NEON码农指导 Chapter 1 : Introduction
Translated from 《NEON Programmer’s Guide》
翻译可能有偏差,描述可能有错误,请以原著为准
本书为码农们提供了一份指导,以高效地使用NEON技术,NEON是ARM的先进SIMD(Single Instruction Multiple Data)架构扩展。本书提供的信息对汇编语言和C语言都是很有用的。
本书介绍了NEON技术,该技术已在实现ARMv7–A或ARMv7–R体系结构配置文件的ARM Cortex™-A系列处理器上使用。
注意
- 如果你完全是ARM小白,先看看Cortex-A系列的编程指导手册。
- NEON技术是ARM高级单指令多数据(SIMD)扩展的实现。
- NEON单元是处理器的组件,执行SIMD指令的。 也称为NEON媒体处理引擎(MPE)。
- 某些实现ARMv7–A或ARMv7–R体系结构配置文件的Cortex-A系列处理器不包含NEON单元。
1. Data processing technologies
1.1 Single Instruction Single Data
单指令单操作
每个操作指定要处理的单个数据,处理多个数据需要多条指令。下面的代码用4条指令把8个寄存器相加:
add r0, r5 @ 意思是r0 = r0 + r5
add r1, r6
add r2, r7
add r3, r8
这种方式很慢,并且很难看到不同寄存器之间是怎么关联的。为了提高效率和性能,媒体处理通常下放到不同的处理器,例如图形处理单元(Graphics Processing Unit、GPU)或者媒体处理单元(Media Processing Unit),这些单元可以通过单指令处理多个数据。
在一个32位ARM处理器上,处理大量的8位或者16位单独操作很难有效地利用机器资源,因为处理器、寄存器和数据路径都是为了32位的计算而设计的。
1.2 Single Instruction Multiple Data(vector mode)
SMID单指令多数据(向量模式)
一个操作可以指定对多个数据源进行相同的处理。 如果控制寄存器中的LEN值为4,则单个向量加法指令将执行四个加法:
VADD.F32 S24, S8, S16
// 以上操作产生4条加法:
// S24 = S8 +S16
// S25 = S9 +S17
// S26 = S10 +S18
// S27 = S11 +S20
尽管只有一条指令,但是它在4个步骤中按顺序执行了4次加法。
在ARM的术语中,这种叫做Vector Floating Point(VPF 向量浮点)。
向量浮点(VFP)扩展是在ARMv5架构中引入的,并执行了短向量指令以加快浮点操作。 源寄存器和目标寄存器可以是用于标量运算的单个寄存器,也可以是用于向量运算的两个至八个寄存器的序列。
由于SIMD操作比VFP操作更有效地执行向量计算(vector calculation),因此从ARMv7引入以来,向量模式操作已被弃用,并被NEON技术所取代,该技术对宽寄存器执行多种操作。
浮点(floating-point)和NEON使用公共寄存器组进行操作。
1.3 Single Instruction Multiple Data(packed data mode)
SIMD单指令多数据(打包的数据模式)
一个操作可以指定对存储在一个大寄存器中的多个数据字段进行相同的处理:
VADD.I16 Q10, Q8, Q9
// 这个操作把两个64位寄存器相加
// 但是把寄存器中每16位作为一个lane,寄存器中4个lane被分开单独相加
// 元素之间互不影响
