面试资料整理
List、Set与Map的区别
List和Set都实现了collection的接口
Map不是collection的子接口或者实现类,Map是一个接口
List
- 可以允许重复的对象
- 可以插入多个null对象
- 是一个有序容器,保持了每个元素的插入顺序,输出的顺序就是插入的顺序
- 常用的实现类有 ArrayList、LinkedList 和 Vector。
Set
- 不允许重复对象
- 无序容器,无法保证每个元素的存储顺序,TreeSet通过Comparator或者Comparable维护了一个排列顺序
- 只允许一个null元素
- Set 接口最流行的几个实现类是 HashSet、LinkedHashSet 以及 TreeSet。最流行的是基于 HashMap 实现的 HashSet;TreeSet 还实现了 SortedSet 接口,因此 TreeSet 是一个根据其 compare() 和 compareTo() 的定义进行排序的有序容器。
Map
- Map不是collection的子接口或者实现类。Map是一个接口。
- Map 的 每个 Entry 都持有两个对象,也就是一个键一个值,Map 可能会持有相同的值对象但键对象必须是唯一的。
- TreeMap 也通过 Comparator 或者 Comparable 维护了一个排序顺序。
- Map里值可以有多个null,但是键最多只能有一个为null
- Map 接口最流行的几个实现类是 HashMap、LinkedHashMap、Hashtable 和 TreeMap。(HashMap、TreeMap最常用)
什么场景下使用list、set、map?
- 如果你经常会使用索引来对容器中的元素进行访问,那么 List 是你的正确的选择。如果你已经知道索引了的话,那么 List 的实现类比如 ArrayList 可以提供更快速的访问,如果经常添加删除元素的,那么肯定要选择LinkedList。
- 如果你想容器中的元素能够按照它们插入的次序进行有序存储,那么还是 List,因为 List 是一个有序容器,它按照插入顺序进行存储。
- 如果你想保证插入元素的唯一性,也就是你不想有重复值的出现,那么可以选择一个 Set 的实现类,比如 HashSet、LinkedHashSet 或者 TreeSet。所有 Set 的实现类都遵循了统一约束比如唯一性,而且还提供了额外的特性比如 TreeSet 还是一个 SortedSet,所有存储于 TreeSet 中的元素可以使用 Java 里的 Comparator 或者 Comparable 进行排序。LinkedHashSet 也按照元素的插入顺序对它们进行存储。
- 如果你以键和值的形式进行数据存储那么 Map 是你正确的选择。你可以根据你的后续需要从 Hashtable、HashMap、TreeMap 中进行选择。
Arraylist 与 LinkedList 区别
- ArrayList是实现了
基于动态数组的数据结构,而LinkedList是基于链表的数据结构 - 对于随机访问get和set,ArrayList要优于LinkedList,因为LinkedLIst要移动指针
- 对于移动和删除操作add和remove,一般来说LinkedList要比ArrayList快,因为一般ArrayList要移动数据
ArrayList的内部实现是基于基础的对象数组的,因此,它使用get方法访问列表中的任意一个元素时(random access),它的速度要比LinkedList快。LinkedList中的get方法是按照顺序从列表的一端开始检查,直到另外一端。对LinkedList而言,访问列表中的某个指定元素没有更快的方法了。
性能上的有缺点
1.对ArrayList和LinkedList而言,在列表末尾增加一个元素所花的开销都是固定的。对 ArrayList而言,主要是在内部数组中增加一项,指向所添加的元素,偶尔可能会导致对数组重新进行分配;而对LinkedList而言,这个开销是 统一的,分配一个内部Entry对象。
2.在ArrayList集合中添加或者删除一个元素时,当前的列表所所有的元素都会被移动。而LinkedList集合中添加或者删除一个元素的开销是固定的。
3.LinkedList集合不支持 高效的随机随机访问(RandomAccess),因为可能产生二次项的行为。
4.ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间
ArrayList 与 Vector 区别
相同点
都实现了List接口(List接口继承了Collection接口),都是有序集合,即存储在这两个集合中的元素的位置都是由顺序的,相当于一种动态的数组。我们可以按位置索引号取出某个元素,并且其中的数据是允许重复的。
不同点
1. 同步性:
Vector 是线程安全的,也就是说是它的方法之间是线程同步的,而 ArrayList 是线程序不安全的,它的方法之间是线程不同步的。如果只有一个线程会访问到集合,那最好是使用 ArrayList,因为它不考虑线程安全,效率会高些;如果有多个线程会访问到集合,那最好是使用 Vector,因为不需要我们自己再去考虑和编写线程安全的代码。
备注:对于 Vector&ArrayList、 Hashtable&HashMap,要记住线程安全的问题,记住 Vector与 Hashtable 是旧的,是 java 一诞生就提供了的,它们是线程安全的,ArrayList 与 HashMap是 java2时才提供的,它们是线程不安全的。
2.数据增长:
ArrayList 与 Vector 都有一个初始的容量大小,当存储进它们里面的元素的个数超过了容量时,Vector 默认增长为原来两倍,而 ArrayList 增长为原来的1.5倍)。 ArrayList 与 Vector 都可以设置初始的空间大小, Vector 还可以设置增长的空间大小,而 ArrayList 没有提供设置增长空间的方法。
HashMap和Hashtable的区别
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
- HashMap几乎可以等价于Hashtable,除了
HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。 - HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
- 另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
- 由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
- HashMap不能保证随着时间的推移Map中的元素次序是不变的。
要注意的一些重要术语:
- sychronized意味着在一次仅有一个线程能够更改Hashtable。就是说任何线程要更新Hashtable时要首先获得同步锁,其它线程要等到同步锁被释放之后才能再次获得同步锁更新Hashtable。
- Fail-safe和iterator迭代器相关。如果某个集合对象创建了Iterator或者ListIterator,然后其它的线程试图“结构上”更改集合对象,将会抛出ConcurrentModificationException异常。但其它线程可以通过set()方法更改集合对象是允许的,因为这并没有从“结构上”更改集合。但是假如已经从结构上进行了更改,再调用set()方法,将会抛出IllegalArgumentException异常。
- 结构上的更改指的是删除或者插入一个元素,这样会影响到map的结构。
我们能否让HashMap同步?HashMap可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);
结论
Hashtable和HashMap有几个主要的不同:线程安全以及速度。仅在你需要完全的线程安全的时候使用Hashtable,而如果你使用Java 5或以上的话,请使用ConcurrentHashMap吧。
HashMap与HashSet的区别
HashSet:
HashSet实现了Set接口,它不允许集合中出现重复元素。当我们提到HashSet时,第一件事就是在将对象存储在HashSet之前,要确保重写hashCode()方法和equals()方法,这样才能比较对象的值是否相等,确保集合中没有储存相同的对象。如果不重写上述两个方法,那么将使用下面方法默认实现: public boolean add(Object obj)方法用在Set添加元素时,如果元素值重复时返回 “false”,如果添加成功则返回"true"
HashMap:
HashMap实现了Map接口,Map接口对键值对进行映射。Map中不允许出现重复的键(Key)。Map接口有两个基本的实现TreeMap和HashMap。TreeMap保存了对象的排列次序,而HashMap不能。HashMap可以有空的键值对(Key(null)-Value(null))HashMap是非线程安全的(非Synchronize),要想实现线程安全,那么需要调用collections类的静态方法synchronizeMap()实现。public Object put(Object Key,Object value)方法用来将元素添加到map中。HashSet与HashMap的区别:
session 与 cookie 区别
前言
HTTP是一种无状态的协议,为了分辨链接是谁发起的,需自己去解决这个问题。不然有些情况下即使是同一个网站每打开一个页面也都要登录一下。而Session和Cookie就是为解决这个问题而提出来的两个机制。
应用场景
登录网站,今输入用户名密码登录了,第二天再打开很多情况下就直接打开了。这个时候用到的一个机制就是cookie。
session一个场景是购物车,添加了商品之后客户端处可以知道添加了哪些商品,而服务器端如何判别呢,所以也需要存储一些信息就用到了session。
1.Cookie
通俗讲,是访问某些网站后在本地存储的一些网站相关信息,下次访问时减少一些步骤。更准确的说法是:Cookies是服务器在本地机器上存储的小段文本并随每一个请求发送至同一服务器,是在客户端保持状态的方案。
Cookie的主要内容包括:名字,值,过期时间,路径和域。使用Fiddler抓包就可以看见,比方说我们打开百度的某个网站可以看到Headers包括Cookie,如下:
BIDUPSID: 9D2194F1CB8D1E56272947F6B0E5D47E
PSTM: 1472480791
BAIDUID: 3C64D3C3F1753134D13C33AFD2B38367:FG
ispeed_lsm: 2
MCITY: -131:
pgv_pvi: 3797581824
pgv_si: s9468756992
BDUSS: JhNXVoQmhPYTVENEdIUnQ5S05xcHZMMVY5QzFRNVh5SzZoV0xMVDR6RzV-bEJZSVFBQUFBJCQAAAAAAAAAAAEAAACteXsbYnRfY2hpbGQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAALlxKVi5cSlYZj
BD_HOME: 1
H_PS_PSSID: 1423_21080_17001_21454_21408_21530_21377_21525_21193_21340
BD_UPN: 123253
sug: 3
sugstore: 0
ORIGIN: 0
bdime: 0
key, value形式。过期时间可设置的,如不设,则浏览器关掉就消失了,存储在内存当中,否则就按设置的时间来存储在硬盘上的,过期后自动清除,比方说开关机关闭再打开浏览器后他都会还存在,前者称之为Session cookie 又叫 transient cookie,后者称之为Persistent cookie 又叫 permenent cookie。路径和域就是对应的域名,a网站的cookie自然不能给b用。
2.Session
存在服务器的一种用来存放用户数据的类HashTable结构。
浏览器第一次发送请求时,服务器自动生成了一HashTable和一Session ID来唯一标识这个HashTable,并将其通过响应发送到浏览器。浏览器第二次发送请求会将前一次服务器响应中的Session ID放在请求中一并发送到服务器上,服务器从请求中提取出Session ID,并和保存的所有Session ID进行对比,找到这个用户对应的HashTable。
一般这个值会有个时间限制,超时后毁掉这个值,默认30分钟。
当用户在应用程序的 Web页间跳转时,存储在 Session 对象中的变量不会丢失而是在整个用户会话中一直存在下去。
Session的实现方式和Cookie有一定关系。建立一个连接就生成一个session id,打开几个页面就好几个了,这里就用到了Cookie,把session id存在Cookie中,每次访问的时候将Session id带过去就可以识别了.
