高频知识——C++进阶知识(高级教程)
参考链接:https://www.runoob.com/cplusplus/cpp-interfaces.html
之前分别介绍了C++的基本语法,面向对象的设计方法,下面介绍一下C++的一些高级教程,也是面试的高频问题。
1 文件和流
iostream 标准库,它提供了 cin 和 cout 方法分别用于从标准输入读取流和向标准输出写入流。
从文件读取流和向文件写入流。需要用到 C++ 中另一个标准库 fstream,它定义了三个新的数据类型:
| 数据类型 | 描述 |
|---|---|
| ofstream | 该数据类型表示输出文件流,用于创建文件并向文件写入信息。 |
| ifstream | 该数据类型表示输入文件流,用于从文件读取信息。 |
| fstream | 该数据类型通常表示文件流,且同时具有 ofstream 和 ifstream 两种功能,这意味着它可以创建文件,向文件写入信息,从文件读取信息。 |
要在 C++ 中进行文件处理,必须在 C++ 源代码文件中包含头文件
开文件。ofstream 和 fstream 对象都可以用来打开文件进行写操作,如果只需要打开文件进行读操作,则使用 ifstream 对象。open()函数的标准用法。第一参数是文件名称和位置。第二参数是定义文件被打开的模式。
void open(const char *filename, ios::openmode mode);| 模式标志 | 描述 |
|---|---|
| ios::app | 追加模式。所有写入都追加到文件末尾。 |
| ios::ate | 文件打开后定位到文件末尾。 |
| ios::in | 打开文件用于读取。 |
| ios::out | 打开文件用于写入。 |
| ios::trunc | 如果该文件已经存在,其内容将在打开文件之前被截断,即把文件长度设为 0。 |
可以结合使用,比如:
ifstream afile;
afile.open("file.dat", ios::out | ios::in );关闭文件(好习惯):
void close();写入文件:
在 C++ 编程中,我们使用流插入运算符( << )向文件写入信息,就像使用该运算符输出信息到屏幕上一样。
读取文件:
在 C++ 编程中,我们使用流提取运算符( >> )从文件读取信息,就像使用该运算符从键盘输入信息一样。
例子:
#include
#include
using namespace std;
int main ()
{
char data[100];
// 以写模式打开文件
ofstream outfile;
outfile.open("afile.dat");
cout << "Writing to the file" << endl;
cout << "Enter your name: ";
cin.getline(data, 100);
// 向文件写入用户输入的数据
outfile << data << endl;
cout << "Enter your age: ";
cin >> data;
cin.ignore();
// 再次向文件写入用户输入的数据
outfile << data << endl;
// 关闭打开的文件
outfile.close();
// 以读模式打开文件
ifstream infile;
infile.open("afile.dat");
cout << "Reading from the file" << endl;
infile >> data;
// 在屏幕上写入数据
cout << data << endl;
// 再次从文件读取数据,并显示它
infile >> data;
cout << data << endl;
// 关闭打开的文件
infile.close();
return 0;
}
结果:
$./a.out
Writing to the file
Enter your name: Zara
Enter your age: 9
Reading from the file
Zara
9 上面的实例中使用了 cin 对象的附加函数,比如 getline()函数从外部读取一行,ignore() 函数会忽略掉之前读语句留下的多余字符。
文件位置指针:istream 和 ostream 都提供了用于重新定位文件位置指针的成员函数。这些成员函数包括关于 istream 的 seekg("seek get")和关于 ostream 的 seekp("seek put")。
2 异常处理
异常是程序在执行期间产生的问题。C++ 异常是指在程序运行时发生的特殊情况,比如尝试除以零的操作。
异常提供了一种转移程序控制权的方式。C++ 异常处理涉及到三个关键字:try、catch、throw。
- throw: 当问题出现时,程序会抛出一个异常。这是通过使用 throw 关键字来完成的。
- catch: 在您想要处理问题的地方,通过异常处理程序捕获异常。catch 关键字用于捕获异常。
- try: try 块中的代码标识将被激活的特定异常。它后面通常跟着一个或多个 catch 块。
如果有一个块抛出一个异常,捕获异常的方法会使用 try 和 catch 关键字。try 块中放置可能抛出异常的代码,try 块中的代码被称为保护代码。使用 try/catch 语句的语法如下所示:
try
{
// 保护代码
}catch( ExceptionName e1 )
{
// catch 块
}catch( ExceptionName e2 )
{
// catch 块
}catch( ExceptionName eN )
{
// catch 块
}如果 try 块在不同的情境下会抛出不同的异常,这个时候可以尝试罗列多个 catch 语句,用于捕获不同类型的异常。
抛出异常:可以使用 throw 语句在代码块中的任何地方抛出异常。throw 语句的操作数可以是任意的表达式,表达式的结果的类型决定了抛出的异常的类型。
double division(int a, int b)
{
if( b == 0 )
{
throw "Division by zero condition!";
}
return (a/b);
}捕获异常:catch 块跟在 try 块后面,用于捕获异常。可以指定想要捕捉的异常类型,这是由 catch 关键字后的括号内的异常声明决定的。让 catch 块能够处理 try 块抛出的任何类型的异常,则必须在异常声明的括号内使用省略号 ...。
#include
using namespace std;
