shell脚本基础知识2
一 shell中得数学运算
shell中的加、减、乘、除和取余有点特殊,主要是格式上和C不太一样。
[root@nginx ~]# a=2;b=5
[root@nginx ~]# c=$[$a+$b] # 加法
[root@nginx ~]# echo $c
7
[root@nginx ~]# d=$[$b-$a] # 减法
[root@nginx ~]# echo $d
3
[root@nginx ~]# e=$[$a*$b] # 乘法
[root@nginx ~]# echo $e
10
[root@nginx ~]# f=$[$b/$a] # 除法
[root@nginx ~]# echo $f
2
[root@nginx ~]# g=$[$b%$a] # 取余
[root@nginx ~]# echo $g
1
在shell的数学运算中要想使用小数,或者限定小数位数,可以借助bc的scale实现:
[root@nginx ~]# a=10;b=3
[root@nginx ~]# echo $[$a/$b]
3
[root@nginx ~]# echo "scale=2;$a/$b"|bc # scale=2 表示小数有两位
3.33

二 bc 命令
# man bc 中的解释:![]()
bc --- An arbitrary precision calculator language 一个任意精度的计算器语言。
从他的使用上来看,能够对计算公式的语法进行解释并返回结果。有下面几种使用方式:
1)交互式 ----> bc 后面什么也不跟,直接进入交互界面
输入bc,进入交互式界面,然后输入3+1,回车后在下一行打印出了4;再输入5*2,回车后在下一行自动打印出了10

2)echo 配合 管道
[root@zabbix_nginx ~]# echo "3+1"
3+1
[root@zabbix_nginx ~]# echo "3+1" | bc
4

3)bc 文件名 ---->其实也是进入到了交互界面
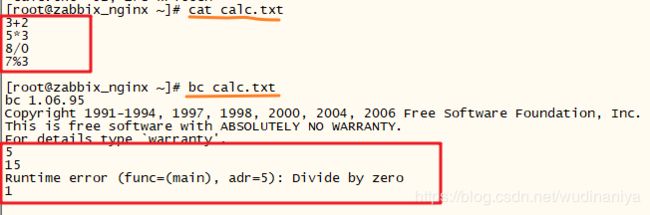
bc "calc.txt" 进入bc交互式界面并自动返回文本内算式的结果
当算术或者语法等出现错误时,程序会返回错误信息,如下:
当执行8/0时,会返回错误信息:Runtime error (func=(main),adr=5):Divide by zero
三 查看mysql队列
在linux系统里,我们可以通过ps、top等指令来查看系统的进程情况,而在mysql中,可以通过“show processlist” 指令查看mysql的进程队列。当mysql服务器负载变高或者访问卡顿时,查看一下进程队列是非常有必要的。操作如下:
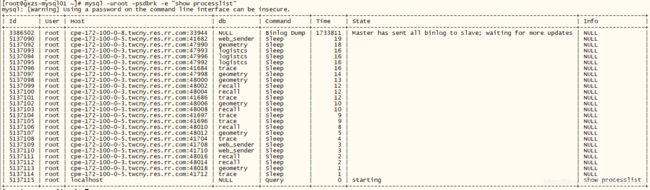
注意:参数 -e statement -e (execute)----> Execute the statement and quit.
