Cascade R-CNN 论文翻译
翻译仅为学习,如有侵权请联系我删除。
翻译不当之处请多多指教。
摘要
在目标检测中,交并比(loU)阈值是用来定义正样本和负样本的。用低阈值,例如0.5,训练的目标探测器通常会产生噪声。然而,检测性能随着阈值的增加而下降。造成这一现象的主要原因有两个:
- 训练过程中由于正样本指数性消失导致的过拟合;
- 检测器最优的IoU与输入假设之间的推断时间不匹配。
针对这些问题,提出了一种多级目标检测结构——级联R-CNN。它由一系列经过训练的检测器组成,这些检测器的IoU阈值不断增加,从而对相似性误报(FP,正样本被判负)具有更强的选择性。对检测器的训练是逐步进行的,利用了这样的观察:检测器的输出是用于训练下一个更高质量检测器的良好分布。通过对逐步改进的假设进行重新采样,可以保证所有检测器都具有一组相同大小的正样本集,从而减少了过拟合问题。推断时采用相同的级联过程,使假设与各阶段的检测器质量更接近。级联R-CNN的一个简单实现被证明在具有挑战性的COCO数据集上超越了所有单一模型目标检测器。实验还表明,级联R-CNN具有广泛的应用前景能够跨越检测器架构,实现与基线检测器强度无关的一致增益。
1. 引言
目标检测是一个复杂的问题,需要解决两个主要任务。首先,检测器必须解决识别问题,区分前景对象和背景对象,并为其分配合适的对象类标签。其次,探测器必须解决定位问题,将准确的边界框分配给不同的对象。这两个任务都特别困难,因为检测器面临许多“相似的”误报,对应于“相似但不正确”的边界框。检测器应该在抑制这些相似的的误报的同时能找到正确的正样本。
最近提出的许多目标检测器都是基于两阶段R-CNN框架[14,13,30,23],其中检测被框定为一个结合分类和边界框回归的多任务学习问题。与目标识别不同,需要使用 IoU 阈值来定义正/负。然而,常用的阈值u,通常为 u=0.5,对正样本的要求比较宽松。产生的检测器经常产生有噪声的边界框,如图1(a)所示。大多数人会认为相似的误报的假设经常通过IoU≥0.5测试。虽然在u=0.5标准下组装的例子是丰富和多样化的,但它们使训练能够有效地拒绝相似性误报的检测器变得困难。
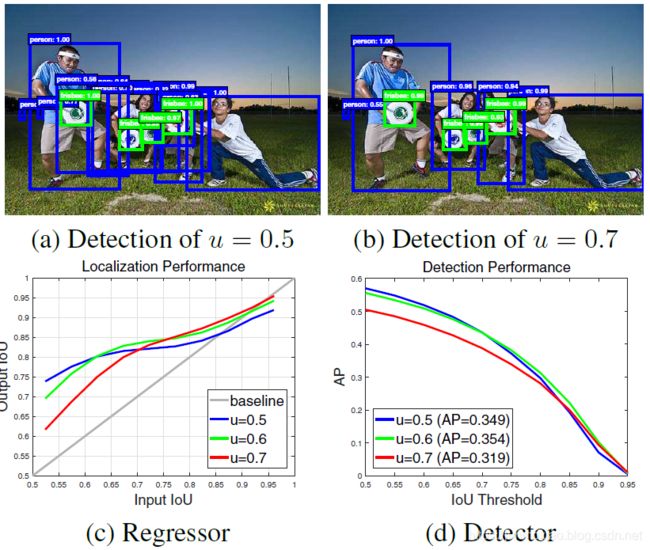
图1.提高IOU阈值u的目标检测器的检测输出、定位和检测性能。
在这项工作中,我们定义一个假设的量作为它与真框值的 IoU,和检测器的量作为用来训练它的 IoU 阈值 u。迄今为止的目的是去研究少有研究过的问题:学习高质量的目标检测器,其输出包含很少的相似性误报,如图1(b)所示。其基本思想是,单个检测器只能用于单量级。这在代价敏感学习文献[7,26]中已经知道,其中对接收机工作特性(ROC)不同点的优化需要不同的损失函数。主要的区别在于,我们考虑的是给定的 loU 阈值的优化,而不是误报率。
图1( c )和( d )分别给出了三种训练 IoU 阈值 u=0.5、0.6、0.7的检测器的定位性能和检测性能。定位性能作为输入方案的 IoU的函数进行评估,检测性能作为loU阈值的函数进行评估,如COCO[22]。注意,在图1( c )中,每个边框回归器对于接近检测器训练的阈值的loU样本表现最佳。这也适用于检测性能,直到过拟合。图1( d )显示,对于低 IoU 的样本,u=0.5 的检测器的性能优于 u=0.6 的检测器,但在较高的loU水平上表现较差。一般来说,在一个单 IoU 水平上优化的检测器不一定在其他水平上是最优的。这些观察结果表明,更高质量的检测需要检测器和它处理的假设之间更紧密的质量匹配。一般来说,一个检测器只有在提交高质量的提议时才能具有高质量。(两步提交,第一步生成提议,第二步识别提议)