区别
存储数据量方面:session 能够存储任意的 java 对象,cookie 只能存储 String 类型的对象
一个在客户端一个在服务端。因Cookie在客户端所以可以编辑伪造,不是十分安全。
Session过多时会消耗服务器资源,大型网站会有专门Session服务器,Cookie存在客户端没问题。
域的支持范围不一样,比方说a.com的Cookie在a.com下都能用,而www.a.com的Session在api.a.com下都不能用,解决这个问题的办法是JSONP或者跨域资源共享。
session多服务器间共享
服务器实现的 session 复制或 session 共享,如 webSphere或 JBOSS 在搭集群时配置实现 session 复制或 session 共享.致命缺点:不好扩展和移植。
利用成熟技术做session复制,如12306使用的gemfire,如常见内存数据库redis或memorycache,虽较普适但依赖第三方.
将 session维护在客户端,利用 cookie,但客户端存在风险数据不安全,且可以存放的数据量较小,所以将session 维护在客户端还要对 session 中的信息加密。
第二种方案和第三种方案的合体,可用gemfire实现 session 复制共享,还可将session 维护在 redis中实现 session 共享,同时可将 session 维护在客户端的cookie 中,但前提是数据要加密。
这三种方式可迅速切换,而不影响应用正常执行。在实践中,首选 gemfire 或者 redis 作为 session 共享的载体,一旦 session 不稳定出现问题的时候,可以紧急切换 cookie 维护 session 作为备用,不影响应用提供服务
单点登录中,cookie 被禁用了怎么办?(一点登陆,子网站其他系统不用再登陆)
单点登录的原理是后端生成一个 session ID,设置到 cookie,后面所有请求浏览器都会带上cookie,然后服务端从cookie获取 session ID,查询到用户信息。
所以,保持登录的关键不是cookie,而是通过cookie 保存和传输的 session ID,本质是能获取用户信息的数据。
除了cookie,还常用 HTTP 请求头来传输。但这个请求头浏览器不会像cookie一样自动携带,需手工处理
原文:https://blog.csdn.net/liyifan687/article/details/80077928
理解Cookie和Session的区别及使用
前言
HTTP是一种无状态的协议,为了分辨链接是谁发起的,需自己去解决这个问题。不然有些情况下即使是同一个网站每打开一个页面也都要登录一下。而Session和Cookie就是为解决这个问题而提出来的两个机制。应用场景
登录网站,今输入用户名密码登录了,第二天再打开很多情况下就直接打开了。这个时候用到的一个机制就是cookie。
session一个场景是购物车,添加了商品之后客户端处可以知道添加了哪些商品,而服务器端如何判别呢,所以也需要存储一些信息就用到了session。1.Cookie
通俗讲,是访问某些网站后在本地存储的一些网站相关信息,下次访问时减少一些步骤。更准确的说法是:Cookies是服务器在本地机器上存储的小段文本并随每一个请求发送至同一服务器,是在客户端保持状态的方案。
Cookie的主要内容包括:名字,值,过期时间,路径和域。使用Fiddler抓包就可以看见,比方说我们打开百度的某个网站可以看到Headers包括Cookie,如下:
BIDUPSID: 9D2194F1CB8D1E56272947F6B0E5D47E
PSTM: 1472480791
BAIDUID: 3C64D3C3F1753134D13C33AFD2B38367:FG
ispeed_lsm: 2
MCITY: -131:
pgv_pvi: 3797581824
pgv_si: s9468756992
BDUSS: JhNXVoQmhPYTVENEdIUnQ5S05xcHZMMVY5QzFRNVh5SzZoV0xMVDR6RzV-bEJZSVFBQUFBJCQAAAAAAAAAAAEAAACteXsbYnRfY2hpbGQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAALlxKVi5cSlYZj
BD_HOME: 1
H_PS_PSSID: 1423_21080_17001_21454_21408_21530_21377_21525_21193_21340
BD_UPN: 123253
sug: 3
sugstore: 0
ORIGIN: 0
bdime: 0
key, value形式。过期时间可设置的,如不设,则浏览器关掉就消失了,存储在内存当中,否则就按设置的时间来存储在硬盘上的,过期后自动清除,比方说开关机关闭再打开浏览器后他都会还存在,前者称之为Session cookie 又叫 transient cookie,后者称之为Persistent cookie 又叫 permenent cookie。路径和域就是对应的域名,a网站的cookie自然不能给b用。2.Session
存在服务器的一种用来存放用户数据的类HashTable结构。
浏览器第一次发送请求时,服务器自动生成了一HashTable和一Session ID来唯一标识这个HashTable,并将其通过响应发送到浏览器。浏览器第二次发送请求会将前一次服务器响应中的Session ID放在请求中一并发送到服务器上,服务器从请求中提取出Session ID,并和保存的所有Session ID进行对比,找到这个用户对应的HashTable。
一般这个值会有个时间限制,超时后毁掉这个值,默认30分钟。
当用户在应用程序的 Web页间跳转时,存储在 Session 对象中的变量不会丢失而是在整个用户会话中一直存在下去。
Session的实现方式和Cookie有一定关系。建立一个连接就生成一个session id,打开几个页面就好几个了,这里就用到了Cookie,把session id存在Cookie中,每次访问的时候将Session id带过去就可以识别了.区别
存储数据量方面:session 能够存储任意的 java 对象,cookie 只能存储 String 类型的对象
一个在客户端一个在服务端。因Cookie在客户端所以可以编辑伪造,不是十分安全。
Session过多时会消耗服务器资源,大型网站会有专门Session服务器,Cookie存在客户端没问题。
域的支持范围不一样,比方说a.com的Cookie在a.com下都能用,而www.a.com的Session在api.a.com下都不能用,解决这个问题的办法是JSONP或者跨域资源共享。session多服务器间共享
服务器实现的 session 复制或 session 共享,如 webSphere或 JBOSS 在搭集群时配置实现 session 复制或 session 共享.致命缺点:不好扩展和移植。
利用成熟技术做session复制,如12306使用的gemfire,如常见内存数据库redis或memorycache,虽较普适但依赖第三方.