就像图1那样,这一条指令对一个大寄存器的所有数据同时处理,这种方法更快。
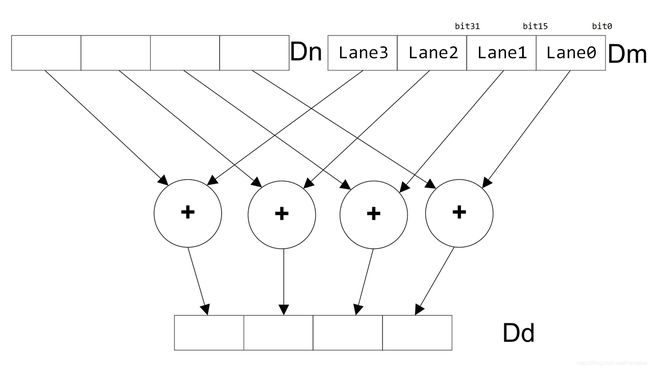
注意
- 图1的几个lane的加法是完全独立的。
- 任何来自第15位(在
lane0中)的溢出或者进位不会影响到第16位(在lane1中),因为每个lane是分隔开计算的 - 图1展示了1个64位寄存器持有4个16位的数据,分别为
lane0~lane3,NEON寄存器还支持其它的组合:- 单个64位寄存器中,同时操作2个32位、4个16位或8个8位整形数据。
- 在128寄存器中,同时操作4个32位、8个16位或者16个8位整形数据。
移动设备中使用的媒体处理器,通常将每个完整的数据寄存器分成多个子寄存器,并并行地对子寄存器执行计算。 如果对数据集的处理简单且重复很多次,则SIMD可以显着提高性能。 对于数字信号处理或多媒体算法,例如:
- 音频、视频、图像处理编解码器。
- 基于矩形像素块的2D图像。
- 3D图像。
- 颜色空间的转换
- 物理仿真。
2. Comparison between ARM NEON technology and other implementations
NEON技术和其它ARM或第三方数据处理之前的区别
2.1 Comparison between NEON technology and the ARMv6 SIMD instructions
NEON和ARMv6 SIMD指令集的区别
ARMv6体系结构引入了一个很小的SIMD指令集,这些指令对打包在标准32位ARM通用寄存器中的多个16位或8位值进行操作。 这些指令允许某些操作以两倍或四倍的速度执行,而无需添加其他计算单元。
ARMv6 SIMD指令UADD8 R0, R1, R2将一个32位寄存器中的四个8位值与另一个32位寄存器中的四个8位值相加,如图1-2所示。
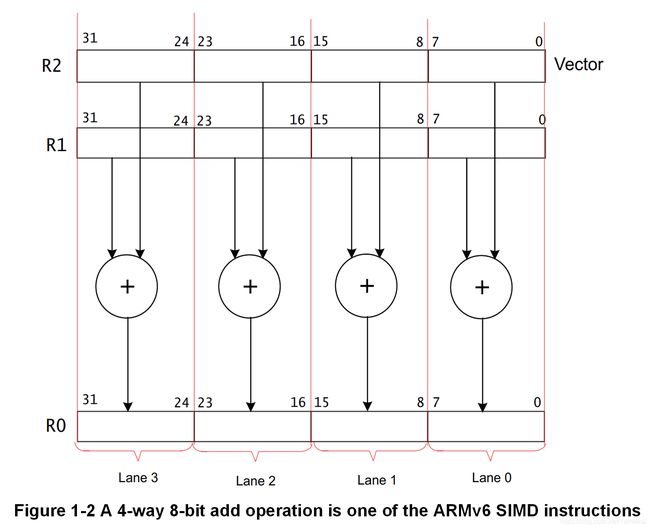
该操作对封装在32位寄存器R1和R2中的向量中的四个8位元素(element)(称为通道lane)执行并行加法运算,并将结果放入寄存器R0中的向量中。
ARM NEON技术基于SIMD的概念,并支持128位向量操作,而不是ARMv6体系结构中的32位向量操作。
Cortex-A7和Cortex-A15处理器中默认含有NEON单元,但在其他ARMv7 Cortex-A系列处理器中也可能有。
| 特性 | ARMv7 NEON 扩展 | ARMv6 SIMD 指令集 |
|---|---|---|
| 打包整形 | 8x8位,4x16位,2x32位 | 4x8位 |
| 数据类型 | 支持整数,如果处理器具有VFP单元,则支持单精度浮点运算 | 仅支持整数运算 |
| 并行操作 | 最多十六个(16 x 8位) | 最多四个(4 x 8位) |
| 专用寄存器 | 32个64位寄存器(或16个128位寄存器) 在与VFP单元共享的单独NEON寄存器文件上执行操作 |
使用32位通用ARM寄存器 |
| 流水线(Pipeline) | 具有专门为NEON执行而优化的专用流水线 | 使用与所有其他指令相同的流水线 |
2.3 Comparison between NEON technology and other SIMD solutions
NEON和其它SIMD的比较
SIMD处理不是ARM独有的,考虑其它的实现,并与NEON技术进行比较很有用。
| Neon | x86 MMX/SSE | Altivec | |
|---|---|---|---|
| 寄存器数量 | 32 x 64位 (或者视为16 x 128位) |
