郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Abstract
我们提出了一种基于情绪的分层强化学习(HRL)算法,用于具有多种奖励来源的环境。该系统的架构受到大脑神经生物学的启发,特别是负责情绪,决策和行为执行的区域,分别是杏仁核,眶额皮质和基底神经节。学习问题根据奖励的来源而分解。奖励源用作给定子任务的目标。为每个子任务分配了一个人工情绪指示(AEI),该AEI可预测与该子任务相关的奖励成分。同时学习AEI和顶层策略,并在AEI发生重大变化时中断子任务的执行。该算法在具有两个奖励来源且部分可观察的模拟网格世界中进行了测试。在相同的学习条件下,将基于情绪的算法与其他HRL算法进行了比较。与人为设计的策略和MAXQ算法的受限形式相比,使用受生物学启发的结构可显著加快学习过程并获得更高的长期奖励。
1 Introduction
通过将强化学习问题分解为子任务的层次结构,可以加快学习过程,并且可以在层次结构级别之间共享子任务策略[1,2]。但是,许多HRL算法在很大程度上依赖于人类的知识和经验来提供层次结构并标识子任务模块。层次结构和子任务模块通常是针对特定问题而设计的,智能体必须在学习和应用过程中对它们做出不可撤销的承诺。正在进行一些研究,例如[3],以识别适当的层次结构,作为学习过程的一部分。在大多数HRL算法中,奖励信号被视为来自单一来源。如果奖励来源出现或被删除,则策略需要进行进一步的学习迭代以适应变化[4]。相反,我们提出HRL系统应明确识别奖励结构的变化,并且仅在遇到新的奖励来源时才需要重新学习。动物很好地解决了这个问题。如果动物在不同的环境中分别学习三项任务,例如进食,饮水和逃逸(每个环境只有一个对应的目标)。当将动物放置在新环境中且所有三个奖励来源都存在时,几乎可以立即将适当的行为与相应的奖励来源相关联。此外,这些目标的优先级可能会根据内部状态(例如能量水平)随时间而变化。众所周知,情绪在灵活且适应性行为中起着重要的作用[5]。情绪是激励和优先考虑的事情。因此,通过权衡不同的目标和情况,情绪为动物提供了在不确定环境中应对多个目标的重要能力[5]。最近,大量生物学证据表明,大脑区域,如杏仁核,眶额皮质(OFC),基底神经节(BG)和多巴胺神经元参与了目标定向行为的情绪/动机控制[5,6]。
受神经生物学启发,Zhou and Coggins[7]最近提出了一种基于情绪的分层强化学习算法。本文将这项工作扩展如下。与[7]相比,已对实验进行了修改,以为所有算法提供相同的状态抽象,从而为所提出方法的优势提供了额外的证据,并能够进行更详细的性能比较和分析。本文的结构如下。第2节简要概述了涉及情绪处理和响应的大脑区域的系统级函数。第3节介绍了我们受到生物学启发的模型。在[7]中找到更详细的理由。在第4节中,介绍了模型的实现和实验结果。第五节是结论。
2 Biological Background and Guidance
杏仁核是大脑前部的皮层下区域,被认为是感觉/情绪联系的中心,包括恐惧,危险和满足感,以及其他动机和情绪感觉[8]。杏仁核的基底外侧核(BLA)主要从皮质感觉处理区域接收高度处理的信息,并被认为参与了感觉信号的情绪意义评估。信息通过杏仁核内部连接进行处理,并传递到杏仁核(CeA)的中央核,该核是与电机系统的接口,并参与仪器响应。与杏仁核紧密合作,眶额皮质(OFC)参与决策和适应性响应选择[5]。假设BLA编码信号的情绪意义,并且OFC在选择适当的行为策略时使用此信息[5]。已知BG与基于强化学习的感觉运动控制有关[9]。因此,通过额纹预测,BG为情绪和动机处理提供了重要的信息处理和行为执行系统之一[5]。中脑多巴胺神经元对OFC,BG和杏仁核有不同的预测,这些预测似乎以预测误差的形式报告了重要事件[6]。
