InfluxDB详解
InfluxDB(时序数据库)(influx,流入,涌入),常用的一种使用场景:监控数据统计。每毫秒记录一下电脑内存的使用情况,然后就可以根据统计的数据,利用图形化界面(InfluxDB V1一般配合Grafana)制作内存使用情况的折线图;可以理解为按时间记录一些数据(常用的监控数据、埋点统计数据等),然后制作图表做统计;
InfluxDB自带的各种特殊函数如求标准差,随机取样数据,统计数据变化比等,使数据统计和实时分析变得十分方便,适合用于包括DevOps监控,应用程序指标,物联网传感器数据和实时分析的后端存储。类似的数据库有Elasticsearch、Graphite等。
1、什么是InfluxDB
InfluxDB是一个由InfluxData开发的开源时序型数据。它由Go写成,着力于高性能地查询与存储时序型数据。InfluxDB被广泛应用于存储系统的监控数据,IoT行业的实时数据等场景。
InfluxDB有三大特性:
- Time Series (时间序列):你可以使用与时间有关的相关函数(如最大,最小,求和等)
- Metrics(度量):你可以实时对大量数据进行计算
- Eevents(事件):它支持任意的事件数据
特点
- 为时间序列数据专门编写的自定义高性能数据存储。 TSM引擎具有高性能的写入和数据压缩
- Golang编写,没有其它的依赖
- 提供简单、高性能的写入、查询 http api,Native HTTP API, 内置http支持,使用http读写
- 插件支持其它数据写入协议,例如 graphite、collectd、OpenTSDB
- 支持类sql查询语句
- tags可以索引序列化,提供快速有效的查询
- Retention policies自动处理过期数据
- Continuous queries自动聚合,提高查询效率
- schemaless(无结构),可以是任意数量的列
- Scalable可拓展
- min, max, sum, count, mean,median 一系列函数,方便统计
- Built-in Explorer 自带管理工具
2、对常见关系型数据库(MySQL)的基础概念对比
| 概念 | MySQL | InfluxDB |
|---|---|---|
| 数据库(同) | database | database |
| 表(不同) | table | measurement(测量; 度量) |
| 列(不同) | column | tag(带索引的,非必须)、field(不带索引)、timestemp(唯一主键) |
2.Influxdb相关名词
database:数据库;
measurement:数据库中的表;
points:表里面的一行数据。
influxDB中独有的一些概念:Point由时间戳(time)、数据(field)和标签(tags)组成。
Point相当于传统数据库里的一行数据,如下表所示:
| Point属性 | 传统数据库中的概念 |
| time(时间戳) | 每个数据记录时间,是数据库中的主索引(会自动生成) |
| fields(字段、数据) | 各种记录值(没有索引的属性)也就是记录的值:温度, 湿度 |
| tags(标签) | 各种有索引的属性:地区,海拔 |
注意
在influxdb中,字段必须存在。因为字段是没有索引的。如果使用字段作为查询条件,会扫描符合查询条件的所有字段值,性能不及tag。类比一下,fields相当于SQL的没有索引的列。
tags是可选的,但是强烈建议你用上它,因为tag是有索引的,tags相当于SQL中的有索引的列。tag value只能是string类型。
还有一个重要的名词:series
所有在数据库中的数据,都需要通过图表来表示,series(系列)表示这个表里面的所有的数据可以在图标上画成几条线(注:线条的个数由tags排列组合计算出来)
-
示例数据如下: 其中census是measurement,butterflies和honeybees是field key,location和scientist是tag key
name: census
————————————
time butterflies honeybees location scientist
2015-08-18T00:00:00Z 12 23 1 langstroth
2015-08-18T00:00:00Z 1 30 1 perpetua
2015-08-18T00:06:00Z 11 28 1 langstroth