将 session维护在客户端,利用 cookie,但客户端存在风险数据不安全,且可以存放的数据量较小,所以将session 维护在客户端还要对 session 中的信息加密。
第二种方案和第三种方案的合体,可用gemfire实现 session 复制共享,还可将session 维护在 redis中实现 session 共享,同时可将 session 维护在客户端的cookie 中,但前提是数据要加密。
这三种方式可迅速切换,而不影响应用正常执行。在实践中,首选 gemfire 或者 redis 作为 session 共享的载体,一旦 session 不稳定出现问题的时候,可以紧急切换 cookie 维护 session 作为备用,不影响应用提供服务单点登录中,cookie 被禁用了怎么办?(一点登陆,子网站其他系统不用再登陆)
单点登录的原理是后端生成一个 session ID,设置到 cookie,后面所有请求浏览器都会带上cookie,然后服务端从cookie获取 session ID,查询到用户信息。
所以,保持登录的关键不是cookie,而是通过cookie 保存和传输的 session ID,本质是能获取用户信息的数据。
除了cookie,还常用 HTTP 请求头来传输。但这个请求头浏览器不会像cookie一样自动携带,需手工处理
java创建线程的三种方式及其对比
创建线程
1.继承Thread类创建线程类
- 定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。
- 创建Thread子类的实例,即创建了线程对象。
- 调用线程对象的start()方法来启动该线程。
package com.thread;
public class FirstThreadTest extends Thread{
int i = 0;
//重写run方法,run方法的方法体就是现场执行体
public void run()
{
for(;i<100;i++){
System.out.println(getName()+" "+i);
}
}
public static void main(String[] args)
{
for(int i = 0;i< 100;i++)
{
System.out.println(Thread.currentThread().getName()+" : "+i);
if(i==20)
{
new FirstThreadTest().start();
new FirstThreadTest().start();
}
}
}
}
上述代码中Thread.currentThread()方法返回当前正在执行的线程对象。GetName()方法返回调用该方法的线程的名字。
2.通过Runnable接口创建线程类
- 定义runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
- 创建 Runnable实现类的实例,并依此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
- 调用线程对象的start()方法来启动该线程。
package com.thread;
public class RunnableThreadTest implements Runnable
{
private int i;
public void run()
{
for(i = 0;i <100;i++)
{
System.out.println(Thread.currentThread().getName()+" "+i);
}
}
public static void main(String[] args)
{
for(int i = 0;i < 100;i++)
{
System.out.println(Thread.currentThread().getName()+" "+i);
if(i==20)
{
RunnableThreadTest rtt = new RunnableThreadTest();
new Thread(rtt,"新线程1").start();
new Thread(rtt,"新线程2").start();
}
}
}
}
3.通过Callable和Future创建线程
- 创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。
- 创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
- 使用FutureTask对象作为Thread对象的target创建并启动新线程。
- 调用FutureTask对象的get()方法来获得子线程执行结束后的返回值
package com.thread;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class CallableThreadTest implements Callable<Integer>
{
public static void main(String[] args)
{
CallableThreadTest ctt = new CallableThreadTest();
FutureTask<Integer> ft = new FutureTask<>(ctt);
for(int i = 0;i < 100;i++)
{
System.out.println(Thread.currentThread().getName()+" 的循环变量i的值"+i);
if(i==20)
{
new Thread(ft,"有返回值的线程").start();
}
}
try
{
System.out.println("子线程的返回值:"+ft.get());
} catch (InterruptedException e)
{
e.printStackTrace();
} catch (ExecutionException e)
{
e.printStackTrace();
}
}
@Override
public Integer call() throws Exception
{
int i = 0;
for(;i<100;i++)
{
System.out.println(Thread.currentThread().getName()+" "+i);
}
return i;
}
}
三种方式对比
采用实现Runnable、Callable接口的方式创见多线程
优势:
线程类只是实现了Runnable接口或Callable接口,还可以继承其他类。
在这种方式下,多个线程可以共享同一个target对象,所以非常适合多个相同线程来处理同一份资源的情况,从而可以将CPU、代码和数据分开,形成清晰的模型,较好地体现了面向对象的思想。
劣势:
编程稍微复杂,如果要访问当前线程,则必须使用Thread.currentThread()方法。
使用继承Thread类的方式创建多线程
优势:
编写简单,如果需要访问当前线程,则无需使用Thread.currentThread()方法,直接使用this即可获得当前线程。
劣势:
线程类已经继承了Thread类,所以不能再继承其他父类。
java之yield(),sleep(),wait()区别详解
一、
sleep
sleep()使当前线程(即调用该方法的线程)暂停执行一段时间,让其他线程有机会继续执行,但它并不释放对象锁。也就是说如果有synchronized同步块,其他线程仍然不能访问共享数据。注意该方法要捕捉异常。例如有两个线程同时执行(没有synchronized)一个线程优先级为MAX_PRIORITY,另一个为MIN_PRIORITY,如果没有Sleep()方法,只有高优先级的线程执行完毕后,低优先级的线程才能够执行;但是高优先级的线程sleep(500)后,低优先级就有机会执行了。总之,sleep()可以使低优先级的线程得到执行的机会,当然也可以让同优先级、高优先级的线程有执行的机会。
join()
join()方法使调用该方法的线程在此之前执行完毕,也就是等待该方法的线程执行完毕后再往下继续执行。注意该方法也需要捕捉异常。
yield()
该方法与sleep()类似,只是不能由用户指定暂停多长时间,并且yield()方法只能让同优先级的线程有执行的机会。
wait()和notify()、notifyAll()
这三个方法用于协调多个线程对共享数据的存取,所以必须在synchronized语句块内使用。
synchronized关键字用于保护共享数据,阻止其他线程对共享数据的存取,但是这样程序的流程就很不灵活了,如何才能在当前线程还没退出synchronized数据块时让其他线程也有机会访问共享数据呢?此时就用这三个方法来灵活控制。
wait()方法使当前线程暂停执行并释放对象锁标示,让其他线程可以进入synchronized数据块,当前线程被放入对象等待池中。
当调用notify()方法后,将从对象的等待池中移走一个任意的线程并放到锁标志等待池中,只有锁标志等待池中线程能够获取锁标志;如果锁标志等待池中没有线程,则notify()不起作用。
notifyAll()则从对象等待池中移走所有等待那个对象的线程并放到锁标志等待池中。注意 这三个方法都是java.lang.Object的方法。
二、
run和start()把需要处理的代码放到run()方法中,start()方法启动线程将自动调用run()方法,这个由java的内存机制规定的。并且run()方法必需是public访问权限,返回值类型为void。
三、
关键字synchronized该关键字用于保护共享数据,当然前提条件是要分清哪些数据是共享数据。每个对象都有一个锁标志,当一个线程访问到该对象,被Synchronized修饰的数据将被"上锁",阻止其他线程访问。当前线程访问完这部分数据后释放锁标志,其他线程就可以访问了。
四、
wait()和notify(),notifyAll()是Object类的方法,sleep()和yield()是Thread类的方法。
(1)、常用的wait方法有wait()和wait(long timeout);void wait() 在其他线程调用此对象的 notify() 方法或者 notifyAll()方法前,导致当前线程等待。void wait(long timeout)在其他线程调用此对象的notify() 方法 或者 notifyAll()方法,或者超过指定的时间量前,导致当前线程等待。wait()后,线程会释放掉它所占有的“锁标志”,从而使线程所在对象中的其他shnchronized数据可被别的线程使用。wait()h和notify()因为会对对象的“锁标志”进行操作,所以他们必需在Synchronized函数或者 synchronized block 中进行调用。如果在non-synchronized 函数或 non-synchronized block 中进行调用,虽然能编译通过,但在运行时会发生IllegalMonitorStateException的异常。
(2)、Thread.sleep(long millis)必须带有一个时间参数。sleep(long)使当前线程进入停滞状态,所以执行sleep()的线程在指定的时间内肯定不会被执行;sleep(long)可使优先级低的线程得到执行的机会,当然也可以让同优先级的线程有执行的机会;sleep(long)是不会释放锁标志的。
(3)、yield()没有参数sleep 方法使当前运行中的线程睡眠一段时间,进入不可以运行状态,这段时间的长短是由程序设定的,yield方法使当前线程让出CPU占有权,但让出的时间是不可设定的。yield()也不会释放锁标志。实际上,yield()方法对应了如下操作;先检测当前是否有相同优先级的线程处于同可运行状态,如有,则把CPU的占有权交给次线程,否则继续运行原来的线程,所以yield()方法称为“退让”,它把运行机会让给了同等级的其他线程。sleep 方法允许较低优先级的线程获得运行机会,但yield()方法执行时,当前线程仍处在可运行状态,所以不可能让出较低优先级的线程此时获取CPU占有权。在一个运行系统中,如果较高优先级的线程没有调用sleep方法,也没有受到I/O阻塞,那么较低优先级线程只能等待所有较高优先级的线程运行结束,方可有机会运行。yield()只是使当前线程重新回到可执行状态,所有执行yield()的线程有可能在进入到可执行状态后马上又被执行,所以yield()方法只能使同优先级的线程有执行的机会。
Java编程:悲观锁、乐观锁的区别及使用场景
定义:
悲观锁(Pessimistic Lock):
每次获取数据的时候,都会担心数据被修改,所以每次获取数据的时候都会进行加锁,确保在自己使用的过程中数据不会被别人修改,使用完成后进行数据解锁。由于数据进行加锁,期间对该数据进行读写的其他线程都会进行等待。
乐观锁(Optimistic Lock):
每次获取数据的时候,都不会担心数据被修改,所以每次获取数据的时候都不会进行加锁,但是在更新数据的时候需要判断该数据是否被别人修改过。如果数据被其他线程修改,则不进行数据更新,如果数据没有被其他线程修改,则进行数据更新。由于数据没有进行加锁,期间该数据可以被其他线程进行读写操作。
适用场景:
悲观锁:比较适合写入操作比较频繁的场景,如果出现大量的读取操作,每次读取的时候都会进行加锁,这样会增加大量的锁的开销,降低了系统的吞吐量。
乐观锁:比较适合读取操作比较频繁的场景,如果出现大量的写入操作,数据发生冲突的可能性就会增大,为了保证数据的一致性,应用层需要不断的重新获取数据,这样会增加大量的查询操作,降低了系统的吞吐量。
CAS和ABA问题
CAS
Compare And Set
CAS有3个操作数,分别为内存值V,旧的预期值A,要修改的新值B
当A与V相同时,将V修改为B,否则什么都不做。
乐观锁用到的机制就是CAS。
但是CAS会导致“ABA问题”。
CAS算法实现一个重要前提需要取出内存中某时刻的数据,而在下时刻比较并替换,那么在这个时间差类会导致数据的变化。比如说一个线程one从内存位置V中取出A,这时候另一个线程two也从内存中取出A,并且two进行了一些操作变成了B,然后two又将V位置的数据变成A,这时候线程one进行CAS操作发现内存中仍然是A,然后one操作成功。尽管线程one的CAS操作成功,但是不代表这个过程就是没有问题的。如果链表的头在变化了两次后恢复了原值,但是不代表链表就没有变化。因此前面提到的原子操作AtomicStampedReference/AtomicMarkableReference就很有用了。这允许一对变化的元素进行原子操作。
广度优先算法
广度优先算法
广度优先算法(Breadth-First Search)简称BFS
从根节点开始,沿着树的宽度遍历树的节点,如果发现目标,则算法终止。
图的遍历的定义:
从图的某个顶点出发访问遍图中所有顶点,且每个顶点仅被访问一次。(连通图与非连通图)
脏读、幻读、不可重复读
丢失更新
两个事务同时更新一行数据,最后一个事务的更新会覆盖掉第一个事务的更新,从而导致第一个事务更新的数据丢失,这是由于没有加锁造成的
脏读
脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。
e.g.