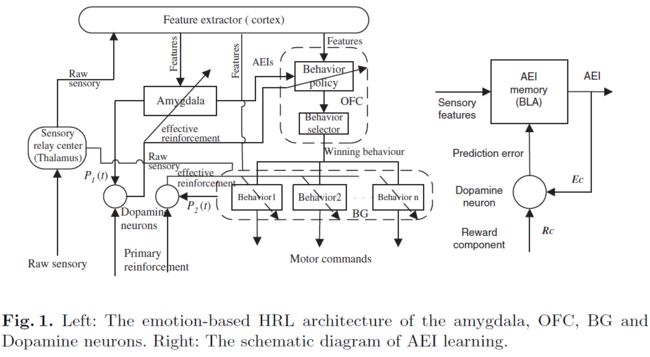
备注:Sensor relay center(Thalamus): 感官中继中心(丘脑); cortex: 皮层; Amygdata(CeA): 杏仁体; OFC: 眶额皮质; BLA: 杏仁核的基底外侧核; BG: 基底神经节
3 The Biologically Inspired Model
在上述相关大脑区域的神经生物学的指导下,一种基于情绪的分层强化学习算法被提出,用于奖励问题的多种来源[7]。图1显示了所提出结构的示意图。原始的感觉输入通过丘脑(大脑中的感觉传递中心)传递到皮层。在皮质区域中提取了高级特征,并投影到了杏仁核和OFC。OFC,杏仁核,BG和多巴胺神经元构成了多层的分层强化学习系统。OFC在最高层上做出抽象决定,即从成分行为替代方案中进行选择以最大化总体奖励。BG位于执行所选行为的最底层。该结构专注于由一组奖励成分定义的多任务问题。根据奖励的来源将整个任务分解。每个奖励成分都用作定义子任务的子目标。每个子任务都追求相应的子目标。我们假设可以通过奖励成分或其他属性(例如颜色,色调)的值来区分每种奖励来源。通常,必须学习此分类。子任务的目的是使相应的奖励成分最大化。最后,每个子任务都有助于最大化整个任务的累积奖励。我们为每个子任务分配一个AEI。AEI近似于BLA中的情绪表示,并被定义为与子任务相对应的奖励成分的预测。BLA学习并维持高级感官特征与AEI的关联。可以通过时序差分(TD)的方法[10]使用经典条件,同时学习AEI和OFC。我们修改了经典条件的TD版本,以便可以将其与状态转换所用的时间量可变的状态抽象一起使用。图1(右侧)显示了AEI学习过程。BLA会在每个时间步骤将感官特征映射到AEI中。根据多巴胺神经元提供的AEI预测误差更新BLA记忆。令xc和x'c分别为对应于给定AEI的当前和下一特征状态,其中n表示从状态xc到x'c的原始时间步骤;下标c索引直接对应于子任务的情绪类别以及该子任务的相关单一奖励来源。然后,AEI值Vc表示为折扣未来奖励成分价值的期望总和,由下式给出:
![]()
其中Vc(xc)是时间 t 的特征状态xc的AEI值,γc是一个折扣因子,说明未来奖励的AEI值逐渐减小,rc,t是在时间 t 所获得的奖励成分c的收益,E是期望算子。
由等式(1)给出的AEI预测值可以分为两部分,其中之一是在从xc到x'c的转换期内,奖励成分的折扣累积收益,而另一部分是状态转换后折扣未来奖励成分价值的新期望总和。实际上,第二部分是时间(t + n)中下一状态x'c的AEI预测值,由下式给出:
![]()
因此,令vc,t表示从xc到x'c的转换期间收到的奖励成分C的累积收益,由下式给出:

等式(1)可以重写为下式:
![]()
因此,每个状态下的期望AEI值等于在下一状态中收到的奖励成分的累积收益加上折扣为![]() 的下一期望AEI值。期望价值与预测价值之差是预测误差δc,t,这由下式给出:
的下一期望AEI值。期望价值与预测价值之差是预测误差δc,t,这由下式给出:
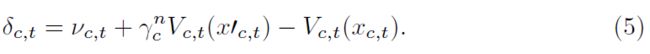
使用资格迹,通过以下方式更新AEI值:
![]()
其中,αc是学习率,而ec(xc)是资格迹,它是奖励对特征空间的追溯效应的基础。资格迹根据下式更新:
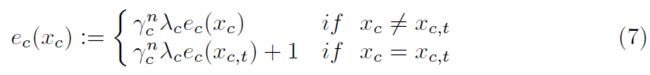
其中λc是资格迹的衰减率,xc是AEI的所有状态,而xc,t是当前状态。
