A |
B |
C |
|
| runtime(ms) |
0 |
0 |
0 |
|
| 按runtime进行排序 |
A B C |
|||
b) 由于runtime值都等于0,假设初始顺序是A B C。那么将A放到CPU上执行,它执行了4ms后:
| 进程 |
A |
B |
C |
| runtime(ms) |
4 |
0 |
0 |
| 按runtime进行排序 |
B C A |
||
c) 按进程排列的顺序,接下来该B执行,假设B只执行了2ms
| 进程 |
A |
B |
C |
| runtime(ms) |
4 |
2 |
0 |
| 按runtime进行排序 |
C B A |
||
d) 假设B执行了2ms的时候产生特殊事件激活了调度器,调度器选择下一个进程执行。进程C的runtime最小,因此选择C。
C执行了4ms:
| 进程 |
A |
B |
C |
| runtime(ms) |
4 |
2 |
4 |
| 按runtime进行排序 |
B A C |
||
假设执行情况是这样的:进程在执行的时候需要从就绪队列中取下来,执行完毕后再放入就绪队列中(真实情况差不多上也是这样的,只是有一点小小的不同)。这就可以解释,为什么C和A有相同的runtime值,而C却排在A后面了。
e) 进程B的runtime值最小,接下来轮到进程B执行,B执行了4ms
| 进程 |
A |
B |
C |
| runtime(ms) |
4 |
6 |
4 |
| 按runtime进行排序 |
A C B |
||
这就是最简单的模型:CPU总是挑已经执行时间最短的那个进程到CPU上运行。最简单的模型往往有很大的漏洞,我们接着往下看。
B. min_runtime公平模型。
原理概述
这个模型的主要目的是要让各个进程尽可能的公平享用CPU时间。其机理如下:
CPU的总时间按就绪的进程数目等分给每个进程,每个进程在就绪队列中的先后顺序由它已享用的CPU时间(runtime)决定,已享用CPU时间短的排在队列的排前面,反之则排在队列后面。
为了好好阐述这个模型是怎么运作的,我们模拟一下进程被调度的过程:调度器每次在所有可运行的进程中挑一个runtime值最小的,让它运行4ms(进程也可以在这4ms还没用完的时候中途释放CPU),刚刚被选中的进程运行完4ms后,调度器再重新挑一个runtime值最小的。规定每次最多执行4ms是为了防止某个进程一直占用CPU不释放而提出的。记住我们这个模型的机理,下面根据一个例子看看具体调度流程什么怎样的:

a)初始的时候,三个进程都没有运行因此,runtime都等于0
| 进程 |
A |
B |
C |
|
| runtime(ms) |
0 |
0 |
0 |
|
| 按runtime进行排序 |
A B C |
|||
b) 由于runtime值都等于0,假设初始顺序是A B C。那么将A放到CPU上执行,它执行了4ms后:
| 进程 |
A |
B |
C |
| runtime(ms) |
4 |
0 |
0 |
| 按runtime进行排序 |
B C A |
||
c) 按进程排列的顺序,接下来该B执行,假设B只执行了2ms
| 进程 |
A |
B |
C |
| runtime(ms) |
4 |
2 |
0 |
| 按runtime进行排序 |
C B A |
||
d) 假设B执行了2ms的时候产生特殊事件激活了调度器,调度器选择下一个进程执行。进程C的runtime最小,因此选择C。
C执行了4ms:
| 进程 |
A |
B |
C |
| runtime(ms) |
4 |
2 |
4 |
| 按runtime进行排序 |
B A C |
||
假设执行情况是这样的:进程在执行的时候需要从就绪队列中取下来,执行完毕后再放入就绪队列中(真实情况差不多上也是这样的,只是有一点小小的不同)。这就可以解释,为什么C和A有相同的runtime值,而C却排在A后面了。
e) 进程B的runtime值最小,接下来轮到进程B执行,B执行了4ms
| 进程 |
A |
B |
C |
| runtime(ms) |
4 |
6 |
4 |
| 按runtime进行排序 |
A C B |
||
这就是最简单的模型:CPU总是挑已经执行时间最短的那个进程到CPU上运行。最简单的模型往往有很大的漏洞,我们接着往下看。
B. min_runtime公平模型。
刚刚讨论的runtime有一个致命的缺陷:
假设系统中只有A,B,C三个进程,并且这三个进程都各自运行了1000ms,那么他们的vruntime为:
| 进程 |
A |
B |
C |
| runtime(ms) |
100 |
150 |
200 |
此时,进程D被创建了,它没有享用过CPU时间,因此它的runtime=0。这就产生大问题了,在接下来的100ms内,调度器总是会让进程D在CPU上执行,直到它运行了100ms以上。
如果你觉得这不是问题的话,你考虑一下这个情况:在已经运行了三年的服务器上,进程A,B,C的runtime都等于1年,这时进程D被创建了,那么接下来的一年内,就只有进程D在运行,其他的进程就慢慢等吧!
细节
谈到这里,我们就简单讨论一下什么叫“公平”吧。
假设进程A,B,C是同时创建并加入就绪队列的。
我的理解是:“操作系统应该在‘当前’将时间公平分配给‘当前’系统中的每个进程”。“当前”意味着什么:
a) 进程A,B,C在系统中共同经历了100+150+200=450ms,它们应该公平享用这段时间,即,每个进程应当执行150ms。
b) D进程被创建了,那么从现在起操作系统应该将CPU时间公平分配给这四个进程。
也就是说,从每个进程创建之时起,它就应该受到“不计历史”的公平待遇——无论其他进程之前运行了多长时间,当前的所有进程都应当一视同仁。
在这种情况下就很好办,如果A,B,C的runtime都等于150ms,那么D被创建的时候,也将它的runtime设置成150ms即可,这样在接下来的一段时间内,这四个进程会基本上公平地享用CPU时间。
然而,这只是我们的理想状态,因为第一点 a) 已经被打破了:A,B,C在过去的450ms内已经没有公平享用这段时间了。我们总不能等到A,B也执行了150ms之后才允许进程D被创建吧。
那么,我们要将D的runtime设置成多少才能:1.使得从现在起A,B,C,D进程尽可能地受到公平待遇。2.还要体现出进程A,B在前450ms内受到了不公平待遇。
如果将D的runtime设置为A,B,C中runtime最大的值显然对进程D不公,如果设置为他们中的最小值,那又对进程A不公。我们姑且先将进程D的runtime设置为A,B,C中最小的那个值(即100ms),这个处理方法显然达不到我们的目的,不过,总比将D->runtime设置成0要好多了。(具体怎么处理的,我们留到后面再讲)
这就是我们在runtime公平模型上改进之后得到的min_runtime公平模型。
C. weight优先级模型
原理概述
刚刚讨论了“公平”的问题,然而,在真实系统中,不同的进程具有不同的重要性。重要的进程我们应该尽量多分配CPU时间,不重要的进程应该少分配CPU时间。
为了达到这个目的,我们引入一个权重(weight)参数。即,每个进程有一个权重值,进程得到的CPU时间和这个权重值成正比。
基于刚才的min_runtime公平模型,我们怎样才能引入weight这个参数呢?
刚才的条件不变:
a) 调度器总是选择runtime值最小的进程放到CPU上执行。
b) 每次执行不得超过4ms,执行完4ms后或者因为某些事件中途激活了调度器,再选一个runtime值最小的(如果当前进程的runtime值最小,就还会选中它执行)。
c) 新创建的进程的runtime设置为当前可运行进程中最小的runtime值。
分析
假设进程A,B的权重分别是1,2,怎样才能使得在一段时间内进程B执行的时间是进程A的2倍呢?
在公平模型中我们用runtime来对进程进行排序,runtime小的排在前面:当进程A,B都分别执行了12ms(runtime都等于12)时,如果轮到进程B运行,它最多再运行4ms(B的runtime变成了16),调度器就会将CPU时间切换给进程A。
很容易发现,如果不在runtime上下功夫的话,进程B最多比进程A多执行4ms(除非进程A是个瞌睡虫,经常睡眠;别试图用催眠进程A的方法来解决该问题,这代价太大了。即便代价很小,那进程A醒来之后又总会排在进程B前面)。
换一个角度考虑,我们就很容易发现解决该问题的方法。我们想要达到这样一个效果:A进程执行了N ms后以及B进程执行了2N ms后他们应当具有相同的先后顺序,即他们的runtime值基本相同。
我们用runtime表示进程已经运行的时间,显然和以上表述矛盾,因此我们用另一个参数vruntime(虚拟运行时间)代替它。
我们检验一下是否可行:假设进程A每执行1ms,它的vruntime值就增加1。进程B每2ms,它的vruntime才增加1。(vruntime仅仅是一个数值,用来作为对进程进行排序的参考,不用来反映进程真实执行时间,别像我一样看书看到这一部分时一样陷入理解误区)
我们仍然用之前的过程模拟一下:

a) 初始的时候两个个进程都没有运行,runtime都等于0。
| 进程 |
A |
B |
|
| weight |
1 |
2 |
|
| runtime(ms) |
0 |
0 |
|
| vruntime |
0 |
0 |
|
| 按vruntime进行排序 |
A B |
||
b) 假设初始顺序为A在前,调度器选择了A,它运行了4ms:
| 进程 |
A |
B |
|
|
| weight |
1 |
2 |
|
|
| runtime(ms) |
4 |
0 |
|
|
| vruntime |
4 |
0 |
|
|
| 按vruntime进行排序 |
B A |
|||
c) B的vruntime最小,选择B运行,运行了4ms:
| 进程 |
A |
B |
| weight |
1 |
2 |
| runtime(ms) |
4 |
4 |
| vruntime |
4 |
2 |
| 按vruntime进行排序 |
B A |
|
d) B的vruntime依旧最小,选择B运行,运行了4ms:
| 进程 |
A |
B |
|
|
| weight |
1 |
2 |
|
|
| runtime(ms) |
4 |
8 |
|
|
| vruntime |
4 |
4 |
|
|
| 按vruntime进行排序 |
A B |
|||
e) vruntime相同,但是A在前,选择A运行,运行了4ms:
| 进程 |
A |
B |
| weight |
1 |
2 |
| runtime(ms) |
8 |
8 |
| vruntime |
8 |
4 |
| 按vruntime进行排序 |
B A |
|
f) B的vruntime依旧最小,选择B运行,运行了4ms:
| 进程 |
A |
B |
| weight |
1 |
2 |
| runtime(ms) |
8 |
12 |
| vruntime |
4 |
6 |
| 按vruntime进行排序 |
B A |
|
通过简单的模拟,我们发现vruntime的引入,果然达到了目的。
那么从现在起忘掉之前提出的runtime,取而代之的是vruntime:每个进程有一个vruntime值,调度器总是选择vruntime值最小的进程,放到CPU上执行,并且vruntime增长的速度和weight值成反比(为了节约篇幅,这里就不证明为什么vruntime的增长速度要这样设定了)。
D. period模型
原理概述
早期版本中用到了时间片模型,从这个版本的内核开始就没有使用时间片的概念了。
在之前的模型中,每当进程运行4ms后(或者进程还未执行完4ms,就有特殊情况产生了:比如进程要睡眠)主调度器(schedule)就会重新选择一个vruntime值最小的进程来执行。现在我们不用时间片的概念了,那么主调度器(schedule)应该在什么时候启动并选择一个新的进程执行呢?
为了解决这个问题,我们引入一个叫period的参数。
这个模型也很简单:
系统设定了一个period值(它表示一段时间),每个进程对应一个ideal_runtime值(称为理想欲运行时间)每个进程的ideal_runtime值是这样设定的:所有可运行进程的ideal_runtime值之和等于period,每个进程的ideal_runtime值的大小与它的权重weight成正比。
这个模型规定:每个进程每次获得CPU使用权,最多执行它对应的ideal_runtime这样长的时间。
例如:如果period=20ms,当前系统中只有A,B,C,D四个进程,它们的权重分别是:1,2,3,4。那么A的ideal_runtime=2ms,B,C,D的ideal_runtime依次为4ms,6ms,8ms。
我们就模拟一下这例子中各个进程的运行过程吧:

a) 初始情况如下:
| 进程 |
A |
B |
C |
D |
|
| weight |
1 |
2 |
3 |
4 |
|
| ideal_runtime(ms) |
2 |
4 |
6 |
8 |
|
| runtime(ms) |
0 |
0 |
0 |
0 |
|
| vruntime |
0 |
0 |
0 |
0 |
|
| 按vruntime进行排序 |
A B C D |
||||
b) 和前一个模型一样,vruntime的行走速度和权重值长反比,假设权重为1的A进程的vruntime和实际runtime行走速度相同。A先执行,它执行了2ms,此时:
| 进程 |
A |
B |
C |
D |
|
| weight |
1 |
2 |
3 |
4 |
|
| ideal_runtime(ms) |
2 |
4 |
6 |
8 |
|
| runtime(ms) |
2 |
0 |
0 |
0 |
|
| vruntime |
2 |
0 |
0 |
0 |
|
| 按vruntime进行排序 |
B C D A |
||||
c) A执行时间等于它的ideal_runtime了,调度器被激活,它重新选择一个vruntime值最小的进程(即B)执行,假设B运行了3ms:
| 进程 |
A |
B |
C |
D |
|
| weight |
1 |
2 |
3 |
4 |
|
| ideal_runtime(ms) |
2 |
4 |
6 |
8 |
|
| runtime(ms) |
2 |
3 |
0 |
0 |
|
| vruntime |
2 |
1.5 |
0 |
0 |
|
| 按vruntime进行排序 |
C D B A |
||||
d) 假设此时某特殊事件激活了调度器,调度器进行重新调度,它仍然选择vruntime最小的,即C进程,C进程运行了3ms:
| 进程 |
A |
B |
C |
D |
|
| weight |
1 |
2 |
3 |
4 |
|
| ideal_runtime(ms) |
2 |
4 |
6 |
8 |
|
| runtime(ms) |
2 |
3 |
3 |
0 |
|
| vruntime |
2 |
1.5 |
1 |
0 |
|
| 按vruntime进行排序 |
D C B A |
||||
e) 假设此时又有某特殊事件产生,激活了调度器,调度器进行重新调度,选择进程D,它运行了8ms:
| 进程 |
A |
B |
C |
D |
|
| weight |
2 |
2 |
3 |
4 |
|
| ideal_runtime(ms) |
2 |
4 |
6 |
8 |
|
| runtime(ms) |
2 |
3 |
3 |
8 |
|
| vruntime |
2 |
1.5 |
1 |
2 |
|
| 按vruntime进行排序 |
C B A D |
||||
细节
f) 进程D运行的时间等于它的ideal_runtime,调度器被激活,重新选择一个进程运行,接着进程C被选中。
这一点很关键:C可以运行多长时间呢?也许你有可能跟我一样认为C最多可以运行3ms,因为它的ideal_runtime为6ms,而它之前已经运行了3ms。
如果是这样的你可能就误解了,在看看之前对ideal_runtime的定义,它只是要求,每个进程每次没调度的时候,运行时间不能超过它对应的ideal_runtime,上次进程C被调度的时候它只执行了3ms,没有超过它的ideal_runtime(6ms);但是,这次它又可以获得CPU使用权了,是新的一次调度了,与之前无关。因此,进程C最多可以运行6ms,那么接下来进程C运行了6ms:
| a. 进程 |
A |
B |
C |
D |
|
| weight |
1 |
2 |
3 |
4 |
|
| ideal_runtime(ms) |
2 |
4 |
6 |
8 |
|
| runtime(ms) |
2 |
3 |
9 |
8 |
|
| vruntime |
2 |
1.5 |
3 |
2 |
|
| 按vruntime进行排序 |
B A D C |
||||
上面模拟了这么多步执行过程,最关键的就是第f)步。如果你理解错了(多半是前面的对period定义误导你了),认为C这次被调度最多可以执行3ms,那么我想你很可能认为:系统将CPU时间划分成一段一段的,每片长度为period,并且将他们按权重值分配给各个进程,并且规定它们在该period内最多执行ideal_runtime限定的时间,进入下一个period时间段后,系统又重新为各个进程分配ideal_runtime。
如果这么理解的,那就有问题了。注意:CPU并没有把时间分成长度为period的时间段,系统仅仅限定了每个进程每次执行时不能超过它对应的ideal_time指定的时间长度。
我们这个简单的机制起到了这样一个作用:每个进程在就绪队列中等待的时间不会超过period,因为每个人进程获得CPU使用权后,如果它执行的时间等于它的ideal_runtime,那么它的vruntime基本上也就比其他所有进程的vruntime值高了,自然会排到队列的后面。(例如:上述A,B,C,D进程,如果A进程执行了2ms,B执行了4ms,C执行了6ms,他们的vruntime都等于2,即他们的vruntime肯定大于队列中那些还没被调度执行的进程的vruntime。注明:这里先不考虑睡眠的问题,睡眠的问题放到后面再讨论)
小结
这个模型实现了这样一个效果:
a) 每个进程每次获得CPU使用权最多可以执行与它对应的ideal_runtime那么长的时间。
b) 如果,每个进程每次获得CPU使用权时它都执行了它对应的ideal_runtime那么长的时间,整个就绪队列的顺序会保持不变。
c) 如果某个进程某几次获得CPU使用权时运行的时间小于它ideal_time指定的时间(即它被调度时没有享用完它可以享用的最大时间),按照vruntime进行排序的机制会使得它尽量排在其他进程前,让它尽快把没有享用完的CPU时间弥补起来。
每个进程每次被调度不再受4ms(之前提到的这个4ms并非是早期版本中时间片的大小,而是为了说明问题随便指定的)的限制了,而是可以运行"任意"长时间。
要注意:我们讨论的这些模型都是针对普通进程的,与实时进程不相关。
总结
1.1.1. 抽象模型的总结
在下面的内容中,我们将上面的“period模型”成为"抽象模型",将上述模型简单总结起来基本上就是对该版本内核运用的整个机制的一个抽象了。我们对上述的机制进行一个总结(暂不考虑睡眠,抢占等细节):
a) 每个进程有一个权重值(weight),值越大,表示该进程越优先。
b) 每个进程还对应一个vruntime(虚拟时间)值,它是根据进程实际运行的时间runtime计算出来的。vruntime值不能反映进程执行的真实时间,只是用来作为系统判断接下来应该将CPU使用权交给哪个进程的依据——调度器总是选择vruntime值最小的进程执行。
c) vruntime行走的速度和进程的weight成反比。
d) 为了保证每个进程在某段时间(period)内每个进程至少能执行一次,操作系统引入了ideal_runtime的概念,规定每个进程每次获得CPU使用权时,执行时间不能超过它对应的ideal_runtime值。达到该值就会激活调度器,让调度器再选择一个vruntime值最小的进程执行。
e) 每个进程的ideal_runtime长度与它的weight成正比。如果有N个进程那么:
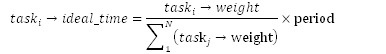
1.1.1. 真实模型概述
细节
总结完抽象模型,我们接下来看看内核代码究竟是如何实现的吧。
先来从宏观上来看看,下图是一个(完全公平)就绪队列,就绪队列上有三个进程。

cfs_rq结构体
接下来看看内部,先看看就绪队列的结构体和调度相关的成员变量(蓝色的是与之前谈到的抽象模型有对应参数的):