- Mary的原工资为1000, 财务人员将Mary的工资改为了8000(但未提交事务)
- Mary读取自己的工资 ,发现自己的工资变为了8000,欢天喜地!
- 而财务发现操作有误,回滚了事务,Mary的工资又变为了1000
像这样,Mary记取的工资数8000是一个脏数据。
不可重复读
是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
e.g.
1.在事务1中,Mary 读取了自己的工资为1000,操作并没有完成
2.在事务2中,这时财务人员修改了Mary的工资为2000,并提交了事务.
3.在事务1中,Mary 再次读取自己的工资时,工资变为了2000 解决办法:如果只有在修改事务完全提交之后才可以读取数据,则可以避免该问题。
解决办法:如果只有在修改事务完全提交之后才可以读取数据,则可以避免该问题。
幻读
是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
e.g.
目前工资为1000的员工有10人。
- 事务1,读取所有工资为1000的员工。
- 这时事务2向employee表插入了一条员工记录,工资也为1000
- 事务1再次读取所有工资为1000的员工 共读取到了11条记录
解决办法:如果在操作事务完成数据处理之前,任何其他事务都不可以添加新数据,则可避免该问题
在一个程序中,依据事务的隔离级别将会有三种情况发生。
◆脏读:一个事务会读进还没有被另一个事务提交的数据,所以你会看到一些最后被另一个事务回滚掉的数据。
◆不可重复读:一个事务读进一条记录,另一个事务更改了这条记录并提交完毕,这时候第一个事务再次读这条记录时,它已经改变了。
◆ 幻影读:一个事务用Where子句来检索一个表的数据,另一个事务插入一条新的记录,并且符合Where条件,这样,第一个事务用同一个where条件来检索数据后,就会多出一条记录。
快速失败与安全失败
快速失败(fail-fast)
在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。
原理:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。
注意:这里异常的抛出条件是检测到 modCount!=expectedmodCount 这个条件。如果集合发生变化时修改modCount值刚好又设置为了expectedmodCount值,则异常不会抛出。因此,不能依赖于这个异常是否抛出而进行并发操作的编程,这个异常只建议用于检测并发修改的bug。
场景:java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改)。
安全失败(fail-safe)
采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
原理:由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发Concurrent Modification Exception。
缺点:基于拷贝内容的优点是避免了Concurrent Modification Exception,但同样地,迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。
场景:java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改。
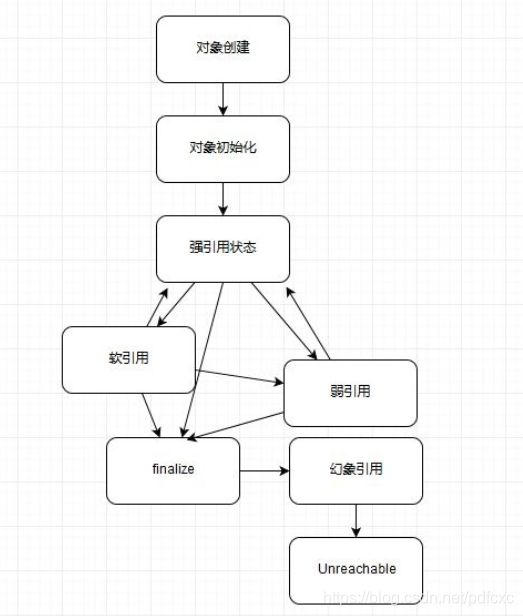
强引用、 软引用、 弱引用、 幻象引用
不同的引用类型,主要体现的是对象不同的可达性(Reachable)状态和对垃圾收集的影响。
强引用:
StrongReference是最常见的普通对象引用 ,只要还有强引用指向一个对象,就能表明对象还“活着”,垃圾收集器不会碰这种对象。 对于一个普通的对象,如果没有其他的引用关系,只要超过了引用的作用域或者显式地将相应(强) 引用赋值为null,就是可以被垃圾收集的了,当然具体回收时机还是要看垃圾收集策略。
软引用:
SoftReference是一种相对强引用弱化一些的引用,可以让对象豁免一些垃圾收集,只有当JVM认为内存不足时,才会去试图回收软引用指向的对象。JVM会确保在抛出OutOfMemoryError之前,清理软引用指向的对象。软引用通常用来实现内存敏感的缓存,如果还有空闲内存,就可以暂时保留缓存,当内存不足时清理掉,这样就保证了使用缓存的同时,不会耗尽内存。
弱引用:
WeakReference并不能使对象豁免垃圾收集,仅仅是提供一种访问在弱引用状态下对象的途径。 这就可以用来构建一种没有特定约束的关系,比如,维护一种非强制性的映射关系,如果试图获取时对象还在,就使用它,否则重现实例化。它同样是很多缓存实现的选择。
幻象引用:
幻象引用有时候也翻译成虚引用,不能通过它访问对象。 幻象引用仅仅是提供了一种确保对象被finalize以后,做某些事情的机制,比如,通常用来做所谓的Post-Mortem清理机制
Spring Boot Starter的面试题
常见的Starter包含几个方面的内容?分别是什么?
- 自动配置文件,根据classpath是否存在指定的类类决定是否要执行给功能的自动配置
- spring.factories,指导Spring Boot找到指定的自动配置文件
- endpoint,可以理解为一个admin,包含对服务的描述、界面、交互(业务信息的查询)
- health indicator,提供服务的健康指标
工作原理
- Spring Boot 在启动时扫描项目所依赖的JAR包,寻找包含spring.factories文件的JAR
- 根据spring.factories配置加载AutoConfigure类
- 根据 @Conditional注解的条件,进行自动配置并将Bean注入Spring Context
自定义springboot-starter注意事项
- springboot默认scan的包名是其main类所在的包名。如果引入的starter包名不一样,需要自己添加scan。
@ComponentScan(basePackages = {"com.xixicat.demo","com.xixicat.sms"})
- 对于starter中有feign的,需要额外指定
@EnableFeignClients(basePackages = {"com.xixicat.sms"})
- 对于exclude一些autoConfig
@EnableAutoConfiguration(exclude = {MetricFilterAutoConfiguration.class})
谈谈对Spring Boot的认识
spring Boot是一个开源框架,它可用于创建可执行的Spring应用程序,采用了习惯优于配置的方法。此框架的神奇之处在于@EnableAutoConfiguration注解,此注解自动载入应用程序所需的所有Bean——这依赖于Spring Boot在类路径中的查找。
- @Enable注解
@Enable注解并不是新发明的注解,早在Spring 3框架就引入了这些注解,用这些注解替代XML配置文件。
很多Spring开发者都知道@EnableTransactionManagement注解,它能够声明事务管理;@EnableWebMvc注解,它能启用Spring MVC;以及@EnableScheduling注解,它可以初始化一个调度器。
- 属性映射
下面看MongoProperties类,它是一个Spring Boot属性映射的例子:
@ConfigurationProperties(prefix = "spring.data.mongodb")
public class MongoProperties {
private String host;
private int port = DBPort.PORT;
private String uri = "mongodb://localhost/test";
private String database;
// ... getters/ setters omitted
}
@ConfigurationProperties注解将POJO关联到指定前缀的每一个属性。例如,spring.data.mongodb.port属性将映射到这个类的端口属性。
强烈建议Spring Boot开发者使用这种方式来删除与配置属性相关的瓶颈代码。
3.@Conditional注解
Spring Boot的强大之处在于使用了Spring 4框架的新特性:@Conditional注解,此注解使得只有在特定条件满足时才启用一些配置。
在Spring Boot的org.springframework.boot.autoconfigure.condition包中说明了使用@Conditional注解能给我们带来什么,下面对这些注解做一个概述:
@ConditionalOnBean
@ConditionalOnClass
@ConditionalOnExpression
@ConditionalOnMissingBean
@ConditionalOnMissingClass
@ConditionalOnNotWebApplication
@ConditionalOnResource
@ConditionalOnWebApplication
4.应用程序上下文初始化器
spring.factories还提供了第二种可能性,即定义应用程序的初始化。这使得我们可以在应用程序载入前操纵Spring的应用程序上下文ApplicationContext。
特别是,可以在上下文创建监听器,使用ConfigurableApplicationContext类的addApplicationListener()方法。
AutoConfigurationReportLoggingInitializer监听到系统事件时,比如上下文刷新或应用程序启动故障之类的事件,Spring Boot可以执行一些工作。这有助于我们以调试模式启动应用程序时创建自动配置的报告。
要以调试模式启动应用程序,可以使用-Ddebug标识,或者在application.properties文件这添加属性debug= true。
海量数据处理面试题
1. 给定 a、b 两个文件,各存放 50 亿个 url,每个 url 各占 64 字节,内存限制是 4G,让你找出 a、b 文件共同的 url?
