SpringBoot入门笔记07——Mybatis增删改查以及事务示例,打印sql
大纲
1、实现打印sql语句以及切换数据源
2、springboot 整合mybatis增删改查实例
3、整合事务示例(简单事务介绍)
1、实现打印sql语句以及切换数据源
(1)添加打印sql 配置
每次通过接口往数据库写入信息,如果我们想查看mybatis实际编译的sql语句,可以使用如下方法:
在配置文件application.properties 文件中添加如下代码
#增加打印sql语句,一般用于本地开发测试
mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl

(2)切换数据源
可以再配置文件中设置数据源,默认使用的是HikariDataSource ,我们也可以改为 阿里巴巴的 DruidDataSource数据源
配置文件如下:
#数据源
#如果不使用默认的数据源 (com.zaxxer.hikari.HikariDataSource)
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
如果使用阿里巴巴的数据源 需要在pom文件中添加依赖
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.1.6version>
dependency>
2、springboot 整合mybatis增删改查实例
直接上代码:
UserMapper类
package code.mapper;
import code.domain.User;
import org.apache.ibatis.annotations.*;
import java.util.List;
public interface UserMapper {
@Insert("insert into user(name,create_time,age,phone) values(#{name},#{createTime},#{age},#{phone})")
@Options(useGeneratedKeys = true,keyProperty = "id",keyColumn = "id")
int insert(User user);
/**
* 功能描述:查找全部
* @return
*/
@Select("SELECT * FROM user")
@Results({
@Result(column = "create_time",property = "createTime")
})
List<User> getAll();
@Select("SELECT * FROM user WHERE id=#{id}")
@Results({
@Result(column = "create_time",property = "createTime")
})
User findById(long id);
/**
* 功能描述:更新对象
* @param user
*/
@Update("UPDATE user SET name=#{name} WHERE id =#{id}")
void update(User user);
/**
* 功能描述:根据id删除用户
* @param userId
*/
@Delete("DELETE FROM user WHERE id =#{userId}")
void delete(long userId);
}
这里用到了几个注解@Insert、 @Select 、@Update 、@Delete 看名字就能看出来是增删改查的操作,然后后面跟上sql语句,没什么难的。
还有一个注解要注意下@Results ,当数据表的字段和 User 类的属性名称不完全一致的时候,需要说明下映射
比如这里,数据库user表是 create_time ,而user类使用的是驼峰命名,createTime,这个时候如果不添加映射,数据就写不进去。
@Results({
@Result(column = "create_time",property = "createTime")
//这里可以添加多个字段的映射
})
当然还可以设置id,因为如果多个地方都用到,每次写一遍就太麻烦了,所以,就写一次,声明id,然后直接引用id。这个看下面其他的例子把,下面贴一下网上总结的用法:
@Results用法总结
MyBatis中使用@Results注解来映射查询结果集到实体类属性。
(1)@Results的基本用法。当数据库字段名与实体类对应的属性名不一致时,可以使用@Results映射来将其对应起来。column为数据库字段名,porperty为实体类属性名,jdbcType为数据库字段数据类型,id为是否为主键。
@Select({"select id, name, class_id from my_student"})
@Results({
@Result(column="id", property="id", jdbcType=JdbcType.INTEGER, id=true),
@Result(column="name", property="name", jdbcType=JdbcType.VARCHAR),
@Result(column="class_id ", property="classId", jdbcType=JdbcType.INTEGER)
})
List<Student> selectAll();
如上所示的数据库字段名class_id与实体类属性名classId,就通过这种方式建立了映射关系。
(2)@ResultMap的用法。当这段@Results代码需要在多个方法用到时,为了提高代码复用性,我们可以为这个@Results注解设置id,然后使用@ResultMap注解来复用这段代码。
@Select({"select id, name, class_id from my_student"})
@Results(id="studentMap", value={
@Result(column="id", property="id", jdbcType=JdbcType.INTEGER, id=true),
@Result(column="name", property="name", jdbcType=JdbcType.VARCHAR),
@Result(column="class_id ", property="classId", jdbcType=JdbcType.INTEGER)
})
List<Student> selectAll();
@Select({"select id, name, class_id from my_student where id = #{id}"})
@ResultMap(value="studentMap")
Student selectById(integer id);
(3)@One的用法。当我们需要通过查询到的一个字段值作为参数,去执行另外一个方法来查询关联的内容,而且两者是一对一关系时,可以使用@One注解来便捷的实现。比如当我们需要查询学生信息以及其所属班级信息时,需要以查询到的class_id为参数,来执行ClassesMapper中的selectById方法,从而获得学生所属的班级信息。可以使用如下代码。
@Select({"select id, name, class_id from my_student"})
@Results(id="studentMap", value={
@Result(column="id", property="id", jdbcType=JdbcType.INTEGER, id=true),
@Result(column="name", property="name", jdbcType=JdbcType.VARCHAR),
@Result(column="class_id ", property="myClass", javaType=MyClass.class,
one=@One(select="com.my.mybatis.mapper.MyClassMapper.selectById"))
})
List<Student> selectAllAndClassMsg();
