超详细记录Ubuntu16.04.1 3台服务器上Hadoop2.7.3完全分布式集群部署过程。包含,Ubuntu服务器创建、远程工具连接配置、Ubuntu服务器配置、Hadoop文件配置、Hadoop格式化、Hadoop启动。
Hadoop欢迎页面:
集群规划:
| 主机名/hostname |
IP |
角色 |
| master |
192.168.182.129 |
ResourceManager/NameNode/SecondaryNameNode |
| slave1 |
192.168.182.130 |
NodeManager/DataNode |
| slave2 |
192.168.182.131 |
NodeManager/DataNode |
1.0.准备
1.1.目录
- 用VMware创建3个Ubuntu虚拟机
- 用mobaxterm远程连接创建好的虚拟机
- 配置Ubuntu虚拟机源、ssh无密匙登录配置、jdk安装
- 配置Hadoop集群文件
- 启动Hadoop集群、在Windows主机上显示集群状态。
1.2.提前准备安装包
- Windows7(宿主操作系统)
- VMware-workstation-full-12.0.0-2985596.exe(虚拟机)
- ubuntu-16.04.1-server-amd64.iso 服务器版
- hadoop-2.7.3.tar.gz
- jdk-8u111-linux-x64.tar.gz
- xShell(远程连接工具)
2. VMvare安装Ubuntu16.04.1服务器版过程
2.1.注意在安装时username要一致如shun,即主机用户名。而主机名hostname可不同,如使用master,slave1,slave2区分hostname主机名。
2.2.VMvare安装Ubuntu16.04.1桌面版过程
2.3.在VMvare中选择 文件 然后 新建虚拟机
2.4选择典型安装
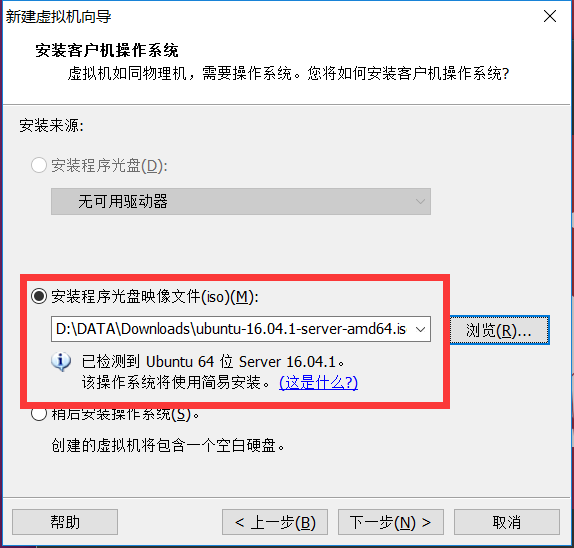
2.5.选择下载好的Ubuntu64位 16.04.1服务器版镜像,选择“安装程序光盘映射文件”,选择到“ubuntu-16.04.1-server-amd64.iso”镜像文件,下一步
2.6.个性化Linux设置,全名三个虚拟机都填写shun,用户名/密码填写shun/shun66,下一步
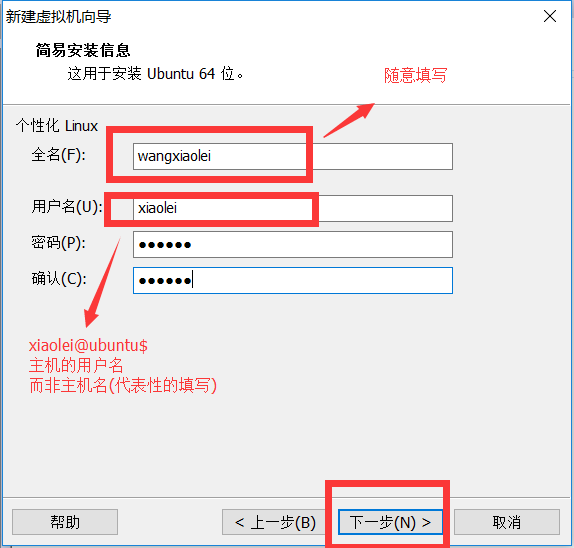
2.7.虚拟机命名及文件路径 master\slave1\slave2等,位置填写F:\VMData\Virtual Machines\master或者F:\VMData\Virtual Machines\slave1或者F:\VMData\Virtual Machines\slave2,下一步
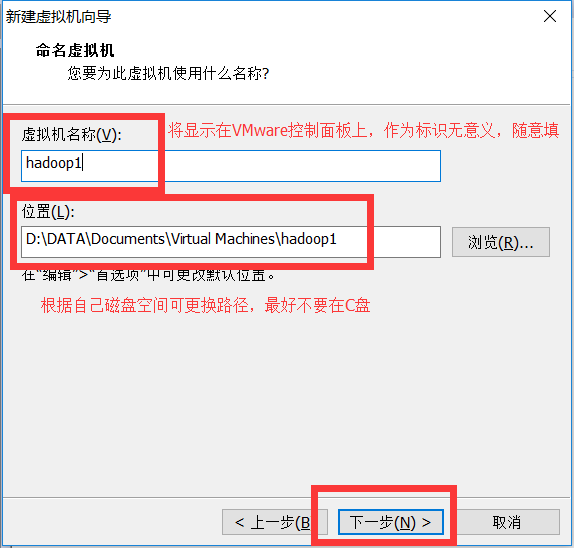
2.8.磁盘分配,默认即可,磁盘大小可以根据自身硬盘空间调节(不要太小)
2.9.然后就是等待安装完成,输入登录名 shun登录密码**…
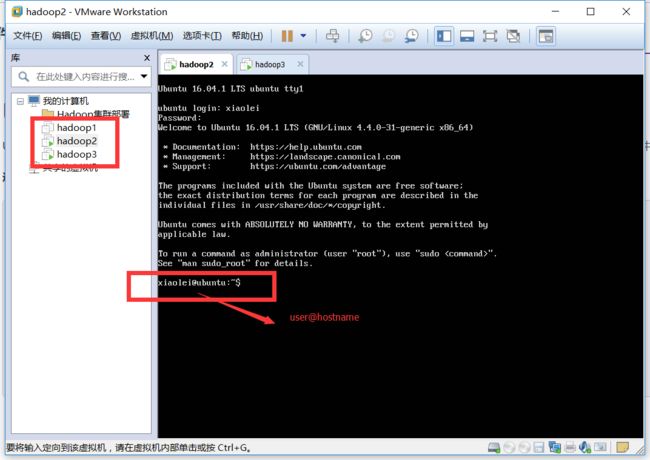
建立好的虚拟机如下:
通过ifconfig命令查看每台服务器IP地址:
IP 192.168.182.129 默认主机名ubuntu
IP 192.168.182.130 默认主机名ubuntu
