1.drools是什么
Drools是为Java量身定制的基于Charles Forgy的RETE算法的规则引擎的实现。具有了OO接口的RETE,使得商业规则有了更自然的表达。
Rule是什么呢?
一条规则是对商业知识的编码。一条规则有 attributes ,一个 Left Hand Side ( LHS )和一个 Right Hand Side ( RHS )。Drools 允许下列几种 attributes : salience , agenda-group , no-loop , auto-focus , duration , activation-group 。
规则的 LHS 由一个或多个条件( Conditions )组成。当所有的条件( Conditions )都满足并为真时, RHS 将被执行。 RHS 被称为结果( Consequence )。 LHS 和 RHS 类似于
if(
}
下面介绍几个术语:
对新的数据和被修改的数据进行规则的匹配称为模式匹配( Pattern Matching )。进行匹配的引擎称为推理机( Inference Engine )。被访问的规则称为 ProductionMemory ,被推理机进行匹配的数据称为 WorkingMemory 。 Agenda 管理被匹配规则的执行。推理机所采用的模式匹配算法有下列几种: Linear , RETE , Treat , Leaps 。这里注意加红的地方,对数据的修改也会触发重新匹配,即对 WorkingMemory中的数据进行了修改。
然后规则引擎大概是这个样子的:
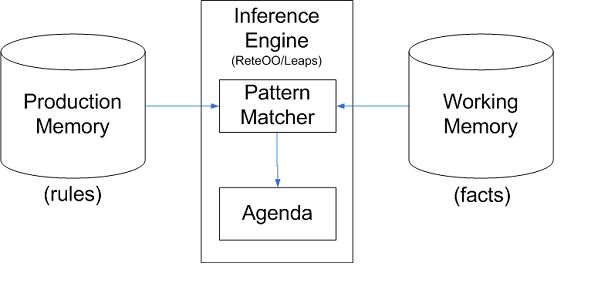
这个图也很好理解,就是推理机拿到数据和规则后,进行匹配,然后把匹配的规则和数据传递给Agenda。
规则引擎实现了数据同逻辑的完全解耦。规则并不能被直接调用,因为它们不是方法或函数,规则的激发是对 WorkingMemory 中数据变化的响应。结果( Consequence ,即 RHS )作为 LHS events 完全匹配的 Listener 。
数据被 assert 进 WorkingMemory 后,和 RuleBase 中的 rule 进行匹配(确切的说应该是 rule 的 LHS ),如果匹配成功这条 rule 连同和它匹配的数据(此时就叫做 Activation )一起被放入 Agenda ,等待 Agenda 来负责安排激发 Activation (其实就是执行 rule 的 RHS ),上图中的菱形部分就是在 Agenda 中来执行的, Agenda 就会根据冲突解决策略来安排 Activation 的执行顺序。
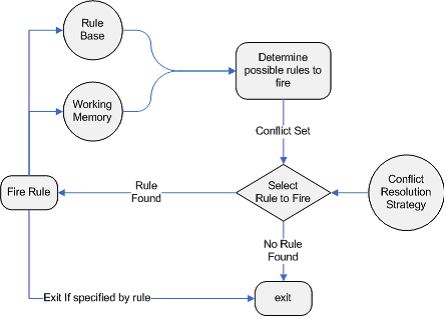
下面附上drools规则引擎的执行过程
2.rete算法
参考链接:Rete Algorithm
rete在拉丁文里是net network的意思,这个算法由 Charles Forgy 博士在他的博士论文里提到。
这个算法可以分为两个部分,一个是如何编译规则,一个是如何执行。原话(The Rete algorithm can be broken into 2 parts: rule compilation and runtime execution.)
rule compilation 就是如何通过对所有规则进行处理,生成一个有效的辨别网络。而一个辨别网络,则对数据进行过滤,使数据一步步往下传送。数据刚进入网络,有很多的匹配条件,这里可以理解为:逻辑表达式为true or false,然后在网络里往下传递的时候,匹配的条件越来越少,最后到达一个终止节点。
在这个论文里Dr Charles描述了这么几个节点,Node:
2.rete算法
参考链接:Rete Algorithm
rete在拉丁文里是net network的意思,这个算法由 Charles Forgy 博士在他的博士论文里提到。
这个算法可以分为两个部分,一个是如何编译规则,一个是如何执行。原话(The Rete algorithm can be broken into 2 parts: rule compilation and runtime execution.)
