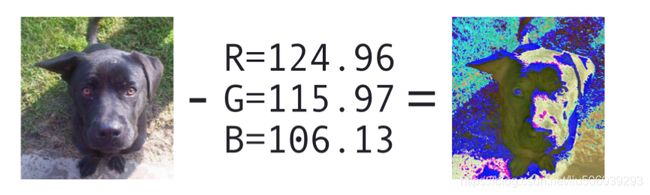- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- android系统selinux中添加新属性property
辉色投像
1.定位/android/system/sepolicy/private/property_contexts声明属性开头:persist.charge声明属性类型:u:object_r:system_prop:s0图12.定位到android/system/sepolicy/public/domain.te删除neverallow{domain-init}default_prop:property
- 【iOS】MVC设计模式
Magnetic_h
iosmvc设计模式objective-c学习ui
MVC前言如何设计一个程序的结构,这是一门专门的学问,叫做"架构模式"(architecturalpattern),属于编程的方法论。MVC模式就是架构模式的一种。它是Apple官方推荐的App开发架构,也是一般开发者最先遇到、最经典的架构。MVC各层controller层Controller/ViewController/VC(控制器)负责协调Model和View,处理大部分逻辑它将数据从Mod
- element实现动态路由+面包屑
软件技术NINI
vue案例vue.js前端
el-breadcrumb是ElementUI组件库中的一个面包屑导航组件,它用于显示当前页面的路径,帮助用户快速理解和导航到应用的各个部分。在Vue.js项目中,如果你已经安装了ElementUI,就可以很方便地使用el-breadcrumb组件。以下是一个基本的使用示例:安装ElementUI(如果你还没有安装的话):你可以通过npm或yarn来安装ElementUI。bash复制代码npmi
- C语言如何定义宏函数?
小九格物
c语言
在C语言中,宏函数是通过预处理器定义的,它在编译之前替换代码中的宏调用。宏函数可以模拟函数的行为,但它们不是真正的函数,因为它们在编译时不会进行类型检查,也不会分配存储空间。宏函数的定义通常使用#define指令,后面跟着宏的名称和参数列表,以及宏展开后的代码。宏函数的定义方式:1.基本宏函数:这是最简单的宏函数形式,它直接定义一个表达式。#defineSQUARE(x)((x)*(x))2.带参
- LocalDateTime 转 String
igotyback
java开发语言
importjava.time.LocalDateTime;importjava.time.format.DateTimeFormatter;publicclassMain{publicstaticvoidmain(String[]args){//获取当前时间LocalDateTimenow=LocalDateTime.now();//定义日期格式化器DateTimeFormatterformat
- ArcGIS栅格计算器常见公式(赋值、0和空值的转换、补充栅格空值)
研学随笔
arcgis经验分享
我们在使用ArcGIS时通常经常用到栅格计算器,今天主要给大家介绍我日常中经常用到的几个公式,供大家参考学习。将特定值(-9999)赋值为0,例如-9999.Con("raster"==-9999,0,"raster")2.给空值赋予特定的值(如0)Con(IsNull("raster"),0,"raster")3.将特定的栅格值(如1)赋值为空值,其他保留原值SetNull("raster"==
- 水平垂直居中的几种方法(总结)
LJ小番茄
CSS_玄学语言htmljavascript前端csscss3
1.使用flexbox的justify-content和align-items.parent{display:flex;justify-content:center;/*水平居中*/align-items:center;/*垂直居中*/height:100vh;/*需要指定高度*/}2.使用grid的place-items:center.parent{display:grid;place-item
- 每日一题——第八十九题
互联网打工人no1
C语言程序设计每日一练c语言
题目:在字符串中找到提取数字,并统计一共找到多少整数,a123xxyu23&8889,那么找到的整数为123,23,8889//思想:#include#include#includeintmain(){charstr[]="a123xxyu23&8889";intcount=0;intnum=0;//用于临时存放当前正在构建的整数。boolinNum=false;//用于标记当前是否正在读取一个整
- 每日一题——第九十题
互联网打工人no1
C语言程序设计每日一练c语言
