教你读懂python3和python2中的编码问题
最近又有很多小伙伴说被python中的编码问题搞得好晕。一会unicode,一会又是bytes,python2跟3还是反过来的,为何在2中只能decode(解码),到3又只能encode(编码)。今天我们就来说一说这个问题。
首先我们得先了解一下,什么是字符编码?
计算机想要工作必须通电,也就是说“电”驱动计算机干活,而“电”的特性,就是高低电平(高低电平即二进制数1,低电平即二进制数0),也就是说计算机只认识01两种数字。我们想要保存数据,首先 得将我们的数据进行一些处理,最终得转换成00101类似的才能让计算机识别。
所以我们必须有一个过程:
字符 ----------> (翻译)---------------> 数字
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称为字符编码。
用大白话来说就是,计算机不认识我们现实世界的数字还有字母,那么我们就规定了一本字典(ascii码表),如下图。然后告诉计算机,以后如果我们输入a,就是十进制97,然后你自己再翻译成二进制,再帮我显示出来,你不用关心我们输入的是什么意思,只要翻译就好,懂不懂?计算机说:老大,我懂了。然后从此我们就可以在计算机上显示字母数字跟一些特殊符号了。然而,这是美国人的字典,他们怎么会想到还有我们博大精深的中文文化呢?
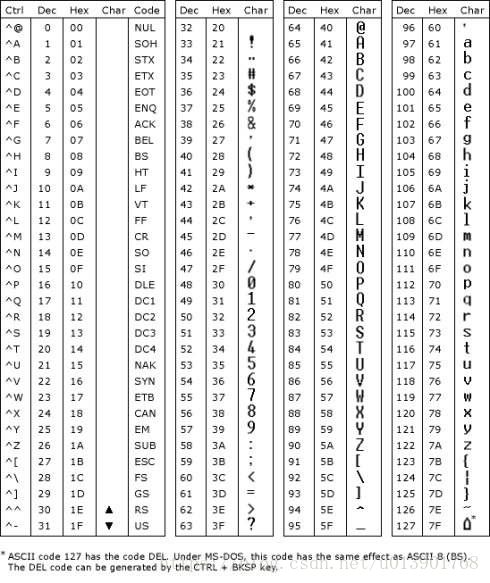
这时候我们中国也要用电脑,但都是全英文,我们想输入汉字,那怎么办。一向来聪明的我们就自己写了一本字典(GBK),然后也是告诉计算机,以后就按照这本字典来显示。
最开始那本,也就是ascii码,用低7位来表示128个字符,后面剩下的就空着。而我们GBK呢,是用2个字节(Bytes)来表示一个汉字,这样一下来就可以显示6W+汉字了。
但这样有个问题,每个国家都有自己的字典,以后你用你的字典跟计算机做的事,我想看,但是我没你的字典就不知道你们干了什么事情,那我岂不是很没面子。这时候,大佬们就坐下来商量,说我们要有一套标准,让所有语言都可以用一本字典来表示,这时候,万国码Unicode就诞生了。
Unicode 最初也是采用两个字节编码字符,后来发现不够用才扩展为四个字节(与 UCS-4 对应)。理论上 UCS-4 编码范围能达到 U+7FFFFFFF,容纳二十多亿个字符,但是因为 Unicode 和 ISO 达成共识,只会用到 17 个平面,包含 1 个基本平面(BMP)和 16 个辅助平面,最高码位 U+10FFFF。
未完待续