无论如何,要产生高质量的检测器,仅仅增加训练中的 u 是不够的。事实上,从图1( d )中u=0.7的检测器可以看出,这会降低检测性能。问题是,一个提议检测器的假设分布通常严重不平衡,导致质量低下。一般来说,强行增大 IoU 阈值会导致正训练样本指数性变少。这对于神经网络来说尤其成问题,因为众所周知,神经网络是非常典型的密集型训练,这使得“高u”训练策略很容易过度拟合。另一个困难是检测器的质量与推断时测试假设的质量不匹配。如图1所示,高质量的检测器只对高质量的假设是最优的。当他们被要求研究其他质量水平的假设时,检测可能不是最优的。
在这篇论文中,我们提出了一个新的探测器结构,级联R-CNN,来解决这些问题。它是R-CNN的一个多阶段扩展,在这里,在级联中较深的探测器阶段对相似性误报具有更强的选择性。级联的R-CNN阶段是按顺序训练的,使用一个阶段的输出训练下一个阶段。这是由于观察到回归变量的输出loU几乎总是比输入loU好,在图1( c )中,几乎所有的图都在灰色线之上。结果表明,训练在一定IoU阈值下的检测器输出是训练下一个更高loU阈值检测器的良好分布。这类似于在目标检测文献[34,9]中通常用来装配数据集的 boostrapping 方法。主要的区别在于,级联R-CNN的重采样过程并不是为了挖掘牢固的负样本。相反,通过调整边界框,每个阶段的目标是为下一阶段的训练找到一组好的相似性误报。当以这种方式运行时,一系列适应于越来越高的IoU的检测器可以克服过拟合问题,从而得到有效的训练。在推断时,应用相同的级联过程。各阶段,逐步改进的假设与不断提升的检测器质量有更好的匹配。这可以实现更高的检测精度,如图1©和(d)所示。
级联R-CNN的实现和端到端的训练非常简单。我们的结果显示,在具有挑战性的COCO检测任务[22]上,特别是在更高质量的评估指标下,一个普通的实现,没有任何附加功能,大大超过了以前所有的最先进的单模型检测器。此外,级联R-CNN可以使用任何基于R-CNN框架的两阶段目标检测器来构建。我们观察到一致的增益(2~4点),在计算上有微小的增加。这个增益与基线对象检测器的强度无关。因此,我们认为这种简单而有效的检测体系结构可以为许多目标检测研究工作提供参考。
2.相关工作
在最近一段时间,由于R-CNN[14]架构的成功,两阶段检测框架,结合一个提议检测器和一个区域分类器,已经成为主导地位。为了在R-CNN中减少冗余计算以提高速度,SPP-Net[17]和Fast R-CNN[13]引入了区域特征提取的思想。后来, Faster R-CNN [30]通过引入区域提议网络(RPN)实现了进一步的加速。最近的一些作品将其扩展到解决各种细节问题。例如,R-FCN[4]提出了高效的区域全卷积且没有精度损失,避免了Faster R-CNN在区域上的繁重计算;虽然MS-CNN [1] 和
FPN[23]在多重输出层检测高召回度提议,以缓解RPN接受域与实际目标大小的尺度不匹配。