IP 192.168.182.131 默认主机名ubuntu
下一步会修改主机名hostname
3. 配置Ubuntu系统(服务器版在VMware中操作不方便,通过远程在putty或者MobaXterm操作比较快捷些)
3.1 安装ssh即可。这里不需要 ssh-keygen。
打开终端或者服务器版命令行
查看是否安装(ssh)openssh-server,否则无法远程连接。
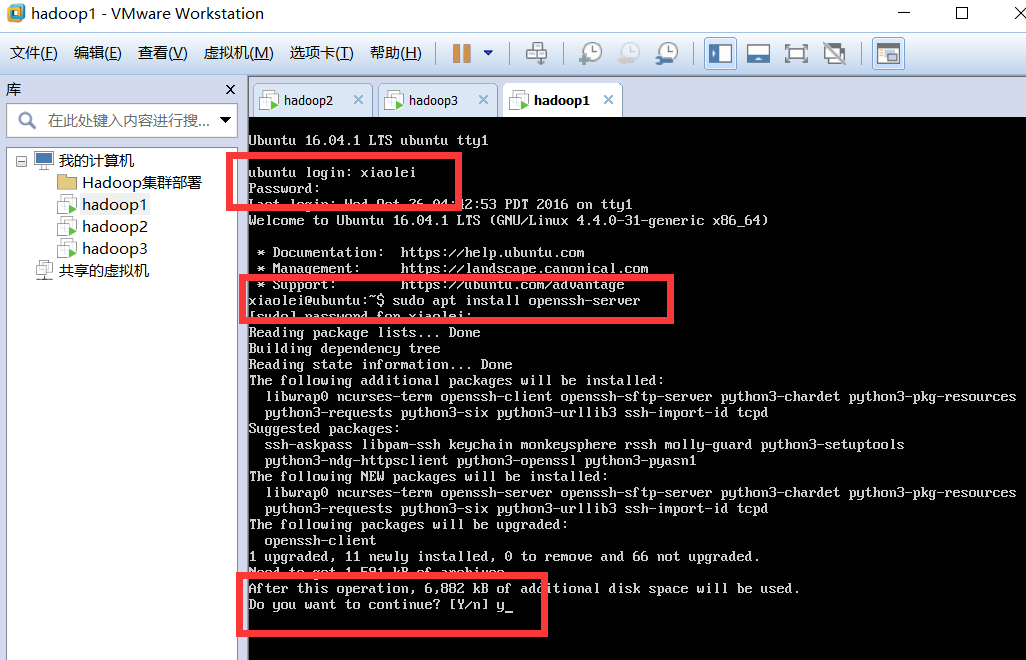
sshd
sudo apt install openssh-server
3.2.安装ssh后,可以通过工具(xShell)远程连接已经建立好的服务器(master,slave1,slave2)
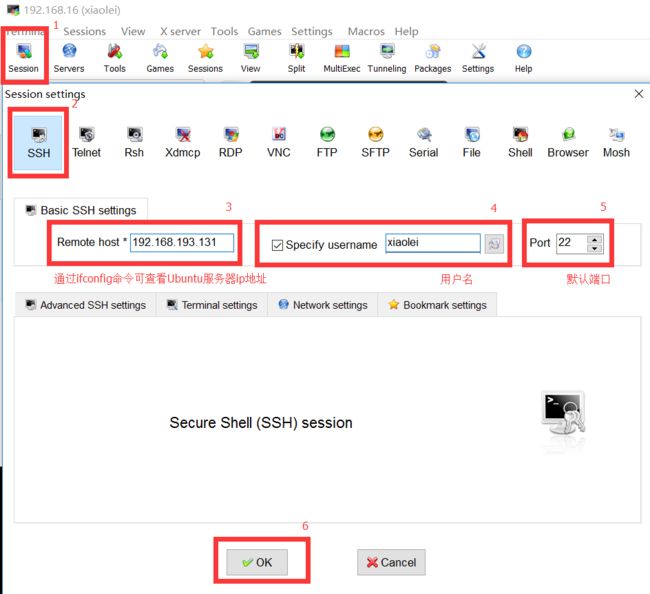
同样三个虚拟机建立连接
3.3.更换为国内源(清华大学帮助文档)
在master、slave1、slave2中
shun@ubuntu:~$ sudo vi /etc/apt/sources.list
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial main main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security main restricted universe multiverse
# 预发布软件源,不建议启用
# deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-proposed main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-proposed main restricted universe multiverse
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
更新源
shun@ubuntu:~$ sudo apt update
3.4.安装vim编辑器,默认自带vi编辑器
sudo apt install vim
更新系统(服务器端更新量小,桌面版Ubuntu更新量较大,可以暂时不更新)
sudo apt-get upgrade
3.5.修改Ubuntu服务器hostname主机名,主机名和ip是一一对应的。
shun@ubuntu:~$ sudo hostname master
shun@ubuntu:~$ sudo hostname slave1
shun@ubuntu:~$ sudo hostname slave2
3.6.增加hosts文件中ip和主机名对应字段
在master\slave1\slave2服务器中设置hosts
shun@master:~$ sudo vim /etc/hosts
192.168.182.129 master
192.168.182.130 slave1
192.168.182.133 slave2
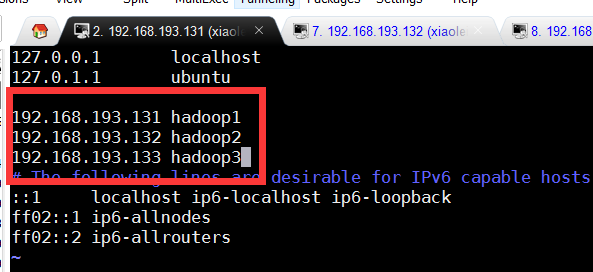
3.7.修改服务器master\slave1\slave2的系统时区(将时间同步更改为北京时间)
shun@master:~$ date
Wed Oct 26 02:42:08 PDT 2016
shun@master:~$ sudo tzselect