因为我实验的机器并没有什么访问量,所以并没有列出什么信息来,只有show processlist本身加一些别的队列。在这里需要提醒大家,有时候列出来的队列命令太长从而显示不完整,则需要使用另外一个指令: show full processlist 。
四 查看mysql主从状态
判断mysql主从是否正常有两种方法,第一种自然是对比两台mysql上的数据是否一致,第二种是通过执行“show slave status” 指令查看输出的结果,判断主从状态。对于第一种是最精准的,但是比较麻烦,所以我们通常用第二种方法来判断mysql主从状态。操作如下所示(在从机上执行):
我们需要关注的行有:Slave_IO_Running、Slave_SQL_Running,只有这两行的值全都是Yes才算是主从同步状态正常。而任何一个为No,则不正常,当不正常时需要查看下面的Error(如,Last_error、Last_IO_Error、Last_SQL_Error) 相关信息近一步判断造成不同步的原因。
在生产环境种,有很大一部分问题不是主从不同步,而是主从延迟太严重,对于以上的输出信息种,有一行显示的是主从延迟信息:Seconds_Behind_Master, 这个显示的是一个时间,单位是秒,表示从落后主多少秒。这个值其实并不完全精准,但我们却可以通过这个数值判断出主从是否有延迟(保证主从两台机器时间设置一致)。
五 shell中的内置变量
在shell脚本中,你会不会奇怪,哪里来的$1和$2,这其实就是shell脚本的预设变量,其中$1的值就是在执行的时候输入的第一个参数,而$2的值就是执行的时候输入的第二个参数,当然一个shell脚本的预设变量是没有限制的。另外还有一个$0,不过它代表的是脚本本身的名字。编写一个测试脚本,如下所示:
[root@slave1 ~]# vim option.sh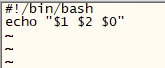
执行结果如下:
[root@slave1 ~]# sh option.sh 1 2
1 2 option.sh
如果这样执行脚本,那 $0 的值会有所不同,如下:
[root@slave1 ~]# ./option.sh 1 2
1 2 ./option.sh
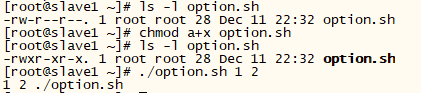
也就是说,$0的值会跟着执行时的命令变化,你用绝对路径它就会显示绝对路径,用相对路径它会显示相对路径。
六 sh命令

七 linux中查看文件显示行号
cat 文件 # 不现实行号
cat -n 文件 # 显示行号(包括空行)
cat -b 文件 # 显示行号 (不包含空行)

八 linux中 vi/vim 显示行号或取消行号命令
1. 显示行号
:set number
或者
:set nu
2. 取消行号显示
:set nu!
九 chmod 命令 ---- 赋权
使用chmod赋权时,r --- 读,对应数字4; w --- 写,对应数字2;x --- 执行,对应数字1
9.1 [root@slave1 ~]# chmod u+x abc.sh 只给本用户赋予对abc.sh文件的执行权限
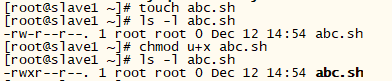
9.2 [root@slave1 ~]# chmod a+x abc.sh 给本用户,本用户同组其他用户,不同组用户都赋予对abc.sh文件的执行权限
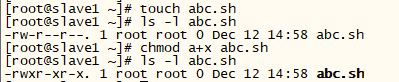
9.3 [root@slave1 ~]# chmod 751 abc.sh 对于abc.sh文件,赋予该用户rwx权限,赋予同组其他用户rx权限,赋予不同组用户x权限

十 awk 命令
# man awk 中给出的解释:

awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK 的确拥有自己的语言: AWK 程序设计语言 , 三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
