C++入门到精通 ——第七章 STL标准模板库大局观
七、STL标准模板库大局观
Author: XFFer_
先分享一本 《C++ 标准库 第二版》 ,望在STL的道路上从入门到放弃!(开玩笑的啦,愈行愈远~)
链接: https://pan.baidu.com/s/1nna7m5F11poNNvEi2ydOyQ
提取码: otld
文章目录
- 七、STL标准模板库大局观
- 01 STL总述、发展史、组成,数据结构谈
- 几个概念
- 推荐书籍
- STL发展史和各个版本
- STL的组成部分
- 02 容器分类、array、vector容器精解
- 容器的分类
- 容器的说明
- array
- vector
- 03 容器的说明和简单应用例续
- deque和stack
- list:双向链表
- `vector` 和 `list`之间的差别
- 其他
- 04 分配器概述、使用,工作原理说
- 分配器概述&分配器的使用
- 05 迭代器的概念和分类
- 迭代器基本概念
- 迭代器的分类
- 族谱smirk.jpg
- 验证迭代器类型的代码
- 06 算法概述、内部处理、使用范例
- 算法概述
- 算法内部的一些处理
- 一些典型算法使用范例
- `for_each`
- 源码
- 使用方法
- `find`
- `find_if`
- `sort`
- 07 函数对象回顾、系统函数对象及范例
- 函数对象(function object)、仿函数回顾(functors)
- 标准库中定义的函数对象[functional](https://zh.cppreference.com/w/cpp/header/functional)->[第八章 未归类知识点](https://blog.csdn.net/qq_44455588/article/details/104474038)
- 标准库中定义的函数对象范例
- 08 适配器概念、分类、范例及总结
- 容器适配器
- 算法适配器
- 迭代器适配器
01 STL总述、发展史、组成,数据结构谈
1 几个概念
2 推荐书籍
3 算法和数据结构浅谈
4 STL发展史和各个版本
5 标准库的使用说明
6 STL的组成部分
几个概念
- C++标准库:C++ Standard Library
- 标准模板库:Standard Template Library(STL)
- 泛型编程:Generic Programming
推荐书籍


《STL源码剖析》
链接: https://pan.baidu.com/s/1apswforzS6dp5-3S05SKeA
提取码: gk0l
《C++标准库》
链接: https://pan.baidu.com/s/1nna7m5F11poNNvEi2ydOyQ
提取码: otld
STL发展史和各个版本
- HP STL: 惠普STL,是所有STL实现版本的始祖
- SGI STL: 参考惠普STL实现的,Linux下的GNU C++(gccc, g++)使用
- P.J.Plauger STL: Visual C++使用
STL的组成部分
- 容器: vector、list、map
- 迭代器: 用于遍历或者访问容器中的元素
- 算法: (函数),用来实现一些功能,search、sort、copy…
- 分配器
- 其他: 适配器、仿函数等
02 容器分类、array、vector容器精解
1 容器的分类
2 容器的说明
array
vector
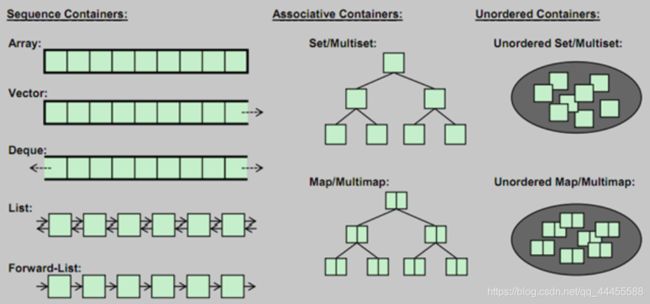
容器的分类
-
顺序容器(Sequence Container):能控制插入位置
arrayvectordequelistforward_list
-
关联容器(Associative Container):元素是 “键值对”,适合用来查找。能够控制插入内容,但不能控制插入位置
setmultisetmapmultimap
-
无序容器(Unordered Container):C++11推出,元素位置不重要,重要的是否存在该元素
unordered_setunordered_multisetunordered_mapunordered_multimap
容器的说明
array
内存空间是连续的,大小是固定的
使用形式: array 可以就当做数组来用。
vector
vector有一个“空间”的概念,容器内存是紧挨着的,故vector从末尾添加元素push_back时,如果容器空间不足就会重新寻找一个足够大的内存存放对象。
容器中有多少个元素可以用size()来看,有多少空间可以用capacity(), c a p a c i t y ≥ s i z e capacity\geq size capacity≥size。
vector基础知识在前面的章节有所提到。
当erase(iter)容器内部一个元素时,处理是比较高效的,其后的元素地址都会顺次移动,仍然是连续的内存。
当insert(iter, value)插入一个元素时,代价很大,会造成其后的元素重新构造,导致降低效率。
