prometheus - node_exporter - CPU利用率(入门基础)
node_exporter - CPU
- 一、获取 各种状态 CPU 的使用率
- 二、所用函数
- 1、increase({}[time]) 增量函数
- 2、sum() 叠加函数
- 3、by () 拆分函数
- 二、计算 CPU 每分钟的 使用率
- 思路、步骤如下
- 1.计算CPU的使用时间
- 2.取一分钟之内的使用增量
- 3.因为CPU核心数太多,所以进一步将多核CPU进行合并为一个整体
- 4.每个节点的CPU 1分钟内的使用增量
- 5.根据使用增量,计算CPU每分钟利用率
- 6. 完整公式
- 三、举一反三、统计 CPU 其他状态的 每分钟利用率
- 1.计算 CPU-system 每分钟使用率
- 2.计算 CPU-user 每分钟利用率
- 3.计算 idle(空闲)CPU 每分钟占多少利用率
一、获取 各种状态 CPU 的使用率
状态有:
- 所有CPU状态下,每分钟的使用率
- system下,每分钟的使用率
- user下,每分钟的使用率
- idle下,每分钟的使用率
[root@k8s-node1 ~]# curl localhost:9100/metrics | grep -i node_cpu 获取到CPU所有的标签
# TYPE node_cpu_guest_seconds_total counter #虚拟机的虚拟CPU不用管
node_cpu_guest_seconds_total{cpu="0",mode="nice"} 0
node_cpu_guest_seconds_total{cpu="0",mode="user"} 0
node_cpu_guest_seconds_total{cpu="1",mode="nice"} 0
node_cpu_guest_seconds_total{cpu="1",mode="user"} 0
# HELP node_cpu_seconds_total Seconds the cpus spent in each mode.
# TYPE node_cpu_seconds_total counter #当前主机的CPU,0,1两核
node_cpu_seconds_total{cpu="0",mode="idle"} 5347.26 #CPU0 的 空闲CPU
node_cpu_seconds_total{cpu="0",mode="iowait"} 12.29 #CPU0 的 io使用量
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 0.47
node_cpu_seconds_total{cpu="0",mode="softirq"} 2.89 #CPU0 的 中断请求
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 59.93 #CPU0 的 系统使用量
node_cpu_seconds_total{cpu="0",mode="user"} 29.78 #CPU0 的 用户使用量
node_cpu_seconds_total{cpu="1",mode="idle"} 5341.86
node_cpu_seconds_total{cpu="1",mode="iowait"} 12.94 #CPU1 同理
node_cpu_seconds_total{cpu="1",mode="irq"} 0
node_cpu_seconds_total{cpu="1",mode="nice"} 0.47
node_cpu_seconds_total{cpu="1",mode="softirq"} 2.7
node_cpu_seconds_total{cpu="1",mode="steal"} 0
node_cpu_seconds_total{cpu="1",mode="system"} 60.49
node_cpu_seconds_total{cpu="1",mode="user"} 33.22此处显示的是 node_exporter 针对 CPU 使用情况的所有 key/value 数据。
对 CPU 使用情况进行统计,就是从这些CPU 的 key 当中进行计算,提取,形成统计图。
二、所用函数
1、increase({}[time]) 增量函数
