关于Python2.X与Python3.X的编码问题
关于Python2.X与Python3.X的编码问题
一、Python2.X中的encode和decode
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转换成unicode编码,如str.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。
encode的作用是将unicode编码转换成其他编码的字符串,如str.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。
因此,转码的时候一定要先搞明白,字符串str是什么编码,然后decode成unicode,然后再encode成其他编码,用非unicode编码形式的str来encode会报错。
如果一个字符串已经是unicode了,再进行解码则将出错,因此通常要对其编码方式是否为unicode进行判断:
isinstance(s, unicode) #用来判断是否为unicode import sys
printsys.getdefaultencoding()
# -*- coding:utf-8 -*- 我们来看实验和结果:
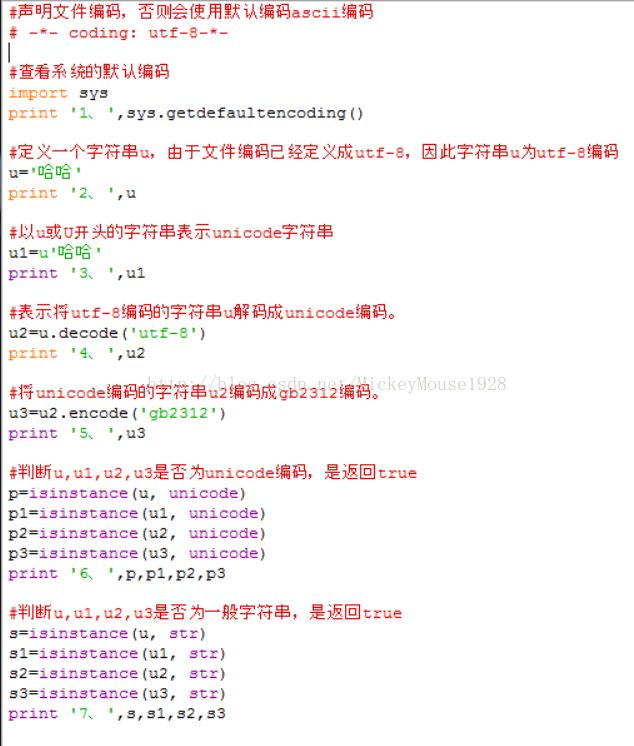
结果如下:
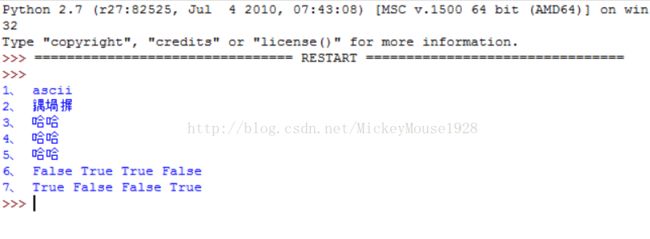
可见输出的第2列,中文为乱码,因为windows默认采用GBK编码,解释器也是用GBK去解码的,如果你在文件中指定了必须用utf-8编码,而不对解释器指定解码格式,用GBK去解码UTF-8,当然就会出现乱码。
而第5列“gb2312”为什么没有出现乱码呢,这是因为GB2312是中国规定的汉字编码,也可以说是简体中文的字符集编码;GBK 是 GB2312的扩展 ,除了兼容GB2312外,它还能显示繁体中文,还有日文的假名。
如何将字符串转换为unicode?很简单,直接使用decode()即可。而我们平时遇见unicode编码形式的字符串如何转换成中文,只需使用decode("unicode_escape")进行反解码,为了深刻理解其中的过程,我将简单问题复杂化,写了两个python文件:
CodingExchange.py,定义了两个函数,其实用到的只是decode()方法:

ceshi.py,调用CodingExchange模块,直接使用CodingExchange.py中定义的函数:
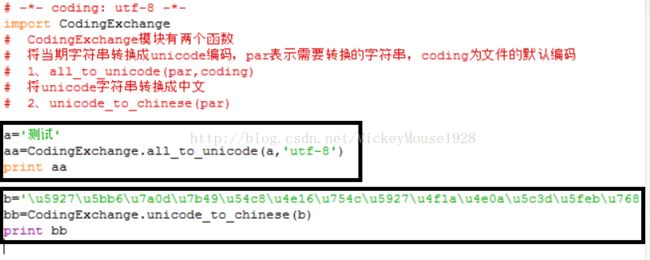
图上的字符串b是将中文转换成Unicode得到的,方便我们与运行结果进行比对。

将CodingExchange.py和ceshi.py放在同一目录下:

运行ceshi.py的结果如下: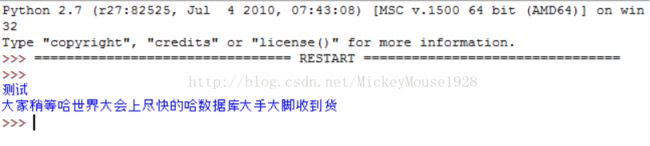
如果我如下所示修改ceshi.py:
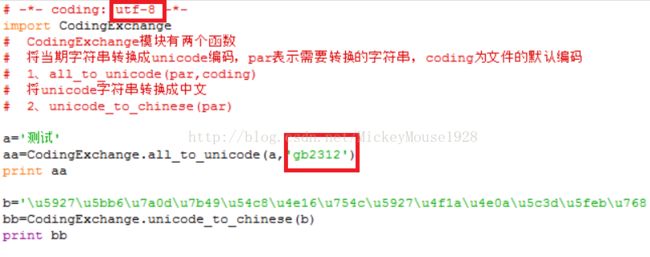
结果发生错误UnicodeDecodeError(Unicode 解码时的错误):
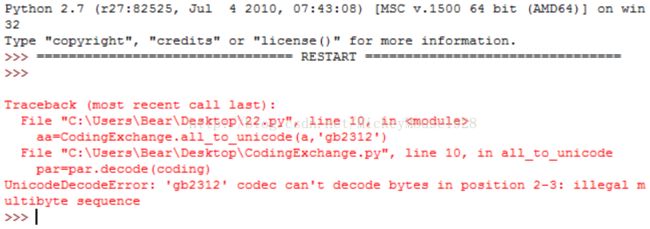
因此,我们在对字符串解码的时候一定要分辨字符串的编码格式,如果是utf-8的编码,则使用decode('utf-8'),如果是gb2312的编码,则使用decode('gb2312')。
二、Python3中的encode和decode
Python3中字符编码经问题已经得到了很好的解决,encode的作用,使我们看到的直观的字符转换成计算机内的字节形式。decode刚好相反,把字节形式的字符转换成我们看的懂的、直观的、“人模人样”的形式。如下图

运行结果如下:

Python3的源码.py文件的默认编码方式为UTF-8,将字符串从一种编码转换到另一种编码,不再需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
而且,encode与decode的作用也与Python2有所差异,encode将我们看到的直观的字符转换成计算机内的字节形式,decode则把字节形式的字符转换成我们看的懂的、直观的的字符。