成员的定义如下:
a) min_vruntime
我想你应该还记得,在讲min_runtime公平模型中遗留留下了一个问题:如果进程A,B,C在系统中运行了一段时间他们的runtime分别是100ms,150ms,200ms,新进程D被创建时它的runtime应该设置成什么?另外,如果进程D不是新创建的,而是睡眠很久之后醒来的,也会引发类似的问题。而这个变量就是用来解决这两个问题的(注意:并不是把进程D的vruntime值直接设置为该值,具体细节后续内容会讲到)。min_vruntime用来“跟踪”可运行进程中最小的vruntime值。之所以用“跟踪”一词,是因为它在某些情况下有的进程的vruntime值会比它小。min_vruntime的值初始的时候为0,周期性调度器负责周期性地用min_vruntime的值和可运行的进程中最小的vruntime值比较,如果该进程的vruntime值比min_vruntime大,那么就将min_vruntime值更新为较大值。也就是说:min_vruntime的值只会随着时间的推移增加,不会减小。(再次提醒:这并不意味着min_vruntime的值比所有进程的vruntime都小。)
b) load
先看看这样一个结构体structload_weight,它包含两个成员:第一个是weight,它就对应我们抽象模型中的权重值weight。第二个成员inv_weight是为了方便计算用的(它其实可以用weight计算得到),暂时不用去管他。
structload_weight {
unsigned long weight, inv_weight;
};
load.weight保存着cfs_rq队列上所有进程(包括当前正在运行的进程)的权重值weight的总和。
c) nr_running
可运行进程的总数,即队列上进程的总数加上正在运行的那个进程(正在运行的进程不在就绪队列上)。
d) tasks_timeline
之前讲过,cfs就绪队列是用红黑树来组织的,tasks_timeline指向红黑树的根节点。(只要记住它是根节点就行了,关于红黑树的细节暂时不需要了解,这里不会涉及到)。
e) rb_leftmost
指向红黑树种最左边那个节点。即,vruntime值最小的那个进程对应的节点。
f) curr
指向当前正在执行的可调度实体。调度器的调度单位不是进程,而是可调度实体。每个task_struct都嵌入了一个可调度实体sched_entity,所以每个进程是一个可调度实体。可以将多个进程捆绑在一起作为一个调度单位(即,调度实体)进行调度。因此,可调度实体可以是一个进程,也可以是多个进程构成的一个组。以免把事情弄复杂,在这里我们就把调度实体和进程看做是一样的吧,暂时把curr理解为指向当前正在运行的进程就可以了。
sched_entity结构体
sched_entity是可调度实体,暂时不管它的定义,姑且把它看做是一个进程吧。sched_entity与调度相关的结构有如下几个(蓝色的是与之前谈到的抽象模型有对应参数的):
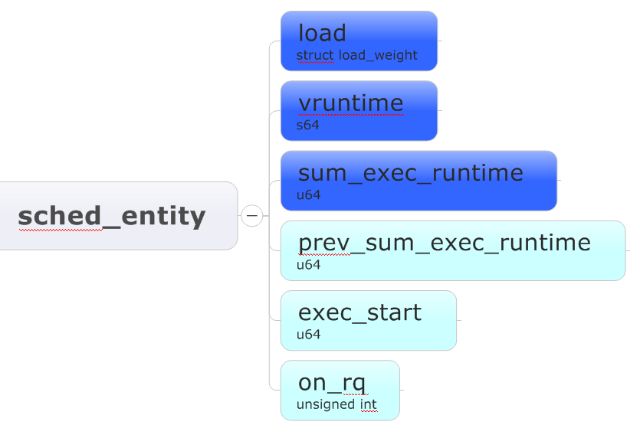
a) load,struct load_wegiht结构体,结构体中的weight值表示该进程的权重。
b) vruntime,该进程已运行的虚拟时间,就是抽象模型中的vruntime。
c) sum_exec_runtime,表示进程已经执行的实际时间,对应抽象模型中的runtime。
d) pre_sum_exec_runtime,进程在本获得CPU使用权前,总的执行时间。pre_sum_exec_runtime-sum_exec_runtime等于进程本次获得CPU使用权后执行的总时间。
e) exec_start,看它的命名好像以为它表示进程开始执行的时间,其实不是这样的。它跟周期性调度器有关。假设一个进程获得CPU使用权并连续执行10ms,在这100ms内,周期性调度器每10ms启动一次并且将进程的exec_start设置为当前时间。例如:周期性调度器在第20ms启动,并执行exec_start=now(now是当前时间)。那么到30ms时周期性再启动一次,它就可以用now-exec_start得到在这10ms时间内,进程已经消耗的CPU时间,然后再更新exec_start的值为当前时间。(这是为了准确计算进程已经消耗的CPU时间,因为理论上时间间隔是10ms,但是由于系统有延时程序真正执行的时间可能没有这么多)。
f) on_rq,用来标识该实体是否在就绪队列上,如果在就绪队列上则该值为非零,反之则为0(其实细节不是这样的,后续会讲到)。
1.1.2. 对应关系
原理概述
我们关注的是“真实模型”是如何实现的,只需关注“抽象模型”是如何和“真实模型”映射起来的就行了,因此cfs_rq结构体和task_struct结构体中不是很相关的成员暂时不用去管它,只需要做一个简单了解就行了,因为待会引用代码时会涉及到。
“抽象模型”和“真实模型”的对应关系如下(在这里,"->"仅仅是表示所属关系,不要和C语言中的操作符联系起来):
抽象模型和真实模型的对应关系
| 抽象模型 |
真实模型 |
说明 |
| task->runtime |
task->se->sum_exec_runtime |
每个进程对应一个可调度实体,在task_struct的结构体中,该实体就是成员变量se。 |
| task->weight |
task->se.load.weight |
|
| task->vruntime |
task->se.vruntime |
|
|
|
cfs_rq->load.weight |
在抽象模型中,我们计算ideal_runtime的时候需要求所有进程的权重值的和,在实现的时候,没有求和的过程,而是把该值记录在就绪队列的load.weight中。
向就绪队列中添加新进程时,就加上新进程的权重值,进程被移出就绪队列时则减去被移除的进程的权重值。 |
|
|
cfs_rq->min_vruntime |
该值用来解决之前在抽象模型中遗留的问题,所以在抽象模型中没有与之对应的值。 |
| task->ideal_runtime |
sched_slice( )函数 |
每个进程的ideal_runtime并没有用变量保存起来,而是在需要用到时用函数shed_slice( )计算得到。 公式跟抽象模型中公式一样:
|
| period |
__sched_period()函数 |
period也没有用变量来保存,也是在需要用到时由函数计算得到: 在默认情况下period的值是20ms,当可运行进程数目超过5个时,period就等于:nr_running*4ms(nr_running是可运行进程的数目。
上面提到的“20ms”由sysctl_sched_latency指定;“5”个由sched_nr_latency指定;“4ms”是由sysctl_sched_min_granularity指定的。
这样设定有它的目的,不与深究,以免迷失在细节里。 |
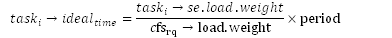
1.1.1. 真实模型详述
原理概述
讲完了变量的对应关系,我们来看看真实模型是怎么运作的。在抽象模型中vruntime决定了进程被调度的先后顺序,在真实模型中决定被调度的先后顺序的参数是entity_key(实例的键值),也是值最小的最先被调度。
这个值没有用变量保存起来,而是在需要的时候由函数entity_key()计算得到:
kernel/sched_fair.c
static inline s64 entity_key(struct cfs_rq *cfs_rq, struct sched_entity *se) {
return se->vruntime - cfs_rq->min_vruntime;
}
从entity_key()的定义可以看出,key=vruntime-cfs_rq->min_vruntime。
其实它本质和我们的抽象模型一样的,只不过对进程进行排序时不是比较各个进程的vruntime值,而是将各个进程的vruntime减去一个相同的数再比较大小。
就好像要比较A和B两个数的大小,等同于比较A-C和B-C的大小一样。(遗留问题。其实我现在还不理解它为什么要将两个数减去一个共同的值再比较大小,这不多此一举吗,是历史的原因还是有其他考虑呢?)
在这里只需要知道真实模型中比较的是键值就行了,不用深究,其本质也只是比较每个进程对应的vruntime值,vruntime小的排在队列(红黑树)前面。红黑树是二叉搜索树的一种,树上的成员的先后顺序是在插入每个成员时就决定的(为了控制树的高度,系统需要对红黑树做一些调整,但是这并不改变各个成员的先后顺序)。
__enqueue_entity()函数用于将各个执行完毕的进程(调度器选择某个进程执行前,会先把它从就绪队列中移除,执行完毕后再放回),或新的进程或刚睡眠的进程加入到就绪队列中。__enqueue_entity()函数将进程(准确地说应该是可调度实例)放在就绪队列中的位置决定了被调度的先后顺序:
kernel/sched_fair.c
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
......
//key是要插入的进程的键值
s64 key =entity_key(cfs_rq,se);
while (*link) {
//link是指向红黑树根节点的指针
parent = *link;
//不用深究这句话的细节,只需要知道
//entry的是parent节点对应的可调度实例
entry = rb_entry(parent, struct sched_entity, run_node);
s64 key =entity_key(cfs_rq, se);
//这句才是我们要关心的,它比较要插入的进程的键值
//和parent节点对应的进程的键值的大小。要插入的进程
//的键值更小,则继续遍历左子树
//反之,则遍历右子树
if (key <entity_key(cfs_rq, entry)) {
link = &parent->rb_left;
} else {
link = &parent->rb_right;
......
}
}
......
}
注意看下划线标注的地方,要插入的进程的可调度实例se和parent节点指向的可调度实例(entry)的键值大小都是通过entity_key()函数获得的。对他们键值的比较实际上是在比较se.vruntime-cfs_rq.min_vruntime,和entry.vruntime-cfs_rq.min_vruntime的大小,这正如前面所述,完全等同于比较se.vruntime和entry.vruntime的大小(除非被减项中的cfs_rq不是同一个就绪队列)。
weight
原理概述
普通进程(非实时进程)被分为40个等级,每个等级的进程对应一个权重值,权重值用一个整数来表示。这些权重值被定义在下述数组中:
kernel/sched.c
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
普通进程的权重值最大为88761,最小为15。默认情况下,普通进程的权重值为1024(由NICE_O_LOAD指定)。顺便说一下实时进程,实时进程也有权重值,它们的权重值为普通进程最大权重值的两倍(即,2X88761)。
相邻两个等级的普通进程的权重值比值约等于1.25(之所以设定这个值,是通过简单计算出来的,系统想达到这个目的:如果只有等级相邻的两个进程在运行,那么它们获得的CPU时间差值为10%)。也就是说,只要知道最小权重值是15,其他进程的权重值也就能计算出来了。但是内核为了节约计算时间,选择把已经计算好的结果存放到上述数组里了。
vruntime行走速度
原理概述
权重值有了,我们还需要知道各个进程的vruntime行走的速度。系统规定:默认权重值(1024)对应的进程的vruntime行走时间与实际运行时间runtime是1:1的关系。由于vruntime的行走速度和权重值成反比,那么其他进程的vruntime行走速度都可以通过:1.该进程的权重值,2.默认进程的权重值两个参数计算得到。
例如:权重值为15的进程它的vruntime行走速度:
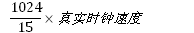
权重值为3906的进程的vruntime行走速度为:
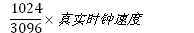
"真实时钟速度"即为runtime(英文资料成为wall clock)行走的速度。
为了更好的认识“真实模型”是如何运作的,我们来看看update_curr()这个函数(我只把相关的几条语句选出来了):
update_curr

在进程执行期间周期性调度器周期性地启动,它的工作只是更新一些相关数据,并不负责进程之间的切换。它会调用update_curr()函数,完成相关数据的更新。
第一条语句:
delta_exec= (unsigned long)(now - curr->exec_start);
是计算周期性调度器上次执行时到周期性这次执行之间,进程实际执行的CPU时间(如果周期性调度器每1ms执行一次,delta_exec就表示没1ms内进程消耗的CPU时间,这个在前面讲了),它是一个实际运行时间。
update_curr()函数内只负责计算delta_exec以及更新exec_start。更新其他相关数据的任务交给了__update_curr()函数。
__update_curr