故可以使用reserve(size)提前留出空间capacity,可以大量提高程序的预留效率。
03 容器的说明和简单应用例续
1 deque和stack
2 queue
3 list
4 其他forward_list
set/map
unordered_set、unordered_multiset等
deque和stack
deque :双端数列(double-ended queue) ,分段连续内存,以分段数组的形式存储。
#include stack:堆栈/栈,只有一个开口,后进先出,后进会放在栈顶,先进会压在栈底,不支持从总结插入/删除数据。deque实际上是包含着stack的功能的。
queue :普通队列 先进先出
list:双向链表
不需要内存是连续的,查找效率不突出,但是在任意位置插入和删除元素非常迅速。
begin()/end()返回一个起始位置/末端下一个位置的iteratorpush_back()push_front()在末端/头部插入元素empty()判断是否为空resize()将list长度改为容纳n个元素clear()清空front()back()获取头部/末端元素,不能为空pop_front()pop_back()从头部/末端删除一个元素insert()插入一个或多个元素insert(iter, value)insert(iter, number_of_v, value)
erase()删除元素/区间内(用iter)元素
vector 和 list之间的差别
- vector类似于数组,内存空间是连续的,list双线链表,内存空间并不连续
- vector从中间或者开头插入元素效率比较低;但是list插入元素效率非常高
- vector当内存不足时,会重新找一块内存,对原来的内存对象做析构,再在新的内存重新构造
- vector能够高效的随机存取,而list做不到。vector可以通过迭代器,而list需要沿着链表一个个找,直到找到所需的元素
这里vector的细节知识可以参考C++中list用法详解,本文只是简单的总述STL标准库。
其他
forward_list:单向链表(受限list)set / map:关联容器。内部实现的数据结构多为红黑树。这些容器没有push_front/back的操作,因为内存并不是规律的- 常用操作↓
#include
#include 快捷键补充
shift+Home 取光标前本行内容
shift+End 取光标后本行内容
04 分配器概述、使用,工作原理说
1 分配器概述
2 分配器的使用
3 其他的分配器及原理说
4 自定义分配器
这节很水smirk~,因为我菜所以没有去详细了解分配器
分配器概述&分配器的使用
内存分配器,通过测试没有采用内存池的技术
allocate(num)是分配器内的重要函数,用来分配内存,这里的num值几个对象而不是字节数deallocate(point, num)用于释放函数,point是指向分配内存的指针
↓图为侯捷老师讲授分配器时使用过的
这里可以参考学习资料集聚地—小破站侯捷老师的STL源码剖析。
05 迭代器的概念和分类
1 迭代器基本概念
2 迭代器的分类
迭代器基本概念
迭代器用来表现容器中的某一个位置,紧密依赖于容器,是一个“可遍历STL容器全部或部分内容”的对象(行为类似于指针)。
//示例
vector<int> v = {1, 2, 3};
for (auto iter = v.begin(); iter != v.end(); iter++)
{
cout << *iter << endl;
}
迭代器的分类
分类的依据:迭代器的移动特性,与内存的连续性也有关。
部分容器是没有提供迭代器的stack、queue,因为它们遵循后进先出和先进先出的规则。
- 输出型迭代器: (Output iterator)
struct output_iterator_tag;- 能力: 向前写入
- 提供者: ostream 、inserter
*iter = val将val写☞迭代器所指位置++iter向前步进,返回新位置iter++向前步进,返回旧位置TYPE(iter)复制迭代器(copy构造函数)
- 输入型迭代器: (Input iterator)
struct input_iterator_tag;- 能力: 向前读取一次
- 提供者: Istream
*iter读取实际元素iter -> member读取实际元素的成员++iter向前步进,返回新位置iter++向前步进,返回旧位置iter1 == iter2判断是否相等iter1 != iter2判断是否不等TYPE(iter)复制迭代器(copy构造函数)
- 前向迭代器: (Forward iterator)
struct forward_iterator_tag;继承自输入型迭代器- 能力: 向前读取
- 提供者: Forward list、 unordered containers
- 继承输入迭代器所有操作
iter1 == iter2对迭代器赋值(assign)
