【万字详解】SQL 优化引擎内幕
本文首发于个人的知识星球,参考了网络上各类文章,感谢这些朋友们留下的宝贵材料和分享,让每个热爱 SQL 的人学到了更加深入的知识。本篇足足有 10945 字左右,大概需要花费半小时,感谢你的阅读!
以下是正文
SQL Server 的优化器是基于成本计算的,高质量的执行计划来自于对成本的准确估算。而整个计划成本的估算,则是基于对每一步操作或实现操作的每个算法的开销估算。
优化器总在寻找最优的计划,但无论计划是最优还是次优,最终的表现形式都是一棵语法树,挂满了各种操作符,用来从数据库结构中抓取相应的数据。随着查询涉及的表越多,可能的 Join 组合,操作逻辑组合也越多,要想穷尽这些组合,并合理评估计划的成本,显然是不合理的。优化器的作用就是在合理的时间范围内,找到可用的最优执行计划。
Statistics 帮助优化器实现基数估算(cardinality estimation)的各个方面,由三部分信息组成:柱状图,密度,字符统计(histogram, density, string statistics). 在接下来的文章中,我们将探讨如何建立 statistics 以及维护他们,如何找到哪些因为 statistics 不准确导致计划运行低效的查询。最后我们将一窥成本估算公式,它是如何估算每个操作的 I/O 以及 CPU 成本开销。
Statistics
Statistics 用来帮助优化器完成基数估算(cardinality estimation). 一次基数估算,算的是各种操作符,比如筛选,Join 条件,Group By 等返回的记录数,也可以称之为命中率(selectivity). 比如 ProductType 字段有三个可能的值:Phone, Pad, Laptop, 那么我们在此字段上加上一个条件筛选, ProductType='Phone',那么理想中的返回记录数应当是整个数据集的 1/3, 而实际中我们知道这概率是很小的,整个结果集的分布并不是正态分散的,取决于真实的情况。有可能 200 万条数据中 ,Phone 占了 150 万,Pad 占 20 万,Laptop 占 30 万,这样 selectivity 就分别是 150/200, 20/200, 30/200 了。这很明显,数据是有倾斜的。
创建和更新 statistics
有很多种方法可以建立 statistics, 比如当 AUTO_CREATE_STATISTICS 设置为 on 的时候,查询优化器会自动创建;当有新的索引创建时;也可以由用户输入命令 CREATE STATISTICS 显式创建。
Statistics 可以以单列,或者多列来创建。比如查询优化器只创建单列的 statistics, 索引或者显式命令则可以创建多列 statistics,当然也包括单列。由此可见,statistics 是数据库的对象,而不是依附于表或索引的属性。histogram, string statistics 都只为 statistics 的第一个字段而建,string statistics 还有个特点就是字段类型必须是 string 才能有效创建。Density 则会为组成的顺序列组合创建,假设 statistics 的列组合为 ProductID, SalesOrderID, SalesOrderDetailID, 那么 Density 则会为 ProductID, ProductID+ SalesOrderID, ProductID+ SalesOrderID+ SalesOrderDetailID都建立一组 Density.
statistics 的更新最有异议的地方在于,这些更新是否能自动完成。在有着频繁事务的数据库中,更新数据已经非常吃力了,还要自动更新 statistics 无疑带来更大的压力。而不更新 statistics 则会导致优化器生成不了最优的执行计划。所以如果是我来设计,也不会允许数据库自动更新 statistics, 或者留一个开关给用户,开不开启自动 statistics 更新交由他们去选择。
当 AUTO_UPDATE_STATISTICS 设置为 ON 的时候,无论是优化器隐式创建的,还是 CREATE STATISTICS 显示创建的 statistics 都会被自动更新。如果想要更自主的去控制更新窗口,也可以使用命令 UPDATE STATISTICS. 值得注意的是,rebuild index 的时候,也会自动更新在索引上面已经建立的 statistics.