题目:判断子串是否与主串匹配#include#include#include//////判断子串是否在主串中匹配//////主串///子串///boolisSubstring(constchar*str,constchar*substr){intlenstr=strlen(str);//计算主串的长度intlenSub=strlen(substr);//计算子串的长度//遍历主字符串,对每个可能得
- 每日一题——第八十一题
互联网打工人no1
C语言程序设计每日一练c语言
打印如下图案:#includeintmain(){inti,j;charch='A';for(i=1;i<5;i++,ch++){for(j=0;j<5-i;j++){printf("");//控制空格输出}for(j=1;j<2*i;j++)//条件j<2*i{printf("%c",ch);//控制字符输出}printf("\n");}return0;}
- 每日一题——第八十四题
互联网打工人no1
C语言程序设计每日一练c语言
题目:编写函数1、输入10个职工的姓名和职工号2、按照职工由大到小顺序排列,姓名顺序也随之调整3、要求输入一个职工号,用折半查找法找出该职工的姓名#define_CRT_SECURE_NO_WARNINGS#include#include#defineMAX_EMPLOYEES10typedefstruct{intid;charname[50];}Empolyee;voidinputEmploye
- 每日一题——第八十二题
互联网打工人no1
C语言程序设计每日一练c语言
题目:将一个控制台输入的字符串中的所有元音字母复制到另一字符串中#include#include#include#include#defineMAX_INPUT1024boolisVowel(charp);intmain(){charinput[MAX_INPUT];charoutput[MAX_INPUT];printf("请输入一串字符串:\n");fgets(input,sizeof(inp
- 每日一题——第八十三题
互联网打工人no1
C语言程序设计每日一练c语言
题目:将输入的整形数字输出,输出1990,输出"1990"#include#defineMAX_INPUT1024intmain(){intarrr_num[MAX_INPUT];intnum,i=0;printf("请输入一个数字:");scanf_s("%d",&num);while(num!=0){arrr_num[i++]=num%10;num/=10;}printf("\"");for(
- C#中使用split分割字符串
互联网打工人no1
c#
1、用字符串分隔:usingSystem.Text.RegularExpressions;stringstr="aaajsbbbjsccc";string[]sArray=Regex.Split(str,"js",RegexOptions.IgnoreCase);foreach(stringiinsArray)Response.Write(i.ToString()+"");输出结果:aaabbbc
- WPF中的ComboBox控件几种数据绑定的方式
互联网打工人no1
wpfc#
一、用字典给ItemsSource赋值(此绑定用的地方很多,建议熟练掌握)在XMAL中:在CS文件中privatevoidBindData(){DictionarydicItem=newDictionary();dicItem.add(1,"北京");dicItem.add(2,"上海");dicItem.add(3,"广州");cmb_list.ItemsSource=dicItem;cmb_l
- python os.environ
江湖偌大
python深度学习
os.environ['TF_CPP_MIN_LOG_LEVEL']='0'#默认值,输出所有信息os.environ['TF_CPP_MIN_LOG_LEVEL']='1'#屏蔽通知信息(INFO)os.environ['TF_CPP_MIN_LOG_LEVEL']='2'#屏蔽通知信息和警告信息(INFO\WARNING)os.environ['TF_CPP_MIN_LOG_LEVEL']='
- 腾讯云技术深度探索:构建高效云原生微服务架构
我的运维人生
云原生架构腾讯云运维开发技术共享
腾讯云技术深度探索:构建高效云原生微服务架构在当今快速发展的技术环境中,云原生技术已成为企业数字化转型的关键驱动力。腾讯云作为行业领先的云服务提供商,不断推出创新的产品和技术,助力企业构建高效、可扩展的云原生微服务架构。本文将深入探讨腾讯云在微服务领域的最新进展,并通过一个实际案例展示如何在腾讯云平台上构建云原生应用。腾讯云微服务架构概览腾讯云微服务架构基于云原生理念,旨在帮助企业快速实现应用的容
- Pyecharts数据可视化大屏:打造沉浸式数据分析体验
我的运维人生
信息可视化数据分析数据挖掘运维开发技术共享
