C++ Book Note
文章目录
- hello world
- g++ 编译参数
- MSVC 编译器参数
- inline - /Ob (Inline Function Expansion)
- Compiler optimizations
- define & g++ -D
- g++ -U & -D
- #pragma once
- Preprocessor directives
- NULL & nullptr
- typeid
- size .\out.exe or .\out.out
- cout align
- console output text color & 变长参数
- 示例1
- 示例2
- numeric_limits min, max
- extern c/c++ test
- array
- 2d array to pointer
- my_vec3 to float*
- pointer - 指针
- shared_ptr - 只能指针
- string test
- string raw define
- stringstream
- char* init by multi char* - 字符串以多个字符串初始化
- volatile 关键字详解
- const 常量
- constexpr
- C++ compiler & runtime std version
- lambda
- struct & class refer to params for pass to func
- struct, class mem layout - 内存布局
- dynamic_cast & force cast
- Static_cast 与 Dynamic_cast的区别
- class - override kinds of operators
- 可重载
- 不可重载
- class friend
- class static memeber
- class virtual func
- class multi inherit
- multi_inherit_ctor_dector
- class static
- new、operator new、placement new
- enum
- pair
- get
- complex
- set
- set - 插入、删除、初始化、遍历、查找、清除
- map
- map 插入、查找、遍历
- vector
- #define,typedef,using用法区别
- macros nested - 宏嵌套
- pragma - 编译指令
- #pragma message("compiling output message") - 编译输出信息
- #pragma pack
- fstream, ofstream, ifstream
- C++ seekp和seekg函数用法详解
- 一次读完
- try...catch.../exception
- GDB 调试输出更信息的信息
- namespace - 命名空间
- template function/class
- typename 与class区别
- thread / mutex
- g++ 编译报错
- VS C++没有这个问题
- 网上查了,大概是编译器的问题
- 测试thread / mutex / atomic
- scope - 作用域
- move、forward
- Calling Conversion - 调用约定
- __declspec - 规范定义
- Debugging C++ Source Code using GDB in Windows
- 错误、异常处理
- LNK 2019
- C++ “void std::sort(const _RanIt,const _RanIt)”: 应输入 2 个参数,却提供了 3 个 - 已解决
- C++ 实例
- judge basic type or data is signed or not - 判断有符号和无符号的变量或类型[C/C++]
- 获取工作空间目录或获取运行程序目录
- 使用
- FindWindow - 查找窗体句柄
- 注意 L"this is wchar" 来声明该字符串是 wchar_t的
- 查找窗体
- std::cout 输出10进制与16进制的控制
- C++ 实例 - 求一元二次方程的根
- 根的判别式
- C++ ASM
- C++ 逆向反汇编
- 1.1
- NASM
- MARS - 更方便学习ASM的工具
- MARS 官网
- MARS - youtube 视频教程
- MARS 简单教程 / 功能
- 汇编入门(长文多图,流量慎入!!!)
- C++面试
- 【腾讯内部工具分享】内存泄漏分析工具tMemoryMonitor
- Refernces
晴天霹雳你觉得很惊讶吗?
哈哈哈,我可是天天都看到各种霹雳!早已习空见惯了。
从大学出来就由于工作原因一直没再使用C++。(大学的时候,我们老师可是极力推荐C#)
工作、规划需要,是时候重温回来了。
C++其实也是很简单的,每个部分都很简单,但是因为语言特性非常的多,需要时间熟悉与记忆。
hello world
那就从最开始的 hello world 出发。
#include g++ 编译参数
| CMD | Des |
|---|---|
| -ansi | 只支持 ANSI 标准的 C 语法。这一选项将禁止 GNU C 的某些特色, 例如 asm 或 typeof 关键词。 |
| -c | 只编译并生成目标文件。 |
| -DMACRO | 以字符串"1"定义 MACRO 宏。 |
| -DMACRO=DEFN | 以字符串"DEFN"定义 MACRO 宏。 |
| -E | 只运行 C 预编译器。 |
| -g | 生成调试信息。GNU 调试器可利用该信息。 |
| -IDIRECTORY | 指定额外的头文件搜索路径DIRECTORY。 |
| -LDIRECTORY | 指定额外的函数库搜索路径DIRECTORY。 |
| -lLIBRARY | 连接时搜索指定的函数库LIBRARY。 |
| -m486 | 针对 486 进行代码优化。 |
| -o | FILE 生成指定的输出文件。用在生成可执行文件时。 |
| -O0 | 不进行优化处理。 |
| -O | 或 -O1 优化生成代码。 |
| -O2 | 进一步优化。 |
| -O3 | 比 -O2 更进一步优化,包括 inline 函数。 |
| -shared | 生成共享目标文件。通常用在建立共享库时。 |
| -static | 禁止使用共享连接。 |
| -UMACRO | 取消对 MACRO 宏的定义。 |
| -w | 不生成任何警告信息。 |
| -Wall | 生成所有警告信息。 |
MSVC 编译器参数
MSVC是微软的VS对C++默认的编译器
按字母顺序列出的编译器选项
inline - /Ob (Inline Function Expansion)
- /Ob (Inline Function Expansion)
- 被知乎大佬嘲讽后的一个月,我重新研究了一下内联函数 - 还行,主要里面提供的连接也不错的。
Compiler optimizations
Compiler optimizations
define & g++ -D
/* a.cpp - jave.lin 2020.04.30 */
#include @rem compile.bat - jave.lin 2020.04.30
g++ a.cpp -o out -DDebug -DMY_MACRO
.\out.exe
@pause
D:\jave\Work Files\CPP\hello_world>g++ a.cpp -o out -DDebug -DMY_MACRO
D:\jave\Work Files\CPP\hello_world>.\out.exe
hello world
this is debugging message.
this is my_macro message.
this is define macro in file message.
input string please:
GodLike
this is your input msg:GodLike
请按任意键继续. . .
这里虽然用了最简单的hello world演示,但需要注意我们使用宏分支,与定义宏的位置
其中定义宏,目前例子表示了两种:
- 源文件中直接
#define - 编译时指定参数
-D
g++ -U & -D
/* a.cpp - jave.lin 2020.04.30 */
#include @rem compile.bat - jave.lin 2020.04.30
@rem -U 只能对命令行 -D 的宏定义取消,源文件内已定义的取消不了
@rem 可以看到 -UA 取消宏定义了,但是还是会输出 A 宏定义的内容
@rem 也可以看到先 -DD, 再 -UD,就可以取消了-D 命令行的宏定义
@rem 还可以看到先 -UE 一个没有定义过的 E,再重新-DE,结果还是会输出 E 的内容,所以-D -U之间的顺序很重要
g++ a.cpp -o out -DC -DD -UD -UA -UE -DE -DTAG=2
.\out.exe
@pause
D:\jave\Work Files\CPP\-UMacro>g++ a.cpp -o out -DC -DD -UD -UA -UE -DE -DTAG=2
D:\jave\Work Files\CPP\-UMacro>.\out.exe
defined A.
defined B.
defined C.
defined E.
tag == 2.