__update_curr()函数主要完成了三个任务:1.更新当前进程的实际运行时间(抽象模型中的runtime)。2.更新当前进程的虚拟时间vruntime。3.更新cfs_rq->min_vruntime。
a) 更新当前实际运行时间之前已经讲过了,见前面sum_exec_runtime的定义。
b) 更新当前进程的vruntime。
delta_exec_weighted表示虚拟时间vruntime的增量。权重值为1024(NICE_0_LOAD)的进程,vruntime行走速度和runtime行走速度相同,那么vruntime的增量也就等于runtime的增量。所以先将 delta_exec_weighted设置为delta_exec。
下一句是判断当前进程的权重值是否是1024,如果不是1024则需要计算。这个计算任务交给calc_delta_fair()函数完成,它又定义为calc_delta_mine()函数,这个函数的实现过程稍有些复杂,这个我们暂时不关心,我们只需要知道calc_delta_fair()返回的是:
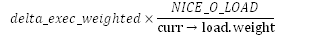
原理很简单,就是按照我们之前定义的,vruntime的增长速度与权重值成反比计算出来的。
至于为什么calc_delta_mine()函数看起来这么复杂,这里简单讨论一下吧。在上面的公式中,curr->load.weight出现在分母上,就意味着要做除法。除法的效率很低,如果我们把curr->load.weight的倒数保存起来,那么“除以weight”的计算就可以转换为乘以它倒数的计算了。就是基于这个想法(实际实现时并不是存的weight的倒数,只是基于这个想法而已,因为weight的倒数是小数,涉及到浮点运算,消耗更大),load_weight结构体中除了weight成员之外,还多了一个inv_weight成员。每个进程的inv_weight值约等于 4294967268/weight。当然每个进程对应的inv_weight值也不是临时计算的,而是提前计算好了放到数组里的:
kernel/sched.c
static const u32 prio_to_wmult[40] = {
/* -20 */ 48388, 59856, 76040, 92818, 118348,
/* -15 */ 147320, 184698, 229616, 287308, 360437,
/* -10 */ 449829, 563644, 704093, 875809, 1099582,
/* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326,
/* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587,
/* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126,
/* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717,
/* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153,
};
c) 更新cfs_rq->min_vruntime。在当前进程和下一个将要被调度的进程中选择vruntime较小的值(因为下一个要执行的进程的vruntime是就绪队列中vruntime值最小的,那么在它和当前进程中选择vruntime更小的意味着选出的是可运行进程中vruntime最小的值)。然后用该值和cfs_rq->min_vruntime比较,如果比min_vruntime大,则更新cfs_rq为它(保证了min_vruntime值单调增加)。
place_entity
细节
来分析一下place_entity()这个函数,通过它可以更进一步了解进程在就绪队列中排序的机制。下面是它的相关源代码,实际代码中会根据sched_feature查询的结果来执行部分代码,这里我把它们去掉了,这不影响我们对基本原理的研究。
kernel/Sched_fair.c
place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
{
......
vruntime = cfs_rq->min_vruntime;
if (initial)
vruntime += sched_vslice_add(cfs_rq, se);
if (!initial) {
/* sleeps upto asingle latency don't count. */
vruntime -= sysctl_sched_latency;
/* ensure we nevergain time by being placed backwards. */
vruntime = max_vruntime(se->vruntime, vruntime);
}
se->vruntime = vruntime;
......
}
place_entity()函数的功能是调整进程的虚拟时间。当新进程被创建或者进程被唤醒时都需要调整它的vruntime值(新进程在创建时需要合理设置它的vruntime值,这个我们在抽象模型中就讨论过,跟新进程一样,进程被唤醒时也是需要调整vruntime值的。)。那我们看看真实模型中是怎么实现的。
新进程被创建
原理概述
进程的ideal_time长度和weight成正比,vruntime行走速度和weight值成反比。那么,如果每个进程在period时间内,都执行了自己对应的ideal_time这么长的时间,那么他们的vruntime的增量delta_vruntime相等。又由于nice值等于0(即weight值等于1024)的进程vruntime行走速度等于runtime行走速度,如果每个进程都运行他自己对应的ideal_runtime那么长时间,那么他们vruntime的增量都等于nice值为0的进程的ideal_runtime。
例如之前举过的例子:A,B,C,D四个进程,weight值分别为1,2,3,4。period长度为20ms。那么他们的ideal_time分别为2ms,4ms,6ms,8ms。如果令weight值为1的进程的vruntime行走速度和runtime相同。那么进程A运行2ms,它的delta_vruntime便是2ms;进程B执行4ms,它的delta_vruntime也是2ms;同样的,进程C,D各自分别执行6ms,8ms它们的delta_vruntime也都是2ms。
那么,假设初始情况下A,B,C,D四个进程就按这个顺序排在就绪队列上的,它们的vruntime值都等于0。当A执行了2ms(即它的ideal_runtime)后,它的vruntime值变成了2ms,后果是:它直接被排到就绪队列的最后,只要其它进程运行的总时间没有达到自己对应的ideal_runtime值,那么它始终是排在进程A前面的。
如果初始的时候,人为地给A的vruntime加上2ms,那会起到什么效果呢?效果是:意味着它被标记为"它在本period内已经执行了它对应的ideal_time那么长的时间",只有等其他进程都执行了它们各自对应的ideal_runtime这么长的时间之后它才能被调度。对于新创建的进程,系统就是这么做的。
如果是新进程,那么initial参数为1。if(initial)中的语句会执行,它的vruntime值被设置为min_vruntime+sched_vslice_add(cfs_rq,se),sched_vslice_add()函数便是计算nice值为0的进程的ideal_runtime(即,该进程运行它对应的ideal_time这么长时间时的delta_vruntime值)。作用是将新加入的进程标记为"它在本period内已经运行了它对应的ideal_time那么长的时间",这致使它理论上会被排到就绪队列的最后,意思就是说,新加入的进程理论上(如果有所进程都执行它对应的ideal_runtime那么长的时间,且没有发生睡眠,进程终止等等特殊事件的情况下)只有等待period之后才能被调度。
细节
sched_vslice_add()调用了__sched_vslice(),计算nice值为0的进程的ideal_runtime便是由__sched_vslice()的工作完成的代码如下:
kernel/Sched_fair.c
| static u64 sched_vslice_add(struct cfs_rq *cfs_rq, struct sched_entity *se) { return__sched_vslice(cfs_rq->load.weight + se->load.weight, cfs_rq->nr_running + 1); } |
| static u64 __sched_vslice(unsigned long rq_weight, unsigned long nr_running) { u64 vslice = __sched_period(nr_running);
vslice *= NICE_0_LOAD; do_div(vslice, rq_weight);
return vslice; } |
睡眠进程被唤醒
原理概述
如果进程是在睡眠之后被唤醒的,它的vruntime值也需要更新。首先将它的vruntime值设置为cfs_rq->mini_vruntime值(这个在抽象模型中就讲过了)。然后在象征性地进行一下补偿:在该vruntime中减去sysctl_sched_latency值(就绪队列中vruntime值越小的进程越靠前,所以减去一个数是对该进程的补偿)。为什么要补偿呢?因为进程进入睡眠状态时cfs_rq->min_vruntime就大于或等于该进程的vruntime值,它在睡眠过程中vruntime值是不改变的,然而cfs_rq->min_vruntime的值却是单调增加的。相当于进程醒来之后便将它的vruntime设置为一个更大的值,那么它当然受到不公平了待遇了。补偿的量由sysctl_sched_latency给出,默认情况下是20ms,相比之下这个量并不大,即便是补偿多了,也没关系(不管进程受到的不公平待遇大还是小,一律只补偿这么多)。
后面还有一句:vruntime =max_vruntime(se->vruntime, vruntime);这句代码的意思是:如果在cfs_rq->min_vruntime的基础长补偿了sysctl_sched_latency后比它原本的vruntime还小,那么这就不是补偿,而是奖励了,这种情况下直接用它原来的vruntime就行了。
总结
真是模型讲完了,我们进行一个简单的总结:
a) 进程在就绪队列中用键值key来排序,它没有保存在任何变量中,而是在需要时由函数entity_key()计算得出。它等于

其实它等是同于用进程的vruntime来进行排序的。
b) 各个进程有不同的重要性(优先等级),越重要的进程权重值weight(task.se.load.weight)越大。
c) 每个进程vruntime行走的速度和weight值成反比。权重值为1024(NICE_O_LOAD)的进程vruntime行走速度和runtime相同。
d) 每个进程每次获得CPU使用权最多执行与该进程对应的ideal_runtime这么多时间。该时间长度和weight值成正比,它没有用变量来保存,而是在需要是用sched_slice()函数计算得出。

e) ideal_runtime计算的基准是period,它也没有用变量来保存,而是在需要是用函数__sched_period()计算得出,当可运行进程数小于等于sched_nr_latency时period等于sysctl_sched_latency;当可运行进程大于sched_nr_latency时,period等于sysctl_sched_min_granularityXnr_running.
1. 进程优先权
原理概述
前面讲到,越重要的进程权重值越大,那么权重值weight是有什么决定的呢?它是由进程的优先等级决定的。接下来我们就来讨论讨论进程的优先级。
内核使用[0~139]这140个数来表示140种优先级。
其中,优先级为[0~99]的是实时进程,优先级[100~139]的是普通进程。
task_struct

上面列出了task_struct结构体中与权限相关的几个成员:

a) static_prio,指普通进程的静态优先级(实时进程没用该参数),值越小优先级越高。静态优先级是进程启动时分配的优先级。它可以用nice()或者sched_setscheduler()系统调用更改,否则在运行期间一直保持恒定。
b) rt_priority,表示实时进程的优先级(普通进程没用该参数),它的值介于[0~99]之间(包括0和99)。注意:rt_priority是值越大优先级越高。
c) normal_prio,normal_prio是基于前两个参数static_prio或rt_priority计算出来的。可以这样理解:static_prio和rt_priority分别代表普通进程和实时进程“静态”的优先级,代表进程的固有属性。由于他们两的“单位”不同(一个是点头yes,摇头no;另一个是摇头yes,点头no),一个是值越小优先级越高,另一个是值越大优先级越高。有必要用normal_prio统一下"单位"。统一成值越小优先级越高,因此,normal_prio也可以理解为:统一了单位的“静态”优先级。
d) prio,叫做动态优先级,它表示进程的有效优先级,顾名思义,在系统中需要判断进程优先级时用的便是该参数,调度器考虑的优先级也就是它。对于实时进程来说,有效优先级prio就等于它的normal_prio(“统一单位”后的优先级)。有效优先级对普通进程来说尤为重要,进程可以临时提高优先级,通过改变prio的值实现,所以优先级的提高不影响进程的静态优先级。顺带说明一下,子进程的有效优先级prio初始划为父进程的静态优先级,而不是父进程的有效优先级(也就是说,父进程的优先级如果临时提高了,该特性不会遗传给子进程)。
e) policy, 调度策略,共有五种可能值:SCHED_NORMAL,SCHED_IDLE,SCHED_BATCH,SCHED_FIFO,SCHED_RR。普通进程的policy是前三种值之一,实时进程的policy是后两种值之一。
细节
进程p的动态优先级是用函数effective_prio(p)计算出来的:
p->prio= effective_prio(p);
kernel/sched.c
static inteffective_prio(struct task_struct *p)
{
p->normal_prio =normal_prio(p);
/*
* If we are RT tasks or we were boosted toRT priority,
* keep the priority unchanged. Otherwise,update priority
* to the normal priority:
*/
if (!rt_prio(p->prio))
return p->normal_prio;
return p->prio;
}
该函数有两个作用:1.设置了进程p的normal_prio。2.返回了进程的有效优先级。
a) 第一句话是effective_prio()函数产生的副作用,它设置了进程p的normal_prio。
来看看normal_prio()函数都干了些什么:
kernel/sched.c
| static inline int normal_prio(struct task_struct *p) { int prio;
if (task_has_rt_policy(p)) prio = MAX_RT_PRIO-1 - p->rt_priority; else prio = __normal_prio(p); return prio; } |
| static inline int__normal_prio(struct task_struct *p) { return p->static_prio; } |
MAX_RT_PRIO的值是100(也就是实时进程的优先级的最大数值加1),normal_prio()函数实际上就是了单位统一的过程。它的执行流程是这样的:如果p是实时进程,那么就返回99-rt_priority(rt_priority是值越大表示进程优先级越高,normal_priority反之,所以通过这个方式将rt_priority转换为normal_priority),如果进程p是普通进程,不需要统一"单位",那么直接返回它的静态优先级static_prio。
其中函数task_has_rt_policy是判断进程的调度策略policy是不是SCHED_FIFO和SCHED_RR中的一种,如果是则它是实时进程,返回true,反之则返回false。
__normal_prio函数上面已经列出,它只是返回静态优先级。早期内核版本中__normal_prio很复杂,需要计算,现在已经不需要计算了,但是由于历史原因或者是兼容性,该函数保留了下来。
b) 讲完了effective_prio()函数的副作用,再来看看它需要做的正事儿是什么吧。
在设置了normal_prio的值后,它接着执行了如下代码:
if (!rt_prio(p->prio))
return p->normal_prio;
return p->prio;
它判断,进程的优先级数值是否小于100,如果不是小于100则返回它的普通优先级。如果小于100,则返回它的动态优先级(有两种情况它的值会小于100:它是实时进程;或者它是普通进程,但是动态优先级prio被临时提高到100以内了)。
rt_prio的定义如下,注意它和task_has_policy的区别,task_has_policy用于判断进程是否是实时进程,而rt_prio仅仅是判断它的优先等级的值是不是落在实时进程的范围内。
static inline int rt_prio(int prio)
{
if (unlikely(prio < MAX_RT_PRIO))
return 1;
return 0;
}
综上所述:
a) prio表示进程的有效优先级。static_prio和rt_priority分别表示普通进程和实时进程固有的的优先级。normal_prio是将实时进程和普通进程的优先级统一单位,它仍然代表进程静态的优先属性。
b) 因此对于实时进程来说:prio=effective_prio()=normal_prio。normal_prio=MAX_RT_PRIO-1-rt_priority
c) 对于优先级没有提高的普通进程来说:prio=effective_prio()=normal_prio=static_prio
d) 对于优先级提高的普通进程来说:prio=effective_prio(),normal_prio=static_prio。prio的值被其他函数更改过,所以与初始时不同。
e) nice值
nice值也用来用来表示普通进程的优先等级,它介于[-20~19]之间,也是值越小优先级越高。之前讲过普通进程的优先值范围是[100~139],刚好和nice值一一对应起来:优先等级=nice值+120。nice值并不是表示进程优先级的一种新的机制,只是优先级的另一个表示而已。sys_nice()系统调用设置的是进程的静态优先级static_prio.

普通进程的静态优先等级static_prio默认为120,即nice值默认为0。
weight
之前在讲进程被调度的先后顺序是,讲到影响进程在就绪队列中的参数是进程的权重值weight。而weight是由进程的静态优先级static_prio决定的,静态优先级越高(static_prio值越小)weight值越大。静态优先级和weight是通过下面这个数组对应起来的。静态优先级为100(nice值为0)的进程,其weight值为prio_to_weight[0],静态优先级为k的(nice值为k-120)的进程,weight值为prio_to_weight[k-100]。
普通进程的默认nice值为0,即默认静态优先级为120,它的weight值为prio_to_weight[20],即1024。因此NICE_O_LOAD的值就是1024,NICE_0_LOAD的命名也就是这么来的。
很重要的规定:nice值为0的进程虚拟运行时间(vruntime)行走速度和真实运行时间(runtime)行走的速度相同。
kernel/sched.c
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
1. 核心调度器
原理概述
讲了这么多周边的东西,终于可以开始讲调度器了。核心调度器即为周期性调度器和主调度器的总称。
讲核心调度器前,先来看看相关结构体:
kernel/sched.c
struct rq {
...
unsigned long nr_running;
#define CPU_LOAD_IDX_MAX 5
unsigned long cpu_load[CPU_LOAD_IDX_MAX];
struct load_weight load;
struct cfs_rq cfs;
struct rt_rq rt;
struct task_struct *curr, *idle;
u64 clock;
...
};
在多核系统中,每个CPU对应一个rq结构体。每个rq结构体包含两个就绪队列,分别是cfs和rt。
a) cfs和rt,分别是用来组织普通进程和实时进程的就绪队列。
b) nr_running,可运行的进程总数,包含普通进程和实时进程。
c) load,记录就绪队列中所有进程的weight值的总和(跟进程的load成员一样,是一个load_weight结构体)。
d) cpu_load,它是一个数组,长度由CPU_LOAD_IDX_MAX指定。它跟踪此前的几个load历史值。
e) curr和idle,都是进程结构体指针,curr指向当前正在运行的进程,idle则指向空闲进程,每个CPU都会有一个空闲进程,当没有进程要执行时,则将CPU使用权交给空闲进程。
f) clock,rq结构体的时钟,它用于跟踪CPU的真实时间。进程的虚拟运行时间vruntime以及进程的实际运行时间sum_exec_runtime等都是根据它计算得来的。
细节
每个CPU对应一个rq结构体,所有rq结构体存放在runqueues数组中,有几个CPU数组长度就为几。
runqueues数组的定义如下:
kernel/sched.c
static DEFINE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
相关宏定义
kernel/sched.c
| #define cpu_rq(cpu) (&per_cpu(runqueues, (cpu))) |
根据CPU的编号,获取它的rq结构体 |
| #define this_rq() (&__get_cpu_var(runqueues)) |
获取当前进程的rq结构体 |
| #define task_rq(p) cpu_rq(task_cpu(p)) |
获取进程p所在的rq结构体 |
| #define cpu_curr(cpu) (cpu_rq(cpu)->curr) |
指定CPU编号,获取正在运行的进程 |
1.1. 周期性调度器
原理概述
周期性调度器,虽然名为“调度器”,但是它并不负责进程间的切换,它只负责定时更新相关的统计数据,如之前提到的进程的虚拟运行时间vruntime,进程的实际运行时间sum_exec_runtime,cfs_rq->min_vruntime等。周期性调度器是由中断实现的,系统会定时产生一个中断,然后启动周期性调度器,周期性调度器执行过程中要关闭中断,周期性调度器执行完毕后再打开中断。
周期性调度器主要做两个工作:
a) 更新相关统计量
b) 检查进程执行的时间是否超过了它对应的ideal_runtime,如果超过了,则告诉系统,需要启动主调度器(schedule)进行进程切换。
周期性调度器怎么告诉系统需要启动主调度器的呢? 注意,周期性调度器发现进程本次获得CPU使用权后执行的时间超过了ideal_runtime,它不会主动去调用schedule函数。它是这样做的:它仅仅把当前正在运行的进程的TIF_NEED_RESCHED标志位置位。由于周期性调度器是由中断完成的,而在中断返回的时候,系统会检查当前进程的TIF_NEED_RESCHED标志位,如果置位了,则启动主调度器进行进程切换。
另外需要注意的是:周期性调度器只是触发主调度器的方式之一,还有其他方式可以触发或者显式地调用主调度器。
细节
scheduler_tick
周期性调度器就是指scheduler_tick函数。系统会定时调用它(每秒钟100次,即10ms一次。这个“100”由宏定义HZ指定),除此之外,其他函数也可以调用它,例如fork()。
kernel/sched.c
void scheduler_tick(void)
{
...
__update_rq_clock(rq);
update_cpu_load(rq);
if (curr != rq->idle) /* FIXME: needed? */
curr->sched_class->task_tick(rq, curr);
...
}
scheduelr_tick()主要负责更新统计信息,在这里我们省去一些实现细节,只关注它完成的三个任务。
a) 更新时钟(rq->clock),这个任务由__update_rq_clock()完成。
b) 更新rq结构体的的cpu_load[ ]数组。它保留了5(由 CPU_LOAD_IDX_MAX指定)个历史load值,update_cpu_load(rq)则是将每个元素往后移,将最老的值从数组中移出,将当前的load添加进去。
c) 接下来更新进程的vruntime,sum_exec_runtime等参数。这任务由该进程指向的调度类所指向的task_tick()函数完成。看调度类(sched_class)结构体的定义,你会发现task_tick只是一个函数指针。如果当前进程是普通进程,它对应的sched_class的task_tick()函数指针是指向task_tick_fair()这个函数的,如果是空闲(idle)进程,它对应的sched_class的task_tick()指向的是task_tick_idle()函数,如果是实时进程则是task_tick_rt()。
原理概述
调度类
由于我在看《深入理解linux架构》的时候,对调度类的理解有很大的错误,以为它是类似于主调度器一样的功能函数,在往后看的时候更是陷入了理解误区,所以我觉得有必要再花一点篇幅来重新说明一下。