作为一种选择,一阶段目标检测架构也变得流行起来,主要是因为它们的计算效率。YOLO[29]输出非常稀疏的检测结果,通过一个有效的主干网络转发一次输入图像,实现实时目标检测。SSD[25]以类似于RPN[30]的方式检测目标,但使用不同分辨率的多个特征映射来覆盖不同尺度的目标。它们的主要限制是其精度通常低于两级探测器。最近,RetinaNet[24]被提出,以解决极端的前-背景级不平衡的密集的目标检测,实现了比最先进的两级对象探测器更好的结果。
3.目标检测
在本文中,我们扩展了两级架构Faster R-CNN [30,23],如图3( a )所示。第一阶段是一个提议子网络(HO),应用于整个图像,产生初步的检测假设,称为目标的提议。在第二个阶段,这些假设然后被一个感兴趣区域检测子网络(H1)处理,表示为检测头。最后一个分类评分(“C”)和一个边界框(“B”)被分配到每个假设。我们专注于建模一个多阶段检测子网络,并采用但不限于RPN[27]来进行提议检测。
3.1.边界框回归
一个边界框 b = ( bx, by, bw, bh ) 包含一个图像块 x 的四个坐标,边界框回归的任务是使用一个回归变量 f( x,b ) 将一个候选边界框 b 回归到一个目标边界框g中。这是从一个训练样本 (gi,bi) 中学习,以最小化边界框 L1损失函数,
Lloc(f(xi, bi),gi),如Fast R-CNN[13]中所建议的。为了促进对比例和位置的回归不变量,Lloc对距离向量Δ =(δx,δy,δw,δh)定义为,
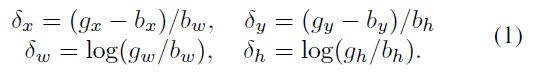
由于边界框回归通常对 b 进行较小的调整,因此(1)的数值可能非常小。因此,回归损失通常比分类损失小得多。为了提高多任务学习的有效性,通常对Δ 进行均值和方差的标准化处理,即或者用δ’x=(δx-μx)/σx代替。这在文献[30,1,4,23,16]中被广泛应用。
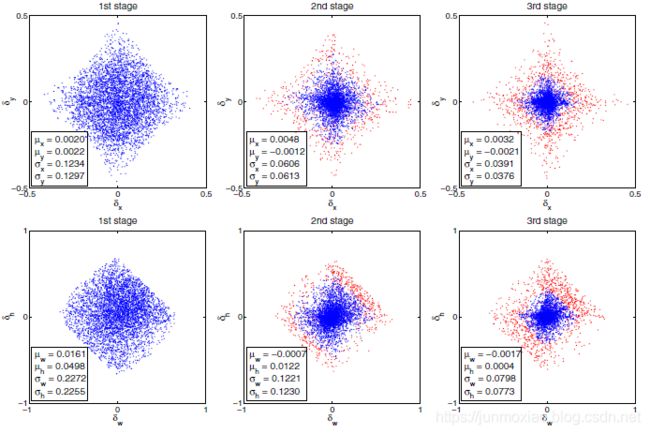
图2.不同的级联阶段的序列∆分布(无归一化)。当使用增加的loU阈值时,红点是异常值,并且在去除异常值后获得了统计信息。
有些文献 [10,11,18] 认为 f 的单一回归步骤不足以精确定位。作为替代的是,f 被迭代地应用,作为后处理步骤来改善边界框b
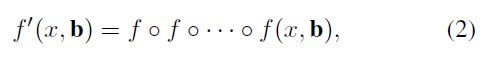
这称为迭代边界框回归,表示为迭代BBox。它可以通过图3(b)的推断架构来实现,其中所有的头都是相同的。然而,这种想法忽略了两个问题。首先,如图1所示,在u=0.5处训练的回归函数f对于更高的loU的假设是次优的。它实际上使IoU超过0.85的loU的边界框退化了。其次,如图2所示,在每次迭代之后,边界框的分布会发生显著变化。虽然回归变量在初始分布时是最优的,但在此之后可能会变得非常次优。由于这些问题,迭代BBox需要大量的人力工程,以提议积累、框投票等形式。
[10,11,18]有一些不可靠的收益。通常,除了两次应用f之外,没有其他好处。
3.2.检测质量
分类器h(x)将一个图像块x赋值给M+1个类中的一个,其中类0包含了背景和剩余的待检测目标。给定训练集(xi, yi),通过最小化分类交叉熵损失Lcls(h(xi), yi)进行学习,其中 yi 是块 xi 的类标签。