Pyecharts数据可视化大屏:打造沉浸式数据分析体验在当今这个数据驱动的时代,如何将海量数据以直观、生动的方式展现出来,成为了数据分析师和企业决策者关注的焦点。Pyecharts,作为一款基于Python的开源数据可视化库,凭借其丰富的图表类型、灵活的配置选项以及高度的定制化能力,成为了构建数据可视化大屏的理想选择。本文将深入探讨如何利用Pyecharts打造数据可视化大屏,并通过实际代码案例
- 第四天旅游线路预览——从换乘中心到喀纳斯湖
陟彼高冈yu
基于Googleearthstudio的旅游规划和预览旅游
第四天:从贾登峪到喀纳斯风景区入口,晚上住宿贾登峪;换乘中心有4路车,喀纳斯①号车,去喀纳斯湖,路程时长约5分钟;将上面的的行程安排进行动态展示,具体步骤见”Googleearthstudio进行动态轨迹显示制作过程“、“Googleearthstudio入门教程”和“Googleearthstudio进阶教程“相关内容,得到行程如下所示:Day4-2-480p
- linux sdl windows.h,Windows下的SDL安装
奔跑吧linux内核
linuxsdlwindows.h
首先你要下载并安装SDL开发包。如果装在C盘下,路径为C:\SDL1.2.5如果在WINDOWS下。你可以按以下步骤:1.打开VC++,点击"Tools",Options2,点击directories选项3.选择"Includefiles"增加一个新的路径。"C:\SDL1.2.5\include"4,现在选择"Libaryfiles“增加"C:\SDL1.2.5\lib"现在你可以开始编写你的第
- Goolge earth studio 进阶4——路径修改与平滑
陟彼高冈yu
Googleearthstudio进阶教程旅游
如果我们希望在大约中途时获得更多的城市鸟瞰视角。可以将相机拖动到这里并创建一个新的关键帧。camera_target_clip_7EarthStudio会自动平滑我们的路径,所以当我们通过这个关键帧时,不是一个生硬的角度,而是一个平滑的曲线。camera_target_clip_8路径上有贝塞尔控制手柄,允许我们调整路径的形状。右键单击,我们可以选择“平滑路径”,这是默认的自动平滑算法,或者我们可
- Google earth studio 简介
陟彼高冈yu
旅游
GoogleEarthStudio是一个基于Web的动画工具,专为创作使用GoogleEarth数据的动画和视频而设计。它利用了GoogleEarth强大的三维地图和卫星影像数据库,使用户能够轻松地创建逼真的地球动画、航拍视频和动态地图可视化。网址为https://www.google.com/earth/studio/。GoogleEarthStudio是一个基于Web的动画工具,专为创作使用G
- python os.environ_python os.environ 读取和设置环境变量
weixin_39605414
pythonos.environ
>>>importos>>>os.environ.keys()['LC_NUMERIC','GOPATH','GOROOT','GOBIN','LESSOPEN','SSH_CLIENT','LOGNAME','USER','HOME','LC_PAPER','PATH','DISPLAY','LANG','TERM','SHELL','J2REDIR','LC_MONETARY','QT_QPA
- 将cmd中命令输出保存为txt文本文件
落难Coder
Windowscmdwindow
最近深度学习本地的训练中我们常常要在命令行中运行自己的代码,无可厚非,我们有必要保存我们的炼丹结果,但是复制命令行输出到txt是非常麻烦的,其实Windows下的命令行为我们提供了相应的操作。其基本的调用格式就是:运行指令>输出到的文件名称或者具体保存路径测试下,我打开cmd并且ping一下百度:pingwww.baidu.com>./data.txt看下相同目录下data.txt的输出:如果你再
- SQL Server_查询某一数据库中的所有表的内容
qq_42772833
SQLServer数据库sqlserver
1.查看所有表的表名要列出CrabFarmDB数据库中的所有表(名),可以使用以下SQL语句:USECrabFarmDB;--切换到目标数据库GOSELECTTABLE_NAMEFROMINFORMATION_SCHEMA.TABLESWHERETABLE_TYPE='BASETABLE';对这段SQL脚本的解释:SELECTTABLE_NAME:这个语句的作用是从查询结果中选择TABLE_NAM
- 四章-32-点要素的聚合
彩云飘过
本文基于腾讯课堂老胡的课《跟我学Openlayers--基础实例详解》做的学习笔记,使用的openlayers5.3.xapi。源码见1032.html,对应的官网示例https://openlayers.org/en/latest/examples/cluster.htmlhttps://openlayers.org/en/latest/examples/earthquake-clusters.
