sqlserver 执行计划
一个很好的手册分享,执行计划里的属性解释官方文档:https://docs.microsoft.com/zh-cn/sql/relational-databases/showplan-logical-and-physical-operators-reference?view=sql-server-2017
想复杂的事情简单说,在看执行计划的其他文章的时候,发现直接上很复杂的DDL脚本来讲解,这样子可能打开就没有兴趣往下看了。所以这里用了一个最简单的select语句进行说明引新入门。
打开
注意这三个【L型图标】,可以把鼠标移动到按钮上方可以显示【解释文字】。
图中从左到右分别为【显示估计的执行计划】【包括实际的执行计划】【包括实时查询统计信息】。
【显示估计的执行计划】是执行某个DDL的估计值。
【包括实际的执行计划】【包括实时查询统计信息】都是执行实际的值,所以你选择后,它会在下次执行后出执行结果。
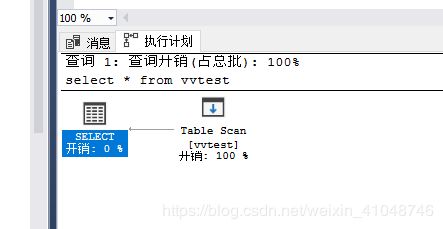
结果分析
这是一个简单的查询,鼠标点击图片中的图片或线上都有惊喜(大量细节信息展示)。执行计划可以通过“另存”操作将某一次结果保留下来,方便与日后进行结果对比。
除了图标外,线的粗细代表涉及到的数据量的大小,越粗代表数据量越大。
执行计划元素列表如下:
| Select (Result) | Sort | Spool |
| Clustered Index Scan | Key Lookup | Eager Spool |
| NonClustered Index Scan | Compute Scalar | Stream Aggregate |
| Clustered Index Seek | Constant Scan | Distribute Streams |
| NonClustered Index Seek | Table Scan | Repartition Streams |
| Hash Match | RID Lookup | Gather Streams |
| Nested Loops | Filter | Bitmap |
| Merge Join | Lazy Spool | Split |
执行计划元素列表解释请参考:
https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms175913(v=sql.105)
https://lvraikkonen.github.io/2017/06/02/%E7%9C%8B%E6%87%82SQL%20Server%E6%89%A7%E8%A1%8C%E8%AE%A1%E5%88%92/
结果细节图
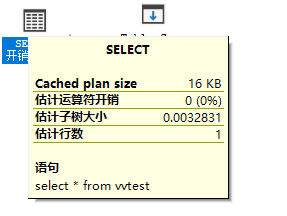
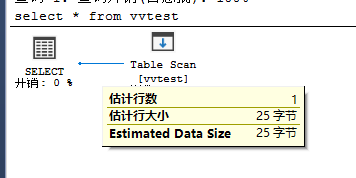
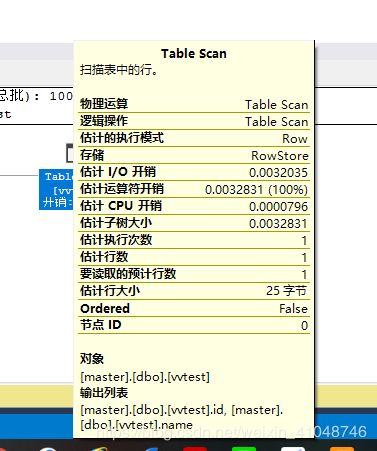
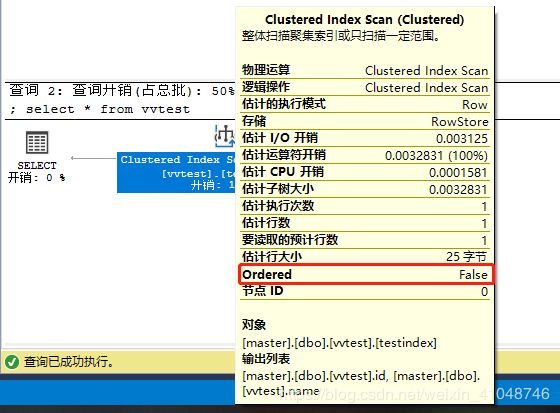
其中,第三个图中的属性Ordered是与order by相关。如下面两个脚本:
select * from vvtest order by id;
select * from vvtest两个执行计划的结果如下:

所谓数据访问就是直接访问数据,可以是访问一个表也可以是访问一个索引。
通常有两种方法:一种是扫描(scan)一种是查找(seek)。
- scan就是读取整个结构,可以访问一个heap或者一个clustered索引或者一个non-clustered索引。
- seek不会读取整个结构,他则是更高效地通过索引访问一行,所以从这个角度来看,查找就只能应用在索引上面了。简单总结如下表所示:
首先分析最右边的Table Scan。这是sqlserver 查询数据的方法。sqlserver 数据查询方式一共有五种:
1. 【Table Scan】:遍历整个表,查找所有匹配的记录行。这个操作将会一行一行的检查,当然,效率也是最差的。
2. 【Index Scan】:根据索引,从表中过滤出来一部分记录,再查找所有匹配的记录行,显然比第一种方式的查找范围要小,因此比【Table Scan】要快。
3. 【Index Seek】:根据索引,定位(获取)记录的存放位置,然后取得记录,因此,比起前二种方式会更快。
4. 【Clustered Index Scan】:和【Table Scan】一样。注意:不要以为这里有个Index,就认为不一样了。 其实它的意思是说:按聚集索引来逐行扫描每一行记录,因为记录就是按聚集索引来顺序存放的。 而【Table Scan】只是说:要扫描的表没有聚集索引而已,因此这二个操作本质上也是一样的。
5. 【Clustered Index Seek】:直接根据聚集索引获取记录,最快!