SSE2: 8 x 128-bit XMM (x86-32模式) x86-64模式下额外8个寄存器 |
32 x 128位 |
| 内存/寄存器操作 | 基于寄存器的3个操作数指令 | 寄存器和内存混合操作 | 基于寄存器的3和4操作数指令 |
| 打包数据的加载和存储 | 支持2、3、4个元素 | 不支持 | 不支持 |
| 在向量和标量寄存器之间移动数据 | 支持 | 支持 | 不支持 |
| 浮点支持 | 32位单精度 | 单精度或双精度 | 单精度 |
2.3 Comparison of NEON technology and Digital Signal Processors
NEON和数字信号处理器的区别
许多ARM处理器还集成了数字信号处理器(DSP),或自定义的信号处理硬件,因此它们可以同时包含NEON单元和DSP。 使用NEON技术与使用DSP有一些区别:
NEON的特点:
- 扩展ARM处理器流水线
- 使用ARM内核寄存器进行内存寻址。
- 单线程控制,可简化开发和调试。
- 支持操作系统多任务(如果操作系统保存或还原NEON和浮点寄存器文件)。
- SMP功能。 MPCore处理器中的每个ARM内核都有一个NEON单元。 通过使用多个内核,用标准的pthread可以提供标准性能的几倍性能。
- 作为ARM处理器体系结构的一部分,NEON单元将在未来更快的处理器上使用,并得到许多基于ARM处理器的SoC的支持。
- 开源社区和ARM生态系统均提供了广泛的NEON工具支持。
DSP的特点:
- 与ARM处理器并行运行。
- 没啥操作系统和任务切换开销,可以提供有保证的性能,但前提是DSP系统设计必须提供可预测的性能。
- 开发应用的程序猿很难用:有两个工具集,分别用单独的调试器,潜在的同步问题。
- 和ARM处理器的集成不太紧密。 在DSP和ARM处理器之间传输数据时,可能会有一些清除缓存或刷新缓存的开销,这会降低使用DSP处理非常小的数据块的效率。
3. Architecture support for NEON technology
NEON技术的架构支持
NEON扩展在某些处理器上被实现,这些处理器实现了ARMv7-A或ARMv7-R体系结构配置文件。
注意
- ARMv8体系结构扩展了对NEON的支持,并提供了与ARMv7实现的向后兼容性。
- 本手册仅涵盖实现了ARMv7-A和ARMv7-R的内核。
- 不保证您正在编程的ARMv7-A或ARMv7-R处理器包含NEON或VFP技术。 符合ARMv7的内核的可能组合为:
- 不存在NEON单元或VFP单元。
- 存在NEON单元,但没有VFP单元。
- 不存在NEON单元,但带有VFP单元。
- NEON单元和VFP单元都有。
- 处理器具有NEON单元,但没有VPF单元,无法在硬件中执行浮点运算。
- 由于NEON的SIMD操作可以更有效地执行向量计算,因此ARMv7的引入已不建议用VFP单元中的向量模式操作。 因此,VFP单元有时称为浮点单元(FPU)。
- 具有NEON或VFP单元的处理器可能不支持以下扩展:
- 半精度。
- 融合乘加。 - 如果存在VPF单元,则有些版本可以访问16或32个NEON双字寄存器
3.1 Instruction timings
指令时序
NEON体系结构未指定指令时序。 一条指令可能需要不同数量的周期才能在不同的处理器上执行。即使在同一处理器上,指令时序也会变化。 导致变化的一个常见原因是指令和数据是否保留在缓存中。
3.2 Support for VFP-only systems
对于仅含VFP系统的支持
一些指令是NEON和VFP扩展所共有的,这些称为共享指令。
注意
VFP和NEON单元都使用CP10和CP11协处理器的指令空间中的指令,并且共享相同的寄存器文件,这导致两种操作之间会产生混淆:
- VFP可以提供完全兼容IEEE-754的浮点运算,根据实现的不同,可以对单精度和双精度浮点值进行运算。
- NEON单元是用于整数和单精度浮点数据的并行数据处理单元,ARMv7 NEON单元中的单精度运算不完全符合IEEE-754。
- NEON单元不能代替VFP。 VFP提供了一些专门的指令,这些指令在NEON指令集中没有等效的实现。
但是,如果您的处理器同时具有NEON单元和VFP单元:
- 所有NEON寄存器与VFP寄存器重叠。
- 所有VFP数据处理指令都可以在VFP单元上执行。
- 共享指令可以在NEON浮点流水线(pipeline)上执行。
3.3 Support for the Half-precision extension
对于半精度扩展的支持
半精度指令仅在包含半精度扩展的NEON和VFP系统上可用。
半精度扩展(Half-precision extention)扩展了VFP和NEON体系结构。 它提供浮点和NEON指令,可在单精度(32位)和半精度(16位)浮点数之间执行转换。
3.4 Support for the Fused Multiply-Add instructions
对于融合乘加指令的支持
融合乘加指令是VFP和NEON扩展的可选扩展。 它提供了VFP和NEON指令,在执行乘法和加法时,带有一个的四舍五入步骤,因此与执行乘法随后执行加法相比,精度损失较小。
融合乘加指令仅在实现了融合乘加扩展的NEON或VFP系统上可用。 在VFPv4和先进的SIMDv2中包括对融合乘加指令的支持。
3.5 Security and virtualization
安全性和虚拟化
Cortex-A9和Cortex-A15处理器包括ARM安全扩展。 Cortex-A15处理器包括ARM安全扩展和虚拟化扩展。 这些扩展会影响您为NEON和VFP单元编写代码的方式。 这些扩展超出了本文的范围,有关更多信息,请参见《 ARM体系结构参考手册》 ARMv7-A和ARMv7-R。
3.6 Undefined instructions
未定义的指令
NEON指令(包括半精度和融合乘加指令)在不支持必要架构扩展的系统上,被视为未定义指令。
即使在具有NEON单元和VFP单元的系统上,如果未在CP15协处理器访问控制寄存器(CPACR)中启用这些指令,则这些指令也是被视为未定义的。 有关启用NEON和VFP单元的更多信息,请参见所编程处理器的《技术参考手册》。
3.6 Support for ARMv6 SIMD instructions
对于ARMv6 SIMD指令集的支持
ARMv6架构添加了许多SIMD指令,以有效地实现多媒体算法的软件。 ARMv7不推荐使用ARM6 SIMD指令。
4. Fundamentals of NEON technology
NEON技术基础
如果您熟悉ARM v7-A架构配置文件,您会注意到ARMv7内核是32位架构,并使用32位寄存器,但是NEON单元使用64位或128位寄存器进行SIMD处理。
之所以可以这样做,是因为NEON单元和VFP是ARMv7指令集的扩展,这些指令集在64位寄存器的单独寄存器文件中运行。 NEON和VFP单元完全集成到处理器中,并共享处理器资源以进行整数运算,循环控制和缓存。 与硬件加速器相比,这大大减少了面积并降低了功耗。 由于NEON单元使用与应用程序相同的地址空间,因此它还使用了更为简单的编程模型。
NEON组件的组件包括:
- NEON寄存器文件。
- NEON整数执行流水线(pipeline)。
- NEON单精度浮点执行流水线(pipeline)。