- 方案1:
- 遍历文件 a,对每个 url 求取 hash(url)%1000,然后根据所取得的值将 url 分别存储到 1000 个小文件(记为 a0,a1,…,a999 每个小文件约 300M),为什么是 1000?主要根据内存大小和要分治的文件大小来计算,我们就大致可以把 320G 大小分为 1000 份,每份大约 300M(当然,到底能不能分布尽量均匀,得看 hash 函数的设计
- 遍历文件 b,采取和 a 相同的方式将 url 分别存储到 1000 个小文件(记为 b0,b1,…,b999 )为什么要这样做?文件 a 的 hash 映射和文件 b 的 hash 映射函数要保持一致,这样的话相同的 url 就会保存在对应的小文件中,比如,如果 a 中有一个 url 记录 data1 被 hash 到了 a99 文件中,那么如果 b 中也有相同 url,则一定被 hash 到了 b99 中。
所以现在问题转换成了:找出 1000 对小文件中每一对相同的 url(不对应的小文件不可能有相同的 url) - 求每对小文件中相同的 url 时,可以把其中一个小文件的 url 存储到 hash_set 中。然后遍历另一个小文件的每个 url,看其是否在刚才构建的 hash_set 中,如果是,那么就是共同的 url,存到文件里面就可以了。
- 方案2:
如果允许有一定的错误率,可以使用 Bloom filter,4G 内存大概可以表示 340 亿 bit。将其中一个文件中的 url 使用 Bloom filter 映射为这 340 亿 bit,然后挨个读取另外一个文件的 url,检查是否与 Bloom filter,如果是,那么该 ur l应该是共同的 url(注意会有一定的错误率)。
2. 如果有一个500G的超大文件,里面都是数值,如何对这些数值排序?
-
先将这个文件里面的值拆分成多个文件,每个文件大小差不多512M。
-
在这1000个小文件里面的值进行排序去重
分两种情况:
① 如果里面的数值不是很大,这样拼接1000文件数值,拼接,去重,排序。对于8G的内存计算机应该是可以处理的。
② 文件里面的数值就是坑爹的大。
-
对于②处理也很简单,对于1000小文件,比如就按升序排序,我们不是已经拿到了每个的 排序么。我们把1000个文件里面最小的值(也就是第一个)拿出来,并把他们从这些文件中删除,拿这些最小值去重排序作为第一个文件,
-
重复上面的步骤,这样我们也得到1000个 这样排好序的文件。
ARP协议
地址解析协议(Address Resolution Protocol,ARP)是在仅知道主机的IP地址时由地址解析协议确定其物理地址的一种协议。
在TCP/IP协议中,A给B发送IP包,在报头中需要填写B的IP为目标地址,但这个IP包在以太网上传输的时候,还需要进行一次以太包的封装,在这个以太包中,目标地址就是B的MAC地址。
计算机A是如何得知B的MAC地址的呢?解决问题的关键就在于ARP协议。 在A不知道B的MAC地址的情况下,A就广播一个ARP请求包,请求包中填有B的IP(192.168.1.2),以太网中的所有计算机都会接收这个请求,而正常的情况下只有B会给出ARP应答包,包中就填充上了B的MAC地址,并回复给A。 A得到ARP应答后,将B的MAC地址放入本机缓存,便于下次使用。 本机MAC缓存是有生存期的,生存期结束后,将再次重复上面的过程。
ip数据包经由路由转发的时候源ip MAC,目的ip 目的MAC是否改变
ip数据包经由路由转发的时候源ip,目的ip是否改变?
最近面试网络方面的经常问到这个问题,答案是不能改变的,除非做了nat转换才能改变。
不过mac地址是变化的,因为发送端开始不知道目的主机的mac地址,所以每经过一个路由器mac地址是变化的。
目的mac地址是如何得到的?
TCP/IP里面是用的ARP协议。比如新建了一个内网,如果一台机器A找机器B,封装FRAME时(OSI的第二层用的数据格式),要封装对方的MAC,开始时A不知道B的MAC,只知道IP,它就发一个ARP包,源IP是自己的,目的IP是B的,源MAC是自己的,目的MAC是广播的。然后这个请求包在内网内被广播,当其他机器接到这个包时,用目的IP和自己的IP比较,不是的话就丢弃。B接到时,发现IP与自己的一样,就答应这个包的请求,把自己的MAC送给A。如果B是其他子网的机器,那么路由器会判断出B是其他子网,然后路由器把自己的MAC返回给A,A以后再给B发包时,目的MAC封装的是路由器的。
路由转发过程:
当主机A发向主机B的数据流在网络层封装成IP数据包,IP数据包的首部包含了源地址和目标地址。主机A会用本机配置的24位IP网络掩码255.255.255.0与目标地址进行与运算,得出目标网络地址与本机的网络地址是不是在同一个网段中。如果不是将IP数据包转发到网关。
在发往网关前主机A还会通过ARP的请求获得默认网关的MAC地址。在主机A数据链路层IP数据包封装成以太网数据帧,然后才发住到网关……也就是路由器上的一个端口。
当网关路由器接收到以太网数据帧时,发现数据帧中的目标MAC地址是自己的某一个端口的物理地址,这时路由器会把以太网数据帧的封装去掉。路由器认为这个IP数据包是要通过自己进行转发,接着它就在匹配路由表。匹配到路由项后,它就将包发往下一条地址。
路由器转发数据包就是这样,所以它始终是不会改IP地址的。只会改MAC.
当有数据包传到路由器时,路由器首先将其的目的地址与路由表进行对比,如果是本地网络,将不会进行转发到外网络,而是直接转发给本地网内的目的主机;但是如果目的地址经路由表对比,发现不是在本网中,有nat就将改变源地址的IP(原源地址的Ip地址改为了路由器的IP地址),路由器将数据包转发到相应的端口,进行通信。
比如:
如:A访问B,
首先对比是否同一子网,如果是,检查ARP表,有B的MAC就直接发送,没有就发送ARP请求.如果否,发送到默认网关C,源IP为A,源MAC为A,目的IP为B,目的MAC地址为C,
C接收到这个包,检查路由表,发送到下一跳D,源IP为A,源MAC为C,目的IP为B,目的MAC为D……
如此循环,直到发送到B.
NAT为特殊应用,会修改源IP为网关自己外网IP。
Java内存模型
在Java语言中,采用的是共享内存模型来实现多线程之间的信息交换和数据同步的。

Java内存模型的主要目标是定义程序中各个变量的访问规则,即在JVM中将变量存储到内存和从内存中取出变量这样的底层细节。
JMM规定了所有的变量都存储在主内存(Main Memory)中。每个线程还有自己的工作内存(Working Memory),线程的工作内存中保存了该线程使用到的变量的主内存的副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的变量(volatile变量仍然有工作内存的拷贝,但是由于它特殊的操作顺序性规定,所以看起来如同直接在主内存中读写访问一般)。不同的线程之间也无法直接访问对方工作内存中的变量,线程之间值的传递都需要通过主内存来完成。

Java内存模型是围绕着并发编程中原子性、可见性、有序性这三个特征来建立的
原子性(Atomicity):一个操作不能被打断,要么全部执行完毕,要么不执行。在这点上有点类似于事务操作,要么全部执行成功,要么回退到执行该操作之前的状态。
可见性:一个线程对共享变量做了修改之后,其他的线程立即能够看到(感知到)该变量这种修改(变化)。
有序性:对于一个线程的代码而言,我们总是以为代码的执行是从前往后的,依次执行的。这么说不能说完全不对,在单线程程序里,确实会这样执行;但是在多线程并发时,程序的执行就有可能出现乱序。用一句话可以总结为:在本线程内观察,操作都是有序的;如果在一个线程中观察另外一个线程,所有的操作都是无序的。前半句是指“线程内表现为串行语义(WithIn Thread As-if-Serial Semantics)”,后半句是指“指令重排”现象和“工作内存和主内存同步延迟”现象。
volatile关键字的两层语义
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
- 保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
- 禁止进行指令重排序。
synchronized关键字
在Java中,可以使用synchronized关键字来标记一个方法或者代码块,当某个线程调用该对象的synchronized方法或者访问synchronized代码块时,这个线程便获得了该对象的锁,其他线程暂时无法访问这个方法,只有等待这个方法执行完毕或者代码块执行完毕,这个线程才会释放该对象的锁,其他线程才能执行这个方法或者代码块。
Redis面试题
优点:
- 性能出色,内存数据库,
- 能保存多种数据结构
- 可以设置过期时间
缺点:
容量受到物理内存的限制,不能用作海量数据的高性能读写
支持的数据类型:
- String 字符串
- Hash 字典
- Set 集合
- Sorted Set 有序集合
- List 列表
数据淘汰策略
- volatile-lru
从已设置过期时间的数据集中挑选最近最少使用的数据淘汰。redis并不是保证取得所有数据集中最近最少使用的键值对,而只是随机挑选的几个键值对中的, 当内存达到限制的时候无法写入非过期时间的数据集。 - volatile-ttl
从已设置过期时间的数据集中挑选将要过期的数据淘汰。redis 并不是保证取得所有数据集中最近将要过期的键值对,而只是随机挑选的几个键值对中的, 当内存达到限制的时候无法写入非过期时间的数据集。 - volatile-random
从已设置过期时间的数据集中任意选择数据淘汰。当内存达到限制的时候无法写入非过期时间的数据集。 - allkeys-lru
从数据集中挑选最近最少使用的数据淘汰。当内存达到限制的时候,对所有数据集挑选最近最少使用的数据淘汰,可写入新的数据集。 - allkeys-random