当表或索引有新建的 statistics 或者 statistics 被更新的时候,原本涉及到这些表或索引的缓存起来的执行计划,都会被统统释放掉。由优化器重新根据新的 statistics 来新建一个执行计划。
对大数据量的表做 statistics 建立与更新都是件非常复杂的事情。如果需要实时更新 statistics 那就更加困难了,势必给 IO 带来很大的压力。因此 SQL Server 优化器总是使用表的抽样值来建立和更新 statistics. 这个抽样的数据量大小最小是 8MB, 不到这个数字就按表的实际数据量来算。当然,表越大,抽样的数据量也越大。
我们都知道,在统计学中,一旦进行了抽样,肯定会有失真。要保证绝对优质的 statistics, 我们需要更大量或者甚至全量来创建和更新它,比如在 CREATE/UPDATE STATISTICS 带上一个抽样值或者 WITH FULLSCAN 来做全量抽取。在新建一个索引时,必然会扫描整张表,那么由此新建的 statistics 也相当于是用了 WITH FULLSCAN,因此这份 statistics 绝对含有全量的数据分布统计。当 AUTO_UPDATE_STATISTICS 设置为 ON 的时候,原本全量统计的 statistics 可能会被优化器用抽样的方式自动置回去,导致 statistics 并不准确。因此是否自动更新 statistics 也是个值得商榷的事情。
默认情况下,查询优化器会等待 statistics 的自动更新完成,基于最新的 statistics 生成执行计划。这意味着在 statistics 没有自动更新完成前,查询是被优化器给阻塞住了。现在的高版本 SQL Server(2005 及以后) 带了一个特性 AUTO_UPDATE_STATISTICS_ASYNC, 在查询生成执行计划和 statistics 更新的同时,优先让位于查询生成执行计划,把 statistics 的更新延迟一会。
那么是不是查询一结束,被延迟的 statistics 更新就马上开始了呢。并不是!在 SQL Server 的内部,为每张表的每个字段定义了一个计数器(counter), 叫做 colmodctr. 这个计数器用来记录字段更新的次数(column modification counter). 有个简单的公式给 SQL Server 来判断 statistics 是否过期:
colmodctr > 500 + 20%*n
当表中的数据大于 500 行,且 statistics 组合字段的 colmodctr 数量大于 500 加总数的 20% 时,statistics 就被判断为过期。n 在这里是指整张表的数据量。colmodctr 通过 DAC(dedicated administrator connection) 连接服务器,查看 sys.sysrscols 就可见了。
观察 statistics 对象
statistics 说得那么玄乎,其实就是一个实实在在的数据库对象,类似一张小表,存储着各类数字信息。
使用 DBCC SHOW_STATISTICS 可以查看表中某字段的 statistics 信息:
DBCC SHOW_STATISTICS('Sales.SalesOrderDetail',UnitPrice)
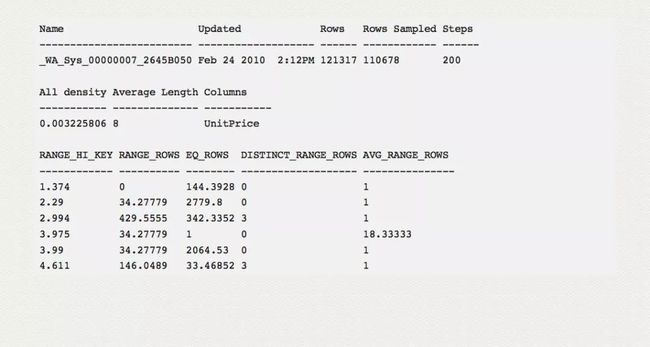
DBCC SHOW_STATISTICS 返回三个结果集,分别是:header, density vector 和 histogram. 如果只需要看其中之一,可以在命令后面分别加 WITH stat_header, WITH density vector , WITH histogram.
DBCC SHOW_STATISTICS('Sales.SalesOrderDetail',UnitPrice) WITH stat_header
DBCC SHOW_STATISTICS('Sales.SalesOrderDetail',UnitPrice) WITH density vector
DBCC SHOW_STATISTICS('Sales.SalesOrderDetail',UnitPrice) WITH histogram
有意思的是,header 中包含了 statistics 的名称, 以 _WA 开头,其实是 Washington, the state of the United Stats, 这里是 SQL Server 开发小组所在地。算是个彩蛋。
这里要注意的就是,当一个字段有其对应的 statistics 建立起来后,再看这字段的统计信息,就需要把字段名改成 statistics 对象名了。否则会出现错误信息:
Msg 2767,Level 16, State 1, Line 31
Could not locate statistics 'UnitPrice' in the system catalogs.