#pragma once
C/C++中#pragma once的使用
C/C++中为了避免同一个文件被多次include的问题通常做法是:
#ifndef __XXX_H__
#define __XXX_H__
// file content
#endif
但是这种方法有弊端,如果大型项目中,碰巧__XXX_H__定义在与其他文件的宏定义重名,那就会有问题了
而 #pragma once 就不会有这问题。
#pragma once只要放在需要被include文件的第一行即可
它底层应该是以文件名或是MD5,或是GUID,之类的来处理的。
听说是比上面那种#ifndef的方法的编译速度更快。所以推荐使用
但是部分低版本的编译器不支持。gcc/g++ 3.4以上才能用。
Preprocessor directives
Preprocessor directives
NULL & nullptr
/* a.cpp - jave.lin 2020.04.30 */
#include p:00000000, q:00000000
typeid
/* b.h jave.lin*/
class Display{};
/* a.cpp - jave.lin */
#include size .\out.exe or .\out.out
可查看可执行文件的数据结构
PS D:\jave\Work Files\CPP\typeid> size .\out.exe
text data bss dec hex filename
16708 2024 116 18848 49a0 .\out.exe
cout align
C/C++中的输出对齐设置
std::cout.setf(std::ios::left) // 默认右对齐,可设置为左对齐
std::cout.width(int i) // 设置后续每次cout<<输出占位几个字符,不足个数将不空格
console output text color & 变长参数
参考:
- C++ 设置控制台输出颜色
- C++更改控制台输出颜色
示例1
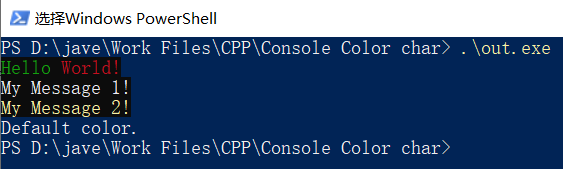
// jave.lin - 调整Console输出字符颜色
#include "stdio.h"
#include "windows.h"
#define _FR FOREGROUND_RED
#define _FG FOREGROUND_GREEN
#define _FB FOREGROUND_GREEN
#define _FI FOREGROUND_INTENSITY
#define MY_TEXT_COLOR _FR | _FG | _FB
#define MY_TEXT_COLOR_INTENSITY _FR | _FG | _FB | _FI
int main() {
HANDLE handle = GetStdHandle(STD_OUTPUT_HANDLE);
CONSOLE_SCREEN_BUFFER_INFO srcConsoleScreenBuffInfo;
BOOL successfully = GetConsoleScreenBufferInfo(handle, &srcConsoleScreenBuffInfo);
SetConsoleTextAttribute(handle, _FG);
printf("Hello");
SetConsoleTextAttribute(handle, _FR);
printf(" World!\n");
SetConsoleTextAttribute(handle, MY_TEXT_COLOR);
printf("My Message 1!\n");
SetConsoleTextAttribute(handle, MY_TEXT_COLOR_INTENSITY);
printf("My Message 2!\n");
if (successfully) {
SetConsoleTextAttribute(handle, srcConsoleScreenBuffInfo.wAttributes);
}
printf("Default color.\n");
return 0;
}
示例2
// jave.lin
#include 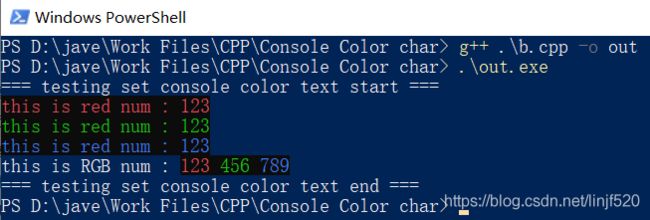
numeric_limits min, max
/* a.cpp - jave.lin */
#include ::min(),\
std::numeric_limits::max()\
);
#define COUT_NUM_INFO(type)\
std::cout.width(15);\
std::cout<<#type;\
std::cout<<"\tsize:";\
std::cout.width(2);\
std::cout<::min();\
std::cout<<"\tmax:";\
std::cout.width(20);\
std::cout<::max()<<"\n";
void print_method() {
printf("printf=====type\tsize:00\tmin:00000000000000000000\tmax:00000000000000000000=====\n", "type");
PRINTF_NUM_INFO(bool,%20d,%20d)
PRINTF_NUM_INFO(char,%20d,%20d)
PRINTF_NUM_INFO(signed char,%20d,%20d)
PRINTF_NUM_INFO(unsigned char,%20d,%20d)
PRINTF_NUM_INFO(wchar_t,%20d,%20d)
PRINTF_NUM_INFO(short,%20d,%20d)
PRINTF_NUM_INFO(unsigned short,%20d,%20d)
PRINTF_NUM_INFO(int,%20d,%20d)
PRINTF_NUM_INFO(unsigned int,%20d,%20d)
PRINTF_NUM_INFO(unsigned,%20d,%20d)
PRINTF_NUM_INFO(long,%20d,%20d)
PRINTF_NUM_INFO(unsigned long,%20d,%20d)
PRINTF_NUM_INFO(long int,%20ld,%20ld)
PRINTF_NUM_INFO(long long,%20ld,%20ld)
PRINTF_NUM_INFO(double,%20e,%20e)
PRINTF_NUM_INFO(long double,%20llg,%20llg)
PRINTF_NUM_INFO(float,%20e,%20e)
PRINTF_NUM_INFO(size_t,%20d,%20d)
PRINTF_NUM_INFO(std::string,%20d,%20d)
printf("printf=====type\tsize:00\tmin:00000000000000000000\tmax:00000000000000000000=====\n", "type");
}
void cout_method() {
printf("cout=======type\tsize:00\tmin:00000000000000000000\tmax:00000000000000000000=====\n", "type");
COUT_NUM_INFO(bool)
COUT_NUM_INFO(char)
COUT_NUM_INFO(signed char)
COUT_NUM_INFO(unsigned char)
COUT_NUM_INFO(wchar_t)
COUT_NUM_INFO(short)
COUT_NUM_INFO(unsigned short)
COUT_NUM_INFO(int)
COUT_NUM_INFO(unsigned int)
COUT_NUM_INFO(unsigned)
COUT_NUM_INFO(long)
COUT_NUM_INFO(unsigned long)
COUT_NUM_INFO(long int)
COUT_NUM_INFO(long long)
COUT_NUM_INFO(double)
COUT_NUM_INFO(long double)
COUT_NUM_INFO(float)
COUT_NUM_INFO(size_t)
COUT_NUM_INFO(std::string)
printf("cout=======type\tsize:00\tmin:00000000000000000000\tmax:00000000000000000000=====\n", "type");
}
int main() {
print_method();
printf("\n\n");
cout_method();
return 0;
}
printf=====type size:00 min:00000000000000000000 max:00000000000000000000=====
bool size: 1 min: 0 max: 1
char size: 1 min: -128 max: 127
signed char size: 1 min: -128 max: 127
unsigned char size: 1 min: 0 max: 255
wchar_t size: 2 min: 0 max: 65535
short size: 2 min: -32768 max: 32767
unsigned short size: 2 min: 0 max: 65535
int size: 4 min: -2147483648 max: 2147483647
unsigned int size: 4 min: 0 max: -1
unsigned size: 4 min: 0 max: -1
long size: 4 min: -2147483648 max: 2147483647
unsigned long size: 4 min: 0 max: -1
long int size: 4 min: -2147483648 max: 2147483647
long long size: 8 min: 0 max: -2147483648
double size: 8 min: 2.225074e-308 max: 1.797693e+308
long double size:12 min: -0 max: -1.#QNAN
float size: 4 min: 1.175494e-038 max: 3.402823e+038
size_t size: 4 min: 0 max: -1
std::string size:24 min: 6422232 max: 6422208
printf=====type size:00 min:00000000000000000000 max:00000000000000000000=====
cout=======type size:00 min:00000000000000000000 max:00000000000000000000=====
bool size: 1 min: 0 max: 1
char size: 1 min: € max:
signed char size: 1 min: € max:
unsigned char size: 1 min: max:
wchar_t size: 2 min: 0 max: 65535
short size: 2 min: -32768 max: 32767
unsigned short size: 2 min: 0 max: 65535
int size: 4 min: -2147483648 max: 2147483647
unsigned int size: 4 min: 0 max: 4294967295
unsigned size: 4 min: 0 max: 4294967295
long size: 4 min: -2147483648 max: 2147483647
unsigned long size: 4 min: 0 max: 4294967295
long int size: 4 min: -2147483648 max: 2147483647
long long size: 8 min:-9223372036854775808 max: 9223372036854775807
double size: 8 min: 2.22507e-308 max: 1.79769e+308
long double size:12 min: 3.3621e-4932 max: 1.18973e+4932
float size: 4 min: 1.17549e-038 max: 3.40282e+038
size_t size: 4 min: 0 max: 4294967295
std::string size:24 min: max:
cout=======type size:00 min:00000000000000000000 max:00000000000000000000=====
extern c/c++ test
c++里的与c的extern一样功能。可以声明外部声明、定义的成员。
还可以用于c++混编时指示编译器在 extern “C” { … }之间的按C风格编译
array
- array Class (C++ Standard Library)
- tuple_element Class
- tuple_size Class;
- get/swap func
2d array to pointer
// jave.lin - 测试类型 2d array[][] 转 pointer
#includemy_vec3 to float*
struct my_vec3;
//using test_vec3 = vec3
using test_vec3 = struct my_vec3;
struct my_vec3 {
float x, y, z;
my_vec3() {
memset((void*)this, 0, sizeof(my_vec3));
}
my_vec3(float x, float y, float z) {
this->x = x;
this->y = y;
this->z = z;
}
};
int main() {
test_vec3* vertices = new test_vec3[3];
for (size_t i = 0; i < 3; i++) {
vertices[i] = test_vec3(i * 3 + 0, i * 3 + 1, i * 3 + 2);
}
std::cout << "floats : ";
float* floats = (float*)vertices;
for (size_t i = 0; i < 9; i++) {
std::cout << *(floats + i);
}
std::cout << "\n";
return 0;
}
// 输出:
// floats : 012345678
pointer - 指针
指针使用比较简单,但是因为太灵活了,有些时候很难做到不泄露内容。
所以新版C++ 也做了引用计数管理的 智能指针
shared_ptr - 只能指针
C++智能指针和普通指针转换需要注意的问题
C++笔记-shared_ptr与weak_ptr需要注意的地方
string test
#include str.data():This is an Message!