从数据集中任意选择数据淘汰,当内存达到限制的时候,对所有数据集挑选随机淘汰,可写入新的数据集。 - no-enviction
当内存达到限制的时候,不淘汰任何数据,不可写入任何数据集,所有引起申请内存的命令会报错。
死锁的四个必要条件和解决办法
死锁概念及产生原理
概念:多个并发进程因争夺系统资源而产生相互等待的现象。
原理:当一组进程中的每个进程都在等待某个事件发生,而只有这组进程中的其他进程才能触发该事件,这就称这组进程发生了死锁。
本质原因:
1. 系统资源有限。
2. 进程推进顺序不合理
死锁产生的4个必要条件
1、互斥:某种资源一次只允许一个进程访问,即该资源一旦分配给某个进程,其他进程就不能再访问,直到该进程访问结束。
2、占有且等待:一个进程本身占有资源(一种或多种),同时还有资源未得到满足,正在等待其他进程释放该资源。
3、不可抢占:别人已经占有了某项资源,你不能因为自己也需要该资源,就去把别人的资源抢过来。
4、循环等待:存在一个进程链,使得每个进程都占有下一个进程所需的至少一种资源。
https://blog.csdn.net/guaiguaihenguai/article/details/80303835
Java基本数据类型
- boolean 1bit
- byte 8bit
- char 16bit
- short 16bit
- int 32bit
- float 32bit
- double 64bit
- long 64bit
多线程之间共享与独占的资源
共享的资源
- 堆 堆是在进程空间中开辟出来的
- 全局变量 它是与某一具体函数无关的,所以也与特定线程无关
- 静态变量 存放位置和全局变量一样,存于堆中开辟的.bss和.data段,是共享的
- 文件等公用资源
独占的资源
- 栈
- 寄存器
RESTful架构优点
- 前后端分离,减少流量
- 安全问题集中在接口上,由于接受json格式,防止了注入型等安全问题
- 前端无关化,后端只负责数据处理,前端表现方式可以是任何前端语言(android,ios,html5)
- 前端和后端人员更加专注于各自开发,只需接口文档便可完成前后端交互,无需过多相互了解
- 服务器性能优化:由于前端是静态页面,通过nginx便可获取,服务器主要压力放在了接口上
Mysql主从配置
MySQL主从又叫做Replication、AB复制。简单讲就是A和B两台机器做主从后,在A上写数据,另外一台B也会跟着写数据,两者数据实时同步的
MySQL主从是基于binlog的,主上须开启binlog才能进行主从。
主从过程大致有3个步骤
1)主将更改操作记录到binlog里
2)从将主的binlog事件(sql语句)同步到从本机上并记录在relaylog(中继日志)里
3)从根据relaylog里面的sql语句按顺序执行
主上有一个log dump线程,用来和从的I/O线程传递binlog
从上有两个线程,其中I/O线程用来同步主的binlog并生成relaylog,另外一个SQL线程用来把relaylog里面的sql语句落地

JAVA多线程间的通信方式
- 同步
这里讲的同步是指多个线程通过synchronized关键字这种方式来实现线程间的通信。
这种方式,本质上就是“共享内存”式的通信。多个线程需要访问同一个共享变量,谁拿到了锁(获得了访问权限),谁就可以执行。 - while轮询的方式
会浪费CPU资源 - wait/notify机制
- 管道通信
https://www.cnblogs.com/hapjin/p/5492619.html
寻找无序数组中第k大的数
- 直接排序法 时间复杂度为O(nlogn)
- 堆选择法----最大堆 O(n+k*logn)
- 排序选择法—插入排序
- 期望线性时间的方法-随机选择法(使用快速排序)
https://blog.csdn.net/yc461515457/article/details/51177812
JVM垃圾回收算法
总共有四种
- 标记-清除算法
思想:算法分为两个阶段:标记阶段和清除阶段
在标记阶段中,标记从根节点开始所有可达的对象。因此未被标记的的对象就视为未被引用的垃圾对象,然后在清除阶段中清除未被标记的对象。
缺点:1. 效率不高 2. 容易造成内存碎片
- 标记-整理算法
思想:同样也是分为两个阶段:标记阶段和整理阶段
标记阶段主要做的工作也是从根节点出发,标记所有可达的对象,然后在整理阶段中将这些标记的对象移动到一个区域里,然后清除区域之外的对象。
优点:1. 解决了内存碎片的问题 2.对象创建时内存分配速度更快
缺点: 效率问题
- 复制算法
思想:将可用内存按容量分为大小相等的两部分,每次只使用其中的一块,当这一块内存用完了,就将还存活着的对象复制到另一块上面,然后把已经使用过的内存空间一次清理掉。
优点:效率高,没有内存碎片
缺点:1. 浪费一般的内存空间 2. 复制shouji0算法在对象存活率较高时要进行较多的赋值操作,效率将会变低。
- 分代收集算法
根据对象存活周期的不同将内存分为几块,一般分为新生代和老年代,然后根据各个代的特点采用最适当的收集算法。
在新生代中,每次垃圾收集都发现有大批对象死去,只有少量对象存活,选用复制算法
在老年代中,对象存活率比较高,没有额外的空间对它进行分配担保,选用“标记清除法”或者“标记整理法”
HotSpot 虚拟机默认 Eden 和 2 块 Survivor 的大小比例是 8:1:1
对象分配策略:1. 对象优先在 Eden 区域分配,如果对象过大直接分配到 Old 区域。 2. 长时间存活的对象进入到 Old 区域。
JVM垃圾收集器之CMS、G1
CMS收集器
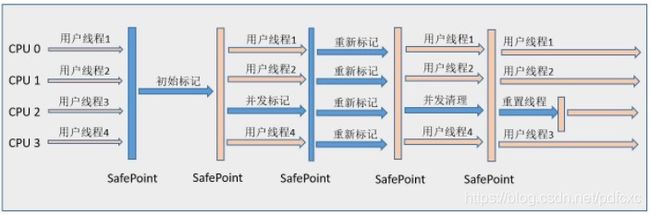
CMS(Concurrent Mark Sweep) 收集器是一种以获取最短回收停顿时间为目标的收集器,它非常符合那些集中在互联网站或者B/S系统的服务端上的Java应用,这些应用都非常重视服务的响应速度。从名字上(“Mark Sweep”)就可以看出它是基于“标记-清除”算法实现的。
CMS收集器工作的整个流程分为以下4个步骤:
- 初始标记(CMS initial mark) 仅仅只是标记一下GC Roots能直接关联到的对象,速度很快,需要“Stop The World”。
- 并发标记(CMS concurrent mark) 进行GC Roots Tracing的过程,在整个过程中耗时最长。
- 重新标记(CMS remark):为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短。此阶段也需要“Stop The World”。
- 并发清除(CMS concurrent sweep)
由于整个过程中耗时最长的并发标记和并发清除过程收集器线程都可以与用户线程一起工作,所以,从总体上来说,CMS收集器的内存回收过程是与用户线程一起并发执行的。通过下图可以比较清楚地看到CMS收集器的运作步骤中并发和需要停顿的时间:
优点
CMS是一款优秀的收集器,它的主要优点在名字上已经体现出来了:并发收集、低停顿,因此CMS收集器也被称为并发低停顿收集器(Concurrent Low Pause Collector)。
缺点
- 对CPU资源非常敏感 其实,面向并发设计的程序都对CPU资源比较敏感。在并发阶段,它虽然不会导致用户线程停顿,但会因为占用了一部分线程(或者说CPU资源)而导致应用程序变慢,总吞吐量会降低。CMS默认启动的回收线程数是(CPU数量+3)/4,也就是当CPU在4个以上时,并发回收时垃圾收集线程不少于25%的CPU资源,并且随着CPU数量的增加而下降。但是当CPU不足4个时(比如2个),CMS对用户程序的影响就可能变得很大,如果本来CPU负载就比较大,还要分出一半的运算能力去执行收集器线程,就可能导致用户程序的执行速度忽然降低了50%,其实也让人无法接受。
- 无法处理浮动垃圾(Floating Garbage 可能出现“Concurrent Mode Failure”失败而导致另一次Full GC的产生。由于CMS并发清理阶段用户线程还在运行着,伴随程序运行自然就还会有新的垃圾不断产生。这一部分垃圾出现在标记过程之后,CMS无法在当次收集中处理掉它们,只好留待下一次GC时再清理掉。这一部分垃圾就被称为“浮动垃圾”。也是由于在垃圾收集阶段用户线程还需要运行,那也就还需要预留有足够的内存空间给用户线程使用,因此CMS收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,需要预留一部分空间提供并发收集时的程序运作使用。
- 标记-清除算法导致的空间碎片 CMS是一款基于“标记-清除”算法实现的收集器,这意味着收集结束时会有大量空间碎片产生。空间碎片过多时,将会给大对象分配带来很大麻烦,往往出现老年代空间剩余,但无法找到足够大连续空间来分配当前对象。
G1收集器
G1(Garbage-First) 收集器是当今收集器技术发展最前沿的成果之一,它是一款面向服务端应用的垃圾收集器,HotSpot开发团队赋予它的使命是(在比较长期的)未来可以替换掉JDK 1.5中发布的CMS收集器。与其他GC收集器相比,G1具备如下特点:
- 并行与并发 G1能充分利用多CPU、多核环境下的硬件优势,使用多个CPU来缩短“Stop The World”停顿时间,部分其他收集器原本需要停顿Java线程执行的GC动作,G1收集器仍然可以通过并发的方式让Java程序继续执行。
- 分代收集 与其他收集器一样,分代概念在G1中依然得以保留。虽然G1可以不需要其他收集器配合就能独立管理整个GC堆,但它能够采用不同方式去处理新创建的对象和已存活一段时间、熬过多次GC的旧对象来获取更好的收集效果。