awk 是一种很棒的语言,它适合文本处理和报表生成,其语法较为常见,借鉴了某些语言的一些精华,如 C 语言等。在 linux 系统日常处理工作中,发挥很重要的作用,掌握了 awk将会使你的工作变的高大上。
awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。
print 是awk打印指定内容的主要命令
awk命令是我最常用的命令之一,比如在文件有多列的时候,我可以用awk输出具体某几列,或者做一些简单的统计求和,求平均值啊。
下面通过几个实例来了解一下awk的工作原理:
实例一: 只查看 test.txt文件(11行)内第2行到第5行的内容(企业面试) # 行号时从1开始计数的
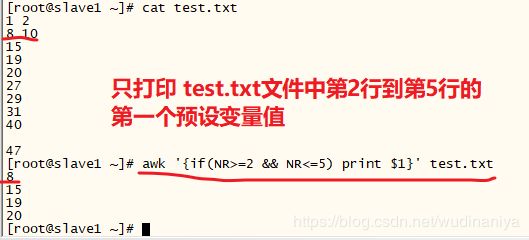
实例二:已知test.txt文件的内容为:
[root@slave1 ~]# cat test.txt
I am Poe,my qq is 36785219请从该文件中过滤出'Poe'字符串与36785219,最后输出的结果为:Poe 36785219
[root@slave1 ~]# awk -F '[ ,]+' '{print $3" "$7}' test.txt
Poe 36785219实例三:
$0 在非awk中,属于shell预设变量,代表脚本本身的名字;在awk中,表示整个当前行
$1 每行第一个字段
$NF 的含义: NF是最后一列。NF 字段数量变量
-F '[:#/]' 定义三个分隔符
已知 1.txt的内容为:
[root@slave1 ~]# cat 1.txt
1 香水有毒 250
2 兄弟 500
3 十年 600 陈奕迅请从该文件中过滤出最后一列,代码及最后输出的结果为:
[root@slave1 ~]# awk '{print $NF}' 1.txt // 必须是单引号
250
500
陈奕迅实例四
-F 参数:指定分隔符,可指定一个或多个
awk默认以空白字符(即空格)为分隔符对每一行进行分割。分割成多个字段。
已知 1.txt 的内容为:
[root@slave1 ~]# cat 1.txt
1 香水有毒 250
2 兄弟 500
3 十年 600 陈奕迅
test.sh
./test.sh
/usr/local/test.sh指定分隔符,指定一个分隔符或多个分隔符,最后执行的结果相差很大,如下:

awk 也可以和 管道 相结合, 如下:
[root@slave1 ~]# cat 1.txt|awk -F '[ /]' '{print $NF}'
250
500
陈奕迅
test.sh
test.sh
test.sh实例五
awk '{print}' /etc/hosts 等价于 awk '{print $0}' /etc/hosts
awk '{print " "}' /etc/hosts # 不输出hosts的内容,而是输出相同个数的空行,进一步解释了awk是一行一行处理文本
[root@nginx ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@nginx ~]# awk '{print $0}' /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@nginx ~]# awk '{print $1}' /etc/hosts
127.0.0.1
::1
[root@nginx ~]# awk -F ' ' '{print $1,$4}' /etc/hosts # 输出字段1,4,以空格为分隔符
127.0.0.1 localhost4
::1 localhost6
[root@nginx ~]# awk '{print "a"}' /etc/hosts # 输出相同个数的a行,一行只有一个a字母
a
a[root@nginx ~]# touch data.txt
[root@nginx ~]# echo "1 2 3 4 5 6 7" > data.txt
[root@nginx ~]# echo "2 3 4 5 6 7 8">> data.txt
[root@nginx ~]# cat data.txt
1 2 3 4 5 6 7
2 3 4 5 6 7 8
