线程池-学习笔记(ThreadPool源代码内容详细解读)
文章目录
- 1. 线程池存在的意义
- 优点
- 线程池优点解释
- 优点2:提高相应速度
- 目的
- 2. 使用场景
- 应用举例
- 3. 处理流程
- 4. 开源库
- 5. 重要问题说明
- 5.1 实现线程池的关键点
- 5.2 线程相关的问答
- 6. 知识点补充(c++11)
- 右引用+move语义
- 浅拷贝 & 深拷贝
- emplace_back
- 可变模板参数
- 自动推导函数返回类型
- lambda表达式
- std::function
- std::future
- std::result_of
- std::mutex
- std::condition_variable
- make_shared
- 7. 参考资料
1. 线程池存在的意义
优点
- 帮我们重复管理线程,避免创建大量的线程增加开销。
- 提高响应速度。
线程池优点解释
优点2:提高相应速度
我们将传统方案中的线程执行过程分为三个过程:T1、T2、T3。
T1:线程创建时间
T2:线程执行时间,包括线程的同步等时间
T3:线程销毁时间
线程本身的开销所占的比例为:(T1+T3) / (T1+T2+T3)。如果线程执行的时间很短的话,这比开销可能占到20%-50%左右。如果任务执行时间很长的话,这笔开销可以忽略。
目的
减少线程本身带来的时间开销,即线程的创建和销毁;
2. 使用场景
- 单位时间内处理任务频繁而且任务处理时间短
- 对实时性要求较高。如果接受到任务后在创建线程,可能满足不了实时要求,因此必须采用线程池进行预创建。
应用举例
- Web服务器、Email服务器;
- 实时三维重建;
3. 处理流程
- 线程池采用预创建的技术,在应用程序启动之后,将立即创建一定数量的线程(N1),放入空闲队列中。这些线程都是处于阻塞(Suspended)状态,不消耗CPU,但占用较小的内存空间。
- 当任务到来后,缓冲池选择一个空闲线程,把任务传入此线程中运行。
- 当N1个线程都在处理任务后,缓冲池自动创建一定数量的新线程,用于处理更多的任务。
- 在任务执行完毕后线程也不退出,而是继续保持在池中等待下一次的任务。
- 当系统比较空闲时,大部分线程都一直处于暂停状态,线程池自动销毁一部分线程,回收系统资源。
线程池,最简单的就是生产者消费者模型了。池里的每条线程,都是消费者,他们消费并处理一个个的任务,而任务队列就相当于生产者了。
线程池最简单的形式是含有一个固定数量的工作线程来处理任务,典型的数量是std::thread::hardware_concurrency()
4. 开源库
Github链接:https://github.com/progschj/ThreadPool
#ifndef THREAD_POOL_H
#define THREAD_POOL_H
#include 5. 重要问题说明
5.1 实现线程池的关键点
- 任务队列:用来存放任务,每次只能有一个线程执行该任务;
- 条件变量与互斥锁:保证同一个线程在执行的时候,不会再被调用。其中条件变量的细节内容,见第6小节。
5.2 线程相关的问答
(1)同时开多少线程最合适?
基本上按照电脑的核数来确定,电脑是6核,可以最多同时开12个线程。当有上下位的时候,要考虑其他软件开启线程的情况。
(2)开启和关闭线程为什么比较耗时?
因为这个涉及到内存的申请和释放。
(3)阻塞线程的两种方式?