- 空间整合 G1从整体来看是基于“标记-整理”算法实现的收集器,从局部(两个Region之间)上来看是基于“复制”算法实现的。这意味着G1运行期间不会产生内存空间碎片,收集后能提供规整的可用内存。此特性有利于程序长时间运行,分配大对象时不会因为无法找到连续内存空间而提前触发下一次GC。
- 可预测的停顿 这是G1相对CMS的一大优势,降低停顿时间是G1和CMS共同的关注点,但G1除了降低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内,消耗在GC上的时间不得超过N毫秒,这几乎已经是实时Java(RTSJ)的垃圾收集器的特征了。
横跨整个堆内存
在G1之前的其他收集器进行收集的范围都是整个新生代或者老生代,而G1不再是这样。G1在使用时,Java堆的内存布局与其他收集器有很大区别,它 将整个Java堆划分为多个大小相等的独立区域(Region) ,虽然还保留新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,而都是一部分Region(不需要连续)的集合。
建立可预测的时间模型
G1收集器之所以能建立可预测的停顿时间模型,是因为它可以有计划地避免在整个Java堆中进行全区域的垃圾收集。G1跟踪各个Region里面的垃圾堆积的价值大小(回收所获得的空间大小以及回收所需时间的经验值),在后台维护一个优先列表 ,每次根据允许的收集时间,优先回收价值最大的Region(这也就是Garbage-First名称的来由)。这种使用Region划分内存空间以及有优先级的区域回收方式,保证了G1收集器在有限的时间内可以获取尽可能高的收集效率。
避免全堆扫描——Remembered Set
G1把Java堆分为多个Region,就是“化整为零”。但是Region不可能是孤立的,一个对象分配在某个Region中,可以与整个Java堆任意的对象发生引用关系。在做可达性分析确定对象是否存活的时候,需要扫描整个Java堆才能保证准确性,这显然是对GC效率的极大伤害。
为了避免全堆扫描的发生,虚拟机为G1中每个Region维护了一个与之对应的Remembered Set。虚拟机发现程序在对Reference类型的数据进行写操作时,会产生一个Write Barrier暂时中断写操作,检查Reference引用的对象是否处于不同的Region之中(在分代的例子中就是检查是否老年代中的对象引用了新生代中的对象),如果是,便通过CardTable把相关引用信息记录到被引用对象所属的Region的Remembered Set之中。当进行内存回收时,在GC根节点的枚举范围中加入Remembered Set即可保证不对全堆扫描也不会有遗漏。
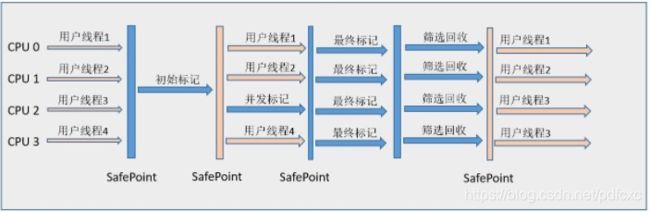
如果不计算维护Remembered Set的操作,G1收集器的运作大致可划分为以下几个步骤:
-
初始标记(Initial Marking) 仅仅只是标记一下GC Roots 能直接关联到的对象,并且修改TAMS(Nest Top Mark Start)的值,让下一阶段用户程序并发运行时,能在正确可以的Region中创建对象,此阶段需要停顿线程,但耗时很短。
-
并发标记(Concurrent Marking) 从GC Root 开始对堆中对象进行可达性分析,找到存活对象,此阶段耗时较长,但可与用户程序并发执行。
-
最终标记(Final Marking) 为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程的Remembered Set Logs里面,最终标记阶段需要把Remembered Set Logs的数据合并到Remembered Set中,这阶段需要停顿线程,但是可并行执行。
-
筛选回收(Live Data Counting and Evacuation) 首先对各个Region中的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划。此阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率。
通过下图可以比较清楚地看到G1收集器的运作步骤中并发和需要停顿的阶段(Safepoint处):
-
新生代GC(Minor GC) 指发生在新生代的垃圾收集动作,因为Java对象大多都具备朝生夕灭的特性,所以Minor GC非常频繁,一般回收速度也比较快。
-
老年代GC(Major GC / Full GC):指发生在老年代的GC,出现了Major GC,经常会伴随至少一次的Minor GC(但非绝对的,在Parallel Scavenge收集器的收集策略里就有直接进行Major GC的策略选择过程)。Major GC的速度一般会比Minor GC慢10倍以上。
双亲委派模型
双亲委派模型的工作过程?
- 当前 ClassLoader 首先从自己已经加载的类中,查询是否此类已经加载,如果已经加载则直接返回原来已经加载的类。每个类加载器都有自己的加载缓存,当一个类被加载了以后就会放入缓存,等下次加载的时候就可以直接返回了。
- 当前 ClassLoader 的缓存中没有找到被加载的类的时候委托父类加载器去加载,父类加载器采用同样的策略,首先查看自己的缓存,然后委托父类的父类去加载,一直到 bootstrap ClassLoader。当所有的父类加载器都没有加载的时候,再由当前的类加载器加载,并将其放入它自己的缓存中,以便下次有加载请求的时候直接返回。
为什么优先使用父 ClassLoader 加载类?
- 共享功能:可以避免重复加载,当父亲已经加载了该类的时候,子类不需要再次加载,一些 Framework 层级的类一旦被顶层的 ClassLoader 加载过就缓存在内存里面,以后任何地方用到都不需要重新加载。
- 隔离功能:主要是为了安全性,避免用户自己编写的类动态替换 Java 的一些核心类,比如 String ,同时也避免了重复加载,因为 JVM 中区分不同类,不仅仅是根据类名,相同的 class 文件被不同的 ClassLoader 加载就是不同的两个类,如果相互转型的话会抛 java.lang.ClassCaseException 。
线程的生命周期?
线程一共有5个状态:
新建(new):当创建Thread类的一个实例(对象)时,此线程进入新建状态(未被启动)。例如:Thread t1 = new Thread() 。可运行(runnable),也称为就绪:线程对象创建后,其他线程(比如 main 线程)调用了该对象的 start 方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取 cpu 的使用权。例如:t1.start() 。运行(running):线程获得 CPU 资源正在执行任务(#run() 方法),此时除非此线程自动放弃 CPU 资源或者有优先级更高的线程进入,线程将一直运行到结束。死亡(dead):当线程执行完毕或被其它线程杀死,线程就进入死亡状态,这时线程不可能再进入就绪状态等待执行。- 自然终止:正常运行完 #run()方法,终止。
- 异常终止:调用 stop() 方法,让一个线程终止运行。
堵塞(blocked):由于某种原因导致正在运行的线程让出 CPU 并暂停自己的执行,即进入堵塞状态。直到线程进入可运行(runnable)状态,才有机会再次获得 CPU 资源,转到运行(running)状态。阻塞的情况有三种:- 正在睡眠:调用 sleep(long t) 方法,可使线程进入睡眠方式。一个睡眠着的线程在指定的时间过去可进入可运行(runnable)状态。
- 正在等待:调用 #wait() 方法。调用 notify() 方法,回到就绪状态。
- 被另一个线程所阻塞:调用 #suspend() 方法。调用 #resume() 方法,就可以恢复。
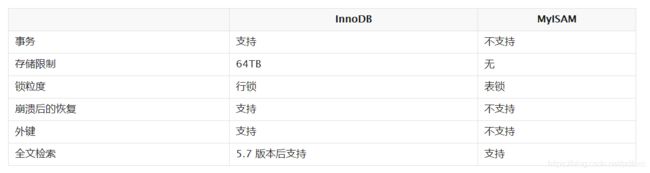
mysql两个引擎介绍以及区别
InnoDB
- 支持事务。
- 支持行级锁和表级锁,能支持更多的并发量。
- 查询不加锁,完全不影响查询。
- 支持崩溃后恢复。
MyISAM
- 不支持事务。
- 使用表级锁,如果数据量大,一个插入操作锁定表后,其他请求都将阻塞。
forward和redirect的区别
- 请求方不同:
- redirect:客户端发起的请求
- forward:服务端发起的请求
- 浏览器地址表现不同:
- redirect:浏览器地址显示被请求的url
- forward:浏览器地址不显示被请求的url
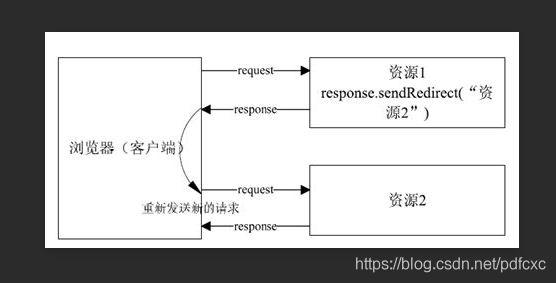
- 参数传递不同
- redirect:重新开始一个request,原页面的request生命周期结束。
- forward:forward另一个连接的时候。request变量是在其生命周期内的。另一个页面也可以使用,其实质是把目标地址include。
- 底层运作不同
- redirect:发送的请求信息又回送给客户机,让客户机再转发到另一个资源上,需要在服务器和客户机之间增加一次通信。
- forward:服务器端直接找到目标,并include过来。
- 定义不同
- 直接转发方式(Forward):客户端和浏览器只发出一次请求,Servlet、HTML、JSP或其它信息资源,由第二个信息资源响应该请求,在请求对象request中,保存的对象对于每个信息资源是共享的。
- 间接转发方式(Redirect)实际是两次HTTP请求,服务器端在响应第一次请求的时候,让浏览器再向另外一个URL发出请求,从而达到转发的目的。
最小生成树
一.概述
图的生成树是它的一颗含有其所有顶点的无环连通子图,一幅加权图的最小生成树(MST)是它的一颗权值(树中的所有边的权值之和)最小的生成树.下图为一幅加权无向图和它的最小生成树.(箭头不指示方向,标红的为最小生成树).