str1.data():hello world!
=== string properties: ===
str.size():19
str.substr(1,2).c_str():hi
str.substr(1,-1).c_str():his is an Message!
str.capacity():19
str[2]:i
str.at(3):s
str.data():This is an Message!
str.c_str():This is an Message!
str.empty():0
str.find('i'):2
str.find('a'):8
str.find('A'):-1
str.find_first_not_of('a'):0
str.find_first_of('a'):8
str.find_last_not_of('e'):18
str.find_last_not_of('a'):18
str.find_last_of('a'):15
str.find_last_of('e'):17
str.length():19
str.max_size():1073741823
str.npos:-1
str.back():!
=== after string.swap(str1) properties ===
--- before ---
str.data():This is an Message!
str1.data():hello world!
--- after ---
str.data():hello world!
str1.data():This is an Message!
=== after str1.reserve() properties ===
--- before ---
str1.data():This is an Message!
--- after ---
str1.data():This is an Message!
=== after str.pop_back() & str.push_back('$') ===
--- before str.pop_back() ---
str.data():hello world!
--- after str.pop_back() ---
str.data():hello world
--- before push_back('$') ---
str.data():hello world
--- after push_back('$') ---
str.data():hello world$
=== str.copy(copy_str, 2, 1),copy_str:el
=== str.ease(1) ===
str.erase(1).data():h
=== after string.clear properties ===
str.empty():1
str.size():0
str.capacity():15
str.length():0
=== after string.shrink_to_fit properies ===
str.empty():1
str.size():0
str.capacity():15
str.length():0
=== after string.insert properites ===
str.insert(str.begin(), 'e':str.insert(str.begin(), 'a':str.insert(str.begin(), 't':str.data():tae
=== string.resize properites ===
str.data():tae
str.data():t
=== string.append('123') properites ===
str.data():t123
string raw define
// jave.lin - 测试C++的字符串常量的多种定义方式
#includestringstream
C++stringstream的妙用
char* init by multi char* - 字符串以多个字符串初始化
// jave.lin
#includevolatile 关键字详解
C/C++ 中 volatile 关键字详解
volatile 还有另一个作用,可以阻止编译器 CPU 动态调度换序好值类似:x = 1; y = 2; 换序变成:y = 2; x = 1;的问题,在多线程中比较多见,如下,参考:《程序员的自我修养》中的P30 - 1.6 众人拾柴火焰高
#define barrier() __asm__ volatile ("lwsync")
volatile T* pInst = 0;
T* GetInstance()
{
if (!pInst)
{
lock();
if (!pInst)
{
T* temp = new T;
barrier();
pInst = temp;
}
unlcok();
}
return pInst;
}
const 常量
- 用在普通基础类型数据中:
const 与 macro,还区别的。
#define NUM 1 和 const int NUM = 1; 是有区别的。
前者没有类型检测的,没有内存地址。前者更准确的说是立即说。
而后者是后类型检测的,也只读内存地址。在编译或链接后出来的文件里分配好,专门储存在只读地址区块内存。
- 用在函数参数时:
returnType functionName(const paramType paramName);
它表示在函数运行过程中对 paramName 是不可修改的。
- 用在函数签名末端时:
returnType functionName(paramType paramName) const;
它是对 functionName 函数的隐式 this 参数的修饰:
returnType functionName(paramType paramName);没有末端const时,functionName的this参数是:const ClassType * this;returnType functionName(paramType paramName); cosnt有在末端const时,functionName的this参数是:const ClassType * const this;表示 this 对象内的所有数据不改修改。但如果ClassType 中某个数据成员有mutable修饰的话,也是可以修改的,并且不报错,如果没有mutable修饰的话,编译会报错。
参考:C/C++基础面试-Const的全面理解(C部分)
int p = 0x1;
const int* a1=&p; //变量a1,int*,const,表名指向的数据不可改
int const *a2 = &p; //同a1
int* const a3=&p; //a3指向的地址不能修改
int const* const a4=&p; //什么都不能修改
constexpr
C++11的constexpr关键字
C++ compiler & runtime std version
检查C++11不支持register 与 auto,那就测试一下。
先查看我们的编译器版本
PS D:\jave\Work Files\CPP\register> g++ --version
g++.exe (MinGW.org GCC Build-20200227-1) 9.2.0
Copyright (C) 2019 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
测试代码
// jave.lin
#include 输出
PS D:\jave\Work Files\CPP\register> g++ .\a.cpp -o out -std=c++11
PS D:\jave\Work Files\CPP\register> .\out.exe __GNUC__:9__cplusplus:201103
Supporting the register and auto keywords, when version lesser than c++14.
register var i:1
auto b typeid.name() : i
PS D:\jave\Work Files\CPP\register> g++ .\a.cpp -o out -std=c++17
PS D:\jave\Work Files\CPP\register> .\out.exe __GNUC__:9__cplusplus:201703
Not supporting the register and auto keywords, when version greater than c++14.
normally var i:1
int b typeid.name() : i
lambda
// jave.lin
#include --lambda format : [capture](parameters)->return-type{body}--
========== normally test ===========
a:2, b:3, a + b = c:5
after opt(add, a, b, c), a:2, b:3, c:5
after opt(sub, a, b, c), a:2, b:3, c:-1
after opt(lambda_multi, a, b, c), a:2, b:3, c:6
after opt(lambda_div, a, b, c), a:2, b:3, c:0
========== address test ===========
add func':00401438
add callback func':00401438
sub func':00401445
sub callback func':00401445
lambda_multi callback func':00401506, int:4199686
again, lambda_multi callback func':0040154C, int:4199756
callback address diff:70
========== capture test ===========
==1.f:100
==2.f:200
==3.f:300
==4.f1:0,f2:0,f3:1
==5.f1:0,f2:0,f3:2
==6.global_i:10
==7.x:0
struct & class refer to params for pass to func
#include ->before s.value:1
<-after s.value:1
->before s1.value:1
<-after s1.value:4
call construct func C1.value:2, name:First
->before c.value:2
call destruct func C1.value:3, name:First
<-after c.value:2
call construct func C1.value:2, name:Second
->before c1.value:2
<-after c1.value:3
->before c2.value:3
<-after c2.value:4
call destruct func C1.value:4, name:Second
call destruct func C1.value:2, name:First
struct, class mem layout - 内存布局
// jave.lin - 测试 CPP 的 struct 内存布局
#includedynamic_cast & force cast
#include (j); // 编译不过,因为原始类型与目标类型没有上下继承关系
Human* hhh = (Human*)(j);
printf("===6===typeid(hhh).name():%s, hhh'':%p\n", typeid(hhh).name(), hhh);
return 0;
}
/*
construct P5Human, name:Tony, age:18
construct P4Tony, name:Tony, age:18
===1===typeid(t).name():4Tony
===2===typeid(h).name():5Human
construct P5Human, name:Tony, age:18
construct P4Tony, name:Tony, age:18
===3===typeid(hh).name():P5Human
===4===typeid(j).name():P5Jerry
===5===typeid(vj).name():Pv // 从这个输出可以看出,啥都可以转为void *类型,而且C++的typeid(obj).name()值只会返回当前声明类型的名称
===6===typeid(hhh).name():P5Human, hhh'':00EF6E60
destruct P5Human, name:Tony, age:18
destruct P5Human, name:Tony, age:18
*/
Static_cast 与 Dynamic_cast的区别
- Static_cast 与 Dynamic_cast的区别
- 关于C++中的dynamic cast的使用
- When should static_cast, dynamic_cast, const_cast and reinterpret_cast be used?