这些AEI构成了基于子任务的价值函数分解。可以将AEI视为相应子任务的价值估计。AEI彼此独立。AEI将感官输入汇总到特定于子任务的变量中,这些变量根据智能体的影响(奖励或惩罚)向智能体提供对环境的选择性感知。因此,AEI构成了智能体的人工情绪状态,并被提出作为OFC和CeA的状态抽象。此外,作为子任务的价值估计,人工情绪状态充当OFC中当前正在执行的子策略的中断触发机制。当人工情绪状态发生显著变化时,OFC重新评估当前的子策略,以决定是否继续执行或选择另一个策略。我们认为,OFC,CeA和多巴胺神经元可以作为时序差分强化学习系统协同工作。OFC充当将状态空间映射到子策略空间的执行者。CeA是为多巴胺神经元提供强化预测P1(t)的评论者。使用强化预测和收到的主要强化r(t),多巴胺神经元计算有效强化(时序误差)。基于有效的强化,CeA和OFC的突触强度得到更新。这是一个半马尔可夫决策过程(SMDP),其中动作需要花费可变的时间量才能完成。可以使用SMDP版本的一步Q学习[2,11]来学习OFC策略。在观察状态s,执行子任务o,终止子任务,观察下一状态s'之后,OFC用于仲裁子任务策略的动作价值函数根据下式给出:
![]()
其中k是子任务o期间经过的时间步骤数,γQ是折扣因子,r是子任务执行期间收到的累积奖励。在BG中,我们将子任务建模为单独的强化学习系统。同样,BG的感觉运动纹状体和边缘纹状体可以分别建模为执行者和评论者[9]。边缘纹状体向计算有效强化的多巴胺神经元提供强化预测P2(t)。感觉运动和边缘纹状体的突触强度使用有效的强化来更新。在本文中,我们假设已经在BG中学习了子任务。
4 Experiments
为了测试提出的受生物启发的HRL结构,我们开发了一个模拟的gridworld环境,其中包含与多个同时的行为目标相对应的多种奖励来源。我们展示了人工情绪机制如何在现有策略的组合中发挥作用而无需修改它们。
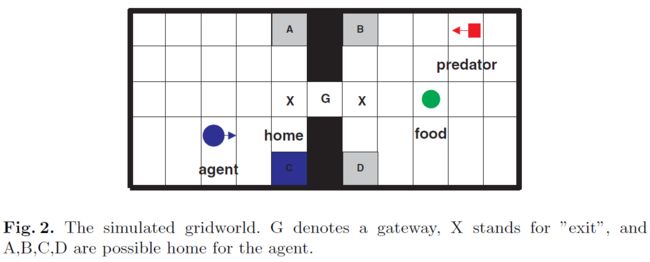
4.1 Experimental Environment
网格世界中有两个房间,它们通过出入口连接起来,如图2所示。应该有一个智能体住在其中,寻找食物,吃食物并逃脱食肉动物。该智能体有6个动作:向东,向南,向西和向北移动,咀嚼食物和无所事事。如果智能体试图穿过墙壁,则该动作无效。每个动作步骤的成本为-0.1。为了使实验变得现实,我们将噪声引入到智能体行为和捕食者行为中。智能体有80%的机会采取预期的动作,而有20%的机会采取随机动作。智能体只能访问有关当前房间的信息。智能体在出入口G上收到指示,所有感官信息都切换到另一个房间。智能体在每个房间中可获得的感官信息是智能体自身的坐标,食物和捕食者的坐标(如果存在)以及家的坐标。食物随机分布在两个房间中。在任何给定时间只有一种食物。智能体花费10个时间步骤咀嚼一块食物以获得价值为10的奖励。吃完食物后,另一块食物随机出现在某处。智能体的家位于A,B,C或D位置之一。捕食者会以至少15步的周期定期出现。在每个步骤中,能够以20%的概率将周期增加一个单位。捕食者总是和食物在同一个房间,并从侧面出发,与食物在同一行的概率为80%,在随机行的概率为20%。捕食者可以移动到房间内除智能体的家外的任何地方。捕食者有四个动作,每步都会向东,南,西,北移动一步,并具有以下概率:

其中i = 1, 2, 3, 4分别表示东,南,西和北,Pi = exp(Di / T)是沿第 i 个方向移动的趋势强度;T是温度;Di = DM cosθi,是智能体与捕食者之间的距离在相应方向上的投影;DM是智能体与捕食者之间的曼哈顿距离,θ是运动方向与从捕食者到智能体的方向之间的夹角。当捕食者抓获智能体时(他们的位置重合),智能体死亡并获得价值为-100的奖励。当两个奖励来源同时存在时,选择奖励幅度的不对称分布是为了将一个目标优先于另一个目标,从而奖励适应不断变化的优先级的行为。