按照互斥锁是否在函数体内外部划分可以分为两种。一种是在函数体内部,这个一般是防止函数还未执行完成,又执行该函数。第二种是多线程访问同一块内存,度需要改写这块内存,需要在这一块内存加锁,防止多个线程同时改写。
6. 知识点补充(c++11)
这一小节,补充上述源代码用到的一些知识,主要是c++11的特性。
右引用+move语义
右值:一般来说,不能取地址的表达式,就是右值;
左值::能取地址的;
右值分为:纯右值和将亡值。将亡值也就是即将被销毁、却能够被移动的值。
右值引用的主要目的:是提高程序运行的效率,减少需要进行深拷贝的对象进行深拷贝的次数。
例如:
class A { };
A & r = A(); // error , A()是无名变量,是一个临时对象,是右值,并且是一个将亡值
A && r = A(); //ok, r 是右值引
std::move 这个方法将左值参数无条件的转换为右值;
std::string lv1 = "string,"; // lv1 是一个左值
// std::string&& r1 = lv1; // 非法, 右值引用不能引用左值
std::string&& rv1 = std::move(lv1);
在vector中使用move的例子:
#include 由于右引用的存在,参数转发会存在问题。向函数传递右值,最终调用的左值函数。应该使用 std::forward 来进行参数的转发。(详细内容请见《高速上手c++11/14》第三章:语言运行期的强化)
浅拷贝 & 深拷贝
- 浅拷贝
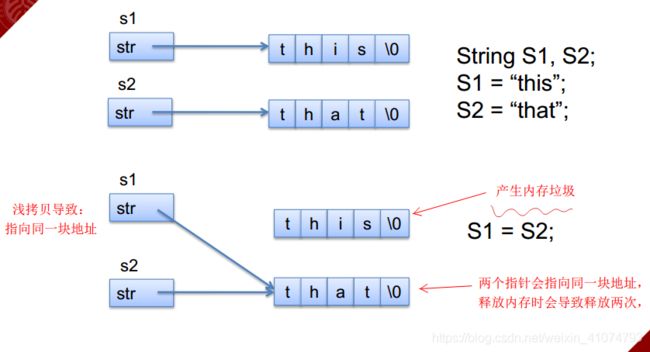
- 深拷贝

emplace_back
emplace_back() 和 push_back 的区别:https://blog.csdn.net/xiaolewennofollow/article/details/52559364
emplace_back():vector压入右值使用的方法;
emplace函数在容器中直接构造元素,传递给emplace函数的参数必须与元素类型的构造函数相匹配。
可变模板参数
它对参数进行了高度泛化,它能表示0到任意个数、任意类型的参数。
形如:
template <class... T>
void f(T... args);
上面的可变模版参数的定义当中,省略号的作用有两个:
- 声明一个参数包T… args,这个参数包中可以包含0到任意个模板参数;
- 在模板定义的右边,可以将参数包展开成一个一个独立的参数。
可变模板参数的特点:无法直接获取参数包args中的每个参数的,只能通过展开参数包的方式来获取参数包中的每个参数。(参数包:带有省略号的参数成为“参数包);
举例:
#include 展开参数包参数的2个办法:
- 通过递归函数来展开参数包(参数包展开的函数和递归终止函数)
- 通过逗号表达式来展开参数包
TODO:待完善学习
参考资料:泛化之美–C++11可变模版参数的妙用:https://www.cnblogs.com/qicosmos/p/4325949.html
自动推导函数返回类型
auto 函数名(参数列表) -> 返回类型 {
// 函数体
}
lambda表达式
[捕获列表](参数列表) mutable(可选) 异常属性 -> 返回类型 {
// 函数体
}
捕获列表常用的4中形式:
- [] 不使用任何外部变量 ;
- [=] 以传值的形式使用所有外部变量 ;
- [&] 以引用形式使用所有外部变量 ;
- [x, &y] x 以传值形式使用, y 以引用形式使用;
- [=,&x,&y] x,y 以引用形式使用,其余变量以传值形式使用;
- [&,x,y] x,y 以传值的形式使用,其余变量以引用形式使用 ;
int main()
{
int x = 100,y=200,z=300;
cout << [ ](double a,double b) { return a + b; } (1.2,2.5) << endl;
auto ff = [=,&y,&z](int n) {
cout <<x << endl;
y++; z++;
return n*n;
};
cout << ff(15) << endl;
cout << y << "," << z << endl;
}
/*
输出:
3.7
100
225
201,301
*/
std::function
-
定义:是一种通用、多态的函数封装。函数的容器。
-
好处:能够更加方便的将函数、函数指针作为对象进行处理。
例子:
#include std::future
用来获取异步任务的结果,因此可以把它当成一种简单的线程间同步的手段。
std::future 对象通常由以下三种 Provider 创建:
- std::async 函数;
- std::promise::get_future,get_future 为 promise 类的成员函数