rule compilation 就是如何通过对所有规则进行处理,生成一个有效的辨别网络。而一个辨别网络,则对数据进行过滤,使数据一步步往下传送。数据刚进入网络,有很多的匹配条件,这里可以理解为:逻辑表达式为true or false,然后在网络里往下传递的时候,匹配的条件越来越少,最后到达一个终止节点。
在这个论文里Dr Charles描述了这么几个节点,Node:
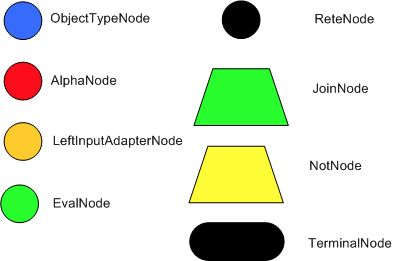
这里对其中的几个节点做一下简单介绍,另外说一下如何运作的。
- 首先,root node是所有的对象都可以进入的节点,也是辨别网络的一个入口,这个可以理解为一个虚节点,其实可能并不存在。
- 然后立马进入到ObjectTypeNode节点,这是一个对象类型节点。很明显,这里承载的是一个对象,可以理解为是java中的某个new Object(),在这个算法里,这个节点的作用就是为了保证不做一些无用功,什么无用功呢,就是不是对每个规则,进入的对象都要去辨别一遍,而是确定的对象类型,去做跟他相关的辨别,其实就是match。那么怎么做到呢?这里用到了一个hashMap,每次进入网络的对象,都会在这个map中通过hash,找到一个对应的辨别路径去辨别,即match。附上英文原文:(
Drools extends Rete by optimizing the propagation from ObjectTypeNode to AlphaNode using hashing. Each time an AlphaNode is added to an ObjectTypeNode it adds the literal value as a key to the HashMap with the AlphaNode as the value. When a new instance enters the ObjectType node, rather than propagating to each AlphaNode, it can instead retrieve the correct AlphaNode from the HashMap,thereby avoiding unnecessary literal checks.)
一个图来说明:
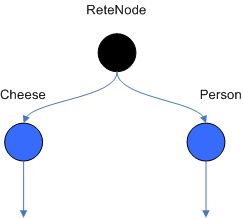
所有经过ObjectTypeNode的对象都会走到下一个节点,下一个节点可以是下面的几种:AlphaNodes, LeftInputAdapterNodes and BetaNodes。后面两个节点是AlphaNodes节点的一些变种,AlphaNodes节点是用来判断一些条件的。可以理解为一些逻辑表达式的计算。
下面开始上图:
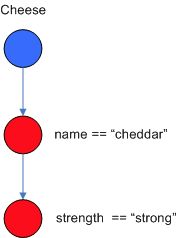
- 这个图就是传递进一个Cheese对象,然后依次判断是否满足条件:1.判断name是否是“cheddar”,2.如果判断1通过了,继续判断strength是否是strong。这是最简单了一种情况了,这里附上对应的规则描述,后面会继续讲解:
rule "cheessRule" when
$cheese:Cheese(name == "cheddar" && strength == "strong")
then
......
end
3.maven依赖
这里列了一些后面的一些例子需要用到的maven依赖
org.kie
kie-api
org.drools
drools-core
org.drools
drools-compiler
org.drools
drools-decisiontables
org.drools
drools-templates
4.规则文件:.drl or xls
我们一般用到的也就这两种形式,一个是drl文件,是drools规则引擎提供的最原生的方式,语法很简单,具体语法见
还有一个是决策表,决策表可以是xls也可以是csv,我们一般用xls比较多。而且好理解。xls就是一个excel文件。ps:在使用的过程中,遇到很多坑,其中一个最大的坑是mac系统的问题,这里后面会安利。
drl文件
首先来看下drl文件,这个在第2条讲解node的时候已经提到过了。
举例:
rule "ageUp12" when
$student: Student(age > 2)
then
$student.ageUp12();
end
rule "nameMax" when
$student: Student(name == "max")
then
$student.nameMax();
retract($student);
end
简单说明:以第一个rule为例
- package 定义了规则文件的一个命名空间,和java中的package无关。
- import 这里可以有多个,就是在规则文件里引用到的java类。
- rule 用来定义一个规则,这里名字不可重复,后面跟一个when关键字,翻译过来就是,规则 名ageUp12,当满足......