假设有两个现有的单独子任务分层策略:进食和逃逸(请参见图2的右侧)。可以使用MAXQ[1]分别学习它们,并去除其他奖励来源和相应的状态变量。实验性任务是如何通过添加用于在这些子任务之间进行仲裁的最高节点来组合这两个单独的现有策略,以最大程度地从环境中获得全部奖励。


4.2 Subtask Combination
首先,我们尝试在两个任务之上简单地添加一个节点。我们称其为简单组合算法(SCA)。根据等式8,使用SMDP的Q-learning来学习顶层策略。状态抽象如表1所示。学习率设置为0.2,γQ = 0.9。我们使用Boltzmann探索,初始温度T = 50,冷却率μ = 0.995。子任务终止后,温度以T := μT更新。在第4.4节中描述了如何选择这些学习参数设置。学习性能如图4所示。学习收敛到价值为-0.1的奖励,智能体可以通过不执行任何动作来获得奖励。这是因为在执行子任务期间不会中断。例如,进食任务的选择具有在进食过程中被捕食者捕获的风险。因此,在大多数状态,进食都被大力劝阻。
为了提高性能,我们修改了子任务策略以允许其在执行期间中断。我们将其称为修正组合算法(modified combination algorithm, MCA)。在进食策略的层次结构中,当智能体可以看到掠食者时,允许所有子策略终止。同样,逃逸策略层次结构中的所有子任务策略都被修改为在捕食者看不见时终止。使用与SCA相同的状态抽象和学习参数时,MCA的性能明显更好(见图4)。但是,修改子任务策略层次结构有两个主要缺点。首先,修改每个子任务策略是一项非常困难的工作,尤其是对于在复杂且不确定的环境中的子任务的多层层次结构而言。另一个问题是终止条件在不同情况下可能会发生变化。这种方法不灵活,因为它依赖于先验知识。

4.3 The Emotion Based Algorithm
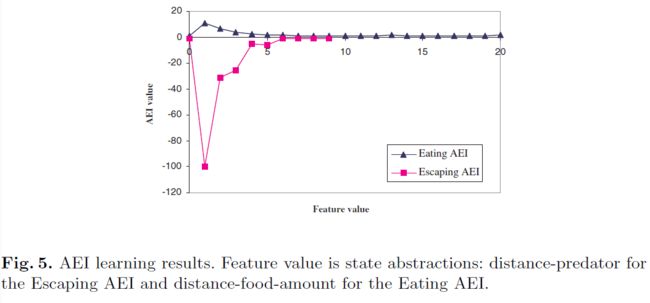
为了解决这个问题,我们使用了第3节中描述的基于情绪的分层强化学习结构。我们假设在BG中已经学习了子任务策略。子任务层次结构保持不变,并且为每个子任务分配了AEI。我们称其为基于情绪的组合算法(ECA)。AEI是通过根据等式(5)和(6)同时使用顶层策略的经验来学习的。进食AEI所依赖的特征是表2中所示的状态抽象。AEI被初始化为较小的任意值。在实验中,进食和逃逸AEI都使用相同的学习设置:αC = 0.25,γC = 0.9,λC = 0.7。图5显示了对顶层策略的学习完成后,进食和逃逸AEI的学习结果。特征值为1时,AEI的量最高。然后,它们随着距离的增加呈指数下降。

当人工情绪状态(一组AEI)发生显著变化时,子任务将中断,并且顶层将重新评估以继续执行该任务或选择另一个任务。使用欧式距离判断人工情绪状态的显著变化。在实验中,将AEI的向量归一化为单位向量,并将人工情绪状态的显著变化的阈值设置为0.5。ECA的状态抽象如表3所示。ECA的学习参数设置为η = 0.2,γQ = 0.9,T = 50,冷却率为0.98(有关这些选择的说明,请参阅第4.4节)。为了进行比较,在实验的学习过程中记录了从环境中获得的实际奖励。他们的学习性能如图4所示。我们可以看到,与MCA相比,ECA的收敛速度更快。它的平均累积奖励以大约160000个步骤达到人工设计策略的平均奖励(请参见表4)。


4.4 Comparison of Algorithms
