使用Verilog HDL语言实现4位超前进位加法器
一、1位半加器的实现
1.1 原理
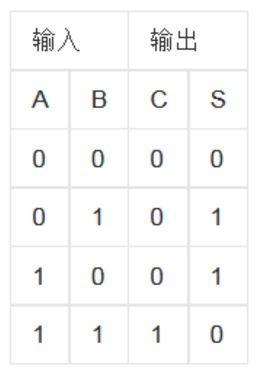
半加器由两个一位输入相加,输出一个结果位和进位,没有进位输入的加法器电路。
1.2 真值表
1.3 逻辑表达式
S = A ^ B
C = A & B
1.4 Verilog 实现
module half_adder(
input a,
input b,
output sum,
output c_out
);
assign sum = a^b;
assign cout = a&b;
endmodule二、1位全加器的实现
2.1 原理
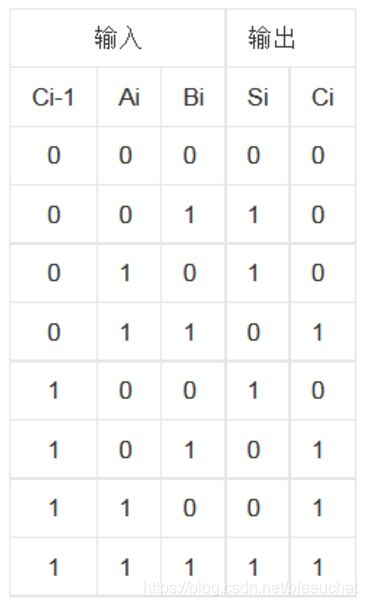
由两个1位的加数和一个进位作为输入,输出一个结果位和进位,与半加器相比,全加器不只考虑本位计算结果是否有进位,也考虑上一位对本位的进位。
2.2 真值表
逻辑表达式:
S=A^B^C
C=AB+(A^B)C
2.3 Verilog 实现
module full_adder(
input a,
input b,
input c_in,
output sum,
output c_out
);
wire sum1;
wire c_out1,c_out2;
half_adder half_adder1(.a(a),.b(b),.sum(sum1),.c_out(c_out1));//sum1=a^b c_out1=ab
half_adder half_adder2(.a(co),.b(sum1),.sum(sum),.c_out(c_out2));//sum=sum1^co c_out2=sum1 co
assign c_out = c_out1|c_out2;
endmodule三、4位串行加法器
3.1 原理
由4个1位全加器串联形成4位加法器,上一全加器的进位输出端作为下一全加器的进位输入端
3.2 原理图

Verilog 实现
例化四个1位全加器实现4位串行加法器
module add_4 (
input [3:0]a,
input [3:0]b,
input c_in,
output [3:0] sum,
output c_out
);
wire [3:0] c_tmp;
full_adder i0 ( a[0], b[0], c_in, sum[0], c_tmp[0]);
full_adder i1 ( a[1], b[1], c_tmp[0], sum[1], c_tmp[1] );
full_adder i2 ( a[2], b[2], c_tmp[1], sum[2], c_tmp[2] );
full_adder i3 ( a[3], b[3], c_tmp[2], sum[3], c_tmp[3] );
assign c_out = c_tmp[3];
endmodule四、4位超前进位加法器的实现
4.1 原理
对普通的全加器进行改良设计的并行加法器,主要针对普通全加器串联互相进位产生延迟而进行改良
Si =Ai ^ Bi^ Ci-1
Ci = AiBi + AiCi-1 + BiCi-1 = AiBi + (Ai+Bi)Ci-1
令 Gi=Ai*Bi ; Pi=Ai+Bi 代入Ci =AiBi + (Ai+Bi)Ci-1
得 Ci=Gi+Gi*Ci-1
C0 = C_in
C1=G0 + P0·C0
C2=G1 + P1·C1 = G1 + P1·G0 + P1·P0 ▪C0
C3=G2 + P2·C2 = G2 + P2·G1 + P2·P1·G0 + P2·P1·P0·C0
C4=G3 + P3·C3 = G3 + P3·G2 + P3·P2·G1 + P3·P2·P1·G0 + P3·P2·P1·P0·C0
C_out=C4
Verilog 实现4位超前加法器
module fastadd_4(
input[3:0] a,
input[3:0] b,
input c_in,
output[3:0] sum,
output c_out
);
wire[4:0] g,p,c;
assign c[0]=c_in;
assign p=a^b;
assign g=a&b;
assign c[1]=g[0]|(p[0]&c[0]);
assign c[2]=g[1]|(p[1]&(g[0]|(p[0]&c[0])));
assign c[3]=g[2]|(p[2]&(g[1]|(p[1]&(g[0]|(p[0]&c[0])))));
assign c[4]=g[3]|(p[3]&(g[2]|(p[2]&(g[1]|(p[1]&(g[0]|(p[0]&c[0])))))));
assign sum=p^c[3:0];
assign c_out=c[4];
endmodule进位选择加法器(carry select adder)
假如一个32位的加法器,如果采用等波纹进位加法器,设计思想就是前16级加法器的进位输出作为后16级加法器的进位输入,这样计算出32位相加的结果需要耗费两个16位数据相加的加法器时间;但如果如下设计:

也就是后16位数据的相加复制两份,不同的仅仅是进位不同,由前16位数据相加的进位来选择,所用的时间就会相对于等波纹进位加法器减少了一半;
module top_module(
input [31:0] a,
input [31:0] b,
output [31:0] sum
);
wire [15:0] sum1,sum2,sum3;
wire cout1;
add16 inst1_add16(
.a(a[15:0]),
.b(b[15:0]),
.cin(1'b0),
.sum(sum1),
.cout(cout1)
);
add16 inst2_add16(
.a(a[31:16]),
.b(b[31:16]),
.cin(1'b0),
.sum(sum2),
.cout()
);
add16 inst3_add16(
.a(a[31:16]),
.b(b[31:16]),
.cin(1'b1),
.sum(sum3),
.cout()
);
wire [15:0] sum4;
assign sum4 = cout1 ? sum3 : sum2;
assign sum = {sum4, sum1};
endmodule16bit的加法器可以采用4个4位的超前进位加法器进行级联,超前进位加法器的位数一般不会超过4位;