由于边界框通常包含一个目标和一些背景,所以很难确定检测是正的还是负的。这通常用IoU标准来表示。如果loU高于一个阈值u,那么这个块就是这个类的一个例子。因此,假设x的类标签是u的函数。

其中gy是真值框g的类标签。这个IoU阈值u定义了检测器的质量。
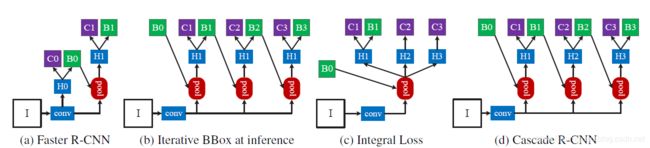
图3.不同框架的结构。在所有结构中,“I”是输入图像,“conv”是骨干卷积,“pool”是感兴趣区域特征提取,“H”是网络头部,“B”是边界框,“C"是分类,“B0”是提议。

图4.训练样本的IoU直方图。第一阶段的分布是RPN的输出。红色的数字是高于相应IoU阈值的正百分比。
目标检测具有挑战性,因为无论阈值是多少,检测设置都是高度对抗性的。当u值较高时,正样本包含的背景较少,但很难收集到足够的正训练样本。当u较低时,可以得到更丰富和更多样化的正训练集,但训练后的检测器几乎没有动力拒绝相似性误报。一般来说,很难要求单个分类器在所有的loU层上都表现良好。在推断时,由于一个提议检测器所产生的大部分假设,例如RPN[30]或选择性搜索[33],质量较差,检测器必须对质量较差的假设有更强的鉴别能力。在这些相互冲突的需求之间的标准折衷方案是u=0.5。然而,这是一个相对较低的阈值,导致低质量的检测,大多数人关心相似性误报,如图1(a)所示。
一个简单的解决方案是开发一个分类器集合,使用图3©的架构,通过针对不同质量级别的损失进行优化,

其中U是一组loU阈值。这与[38]的积分损失密切相关,其中U={0.5,0.55,…,0.75},用来拟合COCO挑战的评估指标。根据定义,需要在推断时对分类器进行集成。这个解决方案没有解决 (4) 的不同损耗对不同数量的正样本起作用的问题。如图4的第一幅图所示,随着u的增加,正样本集迅速减少。这是尤其一个问题,因为高质量的分类器容易出现过拟合。此外,这些高质量的分类器需要在推断时处理大量低质量的提议,因此它们没有进行优化。由于所有这些原因,(4)的集成在大多数质量级别上都不能实现更高的精度,并且体系结构与图3(a)相比几乎没有什么改进。
4.级联 R-CNN
在本节中,我们将介绍图3(d)中提出的级联R-CNN目标检测架构。
4.1.级联边界框回归
如图1( c )所示,很难要求单个回归器在所有质量级别上执行完全一致。在cascade pose regression[6]和face alignment[2,35]的启发下,我们可以将复杂的回归任务分解为一系列简单的步骤。在级联 R-CNN中,它被框定为一个级联回归问题,其架构如图3(d)所示。这依赖于一连串专门的回归函数
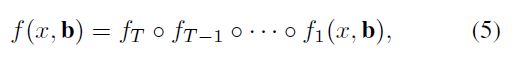
其中T为级联阶段的总数。注意,级联中的每个回归因子ft都经过w.r.t优化,即到达对应阶段的样本分布{bt},而不是{b1}的初始分布。这个级联逐步改进了假设。
它与图3(b)的迭代BBox架构在几个方面不同。首先,迭代BBox是一个用于改进边界框的后处理过程,而级联回归是一个重新采样的过程,它改变了不同阶段处理的假设的分布。其次,由于它同时用于训练和推断,因此训练和推断分布没有差异。第三,多元回归器{fT,fT-1···,f1}进行了优化,得到了不同阶段的重采样分布。这与(2)中的只对初始分布是最优的单个f相反。这些差异使得它比迭代BBox定位更精确,而不需要进一步的人工工程。
