hashSet 是有序的吗、怎么保证唯一性
目录
hashSet 是有序的吗
怎么保证唯一性
hashSet 是有序的吗
这个问题是在去年面试的时候第一次被问到,听到问题的时候一下懵了,因为工作中都是用hashSet保证数据的唯一,没有考虑过数据的顺序性,也没有私下研究过hashSet的源码,所以答的很不好。最近翻笔记又看到了这个问题,决定认真研究一下并做一些记录。
正文前先说明此处的有序是指数值顺序。此文案例使用sun jdk1.8,hashSet在不同版本jdk表现不同。
文中用例参考自:Java遍历HashSet为什么输出是有序的?
菜鸟教程中对hashSet的定义是:该类实现了Set接口,不允许出现重复元素,不保证集合中元素的顺序,允许包含值为null的元素,但最多只能一个。
此题的答案是不保证元素的顺序!
定义中没有直接了当的说无序,而是说不保证元素的顺序是有原因的,因为在特定条件下会出现有序的情况!
public class TestController {
public static void main(String[] args){
Random rand=new Random(47);
Set intset=new HashSet();
for (int i=0;i<10000;i++){
intset.add(rand.nextInt(30));
}
Iterator iterator=intset.iterator();
while (iterator.hasNext()){
System.out.print(iterator.next()+" ");
}
}
} 在sun jdk1.8的环境中运行结果如下:

如图所示打印出的结果是有序的,为什么会出现有序的情况呢?
分析hashSet的源码,可以发现hashSet底层是维护了一个hashMap实例,元素存储到了hahsMap的key值中。因为插入HashSet的是Integer,Integer类重写了hashCode方法,其hashCode()实现就返回int值本身。然后进行hash算法求hash值,计算hash值的代码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}可以看出当数值小于65536时,得出的hash值是本身,插入到hashMap中的顺序即hash的数值顺序,所以出现了有序的现象,
修改测试区间
public class HashSetTest {
public static void main(String[] args){
Random rand=new Random(47);
Set intset=new HashSet();
for (int i=0;i<15;i++){
int x = rand.nextInt(30) + (1 << 16);
intset.add(x);
Object key = x;
int h;
System.out.println("原值:"+(x- (1 << 16))+"求hash的值:"+x+"----hash:"+((h = key.hashCode()) ^ (h >>> 16)));
}
Iterator iterator=intset.iterator();
while (iterator.hasNext()){
System.out.print((iterator.next() - (1 << 16)) +" ");
}
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
} 结果:
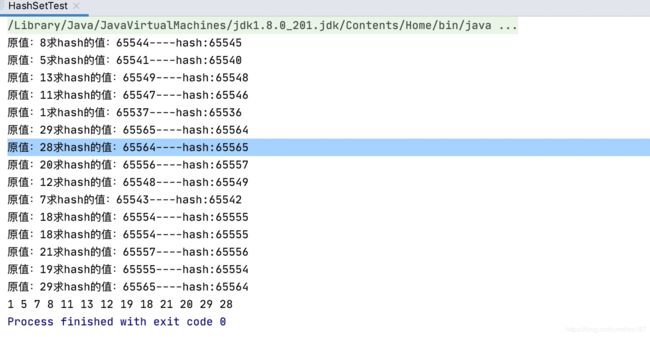
可以看出当数值大于65536时hash值并不等于本身,所以输出顺序不再有序了,而是按照hash值的顺序排列!
怎么保证唯一性
因为hashSet底层采用hashMap实例,hashSet保证唯一的逻辑和HashMap的key值不能重复逻辑一致。
在插入元素时计算hash值得出在hash桶对应的下标,如果数组对应的下标有值了,需要把新值插入到链表,如果存在链表中的某个节点key值和新插入的值相同,则覆盖。参考HashMap源码分析(JDK1.8)
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab;
Node p;
int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
//如果hash桶是空的或者table的长度为0,则做一次扩容;table的长度并不是实际含有多少对象,而是扩容的长度。当前只put了三个对象,但是table长度是16
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
//计算当前下标的数组对象是否为null,如果为null,插入新节点
tab[i] = newNode(hash, key, value, null);
else {
//数组对应的下标有值了,需要把新值插入到链表
Node e;
K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//下标相同且key值也相同,会做替换
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode) p).putTreeVal(this, tab, hash, key, value);
else {
//略
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
} 