double division(int a, int b)
{
if( b == 0 )
{
throw "Division by zero condition!";
}
return (a/b);
}
int main ()
{
int x = 50;
int y = 0;
double z = 0;
try {
z = division(x, y);
cout << z << endl;
}catch (const char* msg) {
cerr << msg << endl;
}
return 0;
}
结果:
Division by zero condition! 由于我们抛出了一个类型为 const char* 的异常,因此,当捕获该异常时,我们必须在 catch 块中使用 const char*。
标准异常:
C++ 提供了一系列标准的异常,定义在

| 异常 | 描述 |
|---|---|
| std::exception | 该异常是所有标准 C++ 异常的父类。 |
| std::bad_alloc | 该异常可以通过 new 抛出。 |
| std::bad_cast | 该异常可以通过 dynamic_cast 抛出。 |
| std::bad_exception | 这在处理 C++ 程序中无法预期的异常时非常有用。 |
| std::bad_typeid | 该异常可以通过 typeid 抛出。 |
| std::logic_error | 理论上可以通过读取代码来检测到的异常。 |
| std::domain_error | 当使用了一个无效的数学域时,会抛出该异常。 |
| std::invalid_argument | 当使用了无效的参数时,会抛出该异常。 |
| std::length_error | 当创建了太长的 std::string 时,会抛出该异常。 |
| std::out_of_range | 该异常可以通过方法抛出,例如 std::vector 和 std::bitset<>::operator[]()。 |
| std::runtime_error | 理论上不可以通过读取代码来检测到的异常。 |
| std::overflow_error | 当发生数学上溢时,会抛出该异常。 |
| std::range_error | 当尝试存储超出范围的值时,会抛出该异常。 |
| std::underflow_error | 当发生数学下溢时,会抛出该异常。 |
可以通过继承和重载 exception 类来定义新的异常。
#include
#include
using namespace std;
struct MyException : public exception
{
const char * what () const throw ()
{
return "C++ Exception";
}
};
int main()
{
try
{
throw MyException();
}
catch(MyException& e)
{
std::cout << "MyException caught" << std::endl;
std::cout << e.what() << std::endl;
}
catch(std::exception& e)
{
//其他的错误
}
}
结果:
MyException caught
C++ Exception 在这里,what() 是异常类提供的一个公共方法,它已被所有子异常类重载。这将返回异常产生的原因。
3 动态内存
了解动态内存在 C++ 中是如何工作的是成为一名合格的 C++ 程序员必不可少的。C++ 程序中的内存分为两个部分:
- 栈:在函数内部声明的所有变量都将占用栈内存。
- 堆:这是程序中未使用的内存,在程序运行时可用于动态分配内存。
在 C++ 中,可以使用特殊的运算符为给定类型的变量在运行时分配堆内的内存,这会返回所分配的空间地址。这种运算符即 new 运算符。如果不再需要动态分配的内存空间,可以使用 delete 运算符,删除之前由 new 运算符分配的内存。
new和delete运算符
new data-type;定义一个指向 double 类型的指针,然后请求内存,该内存在执行时被分配。
double* pvalue = NULL; // 初始化为 null 的指针
pvalue = new double; // 为变量请求内存如果自由存储区已被用完,可能无法成功分配内存。所以建议检查 new 运算符是否返回 NULL 指针,并采取以下适当的操作:
double* pvalue = NULL;
if( !(pvalue = new double ))
{
cout << "Error: out of memory." <malloc() 函数在 C 语言中就出现了,在 C++ 中仍然存在,但建议尽量不要使用 malloc() 函数。new 与 malloc() 函数相比,其主要的优点是,new 不只是分配了内存,它还创建了对象。
可以使用 delete 操作符释放它所占用的内存
delete pvalue; // 释放 pvalue 所指向的内存#include
using namespace std;
int main ()
{
double* pvalue = NULL; // 初始化为 null 的指针
pvalue = new double; // 为变量请求内存
*pvalue = 29494.99; // 在分配的地址存储值
cout << "Value of pvalue : " << *pvalue << endl;
delete pvalue; // 释放内存
return 0;
} 数组的动态内存分配:
har* pvalue = NULL; // 初始化为 null 的指针
pvalue = new char[20]; // 为变量请求内存
delete [] pvalue; // 删除 pvalue 所指向的数组多维数组:
int **array
// 假定数组第一维长度为 m, 第二维长度为 n
// 动态分配空间
array = new int *[m];
for( int i=0; i对象的动态内存分配
对象与简单的数据类型没有什么不同。
#include
using namespace std;
class Box
{
public:
Box() {
cout << "调用构造函数!" < 如果要为一个包含四个 Box 对象的数组分配内存,构造函数将被调用 4 次,同样地,当删除这些对象时,析构函数也将被调用相同的次数(4次)。
当上面的代码被编译和执行时,它会产生下列结果:
调用构造函数!