为了测试所提出的基于情绪的算法的性能,与其他几种算法进行了比较。除了第4.2节中所述的SCA和MCA,我们还将ECA与人工设计策略(HUM)和受限MAXQ算法(RMAXQ)进行了比较。HUM使用人类推理。人工策略的伪代码如表4所示。RMAXQ是一种受限MAXQ算法,其中仅使用MAXQ[1]来学习顶层策略。RMAXQ使用与SCA和MCA相同的状态抽象(请参见表1)。RMAXQ也使用修改后的MCA子任务。为了提高分层策略的性能,我们使用了分层策略的非分层执行[1,2]。也就是说,子任务在每个原始步骤中都会中断,并且顶层策略会选择执行价值最高的子任务。在实验中,我们发现学习不会收敛。这是因为在学习的早期阶段,尚未构建正确的价值函数,并且贪婪地执行子任务会导致该过程频繁中断。使用Dietterich的方法[1],我们为子任务执行设置了一个可变的间隔,其初始价值为50。随着学习的进行,该间隔减小为1。在实验中,我们仔细调整了每种算法的学习参数,以便可以按以下最优性能比较每种算法。我们测试了从0.1到0.35的学习率,发现它对学习收敛速度的影响小于5%。因此,对于所有算法,我们选择的学习率为0.2。所有算法均使用Boltzmann探索的初始温度(即50)。由于冷却率对学习收敛的影响更大,因此以从0.9到0.999的冷却率进行了10次运行,并为每种算法选择了实现最快收敛的冷却率。RMAXQ的冷却率为0.998。在学习过程中记录了平均累积奖励。图4显示了10次运行的平均学习性能。图4的详细信息如图6所示。ECA的收敛速度比其他算法快得多。值得注意的是,RMAXQ的收敛速度比MCA慢,直到大约150000步为止。然后它超过了MCA,并以大约500000步达到了HUM策略的平均奖励。
记录每种算法在最近10000个步骤中的平均累积奖励(MCR),以进行公平比较。同样,我们将在190000至200000期间的MCA和RMAXQ的MCR与ECA的学习步骤数相同。记录的HUM的MCR为10000步,在10次运行中进行平均。这些结果如图7所示。经过20万个ECA学习步骤,MCA和RMAXQ的平均MCR分别为0.210、0.169和0.189,均优于HUM。在500000步时,MCA达到0.203,而RMAXQ达到0.211,接近在200000步时ECA的MCR。我们提出ECA学习比MCA和RMAXQ更快的两个原因。首先,AEI将感官输入汇总到特定于任务的变量AEI中,这些变量可根据智能体的行为优先级选择性地感知环境。AEI为顶层策略提供紧凑的状态抽象。第二个原因是ECA基于AEI终止子任务,AEI是基于奖励分解源对子任务的价值函数的估计。因此,根据子任务价值的考虑,子任务在必要时终止。鉴于MCA通过人工设计的标准来终止子任务,因此不可能包括所有必要的终止谓词。RMAXQ在每个原始步骤都终止子任务。如果尚未很好地确定子任务价值函数,则频繁中断可能会减慢学习过程。ECA在子任务方面实现了MCA和RMAXQ之间的平衡。


4.5 Discussion
以上实验结果表明,子任务的简单组合会导致子任务策略的选择不充分。为了获得更好的性能,必须修改子任务定义。如果任务和环境非常复杂,则子任务的修改将很困难。例如,对于程序员来说,几乎不可能精确地包含复杂任务的所有必要终止条件。因此,修改后的组合算法可能会错过一些重要事件,从而限制了其长期学习性能。贪婪的非分层执行分层策略可以比修改后的组合算法获得更好的顶层策略。在非分层执行编程中,对于每个单个原始步骤,子任务都被迫终止,并且程序返回到调用它的上层策略。因此,程序从最低层一直返回最高层。然后,程序选择最有价值的子任务以从顶层向下执行到底层。因此,如果确定了所有级别的子任务价值函数,则贪婪的非分层执行分层策略可以保证最优解决方案。但是,例如,如果状态子任务价值与正确价值相距甚远,并且最重要的是,如果在早期学习阶段或环境发生变化时,则分层策略的贪婪的非分层执行将导致频繁中断正在执行的子任务。