Density(密度)
Density 的定义是 1/(unique number of one field values), 即一个字段所有单值总数的倒数。所以我暂且定义其为密度。比如性别字段,共有男女两个单值,那么 Density 就为 0.5, 密度较高。比如部门字段,不会超过 100 个部门,所以 Density 为 0.01 密度低。单从密度来考量,密度越低,建索引的效果越好,命中率越高。
使用 DBCC SHOW_STATISTICS('Sales.SalesOrderDetail', IX_SalesOrderDetail_ProductID) 可以查看索引 IX_SalesOrderDetail_ProductID 的 Density.

IX_SalesOrderDetail_ProductID 有三个列组成,ProductID, SalesOrderID, SalesOrderDetailID. 每种顺序组合都计算了各自的 density. Density 越小放在前面越好,命中率越高。理论上是这样,但实际情况,往往是根据常用的维度来做查询,顺序需要按需调换。
使用 density 来做预估,有好的地方,也有不好的地方。
先讲下好的地方。当使用 GROUP BY 的时候,能非常迅速的估算出 GROUP BY 的单值,因为那就是 density 的倒数。比如上面的索引 IX_SalesOrderDetail_ProductID, ProductID 单值共有 266, density 就是 1/266, 约等于 0.003759399. 当用 GROUP BY 计算分组时,优化器马上就得出这分组共有 266 组。
SELECT ProductID
FROM Sales.SalesOrderDetail
GROUP BY ProductID
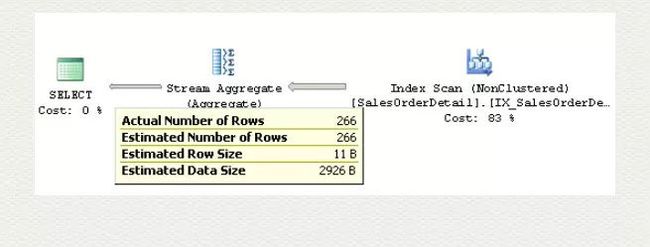
下面说说仅用 density 会产生哪些危害。
DECLARE @ProductID INT
SET @ProductID = 921
SELECT ProductID FROM Saels.SalesOrderDetail
WHERE ProductID = @ProductID
在编译时,优化器并不知道 @ProductID 的值,所以不能借助于 histogram, 而只能用 density. 估算值等于 density 乘以表记录总数,此例中为 0.003759399 * 121317, 约等于 456.079 :
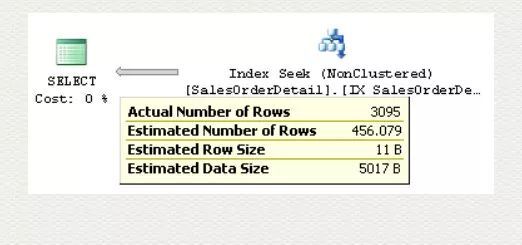
可见预估并不准确。当然换其他值也一样,比如 238,832 都是预估 456.079.