[root@nginx ~]# cat data.txt | awk '{print $1,$3,$5}' // 输出第1 3 5列,注意下标是从1开始
1 3 5
2 4 6
[root@nginx ~]# cat data.txt | awk '{sum += $3} END {print sum}' // END 必须大写, 对第3列求和
7
[root@nginx ~]# cat data.txt | awk -F ' ' '{print $1,$3}' // 把每行数据按空格分列,并输出1 3列
1 3
2 4十一 cut 命令
---文件内容查看,显示行中指定的部分
cut命令参数:
-d,--delimiter=delim: 指定字段的分隔符,默认的字段分隔符为“Tab”
-f,--fields=List: 显示指定字段(以1,2,3...进行表示)的内容
-c: 仅显示行中指定范围的字符
案例1:使用 -f 参数提取指定字段:
[root@mysql-master ~]# cat test.txt
No Name Mark Percent
01 tom 69 91
02 jack 71 87
03 alex 68 98
[root@mysql-master ~]# cut -f 1 test.txt // 显示第1个字段的内容
No
01
02
03
[root@mysql-master ~]# cut -f 2,4 test.txt // 显示第2,4两个字段的内容
Name Percent
tom 91
jack 87
alex 98
[root@mysql-master ~]# cut -f2,4 test.txt
Name Percent
tom 91
jack 87
alex 98案例2:--complement 选项提取指定字段之外的列:
[root@mysql-master ~]# cat test.txt
No Name Mark Percent
01 tom 69 91
02 jack 71 87
03 alex 68 98
[root@mysql-master ~]# cut -f3 --complement test.txt // 打印除了第3列之外的列
No Name Percent
01 tom 91
02 jack 87
03 alex 98
[root@mysql-master ~]# cut -f1,3 --complement test.txt // 打印除了第1,3两列之外的列
Name Percent
tom 91
jack 87
alex 98案例3: 使用 -d 参数指定字段分隔符
[root@mysql-master ~]# cat test.txt
No;Name;Mark;Percent
01;tom;69;91
02;jack;71;87
03;alex;68;98
[root@mysql-master ~]# cut -d";" -f2 test.txt //打印输出test.txt文件中以;分隔的的第2个字段
Name
tom
jack
alex使用-d时,一定要和-f 一同使用,因为使用-d的前提时必须要指定字段
案例4:指定字段的字符或者字节范围
cut命令可以将一串字符作为列来显示,字符字段的记法:
N-:从第N个字节、字符、字段到结尾;
N-M:从第N个字节、字符、字段到第M个(包括M在内)字节、字符、字段;
-M:从第1个字节、字符、字段到第M个(包括M在内)字节、字符、字段。上面是记法。结合下面参数将使用:
-b 表示字节(bytes)
-c 表示字符(characters)
-f 表示字段(fields)
[root@mysql-master ~]# cat test.txt
No;Name;Mark;Percent
01;tom;69;91
02;jack;71;87
03;alex;68;98打印第1个到第3个字符:
[root@mysql-master ~]# cut -c1-3 test.txt
No;
01;
02;
03;打印前2个字符:
[root@mysql-master ~]# cut -c-2 test.txt
No
01
02
03打印从第4个字符开始到结尾:
[root@mysql-master ~]# cut -c4- test.txt