- C++ 中 dynamic_cast 浅析
class - override kinds of operators
可查看:C++ 重载运算符和重载函数
可重载
| 分类 | 符号 |
|---|---|
| 双目算术运算符 | + (加),-(减),*(乘),/(除),% (取模) |
| 关系运算符 | ==(等于),!= (不等于),< (小于),> (大于>,<=(小于等于),>=(大于等于) |
| 逻辑运算符 | ||(逻辑或),&&(逻辑与),!(逻辑非) |
| 单目运算符 | + (正),-(负),*(指针),&(取地址) |
| 自增自减运算符 | ++(自增),–(自减) |
| 位运算符 | | (按位或),& (按位与),~(按位取反),^(按位异或),,<< (左移),>>(右移) |
| 赋值运算符 | =, +=, -=, *=, /= , % = , &=, |
| 空间申请与释放 | new, delete, new[ ] , delete[] |
| 其他运算符 | ()(函数调用),->(成员访问),,(逗号), |
不可重载
| 符号 | 分类 |
|---|---|
| .: | 成员访问运算符 |
| ., ->: | 成员指针访问运算符 |
| ::: | 域运算符 |
| sizeof: | 长度运算符 |
| ?:: | 条件运算符 |
| #: | 预处理符号 |
#include construct typeid.name:P1A, name:Tom
construct typeid.name:P1A, name:Jerry
bool A::operator==(const A &dest), cmp(src:Tom, dest:Jerry)==0
==1==cmp, a == a1 : 0
copy construct typeid.name:P1A, name:Jerry
copy construct typeid.name:P1A, name:Tom
==2==a.name:Tom, a1.name:Jerry, a':0061FE94, a1':0061FE7C
destruct typeid.name:P1A, name:Tom
destruct typeid.name:P1A, name:Jerry
-->before copy from a1
A& A::operator=(const A ©From), src:Tom, dest:Jerry
<--after copy from a1
copy construct typeid.name:P1A, name:Jerry
copy construct typeid.name:P1A, name:Jerry
==3==a.name:Jerry, a1.name:Jerry, a':0061FEC4, a1':0061FEAC
destruct typeid.name:P1A, name:Jerry
destruct typeid.name:P1A, name:Jerry
bool A::operator==(const A &dest), cmp(src:Jerry, dest:Jerry)==1
==4==mp, a == a1 : 1
-->before callCopyConstruct
copy construct typeid.name:P1A, name:Testing
destruct typeid.name:P1A, name:Testing
<--after callCopyConstruct
-->before a1.name = a.name
<--after a1.name = a.name
bool A::operator==(const A &dest), cmp(src:Testing, dest:Testing)==1
==5==cmp, a == a1 : 1
-->before operator=(const std::string)
A& A::operator=(const std::string name), src:Testing, dest:Davide
<--after operator=(const std::string)
-->before copy self
A& A::operator=(const A ©From), src:Davide, dest:Davide
avoid copy self
<--after copy self
bool A::operator==(const A &dest), cmp(src:Davide, dest:Testing)==0
==6==cmp, a == a1 : 0
destruct typeid.name:P1A, name:Testing
destruct typeid.name:P1A, name:Davide
class friend
// jave.lin
#include class static memeber
// jave.lin
#include A'aaa:-1
A::value:999
A::value:1000
enter Class B CallAPrivateMethod.
this is Class A privateMethod.
exit Class B CallAPrivateMethod.
A::const_value:2000
global s : 18
static global s1 : 19
const static global s2 : 20
class virtual func
// jave.lin
#include 虚函数,在每个类蓝图都有一个virtual function table,虚拟函数表
每个表的相同函数签名的函数只有一个。即:在编译时如果派生类覆盖了,那么就不会使用基类的,即使转换类型为其他基类型也是使用覆盖的函数,因为就只有一个。
而普通的函数则不同,所有函数都在对应的类蓝图定义下的函数表中,根据函数签名一一对应的。
即:只要将类型转换到当前对转换到对应的类,就会调用对用类定义下的函数。
class multi inherit
// jave.lin
#include multi_inherit_ctor_dector
#includeclass static
- static 成员未初始化引起 error lnk2001
class MouseInfo {
public:
static double x, y;
static double deltaX, deltaY;
};
// 如果没有下面的初始化 static 就会编译包 LNK 2001 错误
double MouseInfo::x = 0;
double MouseInfo::y = 0;
double MouseInfo::deltaX = 0;
double MouseInfo::deltaY = 0;
new、operator new、placement new
C++ 内存分配(new,operator new)详解
c++中的new、operator new、placement new
enum
- C++中enum的使用
- Enumeration declaration
pair
C++ pair的基本用法总结(整理)
#if COMMENT
std::pair<class FirstType, class SecondType>
#endif
// init
std::pair<std::string, int> person("tony", 18);
// get
printf("name:%s, age:%d\n", person.first.c_str(), person.second);
get
详细参考:std::get(std::pair)
#include complex
在complex头文件定义可以看到:
...
template <class _Ty>
struct _Complex_value {
enum { _Re = 0, _Im = 1 };
_Ty _Val[2];
};
// CLASS TEMPLATE _Complex_base
template <class _Ty, class _Valbase>
class _Complex_base : public _Valbase {
public:
using _Myctraits = _Ctraits<_Ty>;
using value_type = _Ty;
constexpr _Complex_base(const _Ty& _Realval, const _Ty& _Imagval) : _Valbase{{_Realval, _Imagval}} {}
_Ty real(const _Ty& _Right) { // set real component
return this->_Val[_RE] = _Right;
}
_Ty imag(const _Ty& _Right) { // set imaginary component
return this->_Val[_IM] = _Right;
}
_NODISCARD constexpr _Ty real() const { // return real component
return this->_Val[_RE];
}
_NODISCARD constexpr _Ty imag() const { // return imaginary component
return this->_Val[_IM];
}
...