更为严重的是下面这种情况:
DECLARE @ProductID INT
SET @ProductID = 897
SELECT ProductID FROM Saels.SalesOrderDetail
WHERE ProductID lt @ProductID
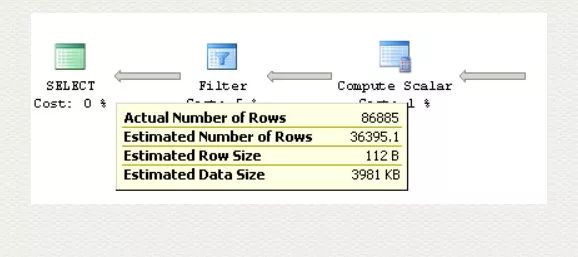
这情况下,并没有用 ProductID 的 density 0.003759399 来判断,而是直接用 30% 来预估(121317*0.3 = 36395.1),造成了很大的差异。
由此可见,当用本地变量 @ProductID时,优化器并不知道编译时的绑定值,只能根据 density 瞎猜,造成执行计划的误差。当编程时,应当尽量少用本地变量(local variable), 而用真实值,或者参数代替。那时,histogram 才能用到位。
Histograms(柱状图)
柱状图有个特性,就是只为statistics 对象的第一个字段建立。它浓缩了字段阈值的分布,用 buckets 或者 steps 来描述和计量数据的分布。针对字符字段,使用 buckets 聚合相同值,比如小学班级,每个班级一个 bucket, 每个 bucket 里面分多少人都是详细记录的;针对连续性数值字段,使用 steps 分层统计,比如产品ID (ProductID),从最高到最低,分成 200 个 steps 来统计每个层次,对应的人数或者岗位数等。
DBCC SHOW_STATISTICS('Sales.SalesOrderDetail', IX_SalesOrderDetail_ProductID)
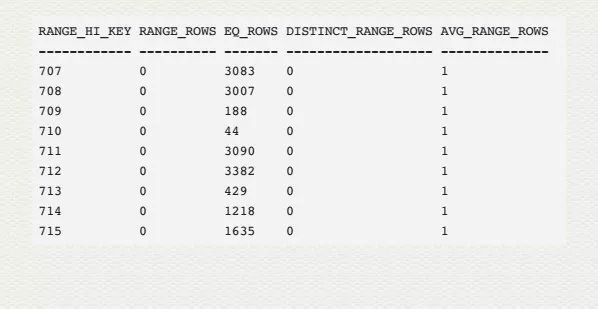
暂取下面这部分 histogram 数据来说事儿:
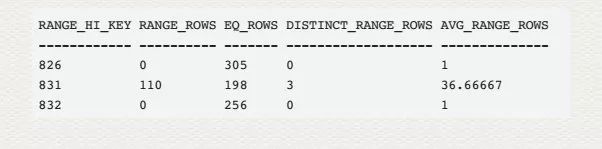
RANGE_HI_KEY: 这是分层连续数据的上界值,比如 826 往后一直到 831 都被放在了 831【RANGE_HI_KEY】这一档位中。
SELECT ProductID,COUNT(*) AS Total
FROM Sales.SalesOrderDetail
WHERE ProductID BETWEEN 827 AND 831
GROUP BY ProductID
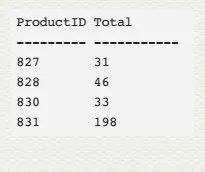
和 histogram 的结果集对比,正好解释了 RANGE_ROWS, EQ_ROWS , DISTINCT_RANGE_ROWS,AVG_RANG_ROWS 的值来源。
histogram 真正威力在这里。我们试用以下 ProductID 去测试:
SELECT *
FROM Sales.SalesOrderDetail
WHERE ProductID = 831
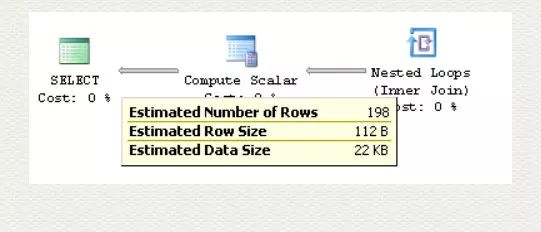
ProductID 831 正好是在边界上,histogram 记录了其对应的有 198 条记录拥有相同的 ProductID. 所以执行计划在预估数据量的时候,非常精确 Estimated Number of Rows 198.
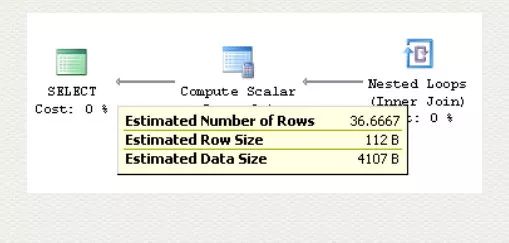
把 ProductID = 831 改为 ProductID = 828. 这次判断条件落入了 826 - 831 的范围内,平均预估值为 110/3, 约等于 36.667.