- 双向迭代器: (Bidirectional iterator)
struct bidirectional_iterator_tag;继承自前向迭代器- 能力: 向前和向后读取
- 提供者: list 、set、 multiset 、map、 multimap
--iter步退,返回新位置iter--步退,返回旧位置
- 随机访问迭代器: (random-access iterator)
struct random_access_iterator_tag;继承自双向迭代器- 能力: 以随机访问方式读取
- 提供者: Array、 vector 、deque 、string 、C-style array
- 增加了随机访问能力,可以计算距离增减某个偏移量(内存是连续的)
iter[n]返回索引位置为n的元素iter+=n前进n个元素iter-=n回退n个元素iter+n返回iter之后的第n个元素n+iter返回iter之后的第n个元素iter-n返回iter之前的第n个元素iter1-iter2返回iter1和iter2之间的距离iter1iter1>iter2判断iter1是否在iter2之后iter1<=iter2判断iter1是否不在iter2之后iter1>=iter2判断iter1是否不在iter2之前
族谱smirk.jpg
验证迭代器类型的代码
void _display_category(random_access_iterator_tag mytag)
{
cout << "random_access_iterator_tag" << endl;
}
void _display_category(bidirectional_iterator_tag mytag)
{
cout << "bidirectional_iterator_tag" << endl;
}
void _display_category(forward_iterator_tag mytag)
{
cout << "forward_iterator_tag " << endl;
}
void _display_category(forward_iterator_tag mytag)
{
cout << "forward_iterator_tag " << endl;
}
void _display_category(output_iterator_tag mytag)
{
cout << "output_iterator_tag " << endl;
}
void _display_category(input_iterator_tag mytag)
{
cout << "input_iterator_tag " << endl;
}
template<typename T>
void display_category(T ite) {
cout << "----------begin----------" << endl;
//整个这个类型叫 过滤器(萃取机),用来获取T迭代器类型的种类
typename iterator_traits<T>::iterator_category cagy;
_display_category(cagy); //编译器挑选一个适合的重载函数,cagy就是迭代器的种类
cout << "typeid(ite).name() = " << typeid(ite).name() << endl;
cout << "----------end----------" << endl;
}
display_category(vector<int>::iterator()); //这样就OK了
06 算法概述、内部处理、使用范例
1 算法概述
2 算法内部一些处理
3 一些典型的算法使用范例for_each
find
find_if
sort
算法概述
函数模板(全局函数/全局函数模板)写成的,比如:查找、排序等。一般情况下,前两个参数一般都是迭代器类型,前闭后开[ , )。
算法这种泛型编程方式,增加灵活性,但是缺失了直观性,和某些数据结构兼容性并不好。
算法内部的一些处理
算法会根据传递进来的迭代器来分析出迭代器种类,不同种类的迭代器,算法会有不同的处理。
一些典型算法使用范例
#include for_each
源码
template<class _InIt,
class _Fn> inline
_Fn for_each(_InIt _First, _InIt _Last, _Fn _Func)
{ // perform function for each element [_First, _Last)
_DEBUG_RANGE(_First, _Last);
auto _UFirst = _Unchecked(_First);
const auto _ULast = _Unchecked(_Last);
for (; _UFirst != _ULast; ++_UFirst)
{
_Func(*_UFirst);
}