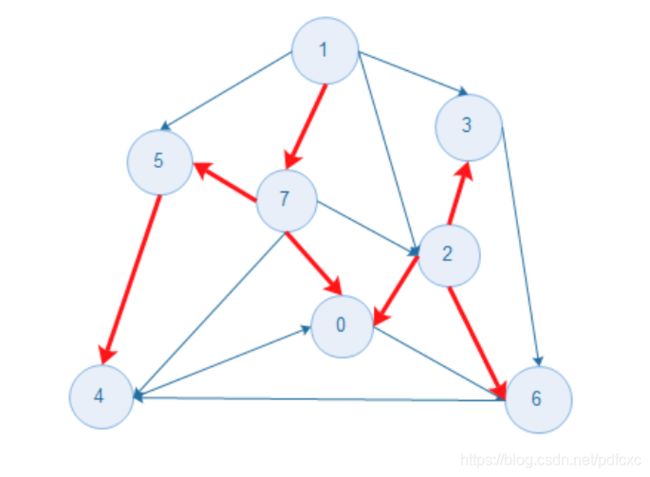
二.原理
- 图的一种切分是将图的所有顶点分为两个非空且不重叠的两个集合.横切边是连接两个属于不同集合的顶点的边.
- 切分定理:在一幅加权图中,给定任意的切分,它的横切边中的权重最小者必然属于最小生成树.
prim 算法
运用贪心算法??
主要思想:
给定连通图G和任意根节点r,最小生成树从结点r开始,一直长大到覆盖V中所有结点为止,即不断寻找轻量级边以实现最小权重和
最短路径算法
https://www.cnblogs.com/skywang12345/p/3711516.html
红黑树
红黑树的特性:
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]
(4)如果一个节点是红色的,则它的子节点必须是黑色的。
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
注意:
(01) 特性(3)中的叶子节点,是只为空(NIL或null)的节点。
(02) 特性(5),确保没有一条路径会比其他路径长出俩倍。因而,红黑树是相对是接近平衡的二叉树。
红黑树示意图如下:
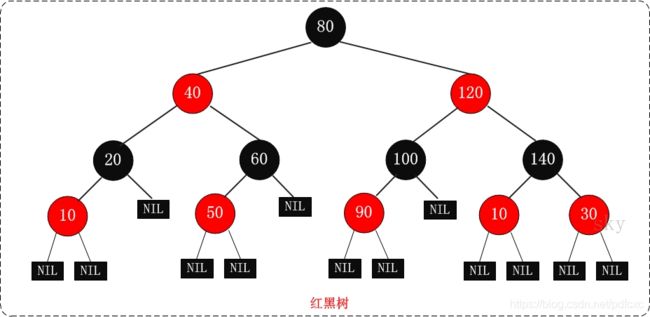
红黑树的时间复杂度为: O(logn)
红黑树和AVL树(平衡二叉树)区别
一、 AVL树(平衡二叉树)
(1)简介
AVL树是带有平衡条件的二叉查找树,一般是用平衡因子差值判断是否平衡并通过旋转来实现平衡,左右子树的高度不超过1,和红黑树相比,AVL树是严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过1)。不管我们是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡,而旋转非常耗时,由此我们可以知道AVL树适合用于插入与删除次数比较少,但查找多的情况。
(2)局限性
由于维护这种高度平衡所付出的代价比从中获得的效率收益还大,故而实际的应用不多,更多的地方是用追求局部而不是非常严格整体平衡的红黑树。当然,如果应用场景中对插入删除不频繁,只是对查找要求较高,那么AVL还是较优于红黑树。
二、红黑树
(1)简介
一种二叉查找树,但在每个节点增加一个存储位表示节点的颜色,可以是红或黑(非红即黑)。通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其它路径长出两倍,因此,红黑树是一种弱平衡二叉树(由于是弱平衡,可以看到,在相同的节点情况下,AVL树的高度低于红黑树),相对于要求严格的AVL树来说,它的旋转次数少,所以对于搜索,插入,删除操作较多的情况下,我们就用红黑树。
为什么说B+树比B树更适合做操作系统的数据库索引和文件索引?
- B+树的磁盘读写的代价更低
B+树内部结点没有指向关键字具体信息的指针,这样内部结点相对B树更小。
- B+树的查询更加的稳定
因为非终端结点并不是最终指向文件内容的结点,仅仅是作为叶子结点中关键字的索引。这样所有的关键字的查找都会走一条从根结点到叶子结点的路径。所有的关键字查询长度都是相同的,查询效率相当。
statement和preparedstatement的区别
该 PreparedStatement接口继承Statement,并与之在两方面有所不同:
PreparedStatement 实例包含已编译的 SQL 语句。这就是使语句“准备好”。包含于 PreparedStatement 对象中的 SQL 语句可具有一个或多个 IN 参数。IN参数的值在 SQL 语句创建时未被指定。相反的,该语句为每个 IN 参数保留一个问号(“?”)作为占位符。每个问号的值必须在该语句执行之前,通过适当的setXXX 方法来提供。
由于 PreparedStatement 对象已预编译过,所以其执行速度要快于 Statement 对象。因此,多次执行的 SQL 语句经常创建为 PreparedStatement 对象,以提高效率。
作为 Statement 的子类,PreparedStatement 继承了 Statement 的所有功能。另外它还添加了一整套方法,用于设置发送给数据库以取代 IN 参数占位符的值。同时,三种方法 execute、 executeQuery 和 executeUpdate 已被更改以使之不再需要参数。这些方法的 Statement 形式(接受 SQL 语句参数的形式)不应该用于 PreparedStatement 对象。
常见的面向对象设计原则
- 单一职责原则(SRP) 一个类只负责一个功能领域中的相应职责,或者可以定义为:就一个类而言,应该只有一个引起它变化的原因。
- 开放关闭原则(OCP) 一个软件实体应当对扩展开放,对修改关闭。即软件实体应尽量在不修改原有代码的情况下进行扩展。
- 里氏替换原则(LSP) 子类型能够替换掉它们的父类型。
- 依赖倒置原则(DIP) 要依赖于抽象,不要依赖于具体类,要做到依赖倒置,应该做到:
- 高层模块不应该依赖底层模块,二者都应该依赖于抽象。
- 抽象不应该依赖于具体实现,具体实现应该依赖于抽象。
- 接口隔离原则(ISP) 使用多个专门的接口,而不使用单一的总接口,即客户端不应该依赖那些它不需要的接口。
- 迪米特法则,又叫最少知识原则(LKP) 一个软件实体应当尽可能少地与其他实体发生相互作用。
- 其他原则:
- 面向接口编程
- 优先使用组合,而非继承
- 一个类需要的数据应该隐藏在类的内部
- 类之间应该零耦合,或者只有传导耦合,换句话说,类之间要么没关系,要么只使用另一个类的接口提供的操作
- 在水平方向上尽可能统一地分布系统功能
CDN
CDN就可以理解为分布在每个县城的火车票代售点,用户在浏览网站的时候,CDN会选择一个离用户最近的CDN边缘节点来响应用户的请求,这样海南移动用户的请求就不会千里迢迢跑到北京电信机房的服务器(假设源站部署在北京电信机房)上了。
CDN的优势很明显:(1)CDN节点解决了跨运营商和跨地域访问的问题,访问延时大大降低;(2)大部分请求在CDN边缘节点完成,CDN起到了分流作用,减轻了源站的负载。
https://www.cnblogs.com/tinywan/p/6067126.html
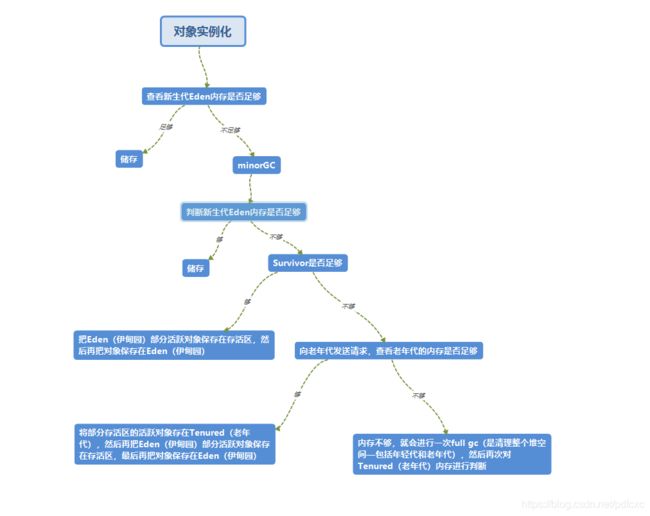
JVM具体会在什么时候进行垃圾回收
数据库连接池到底应该设置多大
一般设置为2*核心数
如果太多,则线程切换浪费时间
如果太少,不能发挥出硬件真正的性能
数据库范式
第一范式: 无重复的列
数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。 在第一范式(1NF)中表的每一行只包含一个实例的信息。简而言之,第一范式就是无重复的列。
第二范式:属性完全依赖于主键
如果关系模式R为第一范式,并且R中每一个非主属性完全函数依赖于R的某个候选键, 则称为第二范式模式。
第三范式: 属性不依赖于其它非主属性 [ 消除传递依赖 ]
第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。
例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在的员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。
BCNF范式:
若关系模式R是第一范式,且每个属性都不传递依赖于R的候选键。这种关系模式就是BCNF模式。即在第三范式的基础上,数据库表中如果不存在任何字段对任一候选关键字段的传递函数依赖则符合鲍依斯-科得范式。