如3.1节所述,(1)中的Δ =(δx,δy,δw,δh)需要归一化,才能有效地进行多任务学习。在每个回归阶段之后,它们的统计数据将依次发展,如图2所示。在训练时,每个阶段使用相应的统计量对Δ进行归一化。
4.2.级联检测
如图4左侧所示,初始假设的分布,如RPN提议严重倾向于低质量。这就不可避免地导致了高质量分类器的无效学习。级联R-CNN通过依赖级联回归作为重采样机制来解决这个问题。这是由于在图1( c )中几乎所有的曲线都在对角线灰色线之上,即一个为特定u训练的边界框回归器倾向于产生更高的IoU的边界框。因此,从一个样本集(xi, bi)开始,逐级回归重新构造了一个更高IoU的样本分布(x’i, b’i)。通过这种方式,即使增加了检测器的质量(IoU阈值),也可以将连续阶段的正样本集保持在一个大致恒定的大小。图4对此进行了说明,在每一次重采样之后,分布会更倾向于高质量的样本。两个后果接踵而至。首先,没有过度拟合,因为在所有级别都有大量的正样本。其次,对深阶检测器进行优化,使其具有更高的loU阈值。请注意,通过增加IoU阈值,一些离群值被依次移除,如图2所示,从而实现了更好的专门检测器的训练序列。
在每个阶段t, R-CNN包括一个分类器ht和一个为loU阈值ut优化的回归器ft,其中
ut>ut-1。这是通过最小化损失来学习的
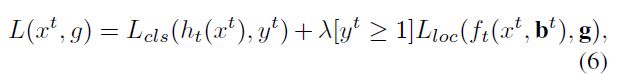
其中,bt = ft-1(xt-1,bt-1),g是xt的真值目标,λ=1是权衡系数,[·]是指示函数,yt是通过 (3) 中 ut 得到的xt的标签。与(4)的整体损失不同,这保证了一个有效训练的检测器序列的质量不断提高。在推断时,通过同样的级联过程,假设的质量可以依次提高,并且只需要更高质量的检测器就可以对更高质量的假设进行操作。这支持高质量的目标检测,如图1( c )和( d )所示。
5.实验结果
级联R-CNN的评估主要基于MS-COCO 2017[22],其中包含用于训练的约118k张图像、用于验证的5k图像(val)和不提供注释的约20k图像(test-dev)。COCO风格的平均精度(AP)平均AP通过loU阈值从0.5到0.95,区间为0.05。这些指标衡量各种质量的检测性能。所有模型在COCO训练集上进行训练,并在val集合上进行评估,最后在test-dev集合上报告结果。
5.1.实现细节
为了简化,所有的回归变量都是类不可知的。级联R-CNN的所有级联检测阶段都具有相同的架构,即基线检测网络的头部。总的来说,级联R-CNN有四个阶段,一个RPN和三个U={0.5,0.6,0.7}的检测阶段,除非另有说明。第一检测阶段的采样如下[13,30]。在下面的阶段中,只需使用前一阶段的回归输出即可实现重采样,如4.2节所示。除了标准的水平翻转图像外,没有使用任何数据增强。推断是在一个单一的图像尺度上进行的,没有其它东西。所有的基线检测器都用Caffe[20]在相同的代码基上重新实现,以便进行公平的比较。
5.1.1.基线网络
为了测试级联R-CNN的通用性,我们使用了三种常用的基线检测器:主干网为VGG-Net[32]的Faster R-CNN,R-FCN[4]和ResNet[18] 的 FPN[23]。这些基线具有广泛的检测性能。除非注明,否则将使用它们的默认设置。采用端到端训练代替多步训练。