- 【华为OD机试真题2023B卷 JAVA&JS】We Are A Team
若博豆
java算法华为javascript
华为OD2023(B卷)机试题库全覆盖,刷题指南点这里WeAreATeam时间限制:1秒|内存限制:32768K|语言限制:不限题目描述:总共有n个人在机房,每个人有一个标号(1<=标号<=n),他们分成了多个团队,需要你根据收到的m条消息判定指定的两个人是否在一个团队中,具体的:1、消息构成为:abc,整数a、b分别代
- 使用Faiss进行高效相似度搜索
llzwxh888
faisspython
在现代AI应用中,快速和高效的相似度搜索是至关重要的。Faiss(FacebookAISimilaritySearch)是一个专门用于快速相似度搜索和聚类的库,特别适用于高维向量。本文将介绍如何使用Faiss来进行相似度搜索,并结合Python代码演示其基本用法。什么是Faiss?Faiss是一个由FacebookAIResearch团队开发的开源库,主要用于高维向量的相似性搜索和聚类。Faiss
- libyuv之linux编译
jaronho
Linuxlinux运维服务器
文章目录一、下载源码二、编译源码三、注意事项1、银河麒麟系统(aarch64)(1)解决armv8-a+dotprod+i8mm指令集支持问题(2)解决armv9-a+sve2指令集支持问题一、下载源码到GitHub网站下载https://github.com/lemenkov/libyuv源码,或者用直接用git克隆到本地,如:gitclonehttps://github.com/lemenko
- 矩阵求逆(JAVA)初等行变换
qiuwanchi
矩阵求逆(JAVA)
package gaodai.matrix;
import gaodai.determinant.DeterminantCalculation;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
/**
* 矩阵求逆(初等行变换)
* @author 邱万迟
*
- JDK timer
antlove
javajdkschedulecodetimer
1.java.util.Timer.schedule(TimerTask task, long delay):多长时间(毫秒)后执行任务
2.java.util.Timer.schedule(TimerTask task, Date time):设定某个时间执行任务
3.java.util.Timer.schedule(TimerTask task, long delay,longperiod
- JVM调优总结 -Xms -Xmx -Xmn -Xss
coder_xpf
jvm应用服务器
堆大小设置JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。
典型设置:
java -Xmx
- JDBC连接数据库
Array_06
jdbc
package Util;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class JDBCUtil {
//完
- Unsupported major.minor version 51.0(jdk版本错误)
oloz
java
java.lang.UnsupportedClassVersionError: cn/support/cache/CacheType : Unsupported major.minor version 51.0 (unable to load class cn.support.cache.CacheType)
at org.apache.catalina.loader.WebappClassL
- 用多个线程处理1个List集合
362217990
多线程threadlist集合
昨天发了一个提问,启动5个线程将一个List中的内容,然后将5个线程的内容拼接起来,由于时间比较急迫,自己就写了一个Demo,希望对菜鸟有参考意义。。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountDownLatch;
public c
- JSP简单访问数据库
香水浓
sqlmysqljsp
学习使用javaBean,代码很烂,仅为留个脚印
public class DBHelper {
private String driverName;
private String url;
private String user;
private String password;
private Connection connection;
privat
- Flex4中使用组件添加柱状图、饼状图等图表
AdyZhang
Flex
1.添加一个最简单的柱状图
? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
<?xml version=
"1.0"&n
- Android 5.0 - ProgressBar 进度条无法展示到按钮的前面
aijuans
android
在低于SDK < 21 的版本中,ProgressBar 可以展示到按钮前面,并且为之在按钮的中间,但是切换到android 5.0后进度条ProgressBar 展示顺序变化了,按钮再前面,ProgressBar 在后面了我的xml配置文件如下:
[html]
view plain
copy
<RelativeLa
- 查询汇总的sql
baalwolf
sql
select list.listname, list.createtime,listcount from dream_list as list , (select listid,count(listid) as listcount from dream_list_user group by listid order by count(
- Linux du命令和df命令区别
BigBird2012
linux
1,两者区别
du,disk usage,是通过搜索文件来计算每个文件的大小然后累加,du能看到的文件只是一些当前存在的,没有被删除的。他计算的大小就是当前他认为存在的所有文件大小的累加和。
- AngularJS中的$apply,用还是不用?