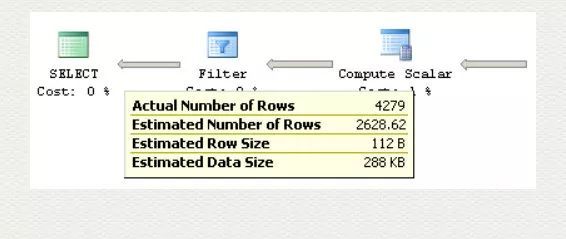
再试下不等于判断,改为 ProductID < 714:
此时就是简单的一个累加计算:
由此可知,只要编译时判断条件值确定,根据 histogram 即可估算出基数值。
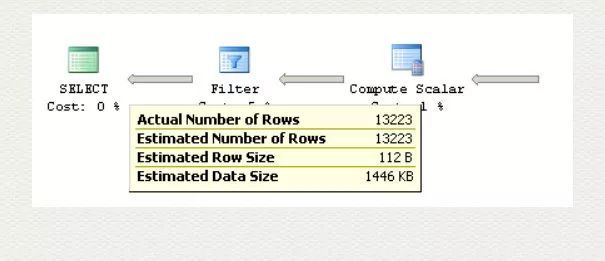
以上都是基于单个字段做查询条件时,优化器给的预估值。现在讨论下多个字段的预估,多个字段的组合逻辑上可分两种,一种为并(and)计算,一种为或(or)计算。
SELECT *
FROM Sales.SalesOrderDetail
WHERE ProductID = 870
AND OrderQty = 1
ProductID = 870, 查 histogram 表可知,总共有 4688 条数据,命中率(selectivity)为 4688/121317, 约等于 0.0386. 而 OrderQty = 1 ,同样查 histogram 可知,共 68024 条数据,命中率为 68024/121317, 约等于 0.5607. 依据统计学方法,两者的并集计算可以通过乘积得出。由此估算最终的记录数为 0.0386*0.5607*121317 ,为 2628.62.
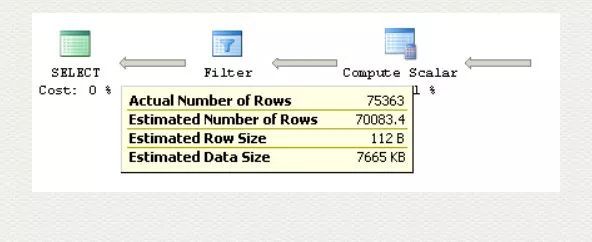
下面看下或计算:
SELECT *
FROM Sales.SalesOrderDetail
WHERE ProductID = 870
同样应用统计学方法,两集合相交,必有一部分是共有的,导致集合的合集会重复计算这部分。因此去掉这一部分重复计算的记录,便是或计算最终的合集部分。所以公式为 (4688+68024)- 2628.62,得到 70083.4
Statistics 的维护
默认情况下,查询优化器会自动更新已过期的 statistics. 过期的条件在前面的文章中也提到过,colmodctr>500+20%n 还记得这个公式吗?n 是指整张表的记录总数。手动更新 statistics 对象有两个方法,一是 UPDATE STATISTICS, 二是 sp_updatestats, 最后引用的还是 UPDATE STATISTICS.
维护 statistics 的最佳做法是选择一个维护窗口期,比如业务不繁忙的时刻。此时做 statistics 维护可以更全面的使用 FullScan 来维护更精确的 statistics, 并且让查询优化器可以优先处理执行计划的生成,而不用延迟。如果有大量数据做更新的时候,也应该在其后手工更新下 statistics.
当维护窗口期同时有 index 和 statistics 操作的时候,需要考虑的事情更多。Index 操作也会自动更新部分 statistics, 但也只更新 index 相关的 statistics 对象,而不会去更新表列 statistics. 我们始终要记住以下三点:
重建索引(Rebuilding an index): ALTER INDEX...REBUILD 会扫描所有表记录来更新 index statistics. 此时的效果与 UPDATE STATISTICS WITH FULLSCAN 一样。但重新索引并不会更新任何表字段的 statistics.