可以看到实质就是一个:struct结构体,里面有个_Ty _Val[2]数组而已
template <class _Ty>
struct _Complex_value {
enum { _Re = 0, _Im = 1 };
_Ty _Val[2];
};
每次我们real()就是return _Val[_Re],real(float v)就是_Val[_Re] = v;
// jave.lin
#includeset
C++ set用法总结(整理)
set - 插入、删除、初始化、遍历、查找、清除
#includemap
C++ map用法总结(整理)
map 插入、查找、遍历
#includevector
// jave.lin
#include#define,typedef,using用法区别
C++ #define,typedef,using用法区别
define没啥可说,就是预编译的关键字,定义需要宏文字替换的功能。
而typedef, using功能一样,但using是C++11后出来的东西,C++委员会推荐using替换typedef。
因为using可读性比typedef高
随着C++11后,因为委员会的推荐使用using,那么就开始弄个using能做,typedef不能的。
using的编译、运行都正常
template <typename T>
using Vec = MyVector<T, MyAlloc<T>>;
// usage
Vec<int> vec;
typedef的编译会报错error: a typedef cannot be a template
template <typename T>
typedef MyVector<T, MyAlloc<T>> Vec;
// usage
Vec<int> vec;
macros nested - 宏嵌套
#includepragma - 编译指令
可以参考:
- OpenGL学习笔记[3]:#pragma comment
#pragma message(“compiling output message”) - 编译输出信息
// jave.lin
// Check GCC
#if __GNUC__
# pragma message("compiling in GNUC, GCC")
# if __x86_64__ || __ppc64__
# pragma message("64 bits computer")
# define ENVIRONMENT64
# else
# pragma message("32 bits computer")
# define ENVIRONMENT32
# endif
#else
// Check windows
# pragma message("compiling Not in GNUC, GCC")
# if _WIN32 || _WIN64
# pragma message("compiling in Window32/64")
# if _WIN64
# pragma message("64 bits computer")
# define ENVIRONMENT64
# else
# pragma message("32 bits computer")
# define ENVIRONMENT32
# endif
# endif
#endif
编译输出:
1、在VS中的MSVC的编译输出:
1>compiling Not in GNUC, GCC
1>compiling in Window32/64
1>32 bits computer
2、在VSC中使用GCC的编译输出:
a.cpp:7:44: note: #pragma message: compiling in GNUC, GCC
7 | # pragma message("compiling in GNUC, GCC")
| ^
a.cpp:12:42: note: #pragma message: 32 bits computer
12 | # pragma message("32 bits computer")
|
VS 中的MSVC编译输出:
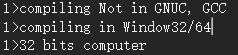
VSC 中的GCC编译输出:

#pragma pack
- C++编译指令#pragma pack的配对使用
- C++中#pragma pack(N)的用法
- C/C++:#pragma pack(1)
- C++中的#pragma pack效果
- C++预处理器及pragma pack(n)的理解
- #pragma pack学习
- #pragma pack()用法详解
- C++之内存对齐
- 从硬件到语言,详解C++的内存对齐(memory alignment)
fstream, ofstream, ifstream
#include PS D:\jave\Work Files\CPP\fstream,ifstream,ofstream> g++ .\a.cpp -o out
PS D:\jave\Work Files\CPP\fstream,ifstream,ofstream> .\out.exe
.\MyTxt.txt reading complete:
input your message:1111111111111111111
writeStr:1111111111111111111
.\MyTxt.txt writing complete:1111111111111111111
PS D:\jave\Work Files\CPP\fstream,ifstream,ofstream> .\out.exe
reading line:1111111111111111111
.\MyTxt.txt reading complete:
1111111111111111111
input your message:22222222222222222
writeStr:22222222222222222
.\MyTxt.txt writing complete:22222222222222222
PS D:\jave\Work Files\CPP\fstream,ifstream,ofstream> .\out.exe
reading line:1111111111111111111
reading line:22222222222222222
.\MyTxt.txt reading complete:
1111111111111111111
22222222222222222
input your message:333333333333333
writeStr:333333333333333
.\MyTxt.txt writing complete:333333333333333
PS D:\jave\Work Files\CPP\fstream,ifstream,ofstream> .\out.exe
reading line:1111111111111111111
reading line:22222222222222222
reading line:333333333333333
.\MyTxt.txt reading complete:
1111111111111111111
22222222222222222
333333333333333
input your message:this is 4th message.
writeStr:this is 4th message.
.\MyTxt.txt writing complete:this is 4th message.
PS D:\jave\Work Files\CPP\fstream,ifstream,ofstream> .\out.exe
reading line:1111111111111111111
reading line:22222222222222222
reading line:333333333333333
reading line:this is 4th message.
.\MyTxt.txt reading complete:
1111111111111111111
22222222222222222
333333333333333
this is 4th message.
input your message:#clear
inputing cmd...[clear].
clearing...
.\MyTxt.txt, clear complete!
PS D:\jave\Work Files\CPP\fstream,ifstream,ofstream> .\out.exe
.\MyTxt.txt reading complete:
input your message:
empty writing str, cancel writing.
C++ seekp和seekg函数用法详解
C++ seekp和seekg函数用法详解
一次读完
参考:tutorial2.c
#includetry…catch…/exception
// jave.lin
#include 如果想要更详细的调试信息,可以参考GNU C Library:
- Backtraces
- GDB: The GNU Project Debugger
GDB 调试输出更信息的信息
可参考:Find Where a C++ Exception is Thrown
throw_exception.cpp
#include ~/exception$ make
g++ -g throw_exception.cpp -o throw_exception
~/exception$ gdb throw_exception
...
Reading symbols from throw_exception...done.
(gdb) catch throw
Catchpoint 1 (throw)
(gdb) run
Starting program: throw_exception
Catchpoint 1 (exception thrown), 0x00007ffff7b8f910 in __cxa_throw () from /usr/lib/libstdc++.so.6
(gdb) where
#0 0x00007ffff7b8f910 in __cxa_throw () from /usr/lib/libstdc++.so.6
#1 0x0000000000400d89 in function () at throw_exception.cpp:8
#2 0x0000000000400dca in main () at throw_exception.cpp:15
(gdb)
namespace - 命名空间
命名空间会修改函数签名,所以这样就算是两个函数参数,名称一模一样,只要他们命名空间不同也是两个不同的函数,因为最终函数签名不一样了
#include template function/class
C++泛型与多态(1):基础篇
// jave.lin
#include typename 与class区别
在 C++ Template 中很多地方都用到了 typename 与 class 这两个关键字,而且好像可以替换,是不是这两个关键字完全一样呢?
相信学习 C++ 的人对 class 这个关键字都非常明白,class 用于定义类,在模板引入 c++ 后,最初定义模板的方法为:
template<class T>......
这里 class 关键字表明T是一个类型,后来为了避免 class 在这两个地方的使用可能给人带来混淆,所以引入了 typename 这个关键字,它的作用同 class 一样表明后面的符号为一个类型,这样在定义模板的时候就可以使用下面的方式了:
template<typename T>......
在模板定义语法中关键字 class 与 typename 的作用完全一样。
typename 难道仅仅在模板定义中起作用吗?其实不是这样,typename 另外一个作用为:使用嵌套依赖类型(nested depended name),如下所示:
class MyArray
{
public:
typedef int LengthType;
.....
}
template<class T>
void MyMethod( T myarr )
{
typedef typename T::LengthType LengthType;
LengthType length = myarr.GetLength;
}
这个时候 typename 的作用就是告诉 c++ 编译器,typename 后面的字符串为一个类型名称,而不是成员函数或者成员变量,这个时候如果前面没有 typename,编译器没有任何办法知道 T::LengthType 是一个类型还是一个成员名称(静态数据成员或者静态函数),所以编译不能够通过。
thread / mutex
g++ 编译报错
#include 编译报错
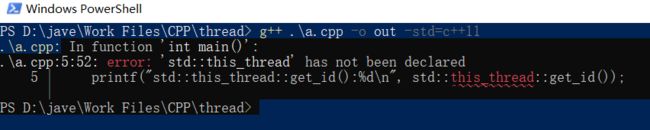
.\a.cpp: In function 'int main()':
.\a.cpp:5:52: error: 'std::this_thread' has not been declared
5 | printf("std::this_thread::get_id():%d\n", std::this_thread::get_id());
VS C++没有这个问题
与上面同样的代码
运行:
std::this_thread::get_id():10884

网上查了,大概是编译器的问题
note: ‘std::thread’ is defined in header ‘’; did you forget to '#include '?