return (_Func);
}
通过源码可以清晰的看出for_each有三个参数,前两个参数用来确定一个迭代区间,第三个参数则是操作方式,lambda,函数对象或者普通函数。
使用方法
void func(int i)
{
cout << i << endl;
}
int main()
{
vector<int> myvector = { 10, 20, 30, 40, 50 };
for_each(myvector.begin(), myvector.end(), func);
//for_each每次迭代对象将得到的值调用第三个参数的函数
return 0;
}
find
这里使用的是泛化模板的find,当容器有特有的.find成员时,建议使用特有的效率更高。返回值都是 iterator。
vector<int> myvector = { 10, 20, 30, 40, 50 };
vector<int>::iterator finditer = find(myvector.begin(), myvector.end(), 400);
if (finditer != myvector.end()) //!=后的使用第二个参数
{
//find it!
}
else
{
//can not find
}
find_if
前两个参数确定一个查找区间,第三个参数返回值是一个bool。
auto result = (myvector.begin(), myvector.end(), [](int vel){
if (val > 10)
return true; //停止遍历
return false;
}); //lambda表达式也是一个可调用对象
if (result != myvector.end())
cout << "找到了" << endl;
else
cout << "没找到" << endl;
sort
当第三个参数缺省时,从小到大排序,第三个参数返回值是bool。
bool func(int i, int j)
{
return i < j;
}
auto result = sort(myvector.begin(), myvector.end(), func); //从小到大
bool func(int i, int j)
{
return i > j;
}
auto result = sort(myvector.begin(), myvector.end(), func); //从大到小
对list而言不能用标准库的sort(),它有自己的sort(),参数表传入返回值bool的比较规则。
07 函数对象回顾、系统函数对象及范例
1 函数对象、仿函数回顾
2 标准库中定义的函数对象
3 标准库中定义的函数对象范例
函数对象(function object)、仿函数回顾(functors)
- 函数:
void func(...) { ... } - 可调用对象:
class A { void operator() (...) { ... } }; - lambda表达式 :
[](...) { ... };
标准库中定义的函数对象functional->第八章 未归类知识点
#include 
标准库中定义的函数对象范例
vector<int> myvector = { 150, 20, 3, 98, 50 };
auto result = sort(myvector.begin(), myvector.end(), greater<int>()); //从大到小
greater就是一个仿函数。
08 适配器概念、分类、范例及总结
1 适配器基本概念
2 容器适配器
3 算法适配器
4 迭代器适配器
容器适配器
适配器像一个转接口。

主要讲一下:(它俩都是deque的阉割版)
stack:堆栈queue:队列
实际上在这里我们就把它们看做适配器而不是容器。
算法适配器
std::bind 绑定器(第八章 未归类知识点)
vector<int> myvector = { 150, 20, 3, 20, 50 };
bool func(int tmp)
{
return tmp > 40;
}
int result = count(myvector.begin(), myvector.end(), 20); //return 2
int result = count_if(myvector.begin(),myvector.end(), func); //return 2
如果想用less这个仿函数代替掉自己写的func,就需要用到bind绑定器。
auto contrast = bind(less<int>(), 40, placeholders::_1)
//less()第一个参数绑定为40, 第二个参数是在被调用时传入的第一个参数
int result = count_if(myvector.begin(), myvector.end(), contrast);
迭代器适配器
reverse_iterator 在这里归为适配器
前文已经提到。