重构索引(Reorganizing an index):ALTER INDEX...REORGANIZE 既不更新任何的 index statistics,也不会更新表字段 statistics.
默认情况,UPDATE STATISTICS 可以更新 index statistics 和 字段的 statistics. 使用 INDEX 选项只更新索引字段的 statistics, 使用 COLUMNS 则只更新字段的 statistics.
同时维护 index 和 statistics 的时候,需要有策略。比如先把 index 维护好,再更新 statistics,有可能把已经 index statistics 维护好的结果,重新再刷了一遍,有些确实做了重复的工作。如果把简单的 statistics 维护(不是 FULLSCAN ) 放在后面,给 index statistics 就会造成一定的误伤,statistics 会做抽样更新,而 index 的维护却是全表扫描完成的。所以我们要严格控制,对字段 statistics 做到 FullScan 的更新, 而对 index statistics, 就需要通过重建索引来控制更新。而仅需做 index organizing 的索引,同样也要做FullScan 的更新。
涉及 index statistics 更新,还需要考虑 index 碎片问题。index 碎片不大的情况下, reorganizing 就够了,此时 index statistics 就不会被自动更新了。碎片化问题,可以通过查询 sys.dm_db_index_physical_stats.avg_fragmentation_in_percent 来解决。后面详说。
更新 statistics 命令:
UPDATE STATISTICS dbo.SalesOrderDetail WITH FULLSCAN, COLUMNS
UPDATE STATISTICS dbo.SalesOrderDetail WITH FULLSCAN, INDEX
UPDATE STATISTICS dbo.SalesOrderDetail WITH FULLSCAN, ALL
第一条命令,更新所有字段的 statistics; 第二条,更新所有索引;第三条:所有字段和索引都更新。
计算字段的 Statistics
当查询优化器在处理标量表达式(scalar expression)时,不能有效利用组成表达式的字段 statistics, 而只能采取 30% 命中率的猜测策略。而解决这种无效的优化时,使用 SQL SERVER 2005 引入的计算字段(computed column)则可以解决这类问题。优化器会自动创建和更新这类计算字段的 statistics.
过滤字段的 statistics ( Filtered Statistics)
当我们建一个过滤索引(filtered index)时,会在索引字段上自动创建 filtered statistics. 另一种方法是通过显式命令增加:CREATE STATISTICS ... WHERE. 过滤索引做的事情,本质上是将符合条件的记录,保存到索引当中,相当于提前做了条件查询。
这类特殊的 statistics 有其自身的优势。通过一个例子(数据库来源 AdvantureWorks)来了解下。
SELECT *
FROM Person.Address
WHERE City='Los Angeles'
上述的语句,执行计划会准确提示,预估的结果集是 93;
SELECT *
FROM Person.Address
WHERE StateProvinceID = 9
上述语句,执行计划也会准确提示,预估的结果集是 4564.