内核中定义了三个调度类(sched_class)的实例,分别是idle_sched_class,fair_shed_class和rt_sched_class。struct sched_class结构体中定义了很多函数指针,例如之前提到的task_tick。idle_sched_class实例的task_tick指针指向task_tick_idle()这个函数,fair_sched_class的task_tick()指向task_tick_fair()这个函数...。
每一个进程的task_struct有一个指向sched_class结构体的指针。如果是普通进程,这个指针指向fair_shed_class,如果是实时进程,这个指针指向rt_sched_class...。
那么这句代码的执行结果因进程而异:
curr->sched_class->task_tick(rq,curr);
如果curr是普通进程,那么上面这句代码就等同于:task_tick_fair(rq,curr);如果curr是实时进程,那么上面这句代码等他与task_tick_rt(rq,curr)...。
(在看《深入理解linux架构》中这个部分(p69)的时候,实陷入了理解误区,导致后面的内容完全无法理解。)
细节
task_tick
a) task_tick_idle
kernel/Sched_idletask.c
static void task_tick_idle(struct rq *rq, struct task_struct *curr)
{
}
上面就是task_tick_idle的函数定义,它就是一个空函数什么也不做。 也就是说,如果当前进程是idle进程,它什么也不做。(idle只是它的一个通用称呼而已,它的进程名是swapper,进程号等于0,是所有进程的祖先)
b) task_tick_fair
task_tick_fair()负责更新普通进程的统计信息。
kernel/sched_fair.c
static void task_tick_fair(struct rq *rq, struct task_struct *curr)
{
...
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
entity_tick(cfs_rq, se);
}
...
}
上面是task_tick_fair()函数的核心代码。当前版本的内核支持组调度,进程是最小的可调度实体,多个进程可以组成一个大的可调度实体,多个大的可调度实体又可以组成更大的可调度实体。例如:有进程A1,A2,A3,他们各自是一个可调度实体,由这几个进程组成的一个组A,也是一个可调度实体,那么A1,A2,A3的parent指针指向A。for_each_sched_entity函数便是依次往上遍历,直至它的最高层祖先。
#definefor_each_sched_entity(se) \
for (; se; se = se->parent)
在这里我们不讨论组调度,即这里的可调度实体就是一个进程,那么这个循环只执行一次。task_tick_fair()的代码就等同于entity_tick(cfs_rq, se)。
entity_tick
kernel/sched_fair.c
static void entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
...
update_curr(cfs_rq);
check_preempt_tick(cfs_rq, curr);
...
}
entity_tick代码很简单(上述代码省去了某些判断语句,这不影响我们对原理的分析),它就做两个事情:1.调用update_curr()函数更新相关统计量,2.调用check_preempt_tick(),检查进程本次被获得CPU使用权执行的时间是否超过了它对应的ideal_runtime值,如果超过了,则将当前进程的TIF_NEED_RESCHED标志位置位。
check_preempt_tick
kernel/sched_fair.c
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
ideal_runtime = sched_slice(cfs_rq, curr);
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
if (delta_exec > ideal_runtime)
resched_task(rq_of(cfs_rq)->curr);
}
check_preempt_tick的代码很简单,我们先来看看它吧。delta_exec是进程本次获得CPU使用权执行的时间(通过进程当前的总执行时间减去本次获得CPU使用权前执行的总时间得到)。比较delta_exec和ideal_runtime的大小,如果前者超过了后者,则调用resched_task()函数,不要受它名字的误导,这个函数不做进程切换,只是把当前进程的TIF_NEED_RESCHED标志位置位。
update_curr
update_curr()函数的主要工作是调用__update_curr()函数完成的,__update_curr()的工作在之前就讲过了。
小结
如果当前进程是普通进程,那么周期性调度器的执行流程如下(其中省略了判断语句和其他的细节):

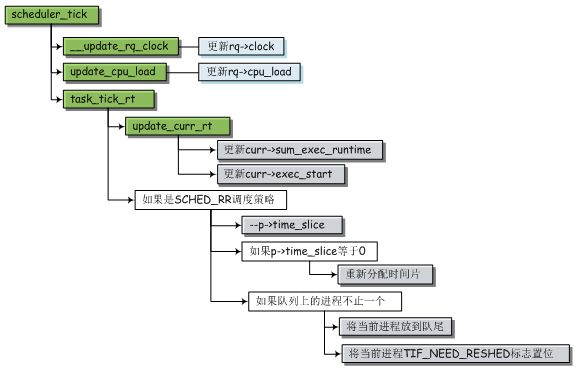
a) task_tick_rt
kernel/sched_rt.c
static void task_tick_rt(struct rq *rq, struct task_struct *p)
{
update_curr_rt(rq);
if (p->policy != SCHED_RR)
return;
if (--p->time_slice)
return;
p->time_slice = DEF_TIMESLICE;
if (p->run_list.prev != p->run_list.next) {
requeue_task_rt(rq, p);
set_tsk_need_resched(p);
}
}
实时进程的调度不涉及虚拟运行时间,所以比更新统计量的工作普通进程要简单很多。该函数首先调用update_curr_rt()函数更新当前进程的统计信息。然后根据判断条件进行必要的操作。
实时进程有两种调度策略,FIFO(先进先出)和RR(时间片轮转)。FIFO策略很简单:得到CPU使用权的进程可以执行任意长时间,直到它主动放弃CPU。RR策略呢,则是给每个进程分配一个时间片,当前进程的时间片消耗完毕则切换至下一个进程。
所以,接下来的代码,判断调度策略是不是RR,如果不是RR则无事可做。如果是RR,则将其时间片减一,如果时间片不为零,该进程可以继续执行,那么什么都不需要做。如果时间片为0,则重新给它分配时间片(长度由DEF_TIMESLICE指定),如果可运行进程大于一个,就调用requeue_task_rt()将当前进程放到实时就绪队列的末尾,并将TIF_NEED_RESCHED标志位置为,提示系统需要进行进程切换。
小结
如果当前进程是实时进程,周期性调度器的执行流程如下:
1.1. 主调度器
原理概述
主调度器的实现涉及锁的操作以及多个CPU之间的负载均衡相关的操作,这里我们就将这些细节省去,主要讲述主调度器是如何完成进程切换的。
kernel/sched.c
prev = rq->curr;
__update_rq_clock(rq);
clear_tsk_need_resched(prev);
if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {
if (unlikely((prev->state & TASK_INTERRUPTIBLE) &&
unlikely(signal_pending(prev)))) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, 1);
}
switch_count = &prev->nvcsw;
}
prev->sched_class->put_prev_task(rq, prev);
next = pick_next_task(rq, prev);
if (likely(prev != next)) {
context_switch(rq, prev, next); /* unlocks the rq */
}
为了更清晰地看到schedule函数做了些什么工作,我将它的源码分隔成几块(其中省略了其他细节相关的代码)。
1.1.1. 代码块1
schedule函数也要更新时钟(即rq->clock)。和周期性调度器一样,也是通过调用__update_rq_clock函数完成该工作的。紧着着,主调度器将当前进程的TIF_NEED_RESCHED标志位清零(周期性调度通过将该标志位置位可以间接地激活主调度器,当主调度器启动时则应当将该标志重新清零)。
1.1.2. 代码块2
下一段代码执行的工作很简单,只是判断语句看起来有些复杂。这段代码的工作是:如果当前进程之前处于睡眠状态但现在收到信号,那么将它再次提升为运行进程。如果不是这样的就让它停止活动。
进程的state是这样定义的:-1表示不可运行, 0 表示可运行, >0 表示stopped。第一个if语句和内核抢占有关,第二个if语句则是判断进程是否处于可中断睡眠状态,且收到了信号。
1.1.3. 代码块3
调用put_pre_task()函数,通知系统当前运行的进程将要被另一个进程取代。put_pre_task()仅仅做一些准备工作,并不把当前进程从就绪队列总移除。
如果当前进程是idle进程,那么它实际执行的是put_prev_task_idle()函数,该函数什么也不做。
kernel/sched_fair.c
static void put_prev_task_idle(struct rq *rq, struct task_struct *prev)
{
}
如果当今进程是实时进程,则调用update_curr_rt()函数更新相关统计信息,然后将exec_start设置为0。
kernel/sched_rt.c
static void put_prev_task_rt(struct rq *rq, struct task_struct *p)
{
update_curr_rt(rq);
p->se.exec_start = 0;
}
如果当前进程是普通进程,则是调用put_prev_task_fair()函数,该函数的工作由put_prev_entity()完成。下属代码将部分细节省去了。
kernel/sched_fair.c
static void put_prev_entity(struct cfs_rq *cfs_rq, struct sched_entity *prev)
{
/*
* If still on the runqueue thenupdate_curr() has to be done:
*/
if (prev->on_rq)
update_curr(cfs_rq);
if (prev->on_rq) {
__enqueue_entity(cfs_rq, prev);
}
}
它首先调用update_curr()函数更新相关统计信息,然后将当前进程重新放回红黑树(之前就说过,正在执行的进程会从红黑树中移出,执行完毕后,如果仍处于可运行状态,则调用__enqueue_entity()函数将它重新放回红黑树,即就绪队列)。
细节
这里需要说明一下on_rq这个成员变量,对于普通进程而言,当前正在执行的进程以及就绪队列(红黑树)中的进程on_rq的值非零。(内核把on_rq不等于0的进程称为"在就绪队列上",所以if(prev->on_rq)前面的注释语句是“如果它还在就绪队列上...”,正在运行的进程on_rq值不等于0,然后它实质却不在就绪队列中,这一点需要注意)。
下一句代码是调用pick_next_task()函数,它负责选择下一个将要执行的进程。这个函数实现很简单,它首先判断实时就绪队列(rq->rt)上有没有可运行进程(用if(rq->nr_running ==rq->cfs.nr_running)间判断的 ),如果有,则调用pick_next_task_rt()函数在实时就绪队列上选择一个优先级最高的可运行进程。如果没有,则调用pick_next_task_fair()函数在完全公平就绪队列(rq->cfs)上选择一个排在最前的进程。如果都没有可运行进程则返回idle(rq->idle)进程。
1.1.4. 代码块4
这句才是主调度器的关键,它复制进程切换。它要进行内存管理上下文的切换。
kernel/sched.c
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
{
...
prepare_task_switch(rq, prev, next);
switch_to(prev, next, prev);
barrier();
finish_task_switch(this_rq(), prev);
...
}
prepare_task_switch的工作是在进程切换前做必要的准备工作,设计体系结构相关的内容,主要工作通常用汇编语言完成,如果感兴趣可以看看源码。
switch_to()函数是主调度器的核心,它负责将CPU使用权从当前进程切换到下一个进程。该函数执行完毕后当前进程的寄存器都被保存起来了然后将CPU使用权就交给了下一个进程,即当前进程的IP指针指向的是switch_to函数中某一条指令,当前进程下次被调度时,便从该语句开始执行的。稍后会详细讲解它的实现过程。
finish_task_switch()则是完成一些进程切换后的清理工作,它和prepare_task_switch()是成对匹配的,也涉及体系结构相关的东西。
barrier()是非功能性代码,它用于将它前面的代码和后面的代码分隔开,以免编译器在优化的时候将它前面的代码和后面的代码的顺序颠倒了。它保证了:finish_task_switch()执行时,前面的代码(prepare_task_switch()和 switch_to())都已经执行过了。
1.1.5. 总结
先进行一个总结,然后接下来再详细讨论一下switch_to()这个宏函数。
主调度器的主要执行流程如下:

在上图中,put_pre_task根据当前进程的类型会调用不同的函数。如果当前进程是idle进程,执行流程如下:
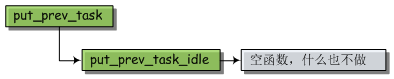
如果当前进程是实时进程,则执行流程如下:
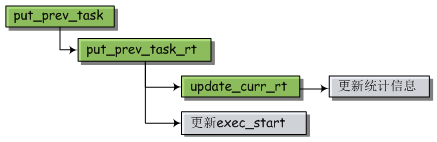
如果当前进程是普通进程,执行流程如下:

细节
1.1.1.
Switch_to
switch_to是用GCC内联汇编实现的,采用的是AT&T汇编语言格式。
include/asm-x86/system_32.h
#define switch_to(prev,next,last)do { \
unsigned long esi,edi; \
asm volatile("pushfl\n\t" /* Save flags */ \
"pushl %%ebp\n\t" \
"movl %%esp,%0\n\t" /* save ESP */ \
"movl %5,%%esp\n\t" /* restore ESP */ \
"movl $1f,%1\n\t" /* save EIP */ \
"pushl %6\n\t" /* restore EIP */ \
"jmp __switch_to\n" \
"1:\t" \
"popl %%ebp\n\t" \
"popfl" \
:"=m" (prev->thread.esp),"=m"(prev->thread.eip), \
"=a"(last),"=S" (esi),"=D" (edi) \
:"m"(next->thread.esp),"m" (next->thread.eip), \
"2" (prev),"d" (next)); \
} while (0)
上述代码中,%0,%1,%5,%6对应后面的参数列表,%0对应第一个参数,即(prev->thread.esp),%5对应第五个参数(即 next->thread.esp)。参数列表前面的“=m”中的m表示它是一个内存变量,=符号表示它是一个输出参数。"D"表示它使用edx寄存器,“a”表示使用eax寄存器...细节不去讨论,将它转换成汇编代码便得到了下面的AT&T汇编代码(左边是源操作数,右边是目的操作数):
1. pushfl
2. pushl %ebp #保存flags#
3. movl %esp, %[prev_sp] #保存前一个进程的ESP#
4. movl %[next_sp], %esp #将下一个进程的esp值恢复到esp寄存器中#
5. movl $1f, %[prev_ip] #将标号为1的语句(即,第8条指令)的地址保存为前一个进程的IP#
6. pushl %[next_ip] #将下一个进程的IP地址压栈
7. jmp __switch_to #跳转到__switch_to,进行进程切换相关处理
8. 1:
9. popl %ebp #将ebp从栈中弹出
10. popfl #将flags从栈中弹出
这10条指令,做的工作非常简单。下面就一条一条解释:
我们将它分为两部分:切换内核栈和切换控制流部分。为了方便讲解,假设调度器正在将CPU使用权从进程A切换到进程B
切换内核栈
1. pushfl
2. pushl %ebp
3. movl %esp, %[prev_sp]
4. movl %[next_sp], %esp
每一个进程有一个内核栈,是它在内核态运行时使用的栈,与之对应的是用户栈。
第一条指令将flag寄存器的值保存在进程A的内核栈中。
第二条指令将ebp寄存器的值也保存在进程A的内核栈中,接着将esp寄存器的值保存在进程A->thread.esp变量中。接下来将进程B->thread.esp的值恢复到寄存器esp中。esp是栈的指针,那么从现在起,任何push和pop操作都是在进程B的内核栈中操作的了,与进程A无关了。这就是所谓的内核栈切换。
切换控制流
5. movl $1f, %[prev_ip]
6. pushl %[next_ip]
7. jmp __switch_to
8. 1:
9. popl %ebp
10. popfl
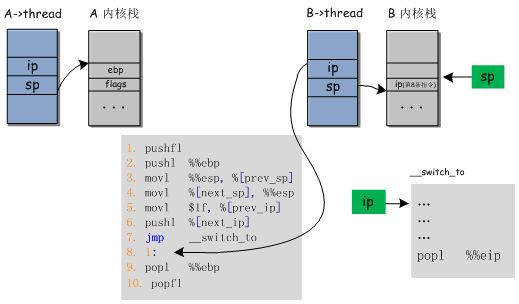
接下来进程控制流的切换,第5条指令,是将标号为1(即第8条指令)的地址赋值给A->thread.ip,这意味着进程A下次获得CPU使用权时将从标号为1的这条指令开始执行。
下一条指令是将B->thread.ip压栈(已经进行了内核栈的切换,那么是压到进程B的内核栈上的)。接下来跳转到__switch_to处继续执行(__switch_to对应内核源码中的__switch_to函数),完成进程切换的其他工作。__switch_to执行完毕时,会从内核栈(进程B的内核栈)中弹出一项作为返回地址,这一项正是刚刚用pushl %[next_ip]指令压入栈中的。
刚刚压入栈中的这个地址究竟指向哪里呢?压入的这个地址是B->thread.ip,这个值等于什么呢。我们看看进程A就知道了,进程A现在的ip值(A->thread.ip)等于什么呢? 等于上面第8条指令的地址。那么如果进程B如果也像进程A一样,曾获得过CPU的使用权,执行一段时间后该使用权被调度器切换给了另一个进程,那么进程B的ip值(B->thread.ip)应该也是指向上述第8条指令的。那如果进程B是新进程呢,那么在创建进程的时候它的ip值(B->thread.ip)会被指定为ret_from_fork(详细情况,看一下fork和e\arch\x86\kernel\entry.S就知道了),也就是说,进程第一次获得CPU使用权时是从那个地方开始执行的。
总结
结合图形对switch_to的整个过程进行一下总结。下图中A->thread表示进程A对应的thread结构体,其中包含了ip和sp两个成员变量。绿色方块sp和ip表示寄存器。假设进程B之前至少运行过一次,即不是新创建的进程,那么进程B的thread.ip应该等于switch_to中的第8条指令,它的thred.sp指向的是自己的内核栈的栈顶。而switch_to是内核中的代码,进程A和进程B在内核态下都可以执行这段代码中的指令。
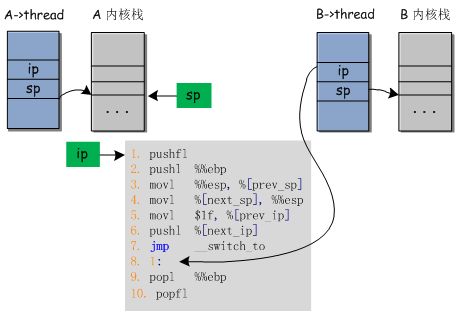
现在运行到了switch_to的第一条指令,所以ip寄存器应该指向这条指令。现在使用的是进程A的内核栈,所以寄存器sp应该指向进程A的内核栈的栈顶。
a) 执行完指令1,2。将flags寄存器和ebp寄存器的值压入进程A的栈中,寄存器sp会指向新的栈顶,ip会指向新的指令地址,而进程A->thread.sp却没有必要更新。

b) 执行完指令3。将寄存器sp的值保存到A->thread.sp中。

c) 执行完指令4。将寄存器sp的值更新为B->thread.sp,如下图所示。

d) 执行完指令5。将A->thread.ip设置为第8条指令的地址,如下图所示。
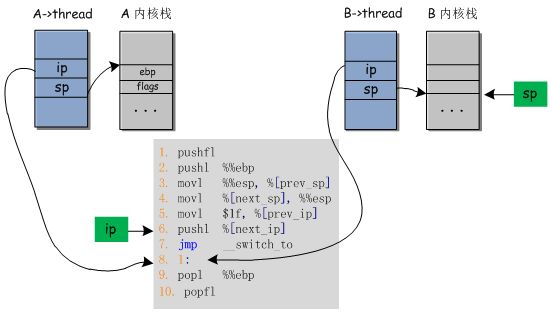
e) 执行完指令6。将B->thread.ip(即第8条指令的地址)压栈。

