LZ77压缩
在huffman压缩中,对于字符不再使用定长编码。我们利用字符出现的次数之间的差异,对字符重新进行编码,使得出现次数多的字符编码短,而出现次数少的字符编码长,这样的话整体来说,需要的总的bit位数就会下降,以此来达到压缩的目的。可见,在这种情况下,如果字符出现的次数大致都相等的话,就起不到压缩的效果了,这也就是huffman为什么不能进行二次压缩的原因,因为压缩一次之后,会使得所有字符出现的次数相差不大。
huffman是建立在静态字典模型的基础上的,但是静态模型的自适应性不是很强,我们必须为不同的信息建立不同的字典,其次我们还必须要维护这些字典。
下面介绍一种采用自适应的字典模型算法,LZ77算法。LZ77算法采用自适应的字典模型,也就是将已经编码的信息作为字典,如果要编码的字符串曾经出现过,就输出该字符串的出现位置以及长度,否则输出新的字符串。
zip压缩算法是从LZ77算法演变过来的。下面我们注重介绍LZ77算法。
LZ77算法使用”滑动窗口”的方法,来进行字符串的匹配。它的核心思想是在前面已经出现过的数据中找重复出现的字符,根据局部性原理,如果一个字符串要重复,那么也是在附近重复,远的地方就不用找了,因此设置了一个滑动窗口,每次都在这个窗口里面找重复出现的字符。关于这个滑动窗口的大小,理论上是窗口越大,重复的可能性越大,压缩的效率越高,但是窗口太大的话,查找的效率也会降低,所以窗口的设置必须合理。LZ77算法中设置滑动窗口的大小为32k。
通常我们在使用压缩软件的时候,会让我们选择最快压缩和超高压缩那种模式,我猜想这两种模式和窗口的大小设置有关
LZ77算法原理:

可以看到,一段字符串最终可以表示成literal、distance+length的形式,以此来达到压缩的目的。
LZ77算法的实现:
1、经过LZ77算法后,一段字符串可以表示为”原文和距离+长度”的形式,那么在解压缩的时候,我们如何区分”原文”和”距离+长度呢”呢?我们可以在每一个字符后面都加一个bit的标志位用于区分”原文”和”距离+长度”,这个bit位为0表示原文,为1表示”长度+距离”。当然这个方法并不是唯一的。
2、由于滑动窗口只有32k,如果我们对距离采用定长编码的话,最多用两个字节就可以表示。
3、对于重复的长度我们也采用定长编码,并且规定最多一次匹配255个字符。这样的话用一个字节就可以表示。
4、由于”距离+长度”我们使用了3个字节表示,所以当重复的字节数大于等于3的时候,才不会导致我们越压越大。
当然zip压缩远远不止这些内容,在zip中还对distance、length利用huffman树进行了重新编码,整个过程是非常复杂的。
算法分析:
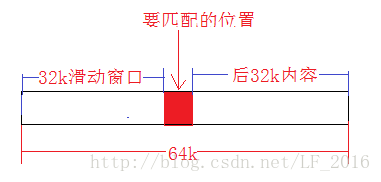
1、在滑动窗口匹配数据的时候,我们可以将数据加载到内存中再进行匹配。但是如果只使用32k的窗口的话,每一次匹配字符串我们都必须将前32k的内容重新加载一次,这样的话效率简直太低了。为此,我们可以使用64k的缓存,将要匹配的位置的前32k和后32k内容都读到缓存中,这样的话,我们每处理32k的内容才读一次数据,效率能提高不少。
实现:
//代码…
测试:
在huffman文件压缩下:
压缩一个1.2M左右的文件,能够到压缩0.9M左右,用时0.5秒左右。
压缩一个2.3M左右的文件,能够到压缩1.8M左右,用时0.8秒左右。
压缩一个8.3M左右的文件,能够到压缩6.7M左右,用时3秒。
在上面实现的LZ77算法下:
压缩一个1.2M左右的文件,能够到压缩0.6M左右,用时30秒左右。
压缩一个2.3M左右的文件,能够到压缩1.3M左右,用时1分钟左右。
压缩一个8.3M左右的文件,能够到压缩4.6M左右,用时4分钟左右。
不得不承认,上面实现的算法效率简直太低了,虽然压缩出来的效果还可以,但是这个压缩时间简直是慢的让人难以忍受。这主要是我们在匹配字符串的时候浪费了大量的时间,因此我们要想提高效率的话,可以使用一些匹配算法。
算法扩展:
1、由于我们增加了一个bit位用来区分”原文”和”距离+长度”,所以最极端的情况下,假设不会出现任何重复的字符,这时我们无形中就增加了八分之一的开销。导致数据不仅没能被压缩,反而被增大。这种情况下就不能使用上面的算法进行压缩了,而应该使用其他算法,比如huffman算法,或者直接不压缩。
2、当我们匹配字符串的时候,如果采用顺序搜索的话,效率会降低不少,所以我们可以为滑动窗口的数据建立索引,然后采用hashtable来进行匹配查找。
3、还有就是,我们如何在窗口中匹配重复长度最长的字符串,因为如果匹配的字符串的长度越长的话,压缩的效率越高。
4、在对”距离+长度”进行编码的时候,不要采用定长编码,我们可以向zip一样,使用huffman树进行变长编码。
//代码
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once
#includeif (ch == EOF)
break;
_windows.push_back(ch);
}
_frist = OFFSET1; //记录加载到窗口的数据的起始位置
_last = _windows.size() + OFFSET1;
}
int length = GetRepetionlength(fInput, distance, OFFSET1);
return length;
}
int GetRepetionlength(FILE *fInput, long& distance, long pWindowsPos) //得到重复的长度
{
long OFFSET = ftell(fInput); //得到要比较的字符的位置
vector<unsigned char> v;
if (Getch(fInput, v) == false)
return 0;
size_t size = OFFSET - pWindowsPos;
size_t index = pWindowsPos - _frist;
int length = 0;
for (; indexif (_windows[index] == v[0])
{
size_t flag = index;
size_t i = 0;
while ((flag < size) && (length<255))
{
if (i == v.size() - 1)
{
if (Getch(fInput, v) == false)
break;
}
if (_windows[flag] == v[i])
{
length++;
flag++;
i++;
}
else
break;
}
if (length >=3)
{
distance = OFFSET - (index + _frist);
return length; //如果重复出现的字符的长度大于3,则就返回重复长度
}
length = 0;
}
}
return 0;
}
bool Getch(FILE *fInput, vector<unsigned char>& v)
{
int ch = 0;
ch = fgetc(fInput);
v.push_back(ch);
if (ch == EOF)
return false;
else
return true;
}
private:
vector<unsigned char> _windows;
size_t _frist;
size_t _last;
};