起点中文网月票等字体数据爬取Python
起点中文网收藏量等数据爬取
1.难点分析
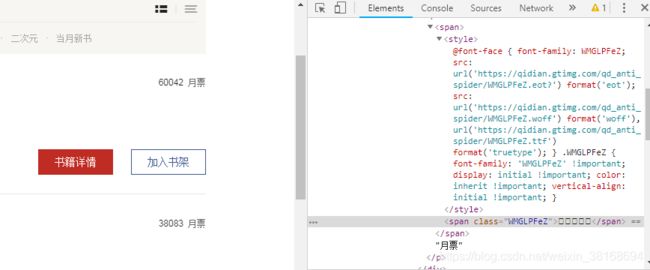
通过chrome开发工具分析我么可以得出结论,月票数量不是html文本,而是通过字体生成出来的数字,这时候的爬虫就要复杂一些了。
2.思路分析
先爬取目标网页的字体,之后通过python fontTools、io库将字体转化成数字
3.核心代码呈现
def get_font(url):
response = requests.get(url)
font = TTFont(BytesIO(response.content))
cmap = font.getBestCmap()
font.close()
return cmap
def get_encode(cmap, values):
WORD_MAP = {'zero': '0', 'one': '1', 'two': '2', 'three': '3', 'four': '4', 'five': '5', 'six': '6', 'seven': '7',
'eight': '8', 'nine': '9', 'period': '.'}
word_count = ''
for value in values.split(';'):
value = value[2:]
key = cmap[int(value)]
word_count += WORD_MAP[key]
return word_count
4.程序效果


5后记
若是想借鉴程序全部代码请评论留言