机器学习历史
目录
综述
监督学习
无监督学习
半监督学习
深度学习
强化学习
参考博客
综述
最早的机器学习算法可以追溯到20世纪初,到今天为止,已经过去了100多年。总体上,机器学习算法可以分为有监督学习、无监督学习、半监督学习、强化学习4种类型。
监督学习 又称为又教师学习,可以理解为有教师教机器的学习过程,说的专业点就是有数据标签,“标签”就是教师。
无监督学习 就是自己学自己的,自己归纳数据中的知识,没有老师教,没有数据标签。
半监督学习 有的数据有标签,有的数据没有标签。
强化学习 算法根据当前的环境状态确定一个动作来执行,然后进入下一个状态,如此反复,目标是让得到的收益最大化。如围棋游戏就是典型的强化学习问题,在每个时刻,要根据当前的棋局决定在什么地方落棋,然后进行下一个状态,反复的放置棋子,直到赢得或者输掉比赛。这里的目标是尽可能的赢得比赛,以获得最大化的奖励。
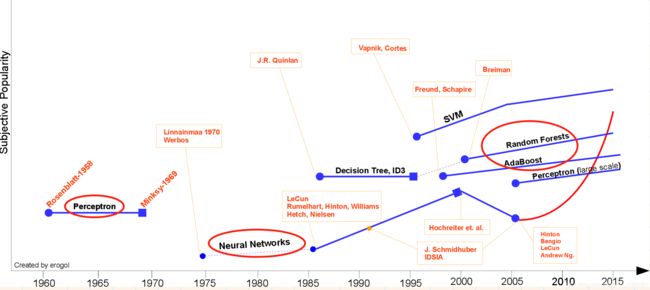 感知机---集成学习---深度学习
感知机---集成学习---深度学习
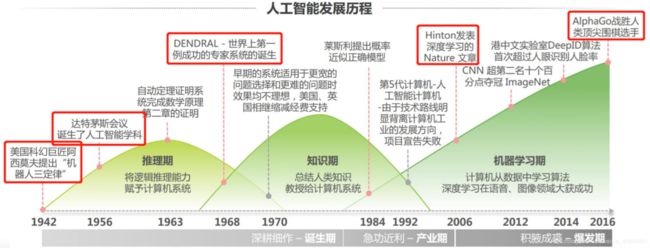 人工智能的两段寒冬分别是1974-1980年和1987-1993年
人工智能的两段寒冬分别是1974-1980年和1987-1993年
监督学习
1936年Fisher发明了LDA,那个时候还没有机器学习的概念;贝叶斯分类器起步于1950年代,基于贝叶斯决策理论。
在1980年之前,这些机器学习算法都是零碎化的,不成体系。从1980年开始,机器学习才真正成为一个独立的方向,从此之后,各种机器学习算法被大量提出,机器学习得到了飞速的发展。
1986年诞生了用于训练多层神经网络的真正意义上的反向传播算法;1989年,LeCun设计出了第一个真正意义上的卷积神经网络,用于手写数字的识别;1990年代是机器学习百花齐放的年代。在1995年诞生了两种经典的算法SVM和AdaBoost,此后它们纵横江湖数十载,神经网络则黯然失色。
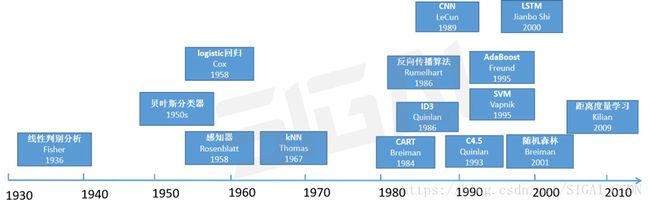 LDA---LSTM
LDA---LSTM
无监督学习
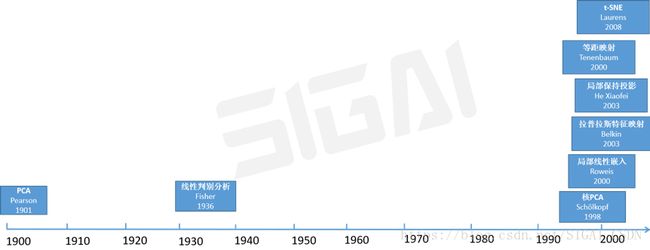
聚类分析的早期研究始于 60 年前——K-means算法的出现,它最初在1955年由Steinhaus提出,随后Stuart Lloyd 在 1957 年提出K-均值聚类算法。随后其一直受到青睐,并延伸出了凝聚分层算法(agglomerative hierarchical algorithm)和基于密度的空间聚类(Density-Based Spatial Clustering of Applications with Noise/DBSCAN) 等。主成分分析(PCA)则由卡尔·皮尔逊于1901年发明,用于分析数据及建立数理模型。1930s由哈罗德·霍特林演进并命名。这也是一种十分成熟并且常用的无监督算法。
异常检测的发展历史则相对较晚一些,虽然统计界早在19世纪就已经研究了检测数据中的异常值或异常,但直到1986年,Dorothy Denning教授才系统的提出了入侵检测系统(IDS)的异常检测方法。
1977年诞生了EM算法,它不光被用于聚类问题,还被用于求解机器学习中带有缺数数据的各种极大似然估计问题。
更多的内容需移步 https://www.jiqizhixin.com/graph/technologies/0a61589e-451d-43d2-a4d6-dc63529fa559
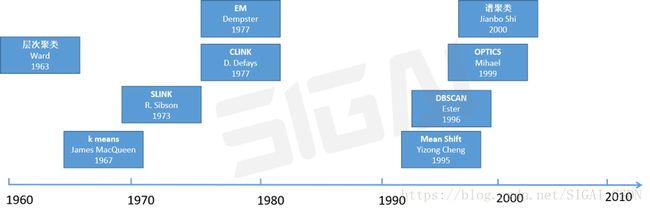 层次聚类---EM---谱聚类
层次聚类---EM---谱聚类
数据降维在机器学习领域没有出现太多重量级的成果。直到1998年,核PCA作为非线性降维算法的出现。这是核技术的又一次登台,与PCA的结合将PCA改造成了非线性的降维算法。
t-SNE是降维算法中年轻的成员,诞生于2008年,虽然想法很简单,效果却非常好。