- NEON加载/存储和置换(permute)流水线(pipeline)。
4.1 Registers, vectors, lanes and elements
寄存器,向量,通道,元素
NEON指令和浮点指令使用相同的寄存器文件,称为NEON和浮点寄存器文件。 这与ARM核心寄存器文件不同。 NEON和浮点寄存器文件是一组寄存器的集合,可以将其作为32位,64位或128位寄存器进行访问。 一条指令可使用哪些寄存器取决于它是NEON指令还是VFP指令。 本文档将NEON和浮点寄存器称为NEON寄存器。 某些VFP和NEON指令在通用寄存器和NEON寄存器之间移动数据,或使用ARM通用寄存器来寻址存储器。
NEON寄存器的内容是相同数据类型的元素的向量。向量分为多个通道(lane),每个通道包含一个称为元素(element)的数据值。
通常,每个NEON指令都会导致n个操作并行发生,其中n是输入向量被划分为的通道(lane)数。 每个操作都包含在通道(lane)中。 从一个通道到另一个通道之间不会有进位或溢出。
NEON向量中的通道的数量取决于向量的大小以及向量中的数据元素:
64位NEON向量可包含:
- 8个8位元素。
- 4个16位元素。
- 2个32位元素。
- 1个64位元素。
128位NEON向量可包含:
- 16个8位元素。
- 8个16位元素。
- 4个32位元素。
- 2个64位元素。
Element ordering
元素的排列
图3显示向量中元素的顺序是从最低有效位开始的。 这意味着元素(element)0 使用寄存器的最低有效位。
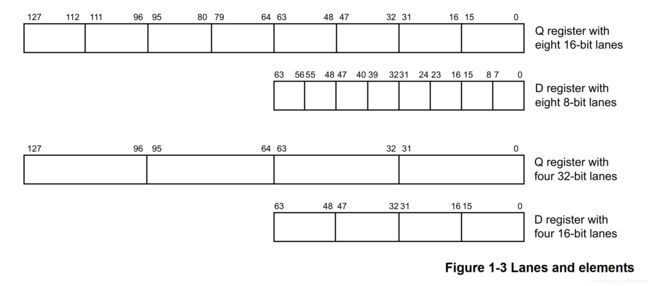
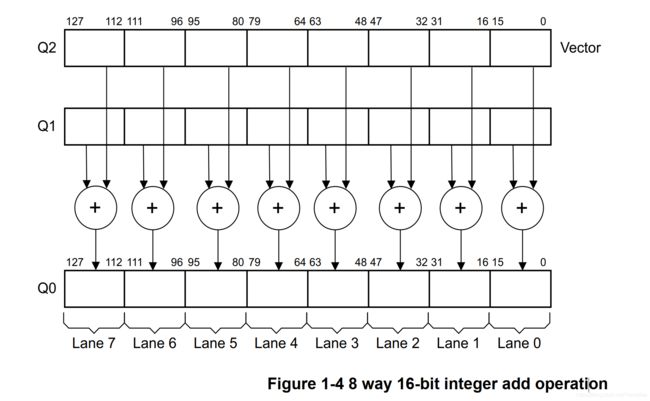
图4展示了VADD.I16 Q0, Q1, Q2指令如何从Q1和Q2中的向量执行八个通道的16位(8 x 16位 = 128位)整数(I)元素的并行加法,并将结果存储在Q0中。
Register overlap
寄存器重叠
图5显示了NEON和浮点寄存器文件,寄存器共享同样的内存,以不同的名称访问(Q或D或S)。
NEON单元把寄存器文件视作:
- 16个128位Q寄存器,或者叫四字寄存器,
Q0-Q15。 - 32个64位D寄存器,或者叫双字寄存器,
D0-D31。(在VFPv3-D16中是16个64位D寄存器)
D寄存器与Q寄存器的映射关系为为:D<2n>映射到Q的低位那半部分。D<2n+1>映射到Q的高位那半部分。
- Q和D寄存器的组合。
- NEON单元无法直接访问各个32位VPF S寄存器。
S寄存器的映射关系为为:S<2n>映射到D的低位那半部分。S<2n+1>映射到D的高位那半部分。

所有这些寄存器都可以随时访问。软件不必在它们之间进行显式切换,因为所使用的指令确定了访问形式。在图6中,S,D和Q寄存器是同一寄存器Q0的不同命名:
- NEON可以把
Q0当做128位寄存器来访问。 - NEON可以把
Q0当做2个连续的64位寄存器:D0和D1来访问。 - NEON不能单独
Q0里的32位S寄存器。但如果存在VPF单元,则可以将其作为S0,S1,S2和S3来访问。

Scalar data
标量数据
标量是指单个值,而不是包含多个值的向量。 一些NEON指令使用标量操作数。 寄存器内的标量通过索引访问值向量。 访问向量的各个元素的数组符号为 D m [ x ] Dm[x] Dm[x]或 Q m [ x ] Qm[x] Qm[x],其中 x x x是向量 D m Dm Dm或 Q m Qm Qm中的索引。
指令VMOV.8 D0[3], R3将寄存器R3的最低有效字节移至寄存器D0的第4字节。