2015-08-18T00:06:00Z 11 28 2 langstroth
示例中有三个tag set
3、注意点
- tag 只能为字符串类型
- field 类型无限制
- 不支持join
- 支持连续查询操作(汇总统计数据):CONTINUOUS QUERY
- 配合Telegraf服务(Telegraf可以监控系统CPU、内存、网络等数据)
- 配合Grafana服务(数据展现的图像界面,将influxdb中的数据可视化)
4、常用InfluxQL
-- 查看所有的数据库
show databases;
-- 使用特定的数据库
use database_name;
-- 查看所有的measurement
show measurements;
-- 查询10条数据
select * from measurement_name limit 10;
-- 数据中的时间字段默认显示的是一个纳秒时间戳,改成可读格式
precision rfc3339; -- 之后再查询,时间就是rfc3339标准格式
-- 或可以在连接数据库的时候,直接带该参数
influx -precision rfc3339
-- 查看一个measurement中所有的tag key
show tag keys
-- 查看一个measurement中所有的field key
show field keys
-- 查看一个measurement中所有的保存策略(可以有多个,一个标识为default)
show retention policies;
5、InfluxDB Java Demo
GitHub Demo
InfluxDB 安装
- 下载地址,
64bit:https://dl.influxdata.com/influxdb/releases/influxdb-1.7.4_windows_amd64.zip
chronograf:https://dl.influxdata.com/chronograf/releases/chronograf-1.7.8_windows_amd64.zip
2.解压安装包
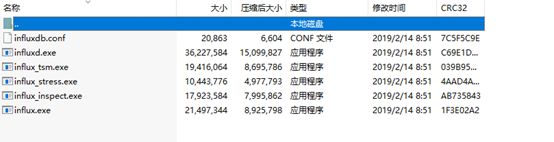
修改配置文件
InfluxDB 的数据存储主要有三个目录。默认情况下是 meta, wal 以及 data 三个目录,服务器运行后会自动生成。
- meta 用于存储数据库的一些元数据,meta 目录下有一个 meta.db 文件。
- wal 目录存放预写日志文件,以 .wal 结尾。
- data 目录存放实际存储的数据文件,以 .tsm 结尾。
如果不使用influxdb.conf配置的话,那么直接双击打开influxd.exe就可以使用influx,此时上面三个文件夹的目录则存放在Windows系统的C盘User目录下的.Influx目录下,默认端口为8086,以下为修改文件夹地址,以及端口号方法。
1.修改以下部分的路径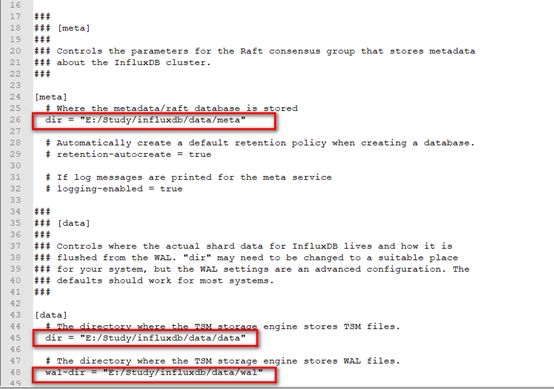
2. 如果需要更改端口号,则修改以下部分配置
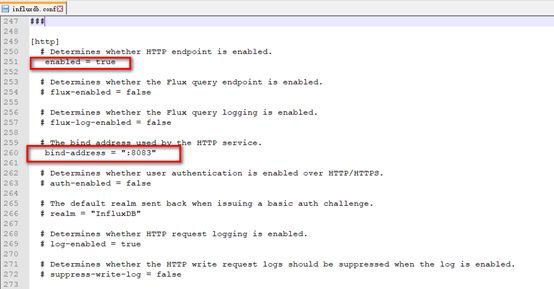
3. 修改配置后启动方式
InfluxDB 使用时需要首先打开Influxd.exe,直接打开会使用默认配置,需要使用已配置的配置文件的话,需要指定conf文件进行启动,启动命令如下:
influxd.exe -config influxdb.conf(cmd目录为influxDB目录)
启动可写成bat文件,内容如下:
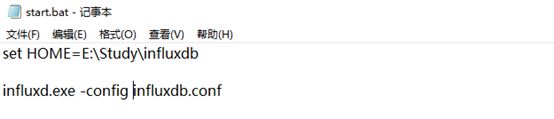
打开成功画面:
Influxd成功启动后,即可打开influx.exe,若使用默认配置,则直接打开即可,使用配置文件的情况下,在cmd中输入influx命令(cmd目录为influxDB目录),启动可写成bat文件,文件内容如下:

-port是使用特定port号启动
启动成功画面显示如下:
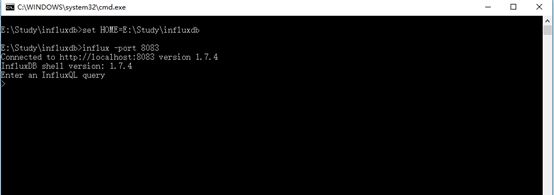
备注:运行influx.exe 时,influxd.exe不可关闭。(influxd.exe是守护进程)
配置文件具体内容详解:
官方介绍:https://docs.influxdata.com/influxdb/v1.2/administration/config/
转自:https://www.cnblogs.com/guyeshanrenshiwoshifu/p/9188368.html