调用构造函数!
调用构造函数!
调用构造函数!
调用析构函数!
调用析构函数!
调用析构函数!
调用析构函数!4 命名空间
命名空间作为附加信息来区分不同库中相同名称的函数、类、变量等。使用了命名空间即定义了上下文。本质上,命名空间就是定义了一个范围。
命名空间的定义使用关键字 namespace,后跟命名空间的名称,如下所示:
namespace namespace_name {
// 代码声明
}为了调用带有命名空间的函数或变量,需要在前面加上命名空间的名称:
name::code; // code 可以是变量或函数#include
using namespace std;
// 第一个命名空间
namespace first_space{
void func(){
cout << "Inside first_space" << endl;
}
}
// 第二个命名空间
namespace second_space{
void func(){
cout << "Inside second_space" << endl;
}
}
int main ()
{
// 调用第一个命名空间中的函数
first_space::func();
// 调用第二个命名空间中的函数
second_space::func();
return 0;
} 可以使用 using namespace 指令,这样在使用命名空间时就可以不用在前面加上命名空间的名称。这个指令会告诉编译器,后续的代码将使用指定的命名空间中的名称。
using 指令也可以用来指定命名空间中的特定项目。例如,如果您只打算使用 std 命名空间中的 cout 部分:
using std::cout;随后的代码中,在使用 cout 时就可以不用加上命名空间名称作为前缀,但是 std 命名空间中的其他项目仍然需要加上命名空间名称作为前缀。
命名空间可以定义在几个不同的部分中,因此命名空间是由几个单独定义的部分组成的。一个命名空间的各个组成部分可以分散在多个文件中。
命名空间可以嵌套。可以通过使用 :: 运算符来访问嵌套的命名空间中的成员。
5 模板
模板是泛型编程的基础,泛型编程即以一种独立于任何特定类型的方式编写代码。模板是创建泛型类或函数的蓝图或公式。
函数模板:type 是函数所使用的数据类型的占位符名称。这个名称可以在函数定义中使用。
template ret-type func-name(parameter list)
{
// 函数的主体
} 类模板:type 是占位符类型名称,可以在类被实例化的时候进行指定。
template class class-name {
.
.
.