 PCA---LDA---核PCA
PCA---LDA---核PCA
概率图模型是机器学习算法中独特的一个分支,它是图与概率论的完美结合。隐马尔可夫模型诞生于1960年,在1980年代,它在语音识别中取得了成功,一时名声大噪,后来被广泛用于各种序列数据分析问题,在循环神经网络大规模应用之前,处于主导地位。马尔可夫随机场诞生于1974年,也是一种经典的概率图模型算法。贝叶斯网络是概率推理的强大工具,诞生于1985年,其发明者是概率论图模型中的重量级人物,后来获得了图灵奖。条件随机场是概率图模型中相对年轻的成员,被成功用于中文分词等自然语言处理,还有其他领域的问题,也是序列标注问题的有力建模工具。

半监督学习
SSL的研究历史可以追溯到20世纪70年代,这一时期,出现了自训练(Self-Training)、直推学习(Transductive Learning)、生成式模型(Generative Model)等学习方法。
90年代,新的理论的出现,以及自然语言处理、文本分类和计算机视觉中的新应用的发展,促进了SSL的发展,出现了协同训练(Co-Training)和转导支持向量机(Transductive Support Vector Machine,TSVM)等新方法。Merz等人在1992年提出了SSL这个术语,并首次将SSL用于分类问题。接着Shahshahani和Landgrebe展开了对SSL的研究。协同训练方法由Blum和Mitchell提出,基于不同的视图训练出两个不同的学习机,提高了训练样本的置信度。Vapnik和Sterin提出了TSVM,用于估计类标签的线性预测函数。为了求解TSVM,Joachims提出了SVM方法,Bie和Cristianini将TSVM放松为半定规划问题从而进行求解。许多研究学者广泛研究将期望最大算法(Expectation Maximum,EM)与高斯混合模型(Gaussian Mixture Model,GMM)相结合的生成式SSL方法。Blum等人提出了最小割法(Mincut),首次将图论应用于解决SSL问题。Zhu等人提出的调和函数法(Harmonic Function)将预测函数从离散形式扩展到连续形式。由Belkin等人提出的流形正则化法(Manifold Regularization)将流形学习的思想用于SSL场景。Klein等人提出首个用于聚类的半监督距离度量学习方法,学习一种距离度量。
深度学习
真正意义上的人工神经网络诞生于1980年代,反向传播算法也早就被提出,卷积神经网络、LSTM等早就别提出,但遗憾的是神经网络在过去很长一段时间内并没有得到大规模的成功应用,在于SVM等机器学习算法的较量中处于下风。原因主要有:算法本身的问题,如梯度消失问题,导致深层网络难以训练。训练样本数的限制。计算能力的限制。直到2006年,情况才慢慢改观。
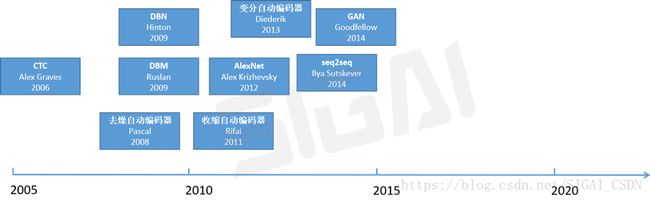
强化学习
强化学习在机器学习领域的起步更晚。虽然早在1980年代就出现了时序差分算法[42-44],但对于很多实际问题,我们无法用表格的形式列举出所有的状态和动作,因此这些抽象的算法无法大规模实用。
神经网络与强化学习的结合,即深度强化学习,才为强化学习带来了真正的机会。在这里,深度神经网络被用于拟合动作价值函数即Q函数,或者直接拟合策略函数,这使得我们可以处理各种复杂的状态和环境,在围棋、游戏、机器人控制等问题上真正得到应用。神经网络可以直接根据游戏画面,自动驾驶汽车的摄像机传来的图像,当前的围棋棋局,预测出需要执行的动作。其典型的代表是DQN这样的用深度神经网络拟合动作价值函数的算法,以及直接优化策略函数的算法。

参考博客
https://blog.csdn.net/SIGAI_CSDN/article/details/82428499
https://www.jiqizhixin.com/graph/technologies/0a61589e-451d-43d2-a4d6-dc63529fa559