bijian1013
JavaScriptAngularJS$apply
在AngularJS开发中,何时应该调用$scope.$apply(),何时不应该调用。下面我们透彻地解释这个问题。
但是首先,让我们把$apply转换成一种简化的形式。
scope.$apply就像一个懒惰的工人。它需要按照命
- [Zookeeper学习笔记十]Zookeeper源代码分析之ClientCnxn数据序列化和反序列化
bit1129
zookeeper
ClientCnxn是Zookeeper客户端和Zookeeper服务器端进行通信和事件通知处理的主要类,它内部包含两个类,1. SendThread 2. EventThread, SendThread负责客户端和服务器端的数据通信,也包括事件信息的传输,EventThread主要在客户端回调注册的Watchers进行通知处理
ClientCnxn构造方法
&
- 【Java命令一】jmap
bit1129
Java命令
jmap命令的用法:
[hadoop@hadoop sbin]$ jmap
Usage:
jmap [option] <pid>
(to connect to running process)
jmap [option] <executable <core>
(to connect to a
- Apache 服务器安全防护及实战
ronin47
此文转自IBM.
Apache 服务简介
Web 服务器也称为 WWW 服务器或 HTTP 服务器 (HTTP Server),它是 Internet 上最常见也是使用最频繁的服务器之一,Web 服务器能够为用户提供网页浏览、论坛访问等等服务。
由于用户在通过 Web 浏览器访问信息资源的过程中,无须再关心一些技术性的细节,而且界面非常友好,因而 Web 在 Internet 上一推出就得到
- unity 3d实例化位置出现布置?
brotherlamp
unity教程unityunity资料unity视频unity自学
问:unity 3d实例化位置出现布置?
答:实例化的同时就可以指定被实例化的物体的位置,即 position
Instantiate (original : Object, position : Vector3, rotation : Quaternion) : Object
这样你不需要再用Transform.Position了,
如果你省略了第二个参数(
- 《重构,改善现有代码的设计》第八章 Duplicate Observed Data
bylijinnan
java重构
import java.awt.Color;
import java.awt.Container;
import java.awt.FlowLayout;
import java.awt.Label;
import java.awt.TextField;
import java.awt.event.FocusAdapter;
import java.awt.event.FocusE
- struts2更改struts.xml配置目录
chiangfai
struts.xml
struts2默认是读取classes目录下的配置文件,要更改配置文件目录,比如放在WEB-INF下,路径应该写成../struts.xml(非/WEB-INF/struts.xml)
web.xml文件修改如下:
<filter>
<filter-name>struts2</filter-name>
<filter-class&g
- redis做缓存时的一点优化
chenchao051
redishadooppipeline
最近集群上有个job,其中需要短时间内频繁访问缓存,大概7亿多次。我这边的缓存是使用redis来做的,问题就来了。
首先,redis中存的是普通kv,没有考虑使用hash等解结构,那么以为着这个job需要访问7亿多次redis,导致效率低,且出现很多redi
- mysql导出数据不输出标题行
daizj
mysql数据导出去掉第一行去掉标题
当想使用数据库中的某些数据,想将其导入到文件中,而想去掉第一行的标题是可以加上-N参数
如通过下面命令导出数据:
mysql -uuserName -ppasswd -hhost -Pport -Ddatabase -e " select * from tableName" > exportResult.txt
结果为:
studentid
- phpexcel导出excel表简单入门示例
dcj3sjt126com
PHPExcelphpexcel
先下载PHPEXCEL类文件,放在class目录下面,然后新建一个index.php文件,内容如下
<?php
error_reporting(E_ALL);
ini_set('display_errors', TRUE);