} include
#include
#include
#include
#include
using namespace std;
template
class Stack {
private:
vector elems; // 元素
public:
void push(T const&); // 入栈
void pop(); // 出栈
T top() const; // 返回栈顶元素
bool empty() const{ // 如果为空则返回真。
return elems.empty();
}
};
template
void Stack::push (T const& elem)
{
// 追加传入元素的副本
elems.push_back(elem);
}
template
void Stack::pop ()
{
if (elems.empty()) {
throw out_of_range("Stack<>::pop(): empty stack");
}
// 删除最后一个元素
elems.pop_back();
}
template
T Stack::top () const
{
if (elems.empty()) {
throw out_of_range("Stack<>::top(): empty stack");
}
// 返回最后一个元素的副本
return elems.back();
}
int main()
{
try {
Stack intStack; // int 类型的栈
Stack stringStack; // string 类型的栈
// 操作 int 类型的栈
intStack.push(7);
cout << intStack.top() < 上边是一个定义stack的例子。
6 预处理器
预处理器是一些指令,指示编译器在实际编译之前所需完成的预处理。
所有的预处理器指令都是以井号(#)开头,只有空格字符可以出现在预处理指令之前。预处理指令不是 C++ 语句,所以它们不会以分号(;)结尾。
我们已经看到,之前所有的实例中都有 #include 指令。这个宏用于把头文件包含到源文件中。
C++ 还支持很多预处理指令,比如 #include、#define、#if、#else、#line 等。
define 预处理指令用于创建符号常量。该符号常量通常称为宏:
#define PI 3.14159可以使用 #define 来定义一个带有参数的宏
#include
using namespace std;
#define MIN(a,b) (a 条件编译:
有几个指令可以用来有选择地对部分程序源代码进行编译。这个过程被称为条件编译。
条件预处理器的结构与 if 选择结构很像。
#ifdef NULL
#define NULL 0
#endif# 和 ## 预处理运算符
在 C++ 和 ANSI/ISO C 中都是可用的。# 运算符会把 replacement-text 令牌转换为用引号引起来的字符串。
#include
using namespace std;
#define MKSTR( x ) #x
int main ()
{
cout << MKSTR(HELLO C++) << endl;
return 0;
}
结果:HELLO C++ 当 CONCAT 出现在程序中时,它的参数会被连接起来,并用来取代宏。例如,程序中 CONCAT(HELLO, C++) 会被替换为 "HELLO C++"
#include
using namespace std;
#define concat(a, b) a ## b
int main()
{
int xy = 100;
cout << concat(x, y);
return 0;
} 预定义宏:
| 宏 | 描述 |
|---|---|
| __LINE__ | 这会在程序编译时包含当前行号。 |
| __FILE__ | 这会在程序编译时包含当前文件名。 |
| __DATE__ | 这会包含一个形式为 month/day/year 的字符串,它表示把源文件转换为目标代码的日期。 |
| __TIME__ | 这会包含一个形式为 hour:minute:second 的字符串,它表示程序被编译的时间。 |
#include
using namespace std;
int main ()
{
cout << "Value of __LINE__ : " << __LINE__ << endl;
cout << "Value of __FILE__ : " << __FILE__ << endl;
cout << "Value of __DATE__ : " << __DATE__ << endl;
cout << "Value of __TIME__ : " << __TIME__ << endl;
return 0;
}
Value of __LINE__ : 6
Value of __FILE__ : test.cpp
Value of __DATE__ : Feb 28 2011
Value of __TIME__ : 18:52:48 7 信号处理
信号是由操作系统传给进程的中断,会提早终止一个程序。在 UNIX、LINUX、Mac OS X 或 Windows 系统上,可以通过按 Ctrl+C 产生中断。
有些信号不能被程序捕获,但是下表所列信号可以在程序中捕获,并可以基于信号采取适当的动作。这些信号是定义在 C++ 头文件
| 信号 | 描述 |
|---|---|
| SIGABRT | 程序的异常终止,如调用 abort。 |
| SIGFPE | 错误的算术运算,比如除以零或导致溢出的操作。 |
| SIGILL | 检测非法指令。 |
| SIGINT | 接收到交互注意信号。 |
| SIGSEGV | 非法访问内存。 |
| SIGTERM | 发送到程序的终止请求。 |
C++ 信号处理库提供了 signal 函数,用来捕获突发事件。以下是 signal() 函数的语法:
void (*signal (int sig, void (*func)(int)))(int); 第一个参数是一个整数,代表了信号的编号;第二个参数是一个指向信号处理函数的指针。
#include
#include
#include
#include
using namespace std;
void signalHandler( int signum )
{
cout << "Interrupt signal (" << signum << ") received.\n";
// 清理并关闭
// 终止程序
exit(signum);
}
int main ()
{
// 注册信号 SIGINT 和信号处理程序
signal(SIGINT, signalHandler);
while(1){
cout << "Going to sleep...." << endl;
sleep(1);
}
return 0;
}
Going to sleep....
Going to sleep....
Going to sleep.... 现在,按 Ctrl+C 来中断程序,会看到程序捕获信号,程序打印如下内容并退出:
Going to sleep....
Going to sleep....
Going to sleep....
