Redis常见的面试题(2020-08-03创建)-有错请留言
关于本文,自己小白,面试的时候收集了一些常见的面试题,根据网上的解答,大牛的解释,自己的理解,写了这篇文章,有需要自提,有错请留言,谢谢指正。
更新记录
20200803 – Redis支持的数据类型及应用场景
20200804 – Redis持久化及相关配置项
问题列表:
1、Redis支持的数据类型
2、什么是Redis持久化(Redis持久化方式和优缺点)以及相关配置项
3、Redis有哪些架构模式以及各自的特点
4、Redis分布式锁以及实现原理
5、怎么使用Redis做异步队列,有什么缺点
6、什么是缓存穿透和缓存雪崩,怎么避免
7、Redis常用的命令
8、为什么Redis单线程却能支持高并发
9、Redis的内存淘汰策略
10、Redis的并发竞争问题怎么解决
Answer-One:
Redis支持5种数据类型:
①String(字符串) --常用操作命令:get/set
②Hash(哈希) --常用操作命令:hmset/hmget/hgetall
③List(列表) --常用操作命令:L/R开头,包含push,指定元素前后,指定下标,列表头尾等插入和删除等命令
④Set(集合) --常用操作命令:S开头,包含添加移除,不同集合的交集/并集/差异等
底层使用哈希表实现,每个集合增删查改的复杂度都是O(1),并且是String类型的无序集合,每个集合成员内的值是唯一的
⑤Sort Set(有序集合) --常用操作命令:Z开头,添加/删除,在指定区间内统计/删除等
Redis内部内存管理怎么描述不同数据类型?
 如上图,Redis内部用一个RedisObject对象来表示所有key-value包含的属性内容。type字段描述了该对象的数据类型,值得一提得是,encoding标识的是redis内部的存储方式;
如上图,Redis内部用一个RedisObject对象来表示所有key-value包含的属性内容。type字段描述了该对象的数据类型,值得一提得是,encoding标识的是redis内部的存储方式;
另外,虚拟内存(vm)字段默认是关闭的,只有打开了Redis的虚拟内存功能,该字段才会真正的分配内存。
通俗的看,无论数据类型是哪一种,从设计数据结构到最后进行存储,需要存储到Redis中的value都是一个字符串(大字符串)
Redis数据类型适用的业务场景
1、String(字符串)类型(最常用):Redis最基本的数据类型,存储方式是二进制安全的,即该类型可以包含任何数据(JPG图像或者是序列化的对象等)
适用场景:要素单一的映射关系,比如金融系统中的四要素映射,由于String类型常用的还有incr(+1),decr(-1)的方法,所以也常用来做统计数的映射
2、Hash(哈希)类型:使用时除了redis命令的关键字外,还需要包含field-value两个参数,标识了Map
该类型一般存储的是对象,常用来存储多表间的关联数据存储,比如有如下的数据结构
表一:课程ID+课程名称+任课老师ID (课程ID:任课老师ID=1:n)
表二:任课老师ID+任课老师名称
表三:学生ID+课程ID+学生名称 (课程ID:学生ID = 1:n)
要求:将上面三张表的所有数据缓存到redis中,使用Hash类型
观察上面的表结构,发现可以通过任课老师ID作为hkey进行三张表的数据关联,具体实现可以如下
王老师(ID:T1001)
负责三门课程(C1001->语文,C1002->数学,C1003->英语)
带了三名学生(S1001->C1001->小明,S1002->C1002->小红,S1003->C1003->小帅,S1001->C1003->小帅)
具体设计如下
hkey = T1001
field <=> value
C_LIST = C1001,C1002,C1003
C1001 = 语文
C1002 = 数学
C1003 = 英语
CLASS_STUDENT_LIST_C1001 = S1001
CLASS_STUDENT_LIST_C1002 = S1002
CLASS_STUDENT_LIST_C1003 = S1001,S1002
S1001 = 小明
S1002 = 小红
S1003 = 小帅
该结构将教师的表编号独立出来,得到唯一映射(字符串类型) : T1001 = 王老师
在上面的例子中,除了表结构中的字段之外,为了将表之间的关系串联起来,添加了
C_LIST 和 CLASS_STUDENT_LIST_C**** 两个field定义,后端代码在hgetall T1001后获得的map集合就可以通过业务关系,还原得到原来的数据库存储的数据
观察上面的Hash结构,在设计完成进行代码的开发时会发现,Map
PS:哈希类型的数据在redis进行存储时。默认的zipmap,当该key下的成员数量增大时会自动转成ht(hashmap)
3、List(列表)类型,存储上是简单的字符串列表,按照插入的顺序进行排序。底层的存储结构是双向列表(每个成员的也是String类型的双向链表),所以通过LPUSH/RPUSH方法可以快速地插入(越接近两端地元素操作越快,通过索引进行访问时会比较慢)
常用的使用场景:使用list构建队列系统,通过range方法限制队列的大小,通过trim方法来裁减列表的大小
like:
在上面的队列场景中,我们要做的内容:
//1、将内容添加到list中
list.lpush("list-queue","1");
//2、裁剪列表的大小
list.ltrim("list-queue",0,N-1);
//3、将列表的内容查询出来返回
list.lrange("list-queue",0,N-1)