Faster R-CNN: 网络头有两个全连接层。为了减少参数,我们使用[15]来修剪不太重要的连接。每一个全连接层保留2048个单元,并删除dropout层。训练以0.002的学习率开始,在60k和90k迭代时降低10倍,在100k迭代时停止,在2个同步gpu上,每个gpu每次迭代持有4张图片。每个图像使用128个感兴趣区域。
R-FCN:R-FCN向ResNet添加了卷积、边界框回归和分类层。级联R-CNN的所有头部都有这种结构。未进行在线挖掘牢固负样本[31]。训练以0.003的学习率开始,在160k和240k迭代时学习率降低了10倍,在280k迭代时停止,在4个同步gpu上,每个gpu每次迭代持有一张图像。每个图像使用256个感兴趣区域。
FPN:由于FPN没有公开的源代码,我们的实现细节可能会有所不同。使用RolAlign[16]作为更强的基线。这被标记为FPN+,并在所有模型简化测试中使用。和往常一样,使用ResNet-50进行模型简化测试,使用ResNet-101进行最终检测。在8个同步gpu上,120k迭代的学习率为0.005,60k迭代的学习率为0.0005。每个图像使用256个感兴趣区域。

图5.(a)为单独训练的检测器的检测性能,分别使用各自的提议(实线)或级联R-CNN 阶段提议(虚线),(b)为向提议集合中加入真值框。

图6.所有级联R-CNN检测器在各个级联阶段的检测性能。
5.2.质量失配
图5(a)为三种单独训练的检测器的AP曲线,它们的loU阈值逐渐增加:U={0.5,0.6,0.7}。在loU水平下,u=0.5的检测器表现优于u=0.6的检测器,但在较高水平下表现不佳。但是,u=0.7的检测器表现不如其他两个检测器。为了理解为什么会发生这种情况,我们在推断时改变了提议的质量。图5(b)显示了将真值框添加到提议集时的结果。虽然所有的检测器都有所改进,但u=0.7的检测器的增益最大,在几乎所有IoU级别上都达到了最佳性能。这些结果表明了两个结论。首先,u=0.5不是精确检测的好选择,只是对低质量的提议更健壮。其次,高度精确的检测需要与检测器质量相匹配的假设。接下来,用更高质量的级联R-CNN提议代替原来的检测器提议(u=0.6, u=0.7分别使用了第二阶段提议和第三阶段提议)。图5(a)还表明,当测试提议与检测器质量更接近时,两个检测器的性能会显著提高。
在所有级联级联阶段测试所有级联R-CNN探测器都得到了类似的观察结果。图6显示,使用更精确的假设时,每个检测器都得到了改进,而更高质量的检测器获得了更大的增益。例如,u=0.7的检测器在第一阶段的低质量建议中表现不佳,但在较深的级联阶段的更精确的假设中表现得更好。此外,即使使用相同的提议,图6中联合训练的检测器的性能也优于图5(a)中单独训练的检测器。这说明在级联R-CNN框架下,检测器得到了更好的训练。

图7.(a)为定位比较,(b)为各分类器在积分损耗检测器中的检测性能。
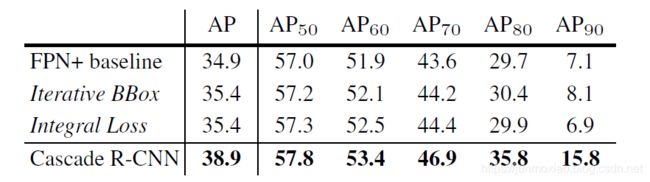
表1.与迭代BBox和积分损耗的比较。
5.3.与迭代BBox和积分损耗的比较
