Hadoop系列(一)Docker部署Hadoop集群
搭建一个Hadoop集群环境时需要多台服务器,对于我们个人,这通常是个门槛,需要使用虚拟机,安装操作系统,然后运行起来多个虚机。
安装操作系统是个不太轻松的任务,并且运行多个虚机对个人电脑性能也有一定要求,这些门槛影响了很多小伙伴的实践积极性
使用Docker的话就简单了,不用安装操作系统,直接下载一个镜像,如centos,这样操作系统就有了,基于这个系统镜像运行多个容器,就相当于起了多个虚机,而且系统性能的消耗要远小于虚拟机。
假设我们有一个 centos7 镜像,启动多个容器,每个容器都有一个IP,都能通过SSH连接操作,这样就可以在每个容器中安装 JAVA Hadoop,从而搭建起集群环境了。
使用Docker搭建Hadoop集群的过程包括:
- 1、安装Docker
- 2、获取centos镜像
- 3、安装SSH
- 4、构建Hadoop镜像
- 5、为容器配置IP及SSH无密码登陆
- 6、配置Hadoop
- 7、Hadoop集群启动测试
一、安装Docker
第1步比较简单,参考Docker系列之前的文章Docker简介及安装
二、获取centos镜像
$ docker pull centos查看镜像列表的命令:
$ docker images三、安装SSH
以centos7镜像为基础,构建一个带有SSH功能的centos,使用Dockerfile创建
$ vi Dockerfile内容:
FROM centos
MAINTAINER dys
RUN yum install -y openssh-server sudo
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
RUN yum install -y openssh-clients
RUN echo "root:111111" | chpasswd
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
RUN mkdir /var/run/sshd
EXPOSE 22
CMD ["/usr/sbin/sshd", "-D"]这段内容的大意是:以 centos 镜像为基础,安装SSH的相关包,设置了root用户的密码为 111111,并启动SSH服务
执行构建镜像的命令,新镜像命名为 centos7-ssh
$ docker build -t="centos7-ssh" .执行完成后,可以在镜像列表中看到centos7-ssh镜像
$ docker images四、构建Hadoop镜像
以前面构建的centos7-ssh镜像为基础,安装Java、Hadoop构建Hadoop镜像
$ vi Dockerfile内容:
FROM centos7-ssh
ADD jdk-8u101-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1.8.0_101 /usr/local/jdk1.8
ENV JAVA_HOME /usr/local/jdk1.8
ENV PATH $JAVA_HOME/bin:$PATH
ADD hadoop-2.7.3.tar.gz /usr/local
RUN mv /usr/local/hadoop-2.7.3 /usr/local/hadoop
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH
RUN yum install -y which sudo这里是基于 centos7-ssh 这个镜像,把 JAVA 和 Hadoop 的环境都配置好了
前提:在Dockerfile所在目录下准备好 jdk-8u101-linux-x64.tar.gz 与 hadoop-2.7.3.tar.gz
执行构建命令,新镜像命名为 hadoop
$ docker build -t="hadoop" .运行3个hadoop容器,分别命名为 hadoop0,hadoop1,hadoop2,hadoop0 作为master
$ docker run --name hadoop0 --hostname hadoop0 -d -P -p 50070:50070 -p 8088:8088 hadoop
$ docker run --name hadoop1 --hostname hadoop1 -d -P hadoop
$ docker run --name hadoop2 --hostname hadoop2 -d -P hadoop
容器hadoop0启动时,映射了端口号,50070和8088,是用来在浏览器中访问hadoop WEB界面的。
查看容器是否都正常启动:
$ docker ps五、为容器配置IP及SSH无密码登陆
参考这篇文章 Docker系列(四)Docker 网络模式及IP配置
5.1、为容器配置IP
设置固定IP,需要用到 pipework,用于给容器设置IP
#先下载
$ git clone https://github.com/jpetazzo/pipework.git
$ cp pipework/pipework /usr/local/bin/
#安装bridge-utils
$ yum -y install bridge-utils
#创建网络
$ brctl addbr br1
$ ip link set dev br1 up
$ ip addr add 192.168.10.1/24 dev br1此时已经创建好网桥br1,为前面启动的容器hadoop0、hadoop1、hadoop2分别指定IP
配置IP
$ pipework br1 hadoop0 192.168.10.30/24
$ pipework br1 hadoop1 192.168.10.31/24
$ pipework br1 hadoop2 192.168.10.32/24分别使用 ping 与 ssh 命令进行验证,看是否可以ping通和成功登录
$ ping 192.168.10.30
$ ssh 192.168.10.305.2、容器间SSH无密码登陆
前面已经为容器配置IP了,在进行ssh 时需要输入要登陆的容器的root密码,Hadoop集群要求集群间机器SSH连接时无密码登陆,下面讲述容器间如何配置 SSH无密码登陆。
