2018ECCV_Learning to Navigate for Fine-grained Classification
目录
摘要
引言
近期工作
细粒度分类 Fine-grained classification
物体检测 Object detection
排序学习 Learning to rank
方法
3.1 方法概述 Approach Overview
3.3 Scrutinizer
3.4 Network architecture
流程
监督
论文链接:https://openaccess.thecvf.com/content_ECCV_2018/papers/Ze_Yang_Learning_to_Navigate_ECCV_2018_paper.pdf
Pytorch代码链接:https://github.com/zxy14120448/NTS-Net
摘要
细粒度图像分类的挑战是找出判别力特征。为了处理这种情况,作者提出了自监督(self-supervision)机制,可以有效地定位信息区域,而无需边界框/部分标注(bounding box/part annotations)。
作者提出Navigator-Teacher-Scrutinizer Network,简写为NTS-Net,网络由Navigator agent,Teacher agent和Scrutinizer agent组成。
考虑到包含丰富信息的区域和其所属ground-truth类别的概率有内部一致性,作者设计了新的训练模式,从而使得Navigator能够在Teacher的指导下检测信息最丰富的区域(informative regions)。然后,Scrutinizer对Navigator生成的区域 (proposed regions)进行检查并作出预测。
提出的模型可以被视为一种多代理合作(multi-agent cooperation),其中agents彼此相互受益,共同进步。 NTS-Net可以端到端地进行训练,同时在推理过程中提供准确的细粒度分类预测以及更大的信息区域。
引言

图1. 模型框架。Navigator使得模型关注信息最丰富区域(表示为黄色矩形),Teacher评估Navigator生成的区域并提供反馈。然后,Scrutinizer对上述区域进行预测。
NTS-Net由Navigator agent,Teacher agent和Scrutinizer agent组成。具体来说:
Navigator对信息最丰富的区域进行关注: 对于图中的每个区域,Navigator预测区域信息的丰富度,并使用上述预测来找到最有信息的区域(most informative regions)。
Teacher评估Navigator生成的区域,并提供反馈:对每个建议区域(proposed region),Teacher评估其属于ground-truth类别的概率;置信度(confidence)评估利用ordering-consistenst损失函数,引导Navigator生成信息更加丰富的区域。
Scrutinizer审查Navigator生成的区域并做出细粒度分类:Navigator生成的每个建议区域扩展成相同的尺寸,Scrutinizer对其进行特征提取;区域的特征和整张图像的特征进行拼接,从而完成细粒度的图像分类。
上述过程类似于强化学习中的actor-critic机制(Actor-Critic的字面意思是“演员-评论”,相当于演员在演戏的同时有评论家指点继而演员演得越来越好),其中Navigator是actor,Teacher是critic。通过Teacher提供更加准确的监督,Navigator将会定位信息更加丰富的区域,这样,反过来也会使得Teacher受益。
论文贡献:
- 提出multi-agent协同学习策略,来解决在不使用bounding box/part annations情况下,细粒度分类任务中的准确定位最有信息区域的问题。
- 提出新的损失函数,使得Teacher通过强制区域的信息(regions' informativeness)和ground-truth类别概率的一致性,来引导Navigator定位图像中最有信息的区域。
- 提出了end-to-end的模型,其在推断阶段提供准确的细粒度分类预测和信息丰富的区域,并在benchmark上取得最优性能。
近期工作
细粒度分类 Fine-grained classification
细粒度分类旨在区分同一超类的从属类(subordinate classes),例如, 区分野生鸟类,汽车模型等。 挑战来源于找出信息区域(informative regions)和提取其中的判别特征(discriminative features)。因此,细粒度分类的关键在于开发自动方法以准确识别图像中的信息区域。
工作1:数据集提供bounding box/part annotations,因此,有些模型在训练和推断阶段充分利用这些标注信息。
而后,有些模型只在训练阶段使用bounding box/part annotations,对于这些模型,整个过程很像检测任务:即选择区域,然后对物体进行分类。
工作2:在训练和推断阶段,不需要bounding box/part annotations。
对于工作1的监督学习:利用细粒度的人工注释,如bird classification中鸟类部分的注释。虽然取得了不错的结果,但它们所需的 细粒度人工注释代价昂贵,使得这些方法在实践中不太适用。
对于工作2的无监督学习:学习规则定位信息区域,不需要昂贵的注释,但缺乏保证模型聚焦于正确区域的机制,这通常会导致
精度降低。
文章提出了一种新颖的自监督(self-supervision )机制,可以有效地定位信息区域而无需边界框/部分注释(bounding box/part annotations)。开发的模型称为NTS-Net,采用multi-agent cooperative学习方法来解决准确识别图像中的信息区域的问题。 直观地,被赋予地ground-truth class的概率较高的区域应该包含更多的对象特征语义,从而增强整个图像的分类性能。 因此,设计了一种新的损失函数来优化每个选定区域的信息量,使其具有与概率为ground-truth class相同的顺序,并且我们将完整图像的ground-truth class作为区域的ground-truth class。
物体检测 Object detection
早期工作:使用SIFT和HOG
近期工作:一些模型,例如R-CNN,OverFeat和SPPnet采用图像处理方法,首先生成目标建议框(object proposal),然后进行 类别分类和bounding box的回归。
一些模型,例如Faster R-CNN,提出Region Proposal Network(RPN),来生成建议框。后来,YOLO和SSD通过单阶段
框架(single-shot),提升了Faster R-CNN的速度。
一些特殊模型,例如Feature Pyramid Networks(FPN), 旨在解决多尺度问题,并从多个特征图中生成anchors。
排序学习 Learning to rank
排序学习的训练集元素列表都分配了顺序,而目标是学习元素列表的顺序。排序损失函数用来惩罚错误顺序对。
![]() 代表要排序的目标,
代表要排序的目标,![]() 代表目标的索引,其中,
代表目标的索引,其中,![]() 代表
代表![]() 的顺序在
的顺序在![]() 之前。
之前。![]() 代表排序函数的假设集。
代表排序函数的假设集。
排序方法主要分为三类:point-wise, pair-wise, list-wise approach
Point-wise方法:给每个数据分配分数,则learning-to-rank问题就转换成了回归问题,例如使用L2损失函数:
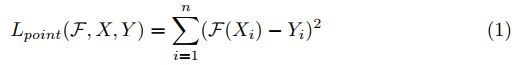
Pair-wise方法:learning-to-rank问题转换成了分类问题,即学习二分类器。假设![]() 只从
只从![]() 中取值,如果
中取值,如果![]() ,则
,则![]() 的排序要在
的排序要在![]() 前面。然后,损失定义在所有的数据对上,且目标是找到最优的
前面。然后,损失定义在所有的数据对上,且目标是找到最优的![]() ,来最小化错误顺序的图像对:
,来最小化错误顺序的图像对:

List-wise方法:优化整个列表,且在排列上可以转换为分类问题。![]() 表示排序函数,损失定义如下:
表示排序函数,损失定义如下:

本文方法中的Navigator损失采用multi-rating pair-wise排序损失,其强制区域的信息和ground-truth类别的概率一致。
方法
3.1 方法概述 Approach Overview
A:给定图像中的所有regions
I: 信息函数, ![]() ,用来评估区域的信息丰富度
,用来评估区域的信息丰富度
C :置信度函数, ![]() ,来评估某个区域属于ground-truth类别的置信度。
,来评估某个区域属于ground-truth类别的置信度。
条件1:
![]()
Navigator网络来近似信息函数 I
Teacher网络来近似置信度函数 C
为了满足条件1,应该优化Navigator网络,以使得![]() 和
和![]() 有相同的顺序。
有相同的顺序。
当Navigtator与Teacher网络不断优化时,生成的更加丰富的区域,会有助于Scrutinizer网络生成更好的细粒度分类结果。
3.2 Navigator and Teacher

图2. Anchors的设计。作者使用三个尺度和三个比率。对于尺寸448的图像,anchor有三个尺度{48,96,192}和比率{1:1, 2:3, 3:2}
如图2所示,一张图像输入到Navigator网络中,然后生成一簇矩形区域![]() ,每个区域都有一个得分,得分预示着区域的信息丰富度。
,每个区域都有一个得分,得分预示着区域的信息丰富度。
如公式4所示,对上述信息列表进行排序,其中,A代表anchors的数量,![]() 代表排序信息列表中的第i个元素。
代表排序信息列表中的第i个元素。
![]()
为了降低区域冗余,对region使用non-maximum suppression(NMS)。然后,将前M个informative regions![]() 送入Teacher网络,从而得到置信度
送入Teacher网络,从而得到置信度![]() 。
。
通过优化Navigator网络,以使得![]() 和
和![]() 有相同的顺序。
有相同的顺序。
每个建议区域通过最小化ground-truth class和predicted confidence之间的交叉熵损失(cross-entropy)来用于优化Teacher。
图3展示了M=3的整个流程,其中M是一个超参,表示了用来训练Navigator网络的区域个数。