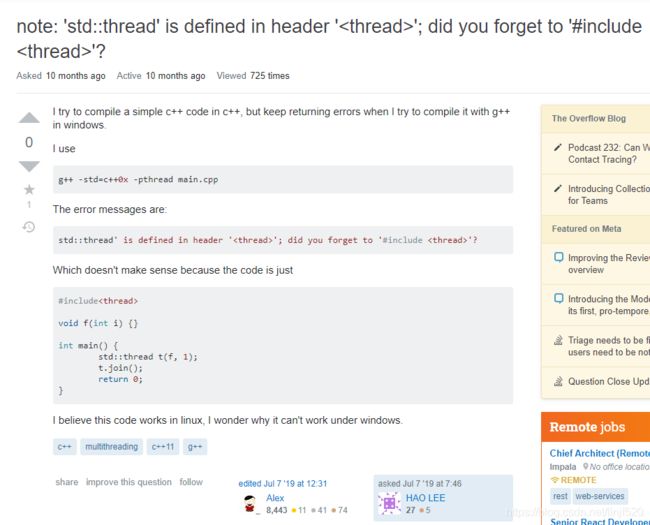
而且include的文件都是一样的
另一个是:identifier “thread” is undefined
它的解决方法是:
- 删除原来的MinGW
- 重新安装了MinGW就好了
我的解决办法是:直接使用VS来编写就没有问题的。(编译器不一样,VS中我使用的是默认的:MSVC编译器)
测试thread / mutex / atomic
参考 微软在线文档:
-
-
-
-
C++ std::thread
-
C++11 原子类型与原子操作
这些概念在很久很久以前我用C#写多线程都是一样的概念。
atomic 就是原子性的操作:原子操作是在多线程程序中“最小的且不可并行化的”操作,意味着多个线程访问同一个资源时,有且仅有一个线程能对资源进行操作。
C#、C++也都封装了原子操作的简便操作。
C#中的我记得是:Interlock_XXX。
C++的则可以直接声明使用原型操作的数据类型:
std::atomic
// jave.lin
#include > HourType; // hours_type;
// 其实也可以在 chrono、ratio头文件中看到类似定义
#if THIS_IS_COMMENT
// in file
// duration TYPES
using nanoseconds = duration<long long, nano>;
using microseconds = duration<long long, micro>;
using milliseconds = duration<long long, milli>;
using seconds = duration<long long>;
using minutes = duration<int, ratio<60>>;
using hours = duration<int, ratio<3600>>;
// in file
// SI TYPEDEFS
using atto = ratio<1, 1000000000000000000LL>;
using femto = ratio<1, 1000000000000000LL>;
using pico = ratio<1, 1000000000000LL>;
using nano = ratio<1, 1000000000>;
using micro = ratio<1, 1000000>;
using milli = ratio<1, 1000>;
using centi = ratio<1, 100>;
using deci = ratio<1, 10>;
using deca = ratio<10, 1>;
using hecto = ratio<100, 1>;
using kilo = ratio<1000, 1>;
using mega = ratio<1000000, 1>;
using giga = ratio<1000000000, 1>;
using tera = ratio<1000000000000LL, 1>;
using peta = ratio<1000000000000000LL, 1>;
using exa = ratio<1000000000000000000LL, 1>;
#endif
void thread_callback_sec(size_t sec) {
printf("-->enter [%s-%d]\n", __func__, std::this_thread::get_id());
// code here
printf("[%s] sleep %d second.\n", __func__, sec);
SecType howManySeconds(sec);
std::this_thread::sleep_for(howManySeconds);
printf("<--exit [%s-].\n", __func__, std::this_thread::get_id());
}
void thread_callback_msec(size_t msec) {
printf("-->enter [%s-%d]\n", __func__, std::this_thread::get_id());
// code here
printf("[%s] sleep %d milli-second.\n", __func__, msec);
MSecType howManyMilliSeconds(msec);
std::this_thread::sleep_for(howManyMilliSeconds);
printf("<--exit [%s-].\n", __func__, std::this_thread::get_id());
}
// ======================== atmoic/synic ========================
// 是否启用线程数据安全同步操作
#define SYNC_ENDABLE
// 同步操作类型,用atomic或是Mutex
#define SYNC_BY_MUTEX 1 // mutex方式
#define SYNC_BY_ATOMIC_DATATYPE 2 // 方式
#define SYNC_TYPE SYNC_BY_ATOMIC_DATATYPE // 同步类型
// 是否启用检测线程结束
#define THREAD_CHECK_END_ENABLED
// 检测线程结束的类型
#define THREAD_CHECK_END_BY_MUTEX 1 // mutex方式
#define THREAD_CHECK_END_BY_ATOMIC_FLAG 2 // atomic_flag方式
#define THREAD_CHECK_END_TYPE THREAD_CHECK_END_BY_ATOMIC_FLAG
// 提前放弃所有线程继续执行
//#define EARLY_ABORT_ALL_THREAD_ENABLE
bool ready = false;
const size_t thread_count = 10;
const size_t thread_loop_count = 100000;
#if defined(SYNC_ENDABLE) && defined(SYNC_TYPE) && SYNC_TYPE == SYNC_BY_ATOMIC_DATATYPE
std::atomic_size_t counter = 0;
#else
size_t counter = 0;
#endif
// diy locker
// 使用std::atomic_flag的原子操作来处理
// std::atomic_flag::test_and_set()第一次返回false,直到clear后才返回true
class mylocker {
public:
// 成功锁定返回
const bool lock() {
while (flag.test_and_set(std::memory_order::memory_order_acquire))
std::this_thread::yield();
return true;
}
void unlock() {
flag.clear(std::memory_order::memory_order_release);
}
private:
std::atomic_flag flag = ATOMIC_FLAG_INIT;
};
#if THREAD_CHECK_END_TYPE == THREAD_CHECK_END_BY_MUTEX
typedef std::mutex locker;
#else // THREAD_CHECK_END_TYPE == THREAD_CHECK_END_BY_ATOMIC_FLAG
typedef mylocker locker;
#endif
class ThreadParams {
public:
locker* group_mutex = nullptr;
locker* add_counter_mutex = nullptr;
ThreadParams()
: group_mutex(nullptr),
add_counter_mutex(nullptr) {
}
ThreadParams(locker* gm, locker* acm)
: group_mutex(gm),
add_counter_mutex(acm) {
}
ThreadParams& operator=(ThreadParams v) {
this->group_mutex = v.group_mutex;
this->add_counter_mutex = v.add_counter_mutex;
return *this;
}
};
void thread_callback_counter(ThreadParams* params) {
while (!ready) {
std::this_thread::yield(); // 放弃后续时间片
}
#if defined(THREAD_CHECK_END_ENABLED)
params->group_mutex->lock();
#endif
printf("-->enter [%s-%d], counter : %ld\n", __func__, std::this_thread::get_id(), (size_t)counter);
for (size_t i = 0; i < thread_loop_count; i++) { // 越快的CPU,这个loop设置大一些,否则看不到效果
#ifdef SYNC_ENDABLE
#if SYNC_TYPE == SYNC_BY_MUTEX
data->add_counter_mutex->lock();
++counter;
data->add_counter_mutex->unlock();
#else
++counter; // 使用atomic的原子操作,不用mutex互斥量来原子操作
#endif
#else
++counter; // 没有原子操作,在多线程并行对同一个数据对象处理会不安全
#endif
}
printf("<--exit [%s-], counter : %ld\n", __func__, std::this_thread::get_id(), (size_t)counter);
#if defined(THREAD_CHECK_END_ENABLED)
params->group_mutex->unlock();
#endif
}
int main() {
printf("support thread : %s\n", __STDCPP_THREADS__ == 1 ? "true" : "false");
printf("using locker type : %s\n", typeid(locker).name());
printf("\n============= join/sleep test ============\n");
printf("[%s-%d]\n", __func__, std::this_thread::get_id());
#if __STDCPP_THREADS__
size_t seconds = 2;
size_t mseconds = 500;
std::thread secThread(thread_callback_sec, seconds);
std::thread::id id = secThread.get_id();
printf("secThread.get_id():%d\n", id);
secThread.join();
std::thread msecThread(thread_callback_msec, mseconds);
id = msecThread.get_id();
printf("msecThread.get_id():%d\n", id);
msecThread.join();
printf("\n============= counter test ============\n");
ThreadParams thParams[thread_count];
locker* add_counter_mutex = new locker();
for (size_t i = 0; i < thread_count; i++) {
//thParams[i] = ThreadParams(new locker(), add_counter_mutex);
thParams[i] = { new locker(), add_counter_mutex };
}
std::thread ts[thread_count];
for (size_t i = 0; i < thread_count; i++) {
ts[i] = std::thread(thread_callback_counter, &thParams[i]);
ts[i].detach(); // 独立运行,join()是线程阻塞执行,有想想sequence执行,detach就并行的
}
// 启用线程结束检测
#ifdef THREAD_CHECK_END_ENABLED
printf("\n============= check exit_group_mutex to exit ============\n");
ready = true;
#ifdef EARLY_ABORT_ALL_THREAD_ENABLE
// 提前放弃、结束线程
MSecType sleepMSecond(1);
printf("sleep %d milliseconds before abort all thread\n.", sleepMSecond);
std::this_thread::sleep_for(sleepMSecond);
printf("after sleep %d seconds abort all thread\n.", sleepMSecond);
for (size_t i = 0; i < thread_count; i++) {
thParams[i].group_mutex->unlock();
ts[i].~thread();
}
add_counter_mutex->unlock();
#endif
// 保证 main thread 最后退出,先让其他子线先执行完,用mutex来检测
for (size_t i = 0; i < thread_count; i++) {
thParams[i].group_mutex->lock();
thParams[i].group_mutex->unlock();
}
// 检测所有线程执行完成的另一个方法更简单的是:
// 在全局变量声明定义一个:atomic_size_t thread_runing_counter = thread_count;
// 然后在每一个线程最后一个语句执行:--thread_runing_counter即可
// 在这里就只要检测:while(thread_runing_counter>0) std::this_thread::yield();即可
#endif // #ifdef THREAD_CHECK_END_ENABLED
printf("\n============= check exit_group_mutex to exit complete! ============\n");
printf("counter:%d\n", (size_t)counter);
#ifndef EARLY_ABORT_ALL_THREAD_ENABLE
printf("thread safely : %s", ((size_t)counter) == (thread_loop_count * thread_count) ? "true" : "false");
#endif // !EARLY_ABORT_ALL_THREAD_ENABLE
#else
printf("not support thread.\n");
#endif
return 0;
}
输出:
support thread : true
using locker type : class mylocker
============= join/sleep test ============
[main-11844]
secThread.get_id():12920
-->enter [thread_callback_sec-12920]
[thread_callback_sec] sleep 2 second.