Interrupt signal (2) received.可以使用函数 raise() 生成信号,该函数带有一个整数信号编号作为参数,语法如下:
int raise (signal sig);sig 是要发送的信号的编号,这些信号包括:SIGINT、SIGABRT、SIGFPE、SIGILL、SIGSEGV、SIGTERM、SIGHUP。
#include
#include
#include
#include
using namespace std;
void signalHandler( int signum )
{
cout << "Interrupt signal (" << signum << ") received.\n";
// 清理并关闭
// 终止程序
exit(signum);
}
int main ()
{
int i = 0;
// 注册信号 SIGINT 和信号处理程序
signal(SIGINT, signalHandler);
while(++i){
cout << "Going to sleep...." << endl;
if( i == 3 ){
raise( SIGINT);
}
sleep(1);
}
return 0;
}
运行结果:
Going to sleep....
Going to sleep....
Going to sleep....
Interrupt signal (2) received.8 多线程
多线程是多任务处理的一种特殊形式,多任务处理允许让电脑同时运行两个或两个以上的程序。一般情况下,两种类型的多任务处理:基于进程和基于线程。
- 基于进程的多任务处理是程序的并发执行。
- 基于线程的多任务处理是同一程序的片段的并发执行。
多线程程序包含可以同时运行的两个或多个部分。这样的程序中的每个部分称为一个线程,每个线程定义了一个单独的执行路径。
对于 Linux 操作系统,我们要使用 POSIX 编写多线程 C++ 程序。POSIX Threads 或 Pthreads 提供的 API 可在多种类 Unix POSIX 系统上可用,比如 FreeBSD、NetBSD、GNU/Linux、Mac OS X 和 Solaris。
下面的程序,我们可以用它来创建一个 POSIX 线程:
#include
pthread_create (thread, attr, start_routine, arg) pthread_create 创建一个新的线程,并让它可执行。下面是关于参数的说明:
| 参数 | 描述 |
|---|---|
| thread | 指向线程标识符指针。 |
| attr | 一个不透明的属性对象,可以被用来设置线程属性。您可以指定线程属性对象,也可以使用默认值 NULL。 |
| start_routine | 线程运行函数起始地址,一旦线程被创建就会执行。 |
| arg | 运行函数的参数。它必须通过把引用作为指针强制转换为 void 类型进行传递。如果没有传递参数,则使用 NULL。 |
创建线程成功时,函数返回 0,若返回值不为 0 则说明创建线程失败。
使用下面的程序,我们可以用它来终止一个 POSIX 线程:
#include
pthread_exit (status) pthread_exit 用于显式地退出一个线程。通常情况下,pthread_exit() 函数是在线程完成工作后无需继续存在时被调用。
如果 main() 是在它所创建的线程之前结束,并通过 pthread_exit() 退出,那么其他线程将继续执行。否则,它们将在 main() 结束时自动被终止。
以下简单的实例代码使用 pthread_create() 函数创建了 5 个线程,每个线程输出"Hello Runoob!":
#include
// 必须的头文件
#include
using namespace std;
#define NUM_THREADS 5
// 线程的运行函数
void* say_hello(void* args)
{
cout << "Hello Runoob!" << endl;
return 0;
}
int main()
{
// 定义线程的 id 变量,多个变量使用数组
pthread_t tids[NUM_THREADS];
for(int i = 0; i < NUM_THREADS; ++i)
{
//参数依次是:创建的线程id,线程参数,调用的函数,传入的函数参数
int ret = pthread_create(&tids[i], NULL, say_hello, NULL);
if (ret != 0)
{
cout << "pthread_create error: error_code=" << ret << endl;
}
}
//等各个线程退出后,进程才结束,否则进程强制结束了,线程可能还没反应过来;
pthread_exit(NULL);
} 使用 -lpthread 库编译下面的程序:
$ g++ test.cpp -lpthread -o test.o得到结果:
$ ./test.o
Hello Runoob!
Hello Runoob!
Hello Runoob!
Hello Runoob!