这里的 StateProvinceID , 9 对应的是 California 州的 ID. 而 Log Angeles 是 California 州的一个城市。City 和 StateProvinceID 在 Person.Address 表中,被称为 "Correlated Columns"(关联字段:大类字段与小类字段就可以看做是关联字段)。当关联字段一起作为条件查询时,则预估就失灵了。
SELECT *
FROM Person.Address
WHERE City='Los Angeles' AND StateProvinceID = 9
上面是两个关联字段 (Correlated Columns)组成的符合查询条件。此时我们看执行计划给出的预估记录数是 21.6403 了,是 (93 * 4564)/ 19614 的算术值(19614 是 Person.Address 的总记录数)。

这是因为组合条件查询,优化器是单独估算每个查询条件引用的字段独立的基数,再求其乘积。而这个例子里,显然最终结果应该是 93, 而预估了 21.6403,所以优化器在这里的估算是错误的。
纠正这类错误,Filtered Statistics 就派上用场了。
CREATE STATISTICS california
ON Person.Address(City)
WHERE StateProvinceID= 9
这里一定是大类(StateProvinceID)里添加小类(City). 删掉缓存重来一下:
DBCC FREEPROCACHE
GO
SELECT *
FROM Person.Addressnbsp
WHERE City='Los Angeles' AND StateProvinceID = 9
再看此时的执行计划,实际值与预估值都对了。
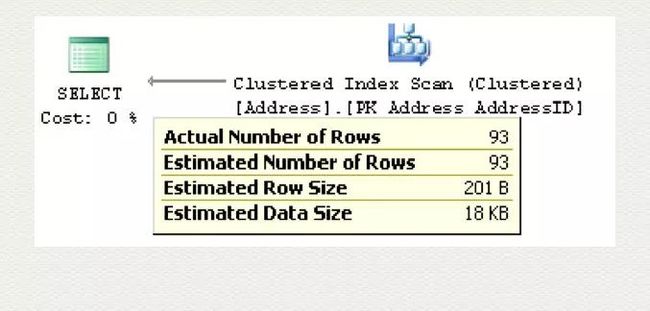
使用 SHOW_STATISTICS观察下新建的统计值对象:
DBCC SHOW_STATISTICS('Person.Address',california) WITH STAT_HEADER

这个结果集里面,最难以理解的就是 Unfiltered Rows. 这是指 Statistics 新建的时候,整张表有多少条记录。Filter Expression 和 sys.stats.filter_definition 字段同值,就是 statistics 的定义。
基数估算错误(Cardinality Estimation Errors)
查询优化器一直依赖精确的基数估算值来正确生成最优执行计划,所以基数一旦估算错误,整个执行计划就有 90% 的可能出现次优的情况,还有 10% 是巧合,碰对了最优计划。当然这是玩笑话,几率并没有那么精确,相对而言,错误的估算导致次优计划的概率,高一些。
SQL Server 提供了一些办法,帮我们找到基数是否估算错误。比如查看执行计划,对比 actual number of rows, estimated number of rows;或者通过 SET STATISTICS PROFILE ON:

如果 Rows 和 EstimateRows 相差太大,那么更新 statistics 就成了唯一可做的事情。
成本估算(Cost Estimation)
查询优化器总是在寻找最优的执行计划,这些计划的成本开销,最终是由一系列算法和基数估算综合得来的。基数的重要性前面讨论很多了,现在要讨论的是成本估算模型。不幸的是微软没有对外公开,他们的算法是建立在什么样的基础之上去估算成本的。但我们可以抓到一些小细节。
在微软官方提供的示例数据库 Advanture Works 有一张大表 Sales.SalesOrderDetail. 针对此表,我们可以找到一些操作的 CPU 以及 IO 成本。
SELECT *
FROM Sales.SalesOrderDetailnbsp
WHERE LineTotal = 35

上图中,我们要清晰两个指标 Estimated I/O Cost 以及 Estimated CPU Cost. 这两个指标之和就是 Estimated Operator Cost.
Estimated CPU Cost: 就图中的 Clustered Index Scan 操作来说,构成 CPU 成本的是: 找到第一条记录所花的成本 0.0001581, 加上其后每条记录的 0.0000011, 总计是 0.0001581 + 0.0000011*(121317-1) = 0.133606.
Estimated I/O Cost: 与 Estimated CPU Cost 不同的是,I/O 是以 database data page 为单位,第一个数据消耗了 0.003125,其后每个数据页(data page)会消耗 0.00074074, 共计 0.003125 + 0.00074074*(1234 - 1),约等于 0.916458.
Sales.SalesOrderDetail 总共有 1234 个数据页,通过下面的查询可以查询到:
SELECT in_row_data_page_count,row_count
FROM sys.dm_db_partition_stats
WHERE object_id =object_id('Sales.SalesOrderDetail')
AND index_id = 1
Estimated I/O Cost 加上 Estimated CPU Cost, 就是 Estimated Operator Cost, 1.05006. 将所有的操作成本加起来,就是整个执行计划的成本,最终查询优化器会选择成本最小的那个。
往期精彩文章
本号精华合集
知乎热文-数据分析师的出路在哪儿
回忆当年阿里的一道 SQL 面试题,亿级表合并