Name;Mark;Percent
tom;69;91
jack;71;87
alex;68;98十二 sed 命令
sed(stream editor)
sed :stream editor for filtering and transforming text。可以采用正则匹配,对文本进行插入,删除,修改等操作(原文本内容并未真的改变,改变的只是在控制台上的展示方式)
sed 处理的时候,一次处理一行,每一次把当前处理的存放在临时缓冲区,处理完后输出缓冲区内容到屏幕,然后把下一行读入缓冲区,如此重复,直到结尾。
sed命令格式:
sed [-nefri] 'command' 输入文本/文件
常用参数:
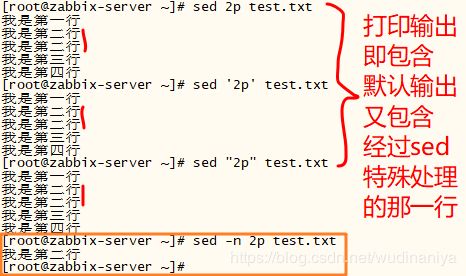
-n: 取消默认的输出,使用安静(slient)模式。在sed处理的时候,所有来自 STDIN 的数据都会被输出到终端。但如果加上 -n 参数后,则只有经过 sed 特殊处理的那一行才会被打印出来。
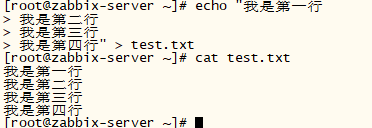
比如:我新建一个文件test.txt,接下来向test.txt中写入内容:
使用 -n 和 不使用 -n ,打印输出上的区别:
-e: 进行多项编辑,即对输入行应用多条sed命令时使用。直接在指令模式上进行sed的动作编辑
[root@zabbix-server ~]# cat test.txt
我是第一行
我是第二行
我是第三行
我是第四行
[root@zabbix-server ~]# sed -e '2,3d' -e 's/第四/four/g' test.txt
我是第一行
我是four行
[root@zabbix-server ~]# cat test.txt
我是第一行
我是第二行
我是第三行
我是第四行
-f: 指定sed脚本的文件名。直接将 sed 的动作写在一个档案内, -f filename 则可以执行 filename 内的sed 动作
-r: sed的动作支援的时延伸型正则表达式的语法。(预设是基础正则表达式语法)
-i: 直接修改原文件内容,而不是屏幕输出。--- 慎用,尤其是用系统文件做练习的时候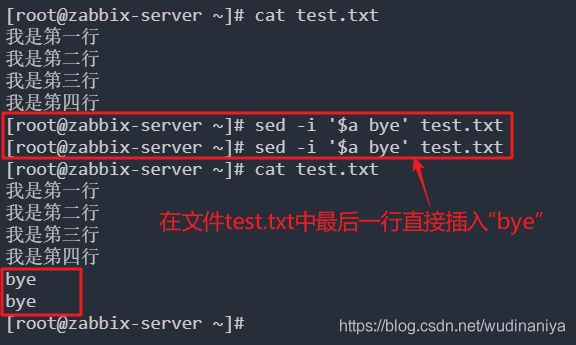
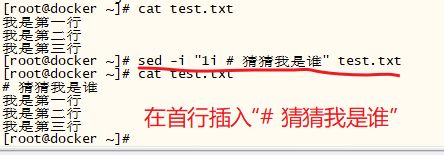
实际经常见到的场景:比如 好多配置文件,我们想在某个特定行下面增加一行配置,如何操作:
思路,先找到该特定行的行号,找到行号之后,就可以使用 sed -i xxxx file 更改文件内容
可通过下面的方法只显示行号:
awk '/特定内容/ {print NR}' 文件名
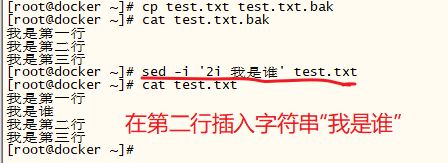
实际场景:向含有“第二行”三个字的行下面追加一行文本“我是谁”
法一:
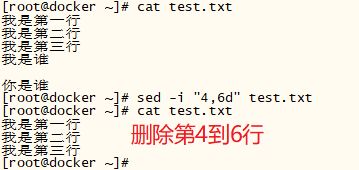
[root@docker ~]# cat test.txt
我是第一行
我是第二行
我是谁
我是第三行
[root@docker ~]# sed -i "3 d" test.txt // 删除第3行
[root@docker ~]# cat test.txt
我是第一行
我是第二行
我是第三行
[root@docker ~]# awk '/第二行/ {print NR}' test.txt // 查看 含有“第二行”的行的行号
2
[root@docker ~]# sed -n '2 p' test.txt // 通过行号,静默方式打印输出指定行的内容(文件内容不做修改)
我是第二行
[root@docker ~]# cat test.txt
我是第一行
我是第二行
我是第三行
[root@docker ~]# sed -i " `awk '/第二行/ {print NR}' test.txt` a 我是谁 " test.txt // 向含有“第二行”三个字的行下面追加一行文本“我是谁”
[root@docker ~]# cat test.txt
我是第一行
我是第二行
我是谁
我是第三行