根据提示选择Asia China Beijing Time yes (一次选择相应项对应的序号数)
最后将Asia/Shanghai shell scripts 复制到/etc/localtime
shun@hadoop1:~$ sudo cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
shun@ubuntu:~$ date
Wed Oct 26 17:45:30 CST 2016
4. Hadoop集群完全分布式部署过程
4.1.安装JDK1.8
4.1.1将所需文件(Hadoop2.7.3、JDK1.8)上传至Hadoop1服务器(可以直接复制粘贴)
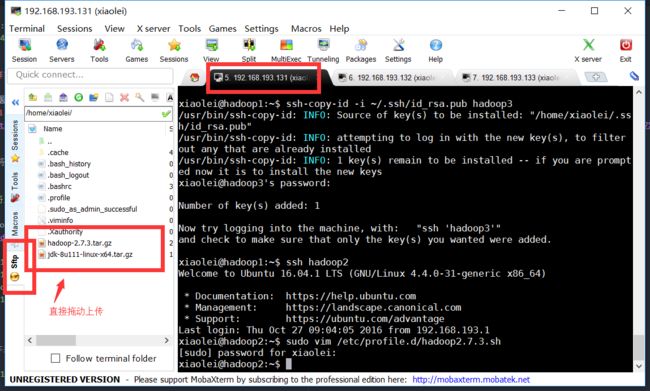
4.1.2.解压缩并将jdk放置/opt路径下
shun@master:~$ tar -zxf jdk-8u111-linux-x64.tar.gz
shun@master:~$ sudo mv jdk1.8.0_111 /opt/
[sudo] password for master:
shun@master:~$
4.1.3.配置环境变量
编写环境变量脚本并使其生效
shun@master:~$ sudo vim /etc/profile.d/jdk1.8.sh
输入内容
#!/bin/sh
export JAVA_HOME=/opt/jdk1.8.0_111
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
shun@master:~$ source /etc/profile
4.1.4.验证jdk成功安装
shun@master:~$ java -version
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build 1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)
4.1.5.同样方法安装其他集群机器。
也可通过scp命令
shun@master:~$ scp jdk-8u111-linux-x64.tar.gz slave1:
shun@master:~$ scp jdk-8u111-linux-x64.tar.gz slave2:
命令解析:scp 远程复制 -r 递归 本机文件地址 app是文件,里面包含jdk、Hadoop包 远程主机名@远程主机ip:远程文件地址
4.2.集群ssh无密匙登录设置
4.2.1.在master,slave1,slave2中执行
sudo apt install ssh
sudo apt install rsync
shun@master:~$ ssh-keygen -t rsa //一路回车就好(会提示输入,直接回车,不需要填写)
4.2.2.在 master(master角色)服务器上 执行,将~/.ssh/下的id_rsa.pub公私作为认证发放到master,slave1,slave2的~/.ssh/下
ssh-copy-id -i ~/.ssh/id_rsa.pub master
ssh-copy-id -i ~/.ssh/id_rsa.pub slave1
ssh-copy-id -i ~/.ssh/id_rsa.pub slave2设置完后,通过#ssh localhost测试,第一次登录会有如下提示:
The authenticity of host 'localhost (127.0.0.1)' can't be established.
RSA key fingerprint is a2:44:5f:79:00:c9:17:3b:b4:b5:47:cf:66:be:c4:0d.
Are you sure you want to continue connecting (yes/no)?
输入yes后,之后就不需要了。(必须操作)
4.2.3.然后在 master上登录其他Linux服务器不需要输入密码即成功。
#不需要输入密码
ssh slave1
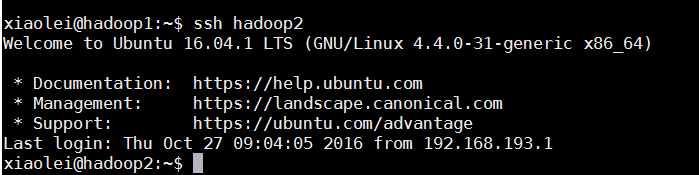
5.hadoop完全分布式集群文件配置和启动
在master上配置完成后将Hadoop包直接远程复制scp到其他Linux主机即可。
在master上解压:tar -zxf hadoop-2.7.3.tar.gz
Linux主机Hadoop集群完全分布式分配
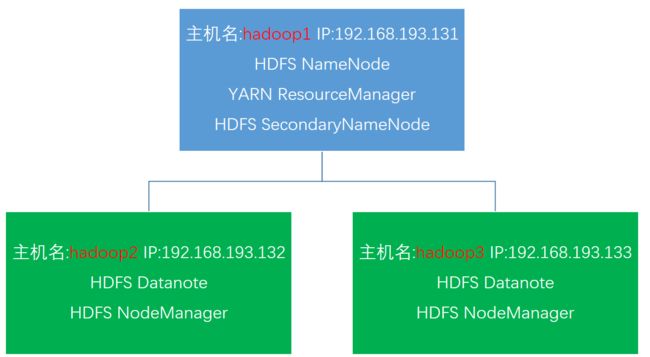
5.1.Hadoop主要文件配置
5.1.1.在Hadoop1,2,3中配置Hadoop环境变量
shun@master:~$ sudo vim /etc/profile.d/hadoop2.7.3.sh
输入
#!/bin/sh
export HADOOP_HOME="/opt/hadoop-2.7.3"
export PATH="$HADOOP_HOME/bin:$PATH"
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
5.1.2.配置..\hadoop-2.7.3\etc\hadoop\hadoop-env.sh 增加如下内容
export JAVA_HOME=/opt/jdk1.8.0_111
5.1.3.配置..\hadoop-2.7.3\etc\hadoop\slaves文件,增加slave主机名
slave1
slave2
5.1.4.配置..\hadoop-2.7.3\etc\hadoop\core-site.xml,创建/home/shun/hadoop/tmp目录
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/shun/hadoop/tmpvalue>
property>
configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
5.1.5.配置..\hadoop-2.7.3\etc\hadoop\hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>master:50090value>
property> <property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/home/shun/hadoop/hdfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/home/shun/hadoop/hdfs/datavalue>
property>
configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