ini_set('display_startup_errors', TRUE);
if (PHP_SAPI == 'cli')
die('
- 爱情格言
dcj3sjt126com
格言
1) I love you not because of who you are, but because of who I am when I am with you. 我爱你,不是因为你是一个怎样的人,而是因为我喜欢与你在一起时的感觉。 2) No man or woman is worth your tears, and the one who is, won‘t
- 转 Activity 详解——Activity文档翻译
e200702084
androidUIsqlite配置管理网络应用
activity 展现在用户面前的经常是全屏窗口,你也可以将 activity 作为浮动窗口来使用(使用设置了 windowIsFloating 的主题),或者嵌入到其他的 activity (使用 ActivityGroup )中。 当用户离开 activity 时你可以在 onPause() 进行相应的操作 。更重要的是,用户做的任何改变都应该在该点上提交 ( 经常提交到 ContentPro
- win7安装MongoDB服务
geeksun
mongodb
1. 下载MongoDB的windows版本:mongodb-win32-x86_64-2008plus-ssl-3.0.4.zip,Linux版本也在这里下载,下载地址: http://www.mongodb.org/downloads
2. 解压MongoDB在D:\server\mongodb, 在D:\server\mongodb下创建d
- Javascript魔法方法:__defineGetter__,__defineSetter__
hongtoushizi
js
转载自: http://www.blackglory.me/javascript-magic-method-definegetter-definesetter/
在javascript的类中,可以用defineGetter和defineSetter_控制成员变量的Get和Set行为
例如,在一个图书类中,我们自动为Book加上书名符号:
function Book(name){
- 错误的日期格式可能导致走nginx proxy cache时不能进行304响应
jinnianshilongnian
cache
昨天在整合某些系统的nginx配置时,出现了当使用nginx cache时无法返回304响应的情况,出问题的响应头: Content-Type:text/html; charset=gb2312 Date:Mon, 05 Jan 2015 01:58:05 GMT Expires:Mon , 05 Jan 15 02:03:00 GMT Last-Modified:Mon, 05
- 数据源架构模式之行数据入口
home198979
PHP架构行数据入口
注:看不懂的请勿踩,此文章非针对java,java爱好者可直接略过。
一、概念
行数据入口(Row Data Gateway):充当数据源中单条记录入口的对象,每行一个实例。
二、简单实现行数据入口
为了方便理解,还是先简单实现:
<?php
/**
* 行数据入口类
*/
class OrderGateway {
/*定义元数
- Linux各个目录的作用及内容
pda158
linux脚本
1)根目录“/” 根目录位于目录结构的最顶层,用斜线(/)表示,类似于
Windows
操作系统的“C:\“,包含Fedora操作系统中所有的目录和文件。 2)/bin /bin 目录又称为二进制目录,包含了那些供系统管理员和普通用户使用的重要
linux命令的二进制映像。该目录存放的内容包括各种可执行文件,还有某些可执行文件的符号连接。常用的命令有:cp、d
- ubuntu12.04上编译openjdk7
ol_beta
HotSpotjvmjdkOpenJDK
获取源码
从openjdk代码仓库获取(比较慢)
安装mercurial Mercurial是一个版本管理工具。 sudo apt-get install mercurial
将以下内容添加到$HOME/.hgrc文件中,如果没有则自己创建一个: [extensions] forest=/home/lichengwu/hgforest-crew/forest.py fe
- 将数据库字段转换成设计文档所需的字段
vipbooks
设计模式工作正则表达式
哈哈,出差这么久终于回来了,回家的感觉真好!
PowerDesigner的物理数据库一出来,设计文档中要改的字段就多得不计其数,如果要把PowerDesigner中的字段一个个Copy到设计文档中,那将会是一件非常痛苦的事情。