所以总体来讲,在查询结果集是相同数量的情况下,查询速度排序为5>3>2>4>1。
一般而言,在性化时可以看到执行记录时是不是【Table Scan】或者【Clustered Index Scan】,如果是,可以通过增加或修改索引类型进行效率上的对比。
Lookup类型
我是真的服气这么多名词解释。
Bookmark Lookup、RID Lookup、Key Lookup。
Bookmark Lookup和Key Lookup是一个意思,等价。
如果表没有创建聚集索引则称为Bookmark Lookup,如果表中没有聚集索引但是存在非聚集索引我们称为RID Lookup。
为什么突然扯了一嘴Lookup呢?因为Lookup其实就是与执行计划里的scan或index相关。如果聚集索引命中就是指Bookmark Lookup——聚集索引命中的时候,很大概率是索引不能带出select所需的某一部分字段或者是全部字段,所以需要先命中一行,然后把某一行的数据全带出来。非聚集索引命中就是指RID Lookup。
SQL SERVER如何选择执行计划
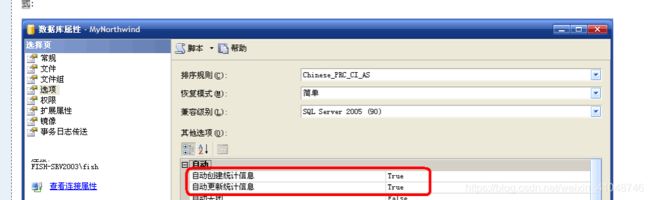
sqlserver选择某个执行计划,执行计划用某个索引,是这有一个权重判断的。这个权重在执行前都计算出来了。那怎么查看呢——通过【索引统计信息】。在执行脚本的过程中,sqlserver会根据这些统计信息,选择一个它认为是最合适的方法去执行查询过程。统计信息可以自动定时更新,在SQL Server中也有个参数来控制这个更新方式。
语法
DBCC SHOW_STATISTICS ("Person.Address", AK_Address_rowguid);
这里的引号很重要,没会报错。
主要有两个参数:
第一个:是表名或者是索引视图名(给视图加的索引)
第二个:索引名、列名、统计信息。
结果属性介绍
索引前缀集是什么?索引前缀和前缀索引不是一个东西。
索引前缀是指索引的选择性——根据索引定义时的字段顺序来决定索引是否被命中。如果是索引(a,b,c),命中查询的时候是查询条件中有(a) (a,b) (a,b,c)进行命中,但是(b,c)这个查询条件不会命中该索引。所以索引前缀也叫索引列前缀集。
前缀索引说白了就是对文本的前几个字符(具体是几个字符在建立索引时指定)建立索引,这样建立起来的索引更小,所以查询更快。
| 属性 | 介绍 | 备注 |
|---|---|---|
| 表1 | 列出了这个索引统计信息的主要信息。 | -- |
| Name | 统计信息的名称 | 语法里的第二个参数 |
| Updated | 上一次更新统计信息的日期和时间。 | |
| Rows | 表中的行数。 | |
| Rows Sampled | 统计信息的抽样行数。 | |
| Step | 数据可分成多少个组,与第三个表有多少行相对应。 |
|
| Desity | 中文翻译:密度。根据索引列计算不同值的分布密度。 | Calculated as 1 / distinct values for all values in the first key column of the statistics object |
| Average key Length | 所有索引列的平均长度。 | |
| String Index | 如果为“YES”,则统计信息中包含字符串摘要索引,以支持为 LIKE 条件估算结果集大小。仅适用于 char、varchar、nchar 和 nvarchar、varchar(max)、nvarchar(max)、text 以及 ntext 数据类型的前导列 | |
| Filter Expression | 谓词表达式 | |
| Unfiltered Rows | 上面的Filter Expression所操作的数据总行数 为NULL,代表Filter Expression没有匹配到具体数据。 |
|
| 表2 | 它列出各种字段组合的选择性,数据越小表示重复越性越小,当然选择性也就越高。 | -- |
| All density | 索引列前缀集的选择性(包括 EQ_ROWS)。注意:这个值越小就表示选择性越高。 | 如果这个值小于0.1,这个索引的选择性就比较高,反之,则表示选择性就不高了。 |
| Average Length | 索引列前缀集的平均长度。 | |
| Columns | 为其显示 All density 和 Average length 的索引列前缀的名称 | |
| 表3 | 数据分布的直方图,SQL Server就是靠它预估一些执行步骤的数据量。 | -- |
| RANGE_HI_KEY | 直方图的数据最大值 | |
| RANGE_ROWS | 每组数据组的估算行数,不包含最大值。 | |
| EQ_ROWS | 每组数据组中与最大值数据(RANGE_HI_KEY)相等的行数目 | 估计值 |
| DISTINCT_RANGE_ROWS | 每组数据组中的非重复值的估算数目,不包含最大值。 | |