在本节中,我们将级联R-CNN与迭代BBox和积分损耗检测器进行比较。迭代BBox是通过三次迭代应用FPN+基线实现的。积分损失检测器也有三个分类头,U={0.5,0.6,0.7}。
定位:图7(a)对比了级联回归和迭代BBox的定位性能。单一回归器的使用降低了高 loU假设的定位性能。当迭代地应用回归变量(如在迭代BBox中)时,这种效果会累积,并且性能实际上会下降。注意经过3次迭代后,迭代BBox的性能非常差。相反,级联回归器在后期具有更好的性能,在几乎所有的loU级别上都优于迭代BBox。
积分损失:共享一个回归变量的积分损失检测器中所有分类器的检测性能如图7(b)所示。在各loU层中,u=0.6的分类器是最好的,而u=0.7的分类器是最差的。所有分类器的集合没有显示任何可见的增益。从表1可以看出,迭代BBox和积分损失检测器都对基线检测器有一定的改进。对于所有的评价指标,级联R-CNN的表现都是最好的。对于低loU阈值来说,收益是轻微的,但对于高IoU阈值来说,收益是显著的。
5.4.消融实验
进行了一系列消融实验,分析了所提出的级联R-CNN。
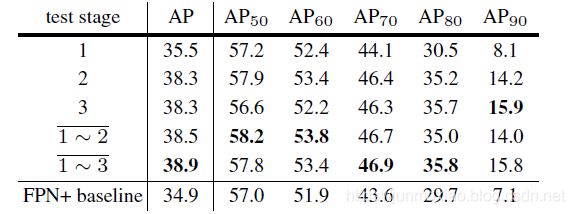
表2.级联R-CNN的阶段表现。1〜3表示整体结果,是给定第三阶段提议的三个分类器概率的平均值。
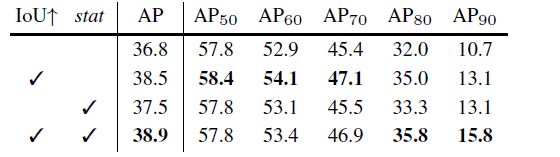
表3.消融实验。“IoU↑”意味着增加IoU阈值,而“stat”则运用了顺序回归统计。
阶段比较:表2总结了阶段性能。注意,由于多阶段多任务学习的好处,第一阶段的性能已经超过了基线检测器。更深层次的级联阶段更喜欢高质量的定位,鼓励学习有利于它的特性。通过跨阶段共享特性,这将有利于早期的级联阶段。第二阶段是大幅度提高性能的阶段,第三阶段相当于第二阶段。这不同于积分损失检测器,其中较高的IoU分类器相对较弱。虽然前(后)阶段在低(高)借据指标上更好,但是总体上所有分类器的集合是最好的。
loU阈值:使用相同的IoU阈值u=0.5训练初步级联R-CNN。在这种情况下,不同的阶段只在他们接受的假设上有所不同。每个阶段都训练了相应的假设,即考虑图2的分布。表3的第一行显示级联改进了基线检测器。这说明了对相应的样本分布优化阶段的重要性。第二行表明,通过增加阶段阈值u,可以使检测器对相似性误报有更强的选择性,并对更精确的假设进行专门化,从而带来额外的收益。这支持第4.2节的结论。
回归统计:利用图2中逐步更新的回归统计,有助于有效地进行分类和回归的多任务学习。通过比较表3中有/没有它的模型可以看出它的好处。学习对这些数据并不敏感。
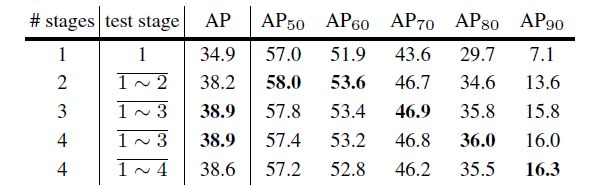
表4.阶段数对级联R-CNN的影响。
阶段数:阶段数的影响见表4。添加第二个检测阶段可以显著地改进基线检测器。三个检测阶段仍然产生非平凡的改进,但是添加第四个阶段(u=0.75)导致性能略有下降。然而,要注意的是,虽然整个AP的性能在下降,但四级联在高IoU时的性能最好。三阶段级联达到了最好的权衡。
5.5.与最先进的比较