在prometheus 中,用来针对 Counter 这种持续增长的数值,截取其中一段时间的增量。配合时间使用
increase(node_cpu_seconds_total[1m]) 获取了CPU总使用时间在1分钟之内的增量
2、sum() 叠加函数
可以将所有的内容进行合并
3、by () 拆分函数
by( ) 这个函数可以把 sum 合并到一起的数值,按照指定的方式进行拆分。( ) 内 填写它指定的方式
在当前案例,需要按照集群节点进行拆分。所以采用 instance=“机器名”,by(instance)。
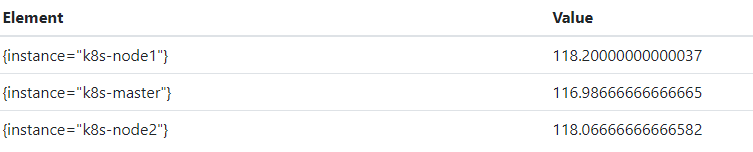
二、计算 CPU 每分钟的 使用率
思路、步骤如下
1.计算CPU的使用时间
空闲CPU使用时间 = node_cpu_seconds_total{mode=“idle”}
CPU总共使用时间 = node_cpu_seconds_total)
2.取一分钟之内的使用增量
空闲CPU一分钟内的增量:increase(node_cpu_seconds_total{mode=“idle”}[1m])
全部CPU一分钟内的增量:increase(node_cpu_seconds_total**[1m]**)
3.因为CPU核心数太多,所以进一步将多核CPU进行合并为一个整体
集群所有主机空闲CPU一分钟内的增量:sum(increase(node_cpu_seconds_total{mode=“idle”}[1m]))
集群所有主机CPU全部使用情况一分钟内的增量:sum(increase(node_cpu_seconds_total[1m]))
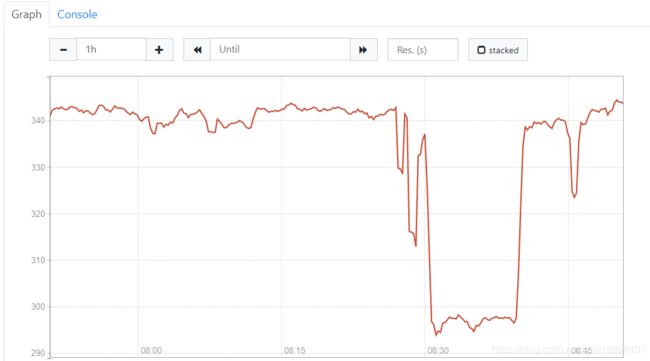
问题:这个CPU监控 采集的是多台服务器的监控数据,怎么但是到了这一步变成了一条线。
原因:因为有sum()函数,默认情况下不管什么内容全部都会进行合并。不光是CPU的核心数,同时把机器也进行合并了。 此时计算的
解决:采用 by()函数,按照主机节点进行拆分,by(instance)
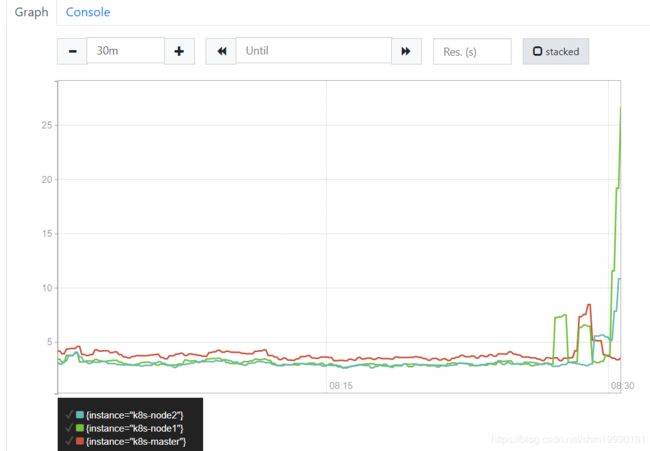
4.每个节点的CPU 1分钟内的使用增量
集群所有节点空闲CPU使用增量:sum(increase(node_cpu_seconds_total{mode=“idle”}[1m])) by(instance)
集群所有节点全部状态CPU使用增量:sum(increase(node_cpu_seconds_total[1m]))by(instance)
5.根据使用增量,计算CPU每分钟利用率
公式:节点非空闲CPU每分钟的增量 / 节点全部状态下CPU每分钟的增量 * 100= CPU每分钟的利用率
节点非空闲CPU每分钟增量 = 1 - 节点空闲CPU每分钟增量
1 - (sum(increase(node_cpu_seconds_total{mode=“idle”}[1m])) by(instance))
6. 完整公式
(1-(sum(increase(node_cpu_seconds_total{mode=“idle”}[1m]))by(instance)) / (sum(increase(node_cpu_seconds_total[1m]))by(instance))) *100

三、举一反三、统计 CPU 其他状态的 每分钟利用率
1.计算 CPU-system 每分钟使用率
(sum(increase(node_cpu_seconds_total{mode='system'}[1m]))by(instance)) / (sum(increase(node_cpu_seconds_total[1m]))by(instance)) *100
2.计算 CPU-user 每分钟利用率
(sum(increase(node_cpu_seconds_total{mode='user'}[1m]))by(instance)) / (sum(increase(node_cpu_seconds_total[1m]))by(instance)) *100
3.计算 idle(空闲)CPU 每分钟占多少利用率
(sum(increase(node_cpu_seconds_total{mode='idle'}[1m]))by(instance)) / (sum(increase(node_cpu_seconds_total[1m]))by(instance)) *100