| AVG_RANGE_ROWS | 每组数据组中的重复值的平均数目,不包含最大值,计算公式:RANGE_ROWS / DISTINCT_RANGE_ROWS for DISTINCT_RANGE_ROWS > 0 | |
执行计划详细属性介绍
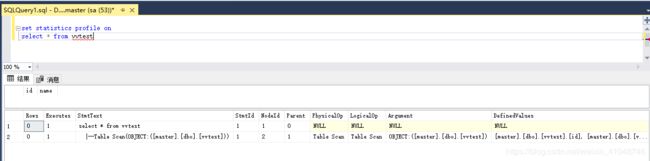
在执行DDL之前,输入一句set statistics profile on 。显示一个表格,表格内是比图上更细节的实际的执行信息。针对这个表的属性做一个整理解析。
| 属性 | 字段介绍 | 备注 |
|---|---|---|
| Rows(重要属性) | 在某个步骤中,实时产生的记录条数 | 真实数据 |
| Executes(重要属性) | 某个步骤被执行的次数。 | 真实数据 |
| StmtTest(重要属性) | 执行步骤的描述 1) |--Table Scan(OBJECT:([master].[dbo].[vvtest])) 2) |--Clustered Index Scan(OBJECT:([master].[dbo].[vvtest].[ClusteredIndex-20190531-153224])) 3)select * from vvtest |
1和2是加了没有聚集索引和把id作聚集索引后的对比。3是DDL是执行计划最外层的脚本执行。2中的加黑部分是在查询方式是Clustered Index Scan的时候他使用到的索引名称。 所以这个属性可以看到使用的索引和实际步骤里执行的DDL脚本。 |
| StmtId | 当前执行语句的单条DDL的编号。 |
set statistics profile on select * from vvtest order by id;——这条就是1 select * from vvtest——这条就是2 |
| NodeId | 单条DDL里的步骤编号。 | 从1开始,单个执行计划中箭头最右边是1,最左边(被指的)依次增加,代表单个DDL内的执行顺序。 |
| Parent | 与该条步骤相关的下一步步骤编号(NodeId) | |
| PhysicalOp | sqlserver 数据查询方式,包括但是不限于我们上面提到的五种Table Scan…… | 只有节点类型Type=PLAN_ROWS 的才有这个属性。Type属性在下方介绍 |
| LogicalOp | 关系运算符 | 只有节点类型Type=PLAN_ROWS 的才有这个属性。Type属性在下方介绍 |
| Argument | 被PhysicalOp执行的对象,细节信息,比如说当前被使用到的列名或表名 | 举例: Sort——ORDER BY:([master].[dbo].[vvtest].[id] ASC) Table Scan ——OBJECT:([master].[dbo].[vvtest]) |
| DefinedValues | 将DDL语句进行细化成一个用逗号分隔的列表。 | |
| EstimateRows | 估计返回多少行数据 | 估计值 |
| EstimateIO | 估计IO开销,单位是 | 估计值 |
| EstimateCPU | 估计CPU开销,计算的是CP占用率(百分比) | 估计值 |
| AvgRowSize | 估计本步骤的数据每行平均的字节数,单位是bytes | 估计值 |
| TotalSubtreeCost | 估计的本步骤和本步骤涉及到所有子步骤的总消耗的占总的百分比 | 估计值 |
| OutPutList | 这个属性是一个用逗号分隔的列表。列表里是本步骤执行的DDL,输出涉及到对应表的列名。 | 列名集合 |
| Warnings | 用逗号分隔的列表,本步骤DDL会触发的警告信息。 | |
| Type | 节点类型 | 1)如果是陈述性SQL,那么Type的值为SELECT, INSERT, EXECUTE等。 2)如果是执行计划的子节点(如索引执行的描述),那么Type的值为PLAN_ROW |
| Parallel | 并行标志。 0-本步骤不能并行执行 1-本步骤可以并行执行 |
|
| EstimateExecutions | 估计本步骤在总的执行中被执行的次数。 | 估计值。 有可能在脚本中步骤被执行N次 |
以上属性的英文版的解释在:
https://docs.microsoft.com/en-us/sql/t-sql/statements/set-showplan-all-transact-sql?view=sql-server-2017
参考文档:https://www.cnblogs.com/fish-li/archive/2011/06/06/2073626.html
https://docs.microsoft.com/en-us/sql/t-sql/database-console-commands/dbcc-show-statistics-transact-sql?view=sql-server-2017