(4)@Many的用法。与@One类似,只不过如果使用@One查询到的结果是多行,会抛出TooManyResultException异常,这种时候应该使用的是@Many注解,实现一对多的查询。比如在需要查询学生信息和每次考试的成绩信息时。
@Select({"select id, name, class_id from my_student"})
@Results(id="studentMap", value={
@Result(column="id", property="id", jdbcType=JdbcType.INTEGER, id=true),
@Result(column="name", property="name", jdbcType=JdbcType.VARCHAR),
@Result(column="class_id ", property="classId", jdbcType=JdbcType.INTEGER),
@Result(column="id", property="gradeList", javaType=List.class,
many=@Many(select="com.my.mybatis.mapper.GradeMapper.selectByStudentId"))
})
List<Student> selectAllAndGrade();
还有一种更简单的方式来映射实体类
直接在清单文件中添加配置,就可以忽略驼峰命名参数
#数据库字段下划线和Java实体类映射
# mybatis 下划线转驼峰配置,两者都可以
#mybatis.configuration.mapUnderscoreToCamelCase=true
mybatis.configuration.map-underscore-to-camel-case=true
UserController类
package code.controller;
import code.domain.JsonData;
import code.domain.User;
import code.mapper.UserMapper;
import code.services.interfaces.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.Date;
import java.util.List;
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
UserService userService;
@Autowired
UserMapper userMapper;
@RequestMapping("/insert")
public Object insertUser(@RequestParam(required = true) String name, @RequestParam(required = true) int age, @RequestParam(required = true) String phone) {
User user = new User();
user.setName(name);
user.setAge(age);
user.setPhone(phone);
user.setCreateTime(new Date());
int id = userService.insert(user);
return new JsonData().buildSuccess(id);
}
@RequestMapping("/get_all")
public Object getAll(){
List<User> all = userMapper.getAll();
return new JsonData().buildSuccess(all,"200");
}
@RequestMapping("/find_by_id")
public Object findById(@RequestParam(name = "user_id",required = true) long id){
User byId = userMapper.findById(id);
return new JsonData().buildSuccess(byId,"200");
}
@RequestMapping("/delete")
public Object deleteById(int id){
userMapper.delete(id);
return new JsonData().buildSuccess();
}
@RequestMapping("/update")
public Object updateById(String name,int id){
User user=new User();
user.setId(id);
user.setName(name);
userMapper.update(user);
return new JsonData().buildSuccess();
}
}
3、整合事务示例(简单事务介绍)
事务简介
1、事务基本上分为单机事务 、分布式事务。我们常见的是单机事务,比如买东西付款,开启事务,一方扣款,一方收款,全部完成操作,此次事务才算解说。。如果是分布式事务就相当复杂了,多个数据库和服务器,所以需要用消息队列进行处理了。
2、讲解场景的隔离级别
Serializable: 最严格,串行处理,消耗资源大
Repeatable Read:保证了一个事务不会修改已经由另一个事务读取但未提交(回滚)的数据
Read Committed:大多数主流数据库的默认事务等级
Read Uncommitted:保证了读取过程中不会读取到非法数据。
3、讲解常见的传播行为
PROPAGATION_REQUIRED--支持当前事务,如果当前没有事务,就新建一个事务,最常见的选择。
PROPAGATION_SUPPORTS--支持当前事务,如果当前没有事务,就以非事务方式执行。
PROPAGATION_MANDATORY--支持当前事务,如果当前没有事务,就抛出异常。
PROPAGATION_REQUIRES_NEW--新建事务,如果当前存在事务,把当前事务挂起, 两个事务之间没有关系,一个异常,一个提交,不会同时回滚
PROPAGATION_NOT_SUPPORTED--以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
PROPAGATION_NEVER--以非事务方式执行,如果当前存在事务,则抛出异常
简单的开启事务实战。
我们使用最常见的传播行为,propagation=Propagation.REQUIRED
由于上面我们直接controller层调用mapper层,没有经过service层写代码,因为操作简单,所以没必要再写一遍。
现在我们试一下通过service层 添加事务
UserServiceImpl类中添加如下代码,,并且再UserService中已经添加了接口
@Override
@Transactional(propagation=Propagation.REQUIRED)
public int addAccount() {
User user = new User();
user.setAge(100);
user.setCreateTime(new Date());
user.setName("事务测试");
user.setPhone("110110110");
userMapper.insert(user);
int i = 100/0;
return 0;
}
上面代码是开启了事务,然后王数据库添加信息,然后执行异常,这样测试下数据库到底有没有写入信息。
UserController:
//测试事务
@GetMapping("transac")
public Object transac(){
int id = userService.addAccount();
return JsonData.buildSuccess(id);
}
运行程序,查看log和 数据表
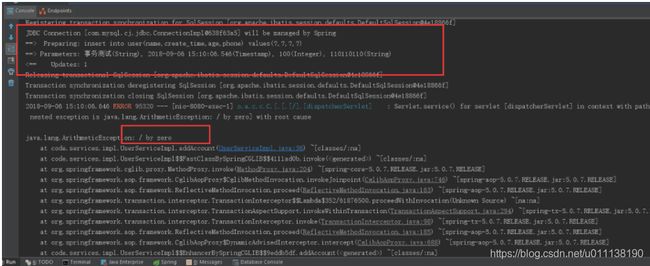
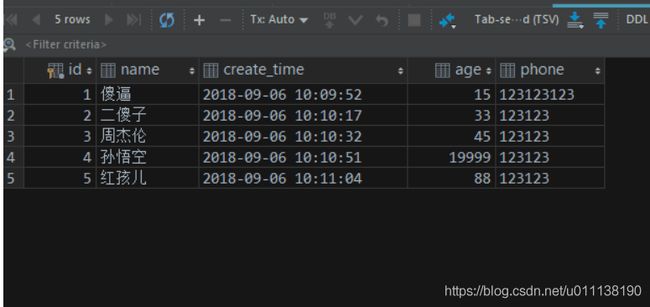
如果不加事务,虽然也会报错,但是确实已经执行了sql,写入了数据库
以上只是一个简单的增删该查的实例,可以直观的了解springboot整合mybatis,通过sql语句对数据库进行操作。