- std::packaged_task::get_future,此时 get_future为 packaged_task 的成员函数
参考资料:并发编程https://www.cnblogs.com/haippy/p/3280643.html
std::result_of
用于在编译的时候推导出一个函数表达式的返回值类型。
参考资料:
- https://blog.csdn.net/Catelemmon/article/details/79884671
- https://blog.csdn.net/qq_31175231/article/details/77165279
std::mutex
互斥锁:https://blog.csdn.net/fengbingchun/article/details/73521630
std::lock_guard与std::mutex配合使用。把锁放到lock_guard中时,mutex自动上锁,lock_guard析构时,同时把mutex解锁。mutex又称互斥量。
std::condition_variable
条件变量一般的使用场景:
线程A需要等某个条件成立才能继续往下执行,现在这个条件不成立,线程A就阻塞等待,而线程B在执行过程中使这个条件成立了,就唤醒线程A继续执行。在pthread库中通过条件变量(Condition Variable)来阻塞等待一个条件,或者唤醒等待这个条件的线程。
pthread内部Condition条件变量有两个关键函数, await和signal方法。
一个Condition实例的内部实际上维护了两个队列,一个是等待锁队列,mutex内部其实就是维护了一个队列。 另一个队列可以叫等待条件队列,在这队列中的节点都是由于(某些条件不满足而)线程自身调用wait方法阻塞的线程,记住是自身阻塞。最重要的Condition方法是wait和 notify方法。另外condition还需要lock的支持, 如果你构造函数没有指定lock,condition会默认给你配一个rlock。
下面是这两个方法的执行流程。
- await方法:
- 入列到条件队列(注意这里不是等待锁的队列)
- 释放锁
- 阻塞自身线程
————被唤醒后执行————-
-
尝试去获取锁(执行到这里时线程已不在条件队列中,而是位于等待(锁的)队列中,参见signal方法)
4.1 成功,从await方法中返回,执行线程后面的代码
4.2 失败,阻塞自己(等待前一个节点释放锁时将它唤醒)
注意: 调用wait可以让当前线程休眠,等待其他线程的唤醒,也就是等待signal,这个过程是阻塞的。 当队列首线程被唤醒后,会继续执行await方法中后面的代码。
- signal (notify)方法:
- 将条件队列的队首节点取出,放入等待锁队列的队尾
- 唤醒节点对应的线程.
注: signal ( notify ) 可以把wait队列的那些线程给唤醒起来。
std::condition_variable 提供了两种 wait() 函数。当前线程调用 wait() 后将被阻塞(此时当前线程应该获得了锁(mutex),不妨设获得锁 lck),直到另外某个线程调用 notify_* 唤醒了当前线程。
在线程被阻塞时,该函数会自动调用 lck.unlock() 释放锁,使得其他被阻塞在锁竞争上的线程得以继续执行。另外,一旦当前线程获得通知(notified,通常是另外某个线程调用 notify_* 唤醒了当前线程),wait() 函数也是自动调用 lck.lock(),使得 lck 的状态和 wait 函数被调用时相同。
参考资料
-
http://xiaorui.cc/2016/05/31/聊聊threading的condition条件变量/
-
https://www.cnblogs.com/haippy/p/3252041.html
make_shared
C++11 中引入了智能指针, 同时还有一个模板函数 std::make_shared 可以返回一个指定类型的 std::shared_ptr。尽量使用make_shared初始化。
举例:
shared_ptr<string> p1 = make_shared<string>(10, '9');
shared_ptr<string> p2 = make_shared<string>("hello");
shared_ptr<string> p3 = make_shared<string>();
参考资料:https://www.jianshu.com/p/03eea8262c11
7. 参考资料
- C++11并发学习之六:线程池的实现:https://blog.csdn.net/caoshangpa/article/details/80374651
- 理解线程池的原理(java):https://blog.csdn.net/mine_song/article/details/70948223
- 《高速上手C++11/14》