爬取新浪微博评论及点赞数并存储为excel的.csv格式
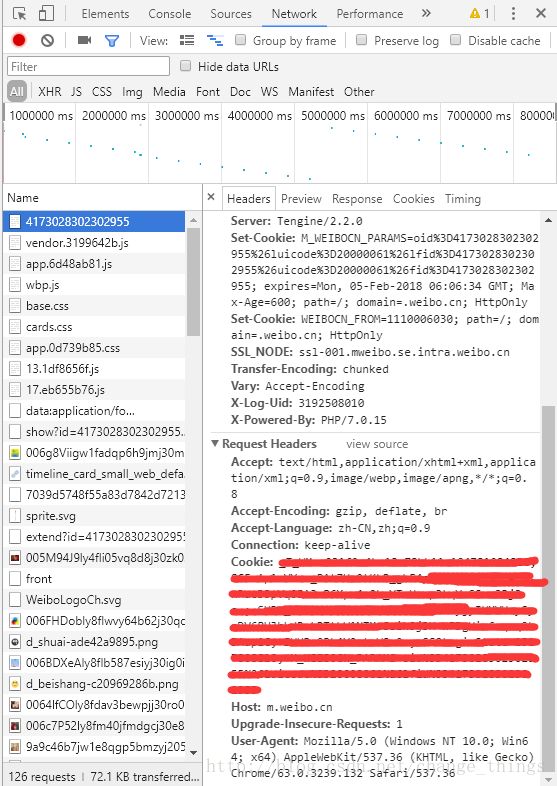
1、获取cookie,先进入微博页面登陆微博,如进入https://m.weibo.cn/status/4173028302302955后登陆,再使用chrome的F12可方便地获取自己的cookie,获取Cookie所需的选择项如下图所示,往下拉会看到自己的Cookie。
2、写爬虫,代码如下,可以爬取诸如用户名 评论时间 点赞数 评论内容等等,保存为.py文件。本文参考了一些博客,但由于时间问题,多多少少有点不适用当前版本,具体参考Reference。
# -*- coding: utf-8 -*-
import requests
import json
import time
import pymongo
import csv
import os
import codecs
import sys
reload(sys)
sys.setdefaultencoding('utf8')
client = pymongo.MongoClient('localhost', 27017)
weibo = client['weibo']
comment_ = weibo['comment_']
headers = {
"Cookies":'********我是最有用的Cookies********',
"User-Agent":'Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1'
}
# id可以换成任意新浪微博的微博id号,具体可以打开相应微博查看,这个评论通过微博开放的api获取,不是微博地址
url_comment = ['https://m.weibo.cn/api/comments/show?id=4173028302302955&page={}'.format(str(i)) for i in range(1,1000)]
#print(url_comment)
path = os.getcwd()+"/weibo.csv"
csvfile = open(path, 'w')
csvfile.write(codecs.BOM_UTF8)
writer = csv.writer(csvfile)
#writer.writerow(('username','created_at','source','comment','like_counts'))
def get_comment(url):
try:
wb_data = requests.get(url,headers=headers)
#data_comment = json.loads(wb_data)
#print(data_comment)
jsondata = wb_data.json()
datas = jsondata.get('data').get('data')
for data in datas:
created_at = data.get("created_at")
like_counts = data.get("like_counts")
source = data.get("source")
username = data.get("user").get("screen_name")
comment = data.get("text")
#print json.dumps(comment, encoding="UTF-8", ensure_ascii=False)
writer.writerow((username,created_at,source,json.dumps(comment, encoding="UTF-8", ensure_ascii=False),like_counts))
except KeyError:
pass
for url in url_comment:
get_comment(url)
time.sleep(2)
写入csv需要注意的是中文采用utf-8编码,如果直接写入会报错,在网上各种搜索得到多种方法,其中每种方法对应如下bug:
遇到bug1:UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-8: ordinal not in range(128)
需要添加:
import sys
reload(sys)
sys.setdefaultencoding('utf8')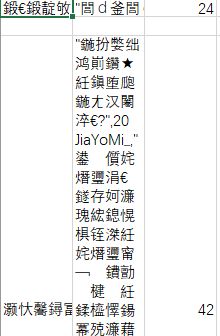
需要在创建文件前添加:
csvfile.write(codecs.BOM_UTF8)print json.dumps(comment, encoding="UTF-8", ensure_ascii=False)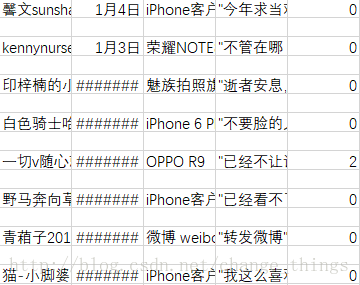
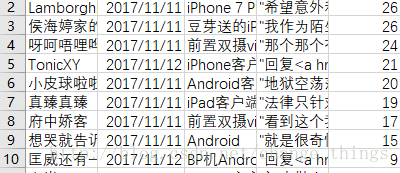
用excel调整一下:
Reference:
[1]http://blog.csdn.net/a_xiao_mili/article/details/77947802获取新浪微博cookie
[2]https://www.cnblogs.com/zhzhang/p/7208928.html Python爬取新浪微博评论数据,写入csv文件中
[3]http://blog.csdn.net/njzhujinhua/article/details/47176233 python写utf-8文件
etc.