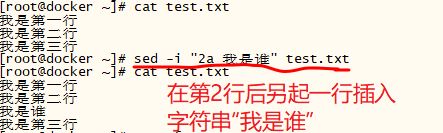
[root@docker ~]# 法二:使用 变量
使用用变量时, $var 和 a 之间要有空格,否者系统分辨不出变量名到底时var 还是 vara, 从而报错
[root@docker ~]# cat test.txt
我是第一行
我是第二行
我是谁
你到底爱谁
你是谁
你到底爱谁
我是第三行
[root@docker ~]# sed -i '/谁/d' test.txt // 删除所有含有“谁”的行
[root@docker ~]# cat test.txt
我是第一行
我是第二行
我是第三行
[root@docker ~]# var=`awk '/第二行/ {print NR}' test.txt` // 查出行号赋予变量var
[root@docker ~]# echo $var
2
[root@docker ~]# sed -i "$var a 我是谁" test.txt // 向指定行下面追加一行内容“我是谁”
[root@docker ~]# cat test.txt
我是第一行
我是第二行
我是谁
我是第三行
[root@docker ~]# 法三 :
[root@docker ~]# cat test.txt
我是第一行
我是第二行
我是谁
你是谁
我是第三行
[root@docker ~]# sed -i " /是谁/ a 你到底爱谁 " test.txt // 在所有含有“是谁”的行下面都追加一行内容“你到底爱谁”
[root@docker ~]# cat test.txt
我是第一行
我是第二行
我是谁
你到底爱谁
你是谁
你到底爱谁
我是第三行
[root@docker ~]# awk '/到底爱谁/ {print NR}' test.txt // 查看含有“到底爱谁”的行的行号
4
6
[root@docker ~]# sed -n "/谁/ p" test.txt // 查询出所有带有“谁”的行
我是谁
你到底爱谁
你是谁
你到底爱谁
[root@docker ~]#
常用动作指令:
a: 新增,a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)
c: 取代,c的后面可以接字串,这些字串可以取代n1,n2之间的行。 c 用于替换一行到多行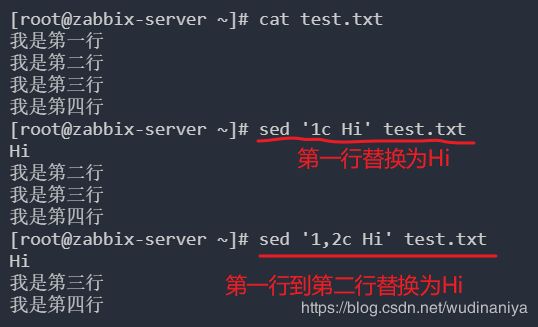
s: 取代,可以直接进行替换的工作。通常这个s的动作。
s 用于替换一行中的某部分
格式:sed 's/要替换的字符串/新的字符串/g' (要替换的字符串可以用正则表达式)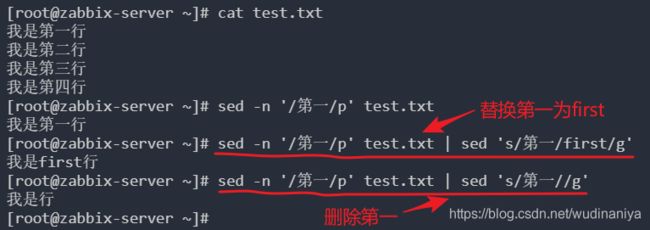
d: 删除,因为是删除,所以d 后面通常不接任何内容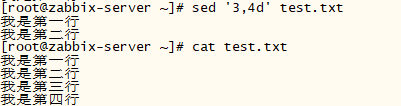
i: 插入,i 的后面可以接字串,而这些字串会在新的一行出现 (目前行的上一行)
p: 打印(print),将某个选择的部分打印出来。通常 p 会和参数 sed -n 一起用。比如 :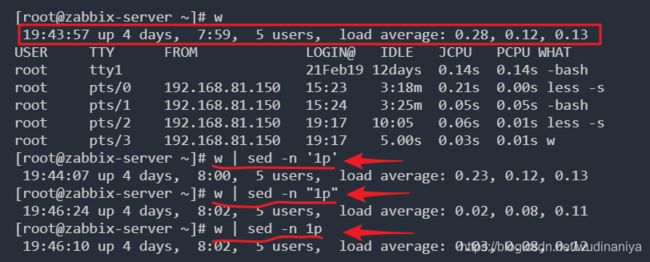
定址
定址用于决定对哪些行进行编辑。地址的形式可以是数字、正则表达式、或二者的结合。如果没有指定地址,sed将处理输入文件的所有行。
地址是一个数字,则表示行号;是 “$” 符号,则表示最后一行。如果地址是逗号分隔的,那么需要处理的地址是这两行之间的范围(包括这两行在内)。范围可以用数字、正则表达式、或二者的组合表示。
例如:
##### 显示某(些)行 ---查 #####
# 只打印第三行
sed -n '3p' datafile
# 显示最后一行
sed -n '$p' datafile
# 只查看文件的第100行到第200行
sed -n '100,200p' mysql_slow_query.log
# 显示第2行到最后一行
sed -n '2,$p' mysql_slow_query.log
##### 使用模式(pattern)进行查询 ---查 #####
# 查询所有包含关键字ruby的行
sed -n '/ruby/p' datafile