- when 和then之间是逻辑表达式,也就是辨别条件,其中$student:Student(age >2)这里其实包含了两个意思,一个是满足age>2的Student对象,一个是把这个对象赋值给$student变量,这样后面就可以引用这个变量了。逻辑表达式写在小括号里,如果是多个条件,可以用逗号分隔,如$sutdent :Student(age > 2,name=="max")
- then和end之间来定义action,即当满足age>2的时候,做什么操作,这里可以像在java方法里一样,调用任何一个java类的方法,只要import了这个类且在前面定义了这个变量
第二个例子可以看到有个retract($student),这里是用到了drools内部提供的一个函数,具体见后续关于drools语法介绍的博客
决策表(decisiontable)
决策表就是一个excel文件,可以是xls(xlsx暂不支持)或者csv是个表格,看上去也很直观,即便是不懂代码的人看了也能看懂,不像drl文件那么多语法。关键的一点是:decisiontable也是最终转成drl文件来让drools规则引擎来解析执行的。*.xls到*.drl的转换这个在后面的wiki会说到。
直接上图吧
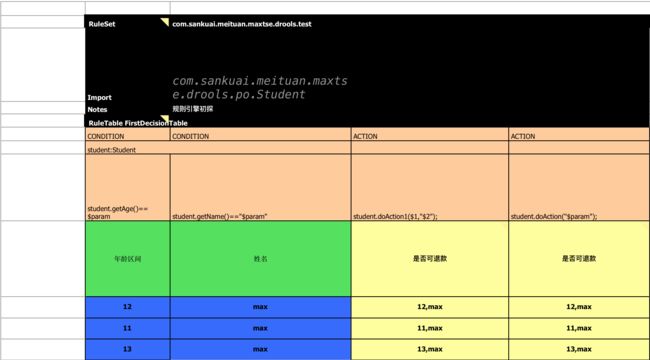
这里可以暂时忽略那些背景色,只是为了好区分没个模块的作用
这里忽略文件开始的空行,从有数据的第一行开始解释说明:
第一行,第一列:RuleSet 第二列。这里RuleSet可以省略的,累似drl文件中的package
第二行,第一列:Import 第二列具体的java类,这里和drl文件里的Improt相对应,多个引用类用逗号分隔
第三行,是个对这个决策表的说明
第四行,第一列:RuleTable FirstDecisionTable 这一行很关键 指明这是一个决策表,并且下面的几行都是具体的规则,就好比上面几行是一些准备条件,下面才是真正干活的地方,这里来个说明
第五行,CONDITION行,这一行可以有两种列名:CONDITION ACTION。CONDITION列就是drl里的辨别条件, ACTION则是具体的操作,即满足前面几列的CONDITION的条件后,会执行什么操作,这里CONDITION一定在ACTION前面,ACTION可以有多个列, 单个ACTION里的多个操作用逗号分隔,末尾要加分号结尾这里很重要,不然会有解析错误
第六行,紧挨着CONDITION的一行,可以在这里声明下面要用的到对象,对应drl文件里的$student:Student()
第七行,是辨别条件逻辑表达式,如:student.getAge()==$param则对应drl里的age==12这里$param是对应列每个单元格的值,然后这里需要特别说明下,针对于非字符串,如整数,小数等,可以直接使用$param,但是如果单元格里是字符串,则需要加双引号。(ps:mac里的双引号是斜的,一定要保证是竖着"的)另外,如果有多个值,可以用逗号隔开,然后可以用$1,$2提取变量值,如第一个ACTION里的student.doAction1($1,"$2")
第八行仍然是注释行,可以添加每一个CONDITON ACTION列的说明。
下面的每一行就是对应的某些条件的取值了。
参考:decisionTable