<--exit [thread_callback_sec-].
msecThread.get_id():21880
-->enter [thread_callback_msec-21880]
[thread_callback_msec] sleep 500 milli-second.
<--exit [thread_callback_msec-].
============= counter test ============
============= check exit_group_mutex to exit ============
-->enter [thread_callback_counter-23256], counter : 0
-->enter [thread_callback_counter-16000], counter : 980
-->enter [thread_callback_counter-16392], counter : 0
-->enter [thread_callback_counter-13912], counter : 0
-->enter [thread_callback_counter-4488], counter : 0
-->enter [thread_callback_counter-9748], counter : 0
-->enter [thread_callback_counter-17864], counter : 0
-->enter [thread_callback_counter-12572], counter : 0
-->enter [thread_callback_counter-19556], counter : 0
-->enter [thread_callback_counter-20844], counter : 0
<--exit [thread_callback_counter-], counter : 16392
<--exit [thread_callback_counter-], counter : 20844
<--exit [thread_callback_counter-], counter : 4488
<--exit [thread_callback_counter-], counter : 9748
<--exit [thread_callback_counter-], counter : 12572
<--exit [thread_callback_counter-], counter : 13912
<--exit [thread_callback_counter-], counter : 23256
<--exit [thread_callback_counter-], counter : 16000
<--exit [thread_callback_counter-], counter : 17864
<--exit [thread_callback_counter-], counter : 19556
============= check exit_group_mutex to exit complete! ============
counter:1000000
thread safely : true
如果我们将#define SYNC_ENDABLE注释掉。
那么输出counter的分线程并行计算就没有线程安全了
============= check exit_group_mutex to exit ============
-->enter [thread_callback_counter-8560], counter : 0
-->enter [thread_callback_counter-11232], counter : 0
-->enter [thread_callback_counter-5792], counter : 0
-->enter [thread_callback_counter-3244], counter : 0
-->enter [thread_callback_counter-9656], counter : 55058
<--exit [thread_callback_counter-], counter : 8560
-->enter [thread_callback_counter-14428], counter : 134866
-->enter [thread_callback_counter-21476], counter : 196042
<--exit [thread_callback_counter-], counter : 11232
-->enter [thread_callback_counter-6412], counter : 212773
-->enter [thread_callback_counter-21468], counter : 268226
-->enter [thread_callback_counter-14016], counter : 277952
<--exit [thread_callback_counter-], counter : 5792
<--exit [thread_callback_counter-], counter : 3244
<--exit [thread_callback_counter-], counter : 21468
<--exit [thread_callback_counter-], counter : 9656
<--exit [thread_callback_counter-], counter : 21476
<--exit [thread_callback_counter-], counter : 6412
<--exit [thread_callback_counter-], counter : 14428
<--exit [thread_callback_counter-], counter : 14016
============= check exit_group_mutex to exit complete! ============
counter:447351
thread safely : false
scope - 作用域
C++ 域有:全局域、命名空间域、类域、函数域、函数子块域
// jave.lin - testing scope
#includemove、forward
C++11朝码夕解: move和forward
Calling Conversion - 调用约定
- C++ _cdecl,_stdcall,_fastcall 函数调用约定/协议
__declspec - 规范定义
c++ 中__declspec 的用法
Debugging C++ Source Code using GDB in Windows
VSC C++ Debugging Settings
错误、异常处理
LNK 2019
无法解析的外部符号。
这是一个编译错误。
先看 错误ID 提示:LNK == Link,2019是编号。
指的是编译后的链接处理除了问题,链接一般处理的是符号地址的重新调整,因为有些全局对象,或是函数,或是类定义的全局成员、函数中,函数用到别的文件的定义的函数、对象是,或是对象、函数被其他文件用到时,在编译时会先预留一个默认的值,这个值是不正确的,以前是需要手动去调整的,很痛苦,现在有链接器了,就可以帮我们快速、无误的处理这些无聊、易错的工作。它就是想一些用到外部文件定义的对象、函数的地址重新调整。有些是静态链接的还会将文件合并处理,再调整所有相关的对象、函数地址(这些都是符号,它们都有地址)。
所以我们知道了链接器的工作原理,这个编译错误的问题自然就不难理解。
case 1
就是说链接器编译过程中符号都是有的(符号一般就是我们就写声明),如果我们的声明与实现分开的话,有些头文件没有明文include 对象的.cpp,那么这些.cpp文件没有在项目中引入,那么编译器是没有问题的,因为声明是有的,但是链接器就找不到外部符号(对象、函数)的具体实现的地址,所以就会报这个错误。
所以解决方法,就是将这些.cpp包含到你的项目中即可解决。
case 2
如果你有一个.lib静态库,在使用时,一般是需要将其放在我们设置的库目录下的,并且要将这个库的头文件放到include目录。
如果这时,你只将头文件放到了include目录,到时.lib文件没有,或是位置不对,那么也是会有这问报错的。
C++ “void std::sort(const _RanIt,const _RanIt)”: 应输入 2 个参数,却提供了 3 个 - 已解决
- C++ “void std::sort(const _RanIt,const _RanIt)”: 应输入 2 个参数,却提供了 3 个 - 已解决
C++ 实例
C++ 实例
judge basic type or data is signed or not - 判断有符号和无符号的变量或类型[C/C++]
判断有符号和无符号的变量或类型[C/C++]
获取工作空间目录或获取运行程序目录
typedef char CHAR;
...
typedef wchar_t WCHAR; // wc, 16-bit UNICODE character
...
typedef _Null_terminated_ CHAR *LPSTR;
...
typedef _Null_terminated_ WCHAR *LPWSTR;
...