设置如5.1.1节所述,但是总共运行了280k的训练迭代,并且在160k和240k的迭代中学习率下降。感兴趣区域的数量也增加到512个。表5中第一组检测器为单级检测器,第二组为两级检测器,最后一组为多级检测器(级联R-CNN为3级+RPN)。所有对比的最先进的探测器都经过了u=0.5的训练。值得注意的是,我们的FPN+实现比原来的FPN[23]更好,提供了一个非常强大的基线。此外,从FPN+扩展到级联R-CNN,性能提高了约4个点。在所有的评价指标下,级联R-CNN也大大优于所有的单模型检测器。这包括COCO挑战赛冠军的单模参赛作品(Faster R-CNN+++[18],和G-RMI[19]),以及最近的Deformable R-FCN [5], RetinaNet[24]和Mask R-CNN[16]。与COCO上最好的多阶段检测器AttractioNet[11]相比,虽然它使用了很多增强,但 vanilla 级联R-CNN仍然比它好7.1个百分点。注意,与Mask R-CNN不同,级联R-CNN没有利用任何分割信息。最后,vanilla 单模级联R-CNN也超越了2015年和2016年赢得COCO挑战(分别为AP37.4和41.6)的高强度工程集成检测器。
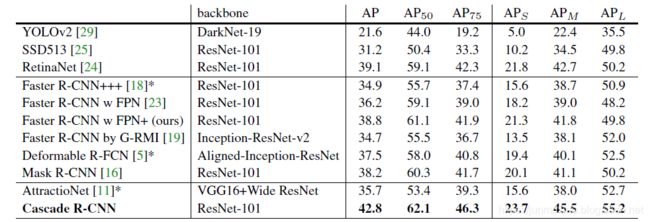
表5.在COCO test-dev上的最先进的单模型检测器。用“*”表示的条目在推断时使用了附加功能。
5.6.泛化能力
三种基线检测器的三级级联R-CNN比较见表6。所有设置如上所示,FPN+更改为5.5部分。
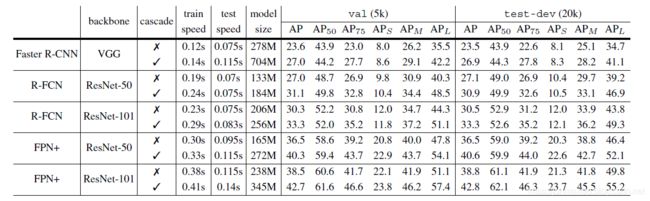
表6.多个流行的基线对象检测器的详细比较。所有的速度都报告在一个单一的Titan Xp GPU图像。
检测性能:同样,我们的实现比原来的检测器更好[30,4,23]。尽管如此,级联R-CNN在这些基线上持续改进了2~4个点,与它们的强度无关。这些收益在val和test-dev上也是一致的。这些结果表明,级联R-CNN广泛适用于探测器结构。
参数和时间:级联R-CNN参数的数量随着级联数的增加而增加。基线探测头的参数数量的增加是线性的。此外,由于检测头的计算成本与RPN相比通常较小,因此级联R-CNN的计算开销较小,在训练和测试中都是如此。
5.7.在PASCAL VOC上的结果
在PASCAL VOC数据集[8]上进行级联R-CNN实验。在[30,25]之后,分别对模型进行VOC2007和VOC2012训练,并进行VOC2007测试。测试了Faster R-CNN(使用AlexNet和VGG-Net)和R-FCN(使用ResNet)。训练细节与第5.1.1节相似,并对AlexNet进行了删减。由于本文的目标是探索高质量的检测,所以我们使用COCO指标进行评估。表7的检测结果表明,级联R-CNN相对于PASCAL VOC的多种检测架构也有显著的改进。这些增强了我们对级联R-CNN鲁棒性的确信。
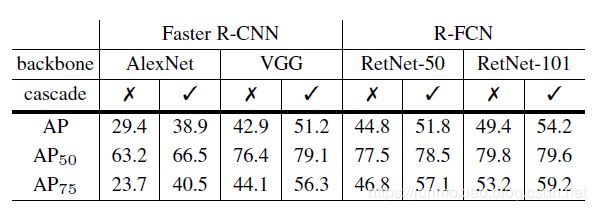
表7.PASCAL VOC 2007 test检测结果。
6.结论
在本文中,我们提出了一个多阶段的目标检测框架,级联R-CNN,用于设计高质量的目标检测器。该体系结构避免了训练时的过拟合和推断时的质量不匹配问题。级联R-CNN对有挑战性的COCO和PASCAL VOC数据集的可靠和一致的检测改进表明,要推进对象检测,需要建模和理解各种并发因素。级联R-CNN被证明适用于许多目标检测架构。我们相信,它可以对未来许多目标检测的研究工作有帮助。