新开3个终端窗口,分别连接到 hadoop0,hadoop1,hadoop2,便于操作
$ docker exec -it hadoop0 /bin/bash
$ docker exec -it hadoop1 /bin/bash
$ docker exec -it hadoop2 /bin/bash(1)修改HOST
在各个容器中修改 /etc/hosts,添加:
192.168.10.30 hadoop0
192.168.10.31 hadoop1
192.168.10.32 hadoop2注意:将原先容器创建时产生的host去掉,比如172.17.0.0这个网段的host,具体类似如下:
172.17.0.1 hadoop0(2)SSH无密码登陆配置
Hadoop镜像时基于centos7-ssh镜像创建的,而centos7-ssh镜像在centos镜像基础上安装了SSH相关的工具包,所以在每个Hadoop容器命令窗口内执行下面命令:
$ ssh-keygen
(执行后会有多个输入提示,不用输入任何内容,全部直接回车即可)
$ ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop0
$ ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop1
$ ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop2#测试
$ ssh hadoop1
#测试完,回退到原先窗口
$ exit六、配置Hadoop
(1)环境确认检查
在配置Hadoop之前,在hadoop0、hadoop1、hadoop2各命令窗口检查下java、hadoop环境变量是否设置正确(构建Hadoop镜像的时候,已经安装Java、Hadoop并设置了相关环境变量)
$ java
$ hadoop如上述两命令不起作用,则需要手动配置下两者的环境变量
$ vi /etc/profile添加以下环境变量
export JAVA_HOME=/opt/module/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin加载刷新环境变量
source /etc/profile重新检查下java 和hadoop命令
(2)Hadoop文件配置
hadoop0中执行
$ cd /opt/module/hadoop
$ mkdir tmp hdfs
$ mkdir hdfs/data hdfs/name1、core-site.xml配置
vi /opt/module/hadoop/etc/hadoop/core-site.xml在 < configuration> 块儿中添加:
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop0:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/opt/module/hadoop/tmpvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>131702value>
property>2、hdfs-site.xml配置
vi /opt/module/hadoop/etc/hadoop/hdfs-site.xml在 < configuration> 块儿中添加:
<property>
<name>dfs.namenode.name.dirname>
<value>file:/opt/module/hadoop/hdfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/opt/module/hadoop/hdfs/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>hadoop0:9001value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>3、mapred-site.xml配置
这个文件默认不存在,需要从 mapred-site.xml.template 复制过来
$ cp mapred-site.xml.template mapred-site.xmlvi /opt/module/hadoop/etc/hadoop/mapred-site.xml在 < configuration> 块儿中添加:
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop0:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoop0:19888value>
property>4、yarn-site.xml配置
vi /opt/module/hadoop/etc/hadoop/yarn-site.xml在 < configuration> 块儿中添加:
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>hadoop0:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>hadoop0:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>hadoop0:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>hadoop0:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>hadoop0:8088value>
property>5、slaves配置
vi /opt/module/hadoop/etc/hadoop/slaves删除已有内容,添加:
hadoop1
hadoop26、hadoop-env.sh配置
找到 export JAVA_HOME=${JAVA_HOME},改为自己JAVA_HOME的绝对路径,比如:
export JAVA_HOME=/opt/module/hadoop/jdk1.87、hadoop集群配置分发
在 hadoop0 上执行
$ scp -r /opt/module/hadoop hadoop1:/opt/module
$ scp -r /opt/module/hadoop hadoop2:/opt/module注意:如果各台服务器中JAVA_HOME位置不同,记得对 hadoop-env.sh 进行相应修改
七、Hadoop集群启动测试
(1)、集群启动
在主节点(hadoop0)启动hadoop,从节点(hadoop1、hadoop2)会自动启动
1、初始化
第一次启动集群时,需要初始化
$ hdfs namenode -format2、依次启动配置文件
$ hadoop-daemon.sh start namenode
$ hadoop-daemon.sh start datanode
$ start-dfs.sh
$ start-yarn.sh
$ mr-jobhistory-daemon.sh start historyserver附:停止hadoop集群
$ hadoop-daemon.sh stop namenode
$ hadoop-daemon.sh stop datanode
$ stop-dfs.sh
$ stop-yarn.sh
$ mr-jobhistory-daemon.sh stop historyserver注:hadoop集群启动和停止可以使用start/stop-all.sh,但不推荐。
3、检查
查看状态,在3台服务器上分别执行jps
[root@hadoop0 hadoop]# jps
10257 Jps
9122 JobHistoryServer
8675 SecondaryNameNode
8376 DataNode
8281 NameNode
8828 ResourceManager
[root@hadoop0 hadoop]# [root@hadoop1 hadoop]# jps
2263 NodeManager
2152 DataNode
2523 Jps
[root@hadoop1 hadoop]# 浏览器中访问(宿主机Host可以配置下hadoop0的IP地址):
http://hadoop0:50070/
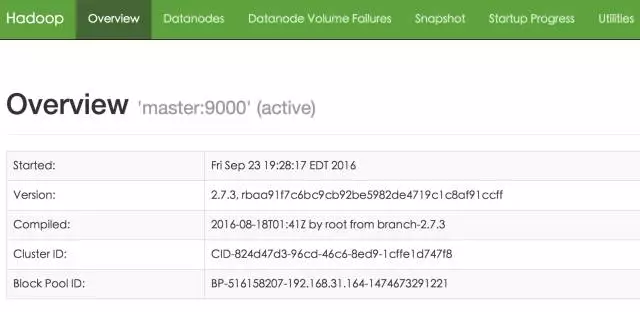
http://hadoop0:8088/
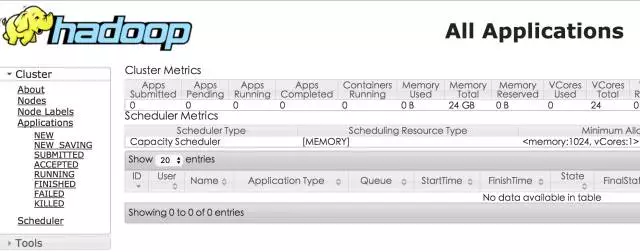
可以正常访问的话,可以说明集群启动成功了,但不一定可以正常运行,还需要下面的实际验证。
(2)测试验证
1、hdfs 操作
创建本地测试文件
在/opt/module/hadoop目录下创建测试文件目录
$ mkdir wcinput
$ cd wcinput
$ vi wc.inputwc.input文件内容如下:
hadoop mapreduce
hadoop yarn
hadoop hdfs
mapreduce spark
hadoop hello创建HDFS目录
$ hdfs dfs -mkdir -p /user/hadoop/input上传文件,把测试文件上传到刚刚创建的目录中
$ hdfs dfs -put /opt/module/hadoop/wcinput/wc.input /user/hadoop/input查看文件上传是否正确
[root@hadoop0 hadoop]# hdfs dfs -ls /user/hadoop/input
Found 1 items
-rw-r--r-- 2 root supergroup 71 2018-04-17 09:12 /user/hadoop/input/wc.input
[root@hadoop0 hadoop]# 运行mapreduce程序
hadoop 安装包中提供了一个示例程序,我们可以使用它对刚刚上传的文件进行测试
hadoop jar /home/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /user/hadoop/input /user/hadoop/output注:在执行过程中,如果长时间处于 running 状态不动,虽然没有报错,但实际上是出错了,后台在不断重试,需要到 logs 目录下查看日志文件中的错误信息。
查看输出结果
[root@hadoop0 hadoop]# hdfs dfs -ls /user/hadoop/output
Found 2 items
-rw-r--r-- 2 root supergroup 0 2018-04-17 09:14 /user/hadoop/output/_SUCCESS
-rw-r--r-- 2 root supergroup 51 2018-04-17 09:14 /user/hadoop/output/part-r-00000
[root@hadoop0 hadoop]# _SUCCESS表示HDFS文件状态,生成的结果在part-r-00000中,可查看
[root@hadoop0 hadoop]# hdfs dfs -cat /user/hadoop/output/part-r-00000
hadoop 4
hdfs 1
hello 1
mapreduce 2
spark 1
yarn 1
[root@hadoop0 hadoop]# 总结:以上就是使用Docker环境搭建Hadoop镜像容器,配置Hadoop集群,并启动和测试的实例,测试用的是hadoop官方给的一个wordcount统计,利用hadoop安装包里的mapreduce示例jar 计算指定HDFS文件里的单词数,并将结果输出到指定HDFS目录。后面会介绍HDFS常用文件操作命令。
参考文章:
https://blog.csdn.net/u011537073/article/details/52799371
https://mp.weixin.qq.com/s?__biz=MzA4Nzc4MjI4MQ==&mid=2652402238&idx=1&sn=44d2a68fb5097db61daacc061ce9d300&scene=21#wechat_redirect