NEON标量可以是8位,16位,32位或64位值。 除了乘法指令,访问标量的指令可以访问寄存器文件中的任何元素。
乘法指令仅允许使用16位或32位标量,并且只能访问寄存器文件中的前32个标量:
- 16位标量仅限于寄存器
D0[x]-D7[x],x的范围为0到3。 - 32位标量仅限于寄存器
D0[x]-D15[x],x为0或1。
4.2 NEON data type specifiers
NEON数据类型说明符
尽管ARM体系结构不需要处理器来实现VFP和NEON技术,但是这些扩展的编程中的共同功能意味着,支持VFP的操作系统只需很少或根本不需要修改,即可支持NEON技术。 但是,由于NEON单元在某些Cortex-A系列处理器中是可选的,因此您不能依靠NEON代码在所有处理器上均可工作。
在使用NEON或VFP指令并在给定处理器上编译代码之前,必须检查是否有NEON或VFP单元。
NEON和VFP指令中的数据类型说明符,由表示数据类型的字母组成。通常后跟表示宽度的数字。它们与指令助记符之间有一个点,例如VMLAL.S8。
| 8位 | 16位 | 32位 | 64位 | |
|---|---|---|---|---|
| 无符号整形 | U8 | U16 | U32 | U64 |
| 有符号整形 | S8 | S16 | S32 | S64 |
| 未指定类型的整数 | I8 | I16 | I32 | I64 |
| 浮点数 | 不可用 | F16 | F32 或 F | 不可用 |
| 多项式{0,1} | P8 | F16 | 不可用 | 不可用 |
多项式类型适用于在{0,1}上使用2次幂的有限域,或简单多项式的运算。
4.3 VFP views of the NEON and floating-point register file
实现ARMv7A和ARMV-7R体系结构的处理器,可包括以下的VFP扩展之一:
| 64位D寄存器 | 有半精度扩展 | 没有半精度扩展 |
|---|---|---|
| 16个 | VFPv3-D16-FP16 | VFPv3-D32 |
| 32个 | VFPv3-D32-FP16 (也叫做VFPv4,若带有融合乘加扩展) |
VFPv3-D32 (有时候就叫VFPv3,如果没有与其它扩展融合的可能) |
在 VFPv3-D16和VPFv3-D16-FP16版本中,VFP单元把NEON寄存器文件当成:
- 16个64位D寄存器
D0-D15,D寄存器被称为半精度寄存器,包含半精度浮点变量。 - 32个32位S寄存器
S0-S31,S寄存器被称为单精度寄存器,包含单精度浮点变量或者32位整形变量。
对于VPFv3-D16-F16,S寄存器可以包含半精度浮点值。 - 以上形式的寄存器组合。
在VFPv3,VFPv3-D32,和VFPv3-D32-FP16版本中,VFP单元把NEON寄存器文件当成:
- 32个64位D寄存器
D0-D31。 - 32个32位S寄存器
S0-S31,D0-D15与S寄存器S0-S31重叠。。
对于VPFv3-D16-F16,S寄存器可以包含一个半精度浮点值。 - 以上形式的寄存器组合。
注意
- 不同的访问形式表示半精度,单精度和双精度值,并且NEON向量同时共存于不同的非重叠寄存器中。
- 您还可以在不同时间,使用相同的重叠寄存器存储半精度,单精度和双精度值以及NEON向量。
表5显示了VFP指令集的可用数据类型。
| 16位 | 32位 | 64位 | |
|---|---|---|---|
| 无符号整形 | U16 | U32 | 不可用 |
| 有符号整形 | S16 | S32 | 不可用 |
| 浮点数 | F16 | F32 (或F) | F64 (或D) |