Hello Runoob!以下简单的实例代码使用 pthread_create() 函数创建了 5 个线程,并接收传入的参数。每个线程打印一个 "Hello Runoob!" 消息,并输出接收的参数,然后调用 pthread_exit() 终止线程。
//文件名:test.cpp
#include
#include
#include
using namespace std;
#define NUM_THREADS 5
void *PrintHello(void *threadid)
{
// 对传入的参数进行强制类型转换,由无类型指针变为整形数指针,然后再读取
int tid = *((int*)threadid);
cout << "Hello Runoob! 线程 ID, " << tid << endl;
pthread_exit(NULL);
}
int main ()
{
pthread_t threads[NUM_THREADS];
int indexes[NUM_THREADS];// 用数组来保存i的值
int rc;
int i;
for( i=0; i < NUM_THREADS; i++ ){
cout << "main() : 创建线程, " << i << endl;
indexes[i] = i; //先保存i的值
// 传入的时候必须强制转换为void* 类型,即无类型指针
rc = pthread_create(&threads[i], NULL,
PrintHello, (void *)&(indexes[i]));
if (rc){
cout << "Error:无法创建线程," << rc << endl;
exit(-1);
}
}
pthread_exit(NULL);
}
$ g++ test.cpp -lpthread -o test.o
$ ./test.o
main() : 创建线程, 0
main() : 创建线程, 1
Hello Runoob! 线程 ID, 0
main() : 创建线程, Hello Runoob! 线程 ID, 21
main() : 创建线程, 3
Hello Runoob! 线程 ID, 2
main() : 创建线程, 4
Hello Runoob! 线程 ID, 3
Hello Runoob! 线程 ID, 4
向线程传递参数
连接和分离线程
我们可以使用以下两个函数来连接或分离线程:
pthread_join (threadid, status)
pthread_detach (threadid) pthread_join() 子程序阻碍调用程序,直到指定的 threadid 线程终止为止。当创建一个线程时,它的某个属性会定义它是否是可连接的(joinable)或可分离的(detached)。只有创建时定义为可连接的线程才可以被连接。如果线程创建时被定义为可分离的,则它永远也不能被连接。
9 Web编程
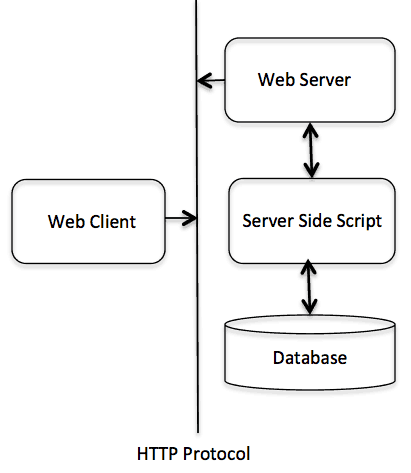
- 公共网关接口(CGI),是一套标准,定义了信息是如何在 Web 服务器和客户端脚本之间进行交换的。
- CGI 规范目前是由 NCSA 维护的,NCSA 定义 CGI 如下:
- 公共网关接口(CGI),是一种用于外部网关程序与信息服务器(如 HTTP 服务器)对接的接口标准。
- 目前的版本是 CGI/1.1,CGI/1.2 版本正在推进中。
公共网关接口(CGI),是使得应用程序(称为 CGI 程序或 CGI 脚本)能够与 Web 服务器以及客户端进行交互的标准协议。这些 CGI 程序可以用 Python、PERL、Shell、C 或 C++ 等进行编写。
其他的还有很多暂时用不到...最后说一下C++的资源库
1 STL标准模版库
C++ STL(标准模板库)是一套功能强大的 C++ 模板类,提供了通用的模板类和函数,这些模板类和函数可以实现多种流行和常用的算法和数据结构,如向量、链表、队列、栈。
C++ 标准模板库的核心包括以下三个组件:
| 组件 | 描述 |
|---|---|
| 容器(Containers) | 容器是用来管理某一类对象的集合。C++ 提供了各种不同类型的容器,比如 deque、list、vector、map 等。 |
| 算法(Algorithms) | 算法作用于容器。它们提供了执行各种操作的方式,包括对容器内容执行初始化、排序、搜索和转换等操作。 |
| 迭代器(iterators) | 迭代器用于遍历对象集合的元素。这些集合可能是容器,也可能是容器的子集。 |
这三个组件都带有丰富的预定义函数,帮助我们通过简单的方式处理复杂的任务。
C++ 标准库可以分为两部分:
- 标准函数库: 这个库是由通用的、独立的、不属于任何类的函数组成的。函数库继承自 C 语言。
- 面向对象类库: 这个库是类及其相关函数的集合。
标准函数库分为以下几类:
- 输入/输出 I/O
- 字符串和字符处理
- 数学
- 时间、日期和本地化
- 动态分配
- 其他
- 宽字符函数
标准的 C++ 面向对象类库定义了大量支持一些常见操作的类,比如输入/输出 I/O、字符串处理、数值处理。面向对象类库包含以下内容:
- 标准的 C++ I/O 类
- String 类
- 数值类
- STL 容器类
- STL 算法
- STL 函数对象
- STL 迭代器
- STL 分配器
- 本地化库
- 异常处理类
- 杂项支持库