5.1.6.配置..\hadoop-2.7.3\etc\hadoop\yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>master:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>master:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>master:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>master:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>master:8088value>
property>
configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
5.1.7.配置..\hadoop-2.7.3\etc\hadoop\mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:19888value>
property>
configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
5.1.8.复制Hadoop配置好的包到其他Linux主机
shun@master:~$ scp -r hadoop-2.7.3 slave1:shun@master:~$ scp -r hadoop-2.7.3 slave2:
将每台服务器上的Hadoop包sudo mv移动到/opt/路径下。不要sudo cp,注意权限。
shun@master:sudo mv hadoop-2.7.3 /opt/
5.2.格式化节点
在hadoop1上执行
shun@master:/opt/hadoop-2.7.3$ bin/hadoop namenode -format
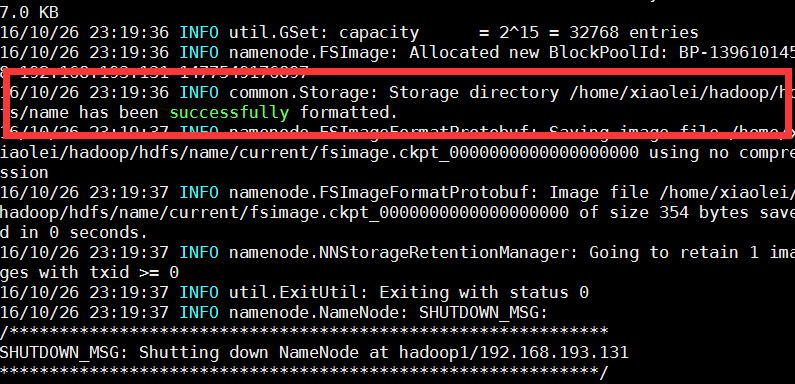
5.3.hadoop集群全部启动
### 5.3.1. 在master上执行
shun@master:/opt/hadoop-2.7.3/sbin$ ./start-all.sh
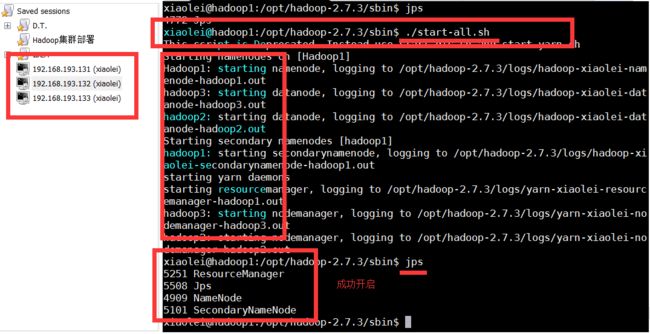
5.3.2.其他主机上jps

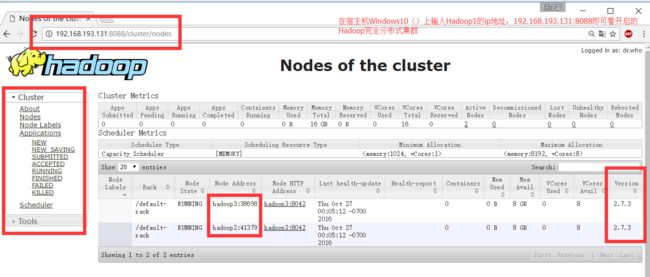
5.3.3.在主机上查看,博主是Windows7,直接在浏览器中输入master集群地址即可。
http:
5.4.可能问题:
权限问题:
chown -R shun:shun hadoop-2.7.3
解析:将hadoop-2.7.3文件属主、组更换为shun:shun
chmod 777 hadoop
解析:将hadoop文件权限变成421 421 421 可写、可读可、执行即 7 7 7
查看是否安装openssh-server
ssd
或者
ps -e|grep ssh
安装 openssh-server
sudo apt install openssh-server
问题解决:
问题
Network error: Connection refused
解决安装
Network error: Connection refused