f) 执行完第7条指令。控制流跳转到__switch_to函数中开始执行。
__switch_to的最后条指令是popl %%eip。执行完该语句后,进程B内核栈中的ip指针被弹出,ip寄存器回到了switch_to函数,指向了第8条指令。如下图:
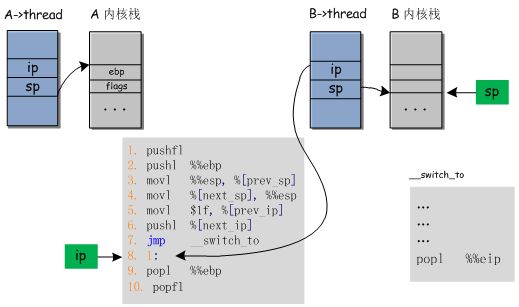
注意看,进程A的栈中依次保存的是ebp和flags寄存器的值,那么相应的,进程B保存的也是上次进程B交出CPU使用权时寄存器ebp和flags的值,因此接下来的两个pop操作则是恢复当时的执行状态,然后开始进程B的执行。
小结
开始的时候控制流在switch_to代码中,后来切换到了__switch_to中,然后又回到了switch_to。进入__switch_to之前,可以认为正在执行的进程是A,从__switch_to回来之后CPU使用权就交给了进程B。如果进程B是新创建的进程,那么从__switch_to中“跳出”时就不是回到switch_to了,而是回到ret_from_fork(这段汇编代码在\arch\x86\kernel\entry.S中有定义)处开始执行。
主调度器启动的时机
前面提到过,在中断返回时,系统会检查当前进程的TIF_NEED_RESCHED标志,如果被置位则启动主调度器。这仅仅是主调度器启动的时机之一,主调度器在其他情况下也会启动:
a) 进程状态转换的时刻:进程终止、进程睡眠。
进程要调用sleep()或exit()等函数进行状态转换,这些函数会主动调用调度程序进行进程调度。
b) 实时进程的时间片用完,或者普通进程本次获得CPU使用权执行时间超过了它对应的ideal_runtime。
由于实时进程的时间片是由时钟中断来更新的,判断普通进程执行时间是否超过ideal_runtime是通过周期性调度器判断的,周期性调度器也是用中断实现的。因此,这种情况和时机4是一样的。
c) 设备驱动程序
当设备驱动程序执行长而重复的任务时,直接调用调度程序。在每次反复循环中,驱动程序都检查need_resched的值,如果必要,则调用调度程序schedule()主动放弃CPU。
d) 进程从中断、异常及系统调用返回到用户态时。
不管是从中断、异常还是系统调用返回,都会检查TIF_NEED_RESCHED标志位,如果该标志位置位,则调用主调度程序。在\arch\x86\kernel\entry.S中能看到相关代码实现(里面包含了ret_from_intr,ret_from_exception,need_resched等汇编代码)。
进程状态切换
原理概述
进程的各个状态和转换条件如下图所示:
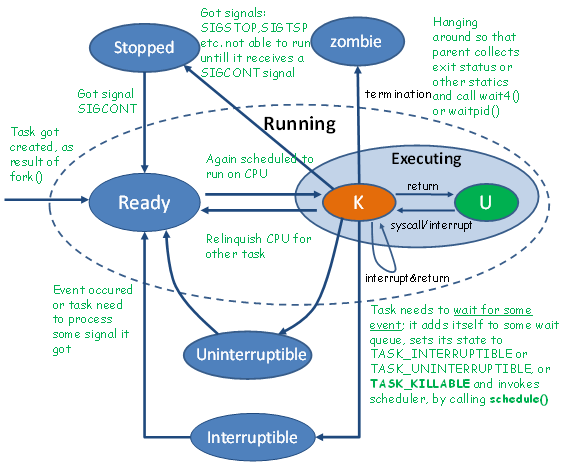
该图是将我在网上看到的两个进程状态切换图结合起来得到的(部分状态如exit_dead等没标注出来)。进程在执行(executing)时又可分为内核态和用户态,所以上图把进程在用户态和内核态直接的转换也标注出来了。
新的进程被创建后并不一定马上就会加入到就绪队列中,其细节我们暂不讨论,所以上图是从进程被创建并被加到就绪队列开始秒速的。假设你已经对状态切换已经有基本的了解了,这里只是简单回顾一下,就不对上图做详细解释了。关于各个状态的解释,以免在转述过程中曲解了原作者的意思,直接附原文吧:
a) TASK_RUNNING: The processis either running on CPU or waiting in a run queue to get scheduled.
b) TASK_INTERRUPTIBLE: Theprocess is sleeping, waiting for some event to occur. The process is open to beinterrupted by signals. Once signalled or awoken by explicit wake-up call, theprocess transitions to TASK_RUNNING.
c) TASK_UNINTERRUPTIBLE: Theprocess state is similar to TASK_INTERRUPTIBLE except that in this stateit does not process signals. It may not be desirable even to interrupt theprocess while in this state since it may be in the middle of completing someimportant task. When the event occurs that it is waiting for, the process isawaken by the explicit wake-up call.
d) TASK_STOPPED: The processexecution is stopped, it's not running, and not able to run. On receipt ofsignals like SIGSTOP,SIGTSTP, and so on, the process arrives at thisstate. The process would be runnable again on receipt of signal SIGCONT.
e) TASK_TRACED: A processarrives at this state while it is being monitored by other processes such asdebuggers.
f) EXIT_ZOMBIE: The processhas terminated. It is lingering around just for its parent to collect somestatistical information about it.
g) EXIT_DEAD: The finalstate (just like it sounds). The process reaches this state when it is beingremoved from the system since its parent has just collected all statisticalinformation by issuing the wait4() or waitpid() systemcall.
细节
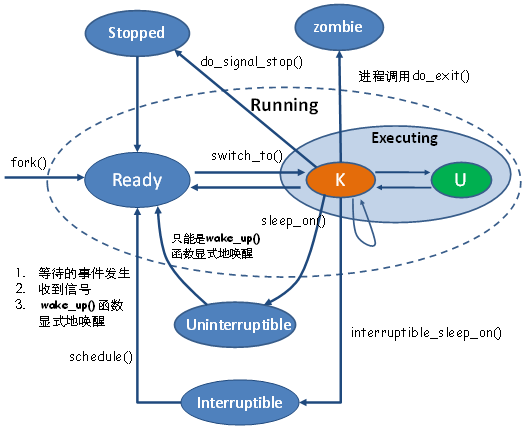
对状态切换过程有了了解,我们来看看具体涉及的函数吧,这才是我想要讲的。
各个转换函数如下图所示:
Read<-->Executing
进程在就绪状态和正在运行状态直接的转换是由schdule()函数完成的,具体实现转换又是有schdule()中的switch_to()函数完成的,这一部分内容之前已经讲过,这里不再重复。
Executing->zombie
进程调用do_exit()退出执行后,它进入僵死(僵尸)状态,在这个状态下它等待父进程完成必要的清理工作(“等待父亲为自己收尸”),清理工作完毕以后就算真正的死亡了。如果此时父进程已经死亡,那么它将成真正的僵尸进程。
Executing->Stopped
前面说了,正在执行的进程收到 SIGSTOP,SIGTSTP等信号会使它转变为stopped状态。这些信号只是致使它发生状态转换的原因,而真正的状态转换是由号处理函数(get_signal_to_deliver)完成的。这个函数会例行检查进程收到了哪些信号,然后对信号进行相应的处理。
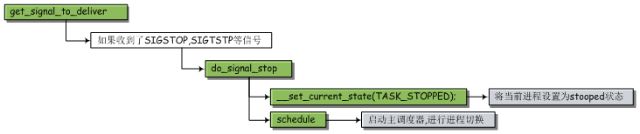
如果信号处理函数发现收到了SIGSTOP,SIGTSTP等信号,它就会调用do_signal_stop函数。该函数的工作流程如下:它先将当前进程的状态设置为stopped,然后后再启动主调度器。主调度器检查发现当前进程的状态时stopped,便会进行对应的进程切换。
Stopped->Ready
它的处理过程与Executing->Stopped的过程类似。(不过我没有看信号处理章节的内容,内核文档中说SIGCONT信号由ignore函数处理,但是目前没找到具体相关函数,找到了在更新本文档吧)。
Executing->Sleeping
进程在访问信号量或者互斥量时会进入睡眠状态,而这里我们只拿调用sleep_on()函数和interruptible_sleep_on()让它进入睡眠状态的特例来简单说明一下状态转换过程吧。从正在运行状态到interruptible睡眠状态是调用interruptible_sleep_on()函数实现的,从正在运行状态到uninterruptible睡眠状态是调用sleep_on()函数完成的。这两个函数实际上都是调用sleep_on_common()完成的,只是参数不同。

sleep_on_common执行流程如上图。它首先根据传入的参数(interruptible或者uninterruptible)将进程设置为相应的状态,然后调用__add_wait_queue(q,&wait)将当前进程加入到指定的等待队列中。接下来调用schedule_timeout,启动一个计时器,然后启动主调度器进行进程切换。
前面我们讲过,当前进程的ip指针指向了switch_to中的第8条指令,然后CPU使用权就转交给了下一个进程。这就意味着,当前进程执行到switch_to(上图用橙色标记出来了),处时就停止了,那么它下一次获得CPU使用权时便会从switch_to往下执行。它接下来会执行finish_task_switch()然后返回到context_switch()中,然后再返回到schedule()函数,再接着返回到schedule_timeout()函数。接着往下,它会执行destroy_timer_on_stack()函数。然后返回到sleep_on_common()中,执行__remove_wait_queue()将自己从等待队列中移除。
其流程如下图中绿线所示:
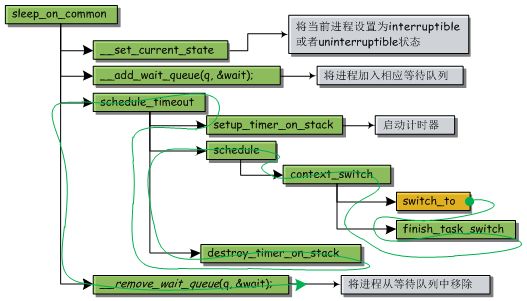
也就是说,计时器是该进程交出使用权前启动的,接下来它进入睡眠状态,直到它从睡眠中醒来并且获得了CPU使用权,才把计时器撤销。另外,也是在它获得CPU使用权后它才将自己从等待队列中移除。(获得CPU使用权前它需要先从睡眠状态中醒来,加入就绪队列。即一个进程可以同时在等待队列和就绪队列中。?这说法还需要做实验考究一下,暂且不知道真假。遗留问题)
Sleeping->Ready
在可中断睡眠状态下,如果收到信号或者调用wake_up()函数就能将进程转换为Ready状态;在不可中断睡眠状态下,只能通过wake_up()函数显式地将进程唤醒。这里我们用wake_up()函数将进程唤醒的情况举例说明一下状态切换过程,另一种情况由信号和事件处理函数完成,核心内容是一样的。
wake_up()是一个宏函数,它被定义为__wake_up()函数,这个函数的主要工作是调用__wak_up_common()函数完成的。它又调用了curr->func(curr为该进程所在的等待队列),这是一个函数指针,默认指向default_wake_funcion()函数。default_wake_funcion()的工作最终是由try_to_wake_up()函数完成的。
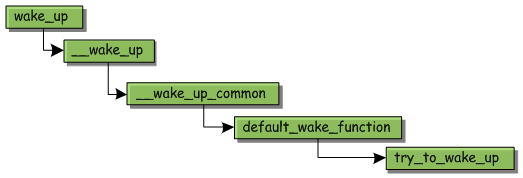
try_to_up()涉及很多细节的工作,和复杂的判断流程,这里我们只关注本章内容相关的部分。
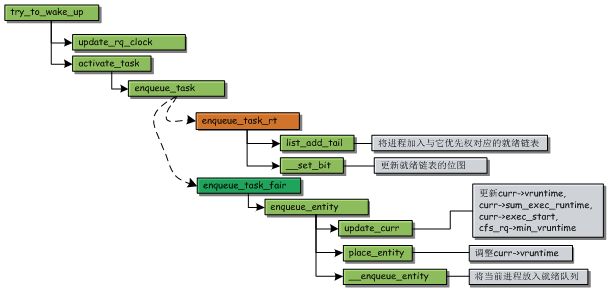
它首先会调用update_rq_clock()更新队列时钟(rq->clock),然后调用activate_task()激活该进程。activate_task()又调用了enqueue_task(),该函数是注册在相关调度类中的。
如果该进程是实时进程,那么enqueue_task指向的是enqueue_task_rt(),对实时进程操作很简单,只需要将它放入与它优先权对应的就绪列表中,然后更新一下对应的就绪列表位图就行了。
如果该进程是普通进程,那么enqueue_task指向的是enqueue_task_fair()。这个函数在之前就讲过,它的主要工作由enqueue_entity()实现,enqueue_entity首先调用update_curr更新相关统计量(sum_exec_runtime,exec_start,vruntime,cfs_rq->min_vruntime),接下来调用place_entity()对vruntime做一个调整(这个在之前讲到过,新创建的进程和睡眠后重新加入就绪队列的进程都需要调整vruntime值),最后才调用__enqueue_entity将它加入红黑树中。
更正:调度器在选择下一个要执行的进程时,当前正在执行的进程不参选(除非可运行进程只有它一个),这个我还没证实,不过好像是这样的,证实之后及时更新。
最后免费赠送我画得非常漂亮的草图一幅。