频繁的中断可能会减慢学习过程。对于许多应用来说,通常就是这种情况,例如在不确定的环境中真正的自主机器人。不确定的层次结构策略的贪婪的非层次结构执行可能导致智能体遭受灾难。对于动物而言,情绪是通过逐代进化而发展的一种重要的内置机制,可帮助动物在瞬息万变的复杂环境中生存。受此想法启发,在基于情绪的算法中,人工情绪机制将感官信息汇总为反映智能体奖励相关优先级的AEI。也可以将AEI视为根据奖励源分解的子任务价值函数的近似值,该函数提供对环境的选择性感知,尤其要注意与特定任务有关的环境的重大变化。AEI彼此独立。这使程序可以更轻松地归纳感官状态空间。贪婪的非分层执行分层策略的另一个缺点是,要求程序在每个原始步骤中终止子任务。然后,此最小子任务执行时间对于所有子任务都是共有的。但是,某些子任务价值可能比其他子任务价值学习得更快。然后,这也可能导致收敛变慢。此外,如果分层策略很复杂,则此方法的计算量很大。而基于情绪的算法则使用AEI作为转换触发机制,即仅使用AEI的更改来终止子任务。AEI根据奖励的来源分解顶层价值函数。子任务价值和终止条件是通过相互协作一起学习的。因此,AEI可以通过在适当的时间终止特定子任务来利用奖励因素来偏向子任务价值的学习,从而使程序可以在不必要的中断和遗漏重要事件之间保持平衡。从编程的角度来看,贪婪的非分层执行分层策略类似于轮询技术,而基于情绪的算法类似于中断驱动的编程,因为其子任务仅在AEI发生显著变化时才被中断。 因此,我们认为基于AEI的算法中的中断机制通过确保子任务不会被不必要地频繁中断而有助于学习收敛。
通过使用人工情绪机制,可以轻松地组合和仲裁多个层次结构策略,而无需进行修改。情绪变量可以通过经验与顶级策略同时学习。因此,基于情绪算法的系统具有灵活性和自主性。此外,人工情绪机制允许现有策略在新环境中重用。例如,假设我们假设一个智能体已经学会了仲裁两个子任务的策略:吃一个可食用的物体和避免一个反感物体。如果智能体看到一个新对象并将其分类为可食用或令人反感,则策略层次可以保持不变。如果对应于对象的奖励改变了,例如感知的对象从可食用变为厌恶,然后在策略层次不变的情况下反转情绪关联。因此,在此程度上,所提出的方法具有迅速适应环境的能力。
4.6 Related Work
Sutton,Precup,Singh and Ravindran[2]说明,如果允许子任务在达到其终止状态之前中断,则可以提高性能。类似地,Dietterich使用贪婪的非分层执行分层策略来提高性能[1]。贪婪地执行分层策略可能会在学习的早期阶段引起问题,因为价值函数尚未得到适当开发[1]。Gadando and Hallam[12]使用基于情绪的事件检测机制来决定行为的终止。在他们的工作中,行为的转换是通过发现情绪的重大变化而触发的。情绪是由程序员基于感官输入进行分析计算的,而在我们的算法中,AEI与顶层策略是同时学习的。Shelton[4]解决了奖励问题的多种来源。通过跟踪奖励的来源,他得出了一种算法,该算法可立即适应奖励的存在或不存在。在本文中,我们使用了多种奖励来源来分解任务。
5 Conclusions
已经提出了一种基于情绪的分层强化学习系统,该系统受大脑中情绪处理的神经生物学的启发。在相同条件下与其他传统的分层强化学习算法进行了对比实验。实验结果表明,与简单组合,修改组合和受限MAXQ算法相比,包含人工情绪机制可以重复使用子任务策略,而无需进行任何修改,并且学习性能得到显著提高。特别是,我们的方法为学习早期阶段贪婪的非分层策略执行提供了一种替代方法,可确保子任务仅在子任务价值的变化显著时才被中断。在随后的工作中,将学习奖励分类,以适应以前看不见的奖励来源。