# 查询包含关键字 $ 所在所有行,使用反斜线 \ 屏蔽特殊含义
sed -n '/\$/p' datafile
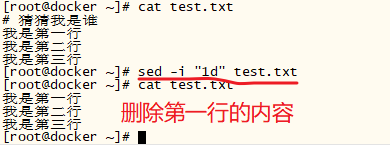
##### 删除行 ---删 #####
# 删除第一行
sed '1d' datafile
# 删除最后一行
sed '$d' datafile
# 删除第二行到第五行(包含第2行和第5行)
sed '2,5d' datafile
# 删除第二行到最后一行
sed '2,$d' datafile
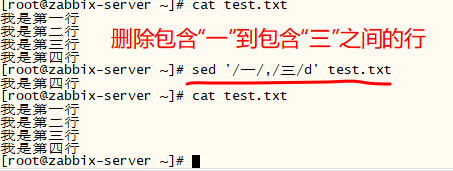
# 删除包含 "My" 的行到包含 "You" 的行之间的行(包含“My”行和“You”行)
sed '/My/,/You/d' datafile
# 删除包含 "My" 的行到第十行的内容
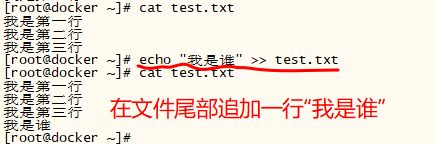
sed '/My/,10d' datafile##### 增 #####
[root@zabbix-server ~]# cat test.txt
我是第一行
我是第二行
我是第三行
我是第四行
[root@zabbix-server ~]# sed '1a drink tea' test.txt // 第一行后增加字符串“drink tea”
我是第一行
drink tea
我是第二行
我是第三行
我是第四行
[root@zabbix-server ~]# sed '1,3a drink tea' test.txt // 第一行到第三行后增加字符串“drink tea”
我是第一行
drink tea
我是第二行
drink tea
我是第三行
drink tea
我是第四行
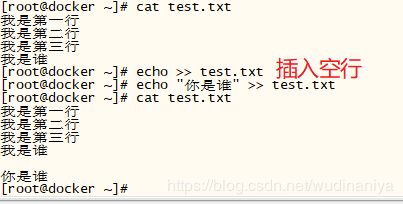
[root@zabbix-server ~]# sed '1a drink tea\nor coffee' test.txt // 第一行后增加多行,使用换行符\n
我是第一行
drink tea
or coffee
我是第二行
我是第三行
我是第四行
sed命令中使用外部变量的方法:
如下图所示,sed命令中使用外部变量不当,将无法显示外部变量的值。

sed命令中使用外部变量的两种方法:
1. sed 命令使用双引号的情况下,使用 $var 直接引用即可。
eg:
[root@test ~]# echo| sed "s/^/$RANDOM.rmb_/g"
13641.rmb_2. sed命令使用单引号的情况下,使用 '"$var"'引用
eg:
[root@test ~]# echo| sed 's/^/'"$RANDOM"'.rmb_/g'
12726.rmb_
[root@test ~]#
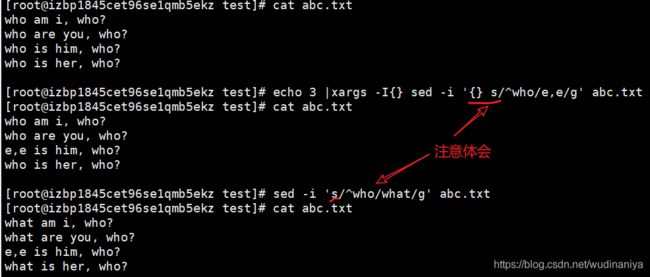
sed替换,注意体会:
十二 sort 命令
对标准内容做排序
基本用法:
cat file|sort 把file里的数据排序,注意是按字典排序的,如果想按数值排序,需要加-n参数
cat file|sort -k4 -n -r 按第4列数值倒序排序,-k 指定第几列,-r是翻转reverse的意思
[root@nginx ~]# cat data.txt
1 2 3 4 5 6 7
2 3 4 5 6 7 8
4 2 8 1 9 13 2
1 1 8 7 2 1
[root@nginx ~]# cat data.txt | sort
1 1 8 7 2 1
1 2 3 4 5 6 7
2 3 4 5 6 7 8
4 2 8 1 9 13 2
[root@nginx ~]# cat data.txt | sort -k4 -n -r
1 1 8 7 2 1
2 3 4 5 6 7 8
1 2 3 4 5 6 7
4 2 8 1 9 13 2
十三 if 命令
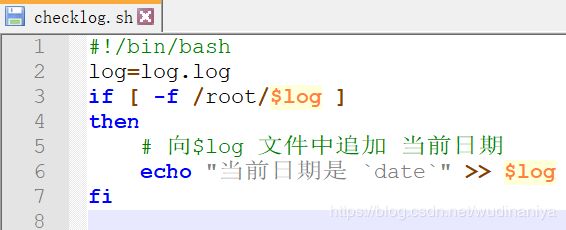
案例一 如果 /root/log.log文件不存在,则创建 /root/log.log文件: (!意为 非)
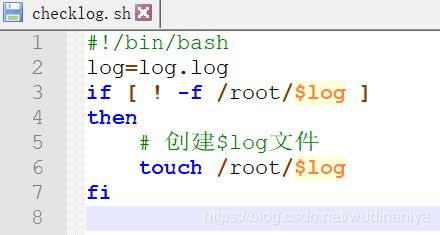