图3. 训练Navigator网络的方法。对于一张输入图像,特征提取器提取深度特征图,然后,特征图输入到Navigator网络,用来计算所有区域的信息。使用NMS,来选择top-3(以3为例)的信息区域,并表示成![]() 。然后,从整张图像中裁剪出对应区域,并resize到预定义的尺寸,然后将他们送入Teacher网络,然后得到置信度
。然后,从整张图像中裁剪出对应区域,并resize到预定义的尺寸,然后将他们送入Teacher网络,然后得到置信度![]() 。通过优化Navigator网络,达到
。通过优化Navigator网络,达到![]() 和
和![]() 有相同顺序的目的。
有相同顺序的目的。
3.3 Scrutinizer
随着Navigator逐渐收敛,Navigator将会生成informative object-characteristic regions, 以帮助Scrutinizer做出更好的决策。
Scrutinizer的训练是使用前K个信息区域(informative regions)和整张图像的结合。
文章【25】已经证明,使用信息区域可以降低类内变化,并且在正确标签上更有可能生成更高的置信度分数。
3.4 Network architecture
为了使得region proposal和特征图中的特征向量一致,使用全卷积网络作为特征提取器,且抛弃全连接层。
特征提取器使用在ILSVRC2012数据集上与训练的Resnet-50.
Navigator network:
类似于Feature Pyramid Networks(FPN)结构【27】,如图4所示,在不同尺度Feature maps上生成多个候选框,每个候选框的坐标与预先设计好的Anchors相对应。Navigator做的就是给每一个候选区域的“信息量”打分,信息量大的区域分数高。
作者使用的特征图尺寸是{14×14,7×7,4×4},对应的区域尺度为{48×48,96×96,192×192}.

图4. 模型的推断阶段(以K=3为例)。首先,图像输入到特征提取器,然后Navigator网络从输入图像中提取出信息最丰富的区域;然后,从输入图像中裁剪上述区域,并resize到事先定义的尺寸;然后,使用特征提取器计算这些区域的特征;然后与输入图像的特征进行融合。最终,Scrutinizer网络处理融合的特征,并预测最终的标签。
Teacher network
就是普通的Feature extractor + FC + softmax,判断输入区域属于target lable的概率。
具体来说:
Teacher网络近似映射![]() ,并表示为每个区域的置信度。
,并表示为每个区域的置信度。
在收到来自Navigator网络的M个尺度归一化(224×224)的信息区域![]() 后,Teacher网络输出置信度来作为教师信号(teaching signals),来帮助Navigator网络学习。
后,Teacher网络输出置信度来作为教师信号(teaching signals),来帮助Navigator网络学习。
除了共享的特征提取器外,Teacher增加了2048神经元的全连接层。
Scrutinizer network
就是一个全连接层,输入是把“各个局部区域和全图提取出来的logits”concatenate到一起的一个长向量,输出对应200个类别的Logits。
具体来说:
收到Navigator网络的top-K个信息区域后,K个区域resize到预定义的尺寸(本文实验设置的224×224大小),然后送入特征提取器,以生成K个区域的特征向量,每一个向量的长度为2048.然后,将这些特征向量与输入图像的特征连接(concatenate),并送入到全连接层,全连接层有2048×(K+1)个神经元(如图4所示).
流程
1)尺寸(448,448,3)的原图进入网络,通过Resnet-50提取特征以后,变成一个(14,14,2048)的Feature map,还有一个经过Global Pooling之后2048维的Feature Vector和一个经过Global Pooling+ FC之后200维的Logits。
2)预设的RPN在(14,14)(7,7)(4,4)这三种尺度上根据不同的size, aspect ration生成对应的Anchors,一共1614个。
3)用步骤1中的Feature map,到Navigator中打分,用NMS根据打分结果只保留N个信息量最多的局部候选框。
4)把那N个局部区域双线性插值到(224,224),输入Teacher网络,得到这些局部区域的Feature vector和Logits。
5)把步骤1和4中的全图Feature vector和局部Feature vector给concatenate在一起,之后接FC层,得到联合分类Logits用于最终决策。

监督
1)普通的Cross-Entropy:步骤1中的全图logits, 步骤4中的part logits,步骤5中的concat logits都用label进行最简单的监督。
2)Ranking Loss: 步骤3中的信息量打分需要用步骤4中的分类概率进行监督,即对于4中的判断的属于目标label概率高的局部区域,必须在3中判断的信息量也高。
Navigator Loss:
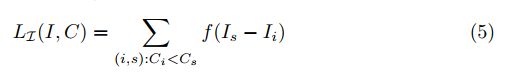
Navigator网络预测的M个信息区域为![]() ,对应的信息为
,对应的信息为![]() ,Teacher网络预测的置信度为
,Teacher网络预测的置信度为![]()
![]()
Teacher Loss:

C表示置信度函数,将region预测成类别概率,第一项是所有区域交叉熵损失的求和,第二项为整张图像(full image)的交叉熵损失。
Scrutinizing loss:使用交叉熵损失来作为分类损失
![]()
Joint training algorithm:![]()
![]()