全局配置
| 1 2 |
|
1、meta相关配置
| 1 2 3 4 |
|
2、data相关配置
| 1 2 3 4 5 6 7 8 9 10 |
|
3、coordinator查询管理的配置选项
| 1 2 3 4 5 6 7 8 |
|
4、retention旧数据的保留策略
| 1 2 3 |
|
5、shard-precreation分区预创建
| 1 2 3 4 |
|
6、monitor 控制InfluxDB自有的监控系统。 默认情况下,InfluxDB把这些数据写入_internal 数据库,如果这个库不存在则自动创建。 _internal 库默认的retention策略是7天,如果你想使用一个自己的retention策略,需要自己创建。
| 1 2 3 4 |
|
7、admin web管理页面
| 1 2 3 4 5 |
|
8、http API
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
9、subscriber 控制Kapacitor接受数据的配置
| 1 2 3 4 5 6 7 |
|
10、graphite 相关配置
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
11、collectd
| 1 2 3 4 5 6 7 8 9 10 11 |
|
12、opentsdb
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
13、udp
| 1 2 3 4 5 6 7 8 9 |
|
14、continuous_queries
| 1 2 3 4 |
|
InfluxDB数据库常用命令
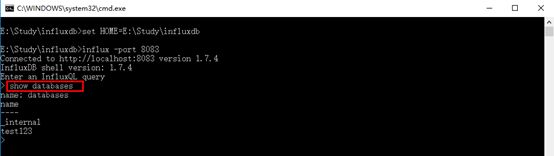
1、显示所有数据库
show databases
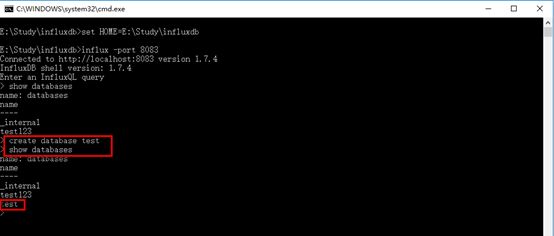
2、 创建数据库
create database test
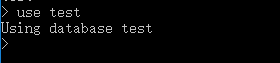
3、 使用某个数据库
use test
4、 显示所有表
show measurements

没有表则无返回。

5、新建表和插入数据
新建表没有具体的语法,只是增加第一条数据时,会自动建立表
insert results,hostname=index1 value=1
这里的时间看不懂,可以设置一下时间显示格式
precision rfc3339
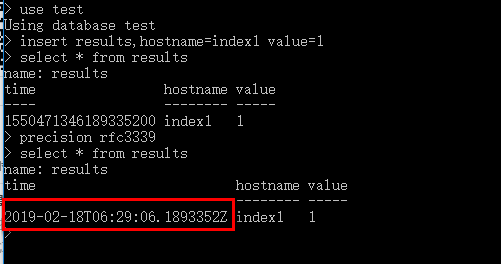
6、 查询数据
表名有点号时,输入双引号
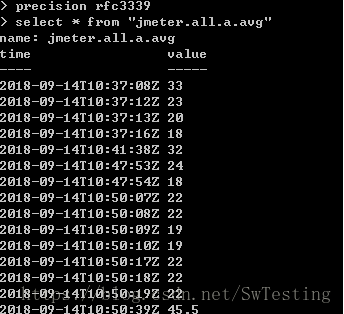
和sql语法相同,区别:
measurement 数据库中的表
points 表里面的一行数据,Point由时间戳(time)、数据(field)、标签(tags)组成。
7、 用户显示
a. 显示所有用户
show users
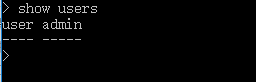
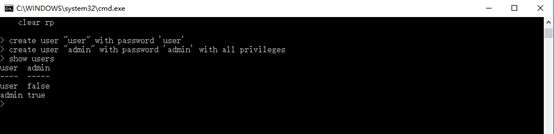
b.新增用户
--普通用户
create user "user" with password 'user'
--管理员用户
create user "admin" with password 'admin' with all privileges
c.删除用户
drop user "user"
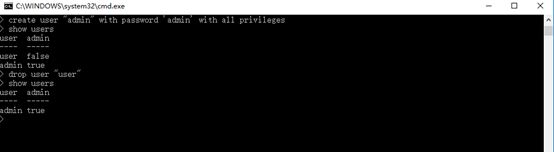
很多InfluxDB的文章都说InfluxDB是时序数据库,不支持删除。但实际测试是可以删除的。
连接InfluxDB![]()
一张叫uv的表
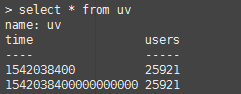
执行删除后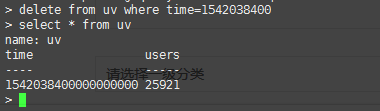
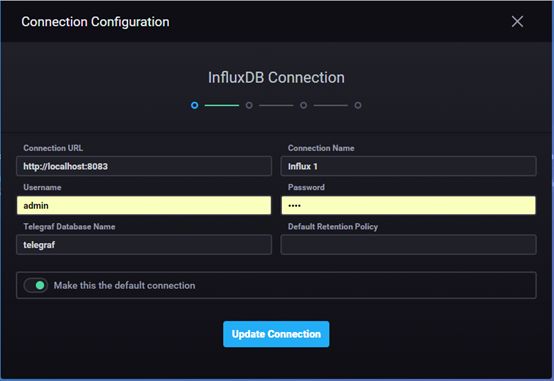
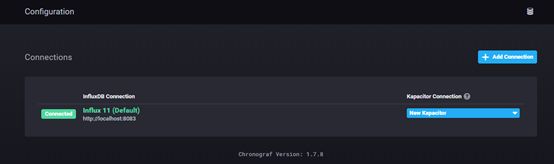
Chronograf 使用
1、解压文件后,直接进入安装目录,执行chronograf.exe后;
2、输入:http://localhost:8888(chronograf默认是8888端口)
3、influxDB数据源连接