WINBASEAPI
_Success_(return != 0 && return < nBufferLength)
DWORD
WINAPI
GetCurrentDirectoryA(
_In_ DWORD nBufferLength,
_Out_writes_to_opt_(nBufferLength, return + 1) LPSTR lpBuffer
);
WINBASEAPI
_Success_(return != 0 && return < nBufferLength)
DWORD
WINAPI
GetCurrentDirectoryW(
_In_ DWORD nBufferLength,
_Out_writes_to_opt_(nBufferLength, return + 1) LPWSTR lpBuffer
);
#ifdef UNICODE
#define GetCurrentDirectory GetCurrentDirectoryW
#else
#define GetCurrentDirectory GetCurrentDirectoryA
#endif // !UNICODE
注意,从定义可以看出来
GetCurrentDirectoryW 的最后一个字符 “W” GetCurrentDirectoryW 第二个接收返回字符串结果的类型是 wchar_t,宽字符的,16 bits,2 个 bytes的。
GetCurrentDirectoryA 的最后一个字符 “A” GetCurrentDirectoryA 第二个接收返回字符串结果的类型是 char_t,宽字符的,8 bits,1 个 byte的。
使用
#include运行:
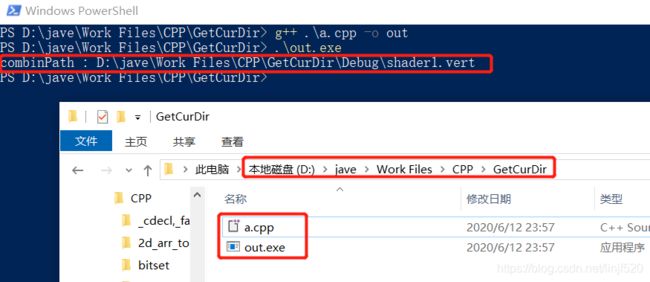
FindWindow - 查找窗体句柄
我们在window 开始菜单输入:notepad
默认打开的notepad 的窗体标题是:无标题 - 记事本
然后我们可以通过全局 API FindWindow 来查找窗体句柄
直接使用该 API的话,现在是有分两个版本的,一个是宽字节(或叫长字节:typedef unsigned short wchar_t;),或是普通短字节(typedef char CHAR;)
WINUSERAPI
HWND
WINAPI
FindWindowA(
_In_opt_ LPCSTR lpClassName,
_In_opt_ LPCSTR lpWindowName);
WINUSERAPI
HWND
WINAPI
FindWindowW(
_In_opt_ LPCWSTR lpClassName,
_In_opt_ LPCWSTR lpWindowName);
#ifdef UNICODE
#define FindWindow FindWindowW
#else
#define FindWindow FindWindowA
#endif // !UNICODE
注意 L"this is wchar" 来声明该字符串是 wchar_t的
const wchar_t* _w_chars = L"this is wchars"; // 宽字符串
const char* _chars = "this is normal chars"; // 短字符串
查找窗体
#define USE_WC
#ifdef USE_WC
const wchar_t* winTitleName = L"无标题 - 记事本";
//HWND handle = ::FindWindowW(L"Notepad", winTitleName);
HWND handle = ::FindWindowW(NULL, winTitleName);
#else
const char* winTitleName = L"无标题 - 记事本";
HWND handle = ::FindWindowA("Notepad", winTitleName);
#endif
if (handle != NULL) {
std::cout << "Found the Window : " << winTitleName << "\n";
}
else {
std::cout << "Not Found the Window : " << winTitleName << "\n";
}
std::cout 输出10进制与16进制的控制
glBindTextureUnit(0, 99);
GLenum error = glGetError();
if (error != 0) {
std::cout << std::dec; // 以10进制显示数值
std::cout << "glError : " << error;
std::cout << std::hex; // 以16进制显示数值
std::cout << "(0x" << error << ")" << std::endl;
}
/* 输出:
glError : 1282(0x502)
*/
C++ 实例 - 求一元二次方程的根
C++ 实例 - 求一元二次方程的根
二次方程 ax2+bx+c = 0 (其中a≠0),a 是二次项系数,bx 叫作一次项,b是一次项系数;c叫作常数项。
x 的值为:
x = − b ± b 2 − 4 a c 2 a x=\cfrac{-b\pm\sqrt{b^2-4ac}}{2a} x=2a−b±b2−4ac
根的判别式
对于 实系数 一元二次方程 a x 2 + b x + c = 0 ( 0 ) ax^2+bx+c=0(0) ax2+bx+c=0(0), Δ = b 2 − 4 a c \Delta=b^2-4ac Δ=b2−4ac称作一元二次方程根的 判别式。根据判别式,一元二次方程的根有三种可能的情况:
- 如果 Δ > 0 \Delta\gt0 Δ>0,则这个一元二次方程有两个不同的 实数 根。如果系数都为有理数,且 Δ \Delta Δ是一个完全平方数,则这两个根都是 有理数,否则这两个根都是 无理数。
- 如果 Δ = 0 \Delta=0 Δ=0,则这个一元二次方程有两个相等的实数根,而且这两个根皆为
x = − b 2 a x=-\frac{b}{2a} x=−2ab - 如果 Δ < 0 \Delta\lt0 Δ<0,则这个一元二次方差有两个不同的 复数根,且为 共轭复根。这时根为
x = − b 2 a + i 4 a c − b 2 2 a x = − b 2 a − i 4 a c − b 2 2 a x=\frac{-b}{2a}+i\frac{\sqrt{4ac-b^2}}{2a}\\\,\\ x=\frac{-b}{2a}-i\frac{\sqrt{4ac-b^2}}{2a} x=2a−b+i2a4ac−b2x=2a−b−i2a4ac−b2
其中 i 2 = − 1 i^2=-1 i2=−1
r o o t 1 = − b + b 2 − 4 a c 2 a r o o t 2 = − b − b 2 − 4 a c 2 a { d e t e r m i n a n t > 0 两个不同的实数根 r o o t 1 ≠ r o o t 2 \begin{matrix} root1=\frac{-b+\sqrt{b^2-4ac}}{2a}\\\,\\ root2=\frac{-b-\sqrt{b^2-4ac}}{2a} \end{matrix} \begin{cases} determinant\gt0 & \text{两个不同的实数根}\\ root1\ne root2 \end{cases} root1=2a−b+b2−4acroot2=2a−b−b2−4ac{determinant>0root1=root2两个不同的实数根
r o o t 1 = r o o t 2 = − b 2 a { d e t e r m i n a n t = 0 两个相同的实数根 r o o t 1 = r o o t 2 root1=root2=\frac{-b}{2a} \begin{cases} determinant=0 & \text{两个相同的实数根}\\ root1=root2 \end{cases} root1=root2=2a−b{determinant=0root1=root2两个相同的实数根
r o o t 1 = − b 2 a + i − ( b 2 − 4 a c ) 2 a r o o t 2 = − b 2 a − i − ( b 2 − 4 a c ) 2 a { d e t e r m i n a n t < 0 两个不同的复数根 r o o t 1 ≠ r o o t 2 \begin{matrix} root1=\frac{-b}{2a}+i\frac{\sqrt{-(b^2-4ac)}}{2a}\\\,\\ root2=\frac{-b}{2a}-i\frac{\sqrt{-(b^2-4ac)}}{2a} \end{matrix} \begin{cases} determinant\lt0 & \text{两个不同的复数根}\\ root1\ne root2 \end{cases} root1=2a−b+i2a−(b2−4ac)root2=2a−b−i2a−(b2−4ac){determinant<0root1=root2两个不同的复数根
#include 以上程序执行输出结果为:
输入 a, b 和 c: 4
5
1
实根不同:
x1 = -0.25
x2 = -1
C++ ASM
- Compiler Explorer - godbolt - C++ to ASM Online
- 汇编语言-wiki
- C++反汇编揭秘2 – VC编译器的运行时错误检查(RTC)
- Inline Assembler
- __asm
- 汇编语言指令大全
C++ 逆向反汇编
- 【精品】软件逆向之C++反汇编基础
1.1
一个一定要好好学一下
NASM
- NASM 在线文档
- NASM - The Netwide Assembler version 2.14.02.pdf -psw:is5t
- 该PDF我使用的是 PDF在线合并工具 导出的,非常方便
- PDF 工具
MARS - 更方便学习ASM的工具
MARS 官网
MARS (MIPS Assembler and Runtime Simulator)
MARS - youtube 视频教程
MIPS Assembly Programming Simplified
MARS 简单教程 / 功能
- MARS features.docs
- MARS Tutorail.docs
汇编入门(长文多图,流量慎入!!!)
汇编入门(长文多图,流量慎入!!!)
C++面试
面试题一般是市场需要的知识点。
可以根据需要来学习,会比较快速可投入项目。
-
C++ 面试知识点总结
-
c++面试
【腾讯内部工具分享】内存泄漏分析工具tMemoryMonitor
【腾讯内部工具分享】内存泄漏分析工具tMemoryMonitor
Refernces
-
https://en.cppreference.com/w/ - 在线学习C++极力推荐的网站,内容很全
-
http://www.cplusplus.com/
- c++ Beginners
-
Visual Studio 中的 C++
-
C/C++语言和标准库参考
-
C++标准库头文件
-
C++ Primer 第三版 中文版.pdf提取码:czse
-
C++ 教程