4、set(集合)类型,String类型的无序集合。跟List不一样的地方。Redis的Set数据类型提供了,不同集合之间的交集,并集,差集等操作,所以经常被应用在:不同用户之间的相似度统计(好友推荐)等场景
5、sort set(有序集合)类型,sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,
该score是一个double类型的权重参数
PS:有序+score优先级参数,sort set有时也作为队列来使用,并且该队列已经包含了优先级参数
总结
| 类型 | 简介 | 特性 | 场景 |
|---|---|---|---|
| String(字符串) | 二进制安全 | 包含任何数据(图片和序列化对象) | – |
| Hash(哈希) | key-value(Map类型) | 复杂的关联表数据存储 | 增删查改用户数据 |
| List(列表) | 双向链表 | 增删快,可以操作某一段元素(start/stop) | 消息队列 |
| Set(集合) | 通过哈希表实现 | 增删查改的复杂度都是O(1),提供交集,并集,差集的api | 相似度统计 |
| Sort set(有序集合) | 通过double类型的sorce权重参数进行排序 | 插入时默认排序 | 排行榜或者带有优先级权重的消息队列 |
Answer-Two
Redis持久化机制有两种:
①RDB(Redis DataBase)
②AOP(Append Only File)
在讨论这两种机制前,我们先看一下Redis的持久化流程
①客户端向服务端发送写操作请求 (此时数据保存在客户端的内存中)
②服务端接收到客户端写请求的数据(此时数据保存在服务端的内存中)
③服务端调用write(一个系统调用接口),将数据写入磁盘(此时数据保存在系统内存的缓冲区)
④操作系统将缓冲区的数据转移到磁盘控制器上(此时数据保存在磁盘缓存中)
⑤磁盘控制器将数据写到磁盘的物理介质中(成功写到磁盘上)
那么持久化策略机制在Redis持久化流程中做了什么?
我们先假设一下在持久化流程的五个步骤中,Redis故障的场景:
场景①:Redis数据库发生故障
此时想要保证数据的完整性只需要执行完成前三步即可
场景②:操作系统发生故障
此时想要保证数据的完整性则需要完成全部流程
一、RDB策略(默认的持久化策略),将流程③~⑤的步骤取消,以如下的方式进行Redis持久化
①在特定时刻(触发机制)的数据写入快照文件(二进制,默认的文件名称为dump.rdb)
②在指定的时间间隔将快照文件的数据写入磁盘
RDB文件写入磁盘的触发机制:
①save(被动):阻塞Redis,不占用服务端内存,在生成RDB文件的过程中,Redis不能处理其他命令
②bgsave(被动,默认):异步进行快照操作,同时快照可以响应客户端请求(异步方式是Redis进程执行fork命令创建子进程,fork时占用服务端内存)
③自动化(主动):在redis.conf中进行配置
默认配置如下
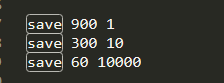
###save: save m n 表示在m秒内数据集发生n次修改时,自动触发 bgsave
save 900 1 表示900s内至少只有一个Key的值发生变化
save 300 10 表示300s内至少有10个key的值发生变化
save 60 10000 表示60s内至少有10000个key值发生变化
###上面的三个默认配置是同时生效的,如果不需要持久化,则取消save行来停用保存功能
其他相关配置:
stop-writes-on-bgsave-error :默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难发生了。如果Redis重启了,那么又可以重新开始接收数据了
rdbcompression ;默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。
rdbchecksum :默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
dbfilename :设置快照的文件名.
dir:设置快照文件的存放路径.
RDB策略的优缺点
优点:RDB文件是全量备份,适合灾备和恢复,其大数据集的速度比AOF的恢复速度要快
缺点:快照持久化是由子进程负责,在该过程中如果父进程修改了内存,这在子进程中是无感知的(该部分修改的数据不会被保存,下一次快照时会更新,但是仍然可能丢失数据)
二、AOF策略,将持久化流程中的③~⑤替换成日志记录
通过write(系统调用接口),将数据append到文件中,该方式生成的Aof文件会越来越大
针对这种情况,redis用类似于快照重写的方式提供了bgrewriteaof命令来将内存中的数据保存到临时文件中,同时fork一个子进程来将文件重写
AOF策略的触发机制:
①always:同步操作,每次变更都记录到磁盘中
②everysec:异步操作,每秒记录一次,如果宕机,则会丢失这一秒内的数据(一般是选择这个)
③no:不同步
AOF策略的优缺点
优点:AOF文件没有磁盘寻址的开销(直接append),写入性能高,文件也不容易损坏,大文件的重写也不影响客户都的读写
缺点:相同的数据量,AOF文件要比RDB文件更大,相同配置的QPS,AOF偏低
PS:两种策略一般都结合使用,根据需求自行选择,总结表格
| 命令 | RDB | AOF |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 文件大小 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 安全性 | 丢数据 | 根据策略决定 |
| 重要性 | 重 | 轻 |
Answer Three