[转]浏览器的工作原理:新式网络浏览器幕后揭秘
源文件:http://www.html5rocks.com/zh/tutorials/internals/howbrowserswork/
写的很好,虽然长还是值得一看。涉及到解析、css计算等等算法有一些具体帮助理解的实例,挺复杂的,建议花点时间阅读原文。
主要结构
· user interface- 包括地址栏、前进/后退按钮、书签菜单等。除了浏览器主窗口显示的您请求的页面外,其他显示的各个部分都属于用户界面。
browser engine -在用户界面和呈现引擎之间传送指令。
rendering engine -负责显示请求的内容。如果请求的内容是 HTML,它就负责解析HTML 和 CSS 内容,并将解析后的内容显示在屏幕上。
networking -用于网络调用,比如HTTP 请求。其接口与平台无关,并为所有平台提供底层实现。
UI backend -用于绘制基本的窗口小部件,比如组合框和窗口。其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法。
JavaScript interpreter。用于解析和执行JavaScript 代码。
data Persistence。这是持久层。浏览器需要在硬盘上保存各种数据,例如Cookie。新的 HTML 规范(HTML5) 定义了“网络数据库”,这是一个完整(但是轻便)的浏览器内数据库。
值得注意的是,和大多数浏览器不同,Chrome浏览器的每个标签页都分别对应一个呈现引擎实例。每个标签页都是一个独立的进程。
Rendering engine
本文所讨论的浏览器(Firefox、Chrome 浏览器和 Safari)是基于两种呈现引擎构建的。Firefox 使用的是 Gecko,这是 Mozilla 公司“自制”的呈现引擎。而 Safari 和 Chrome 浏览器使用的都是 WebKit。
Rendering Engine主流程
呈现引擎一开始会从网络层获取请求文档的内容,内容的大小一般限制在 8000 个块以内。
然后进行如下所示的基本流程:
图:呈现引擎的基本流程。呈现引擎将开始解析 HTML 文档,并将各标记逐个转化成“内容树”上的 DOM 节点。同时也会解析外部 CSS 文件以及样式元素中的样式数据。HTML 中这些带有视觉指令的样式信息将用于创建另一个树结构:呈现树。
呈现树包含多个带有视觉属性(如颜色和尺寸)的矩形。这些矩形的排列顺序就是它们将在屏幕上显示的顺序。
呈现树构建完毕之后,进入“布局”处理阶段,也就是为每个节点分配一个应出现在屏幕上的确切坐标。下一个阶段是绘制 - 呈现引擎会遍历呈现树,由用户界面后端层将每个节点绘制出来。
需要着重指出的是,这是一个渐进的过程。为达到更好的用户体验,呈现引擎会力求尽快将内容显示在屏幕上。它不必等到整个 HTML 文档解析完毕之后,就会开始构建呈现树和设置布局。在不断接收和处理来自网络的其余内容的同时,呈现引擎会将部分内容解析并显示出来。
主流程示例
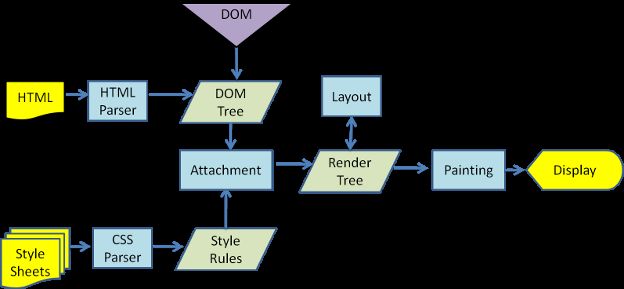 图:WebKit 主流程 图:Mozilla 的 Gecko 呈现引擎主流程 ( 3.6)
图:WebKit 主流程 图:Mozilla 的 Gecko 呈现引擎主流程 ( 3.6)
从图 3 和图 4 可以看出,虽然 WebKit 和 Gecko 使用的术语略有不同,但整体流程是基本相同的。
HTML Parser
HTML 无法用常规的自上而下或自下而上的解析器进行解析。
原因在于:
- 语言的宽容本质。
- 浏览器历来对一些常见的无效 HTML 用法采取包容态度。
- 解析过程需要不断地反复。源内容在解析过程中通常不会改变,但是在 HTML 中,脚本标记如果包含
document.write,就会添加额外的标记,这样解析过程实际上就更改了输入内容。
由于不能使用常规的解析技术,浏览器就创建了自定义的解析器来解析 HTML。
HTML5 规范详细地描述了解析算法。此算法由两个阶段组成:标记化和树构建
标记化算法
通过一个简单的示例来帮助大家理解其原理。
基本示例 - 将下面的 HTML 代码标记化:
Hello world
初始状态是数据状态。遇到字符 < 时,状态更改为“标记打开状态”。接收一个 a-z字符会创建“起始标记”,状态更改为“标记名称状态”。这个状态会一直保持到接收 >字符。在此期间接收的每个字符都会附加到新的标记名称上。在本例中,我们创建的标记是 html 标记。
遇到 > 标记时,会发送当前的标记,状态改回“数据状态”。 标记也会进行同样的处理。目前 html 和 body 标记均已发出(发给树构造器)。现在我们回到“数据状态”。接收到Hello world 中的 H 字符时,将创建并发送字符标记,直到接收 中的 <。我们将为 Hello world 中的每个字符都发送一个字符标记。
现在我们回到“标记打开状态”。接收下一个输入字符 / 时,会创建 end tag token并改为“标记名称状态”。我们会再次保持这个状态,直到接收 >。然后将发送新的标记,并回到“数据状态”。