案例二 若果 /root/log.log文件存在,则向 /root/log.log文件 中追加 “当前日期”

checklog.sh 脚本内容如下:
if else 用法:
[root@zabbix_nginx home]# vim deploy.sh
#!/bin/bash
jar=lala.jar
if [ ! -f /home/$jar ]
then
echo "jar包不存在!"
echo "jar包不存在!"
echo "jar包不存在!"
else
echo "jar包存在!"
fiif else 用法实际应用:
#!/bin/bash
#export PATH="/usr/local/java/bin:$PATH"
jar=/app/jenkins/yangzhou-gateway/yangzhou-gateway-1.0.0.jar
if [ -f $jar ]
then
cd /home/work/yangzhou-gateway
#备份
mv yangzhou-gateway-1.0.0.jar yangzhou-gateway-1.0.0.jar.bak`date +%Y%m%d_%H%M`
#移动项目
mv $jar .
#重启
./restart.sh
else
echo "jar包不存在!"
fiif else 及 exit
[root@zabbix_nginx home]# vim deploy.sh
#!/bin/bash
jar=lala.jar
if [ ! -f /home/$jar ]
then
echo "jar包不存在!"
echo "jar包不存在!"
echo "jar包不存在!"
exit 1 # 如果 /home/$jar文件不存在,if else后面的代码也不会被执行
else
echo "jar包存在!"
fi
echo "======结束========"
十四 chattr 命令
chattr 命令 用于控制文件的属性
一些基本属性控制如下:
+: 在原有参数设定的基础上,追加参数
-: 在原有参数设定基础上,移除参数
a: 即append,设定该参数后,只能向文件中追加数据,而不能删除数据,也不能重命名或删除该文件(可以复制),多用于服务器日志文件安全,只有root才能设定这个属性
[root@zabbix_nginx ~]# cat test.txt
I am used to test.
It's my task.
[root@zabbix_nginx ~]# chattr +a test.txt
[root@zabbix_nginx ~]# rm -rf test.txt # 给文件追加了 a 属性,将无法删除
rm: cannot remove ‘test.txt’: Operation not permitted
[root@zabbix_nginx ~]# echo 124 > test.txt # 也无法修改 test.txt文件的内容
-bash: test.txt: Operation not permitted
[root@zabbix_nginx ~]# cat test.txt
I am used to test.
It's my task.
[root@zabbix_nginx ~]# echo 1234 >> test.txt # 只能向文件 test.txt 中追加内容
[root@zabbix_nginx ~]# cat test.txt
I am used to test.
It's my task.
1234
[root@zabbix_nginx ~]# chattr -a test.txt # 要想获得删除 test.txt 的权限,可移除该文件a属性参数
[root@zabbix_nginx ~]# rm -rf test.txti: 设定文件不能被删除、改名、设定链接关系,同时不能写入或新增内容。i 参数对文件系统的安全设置有很大帮助。----> 比 a 属性更加严格
[root@zabbix_nginx ~]# chattr +i test.txt # 给文件追加了 i 属性后,连向文件中追加内容都无法追加了
[root@zabbix_nginx ~]# echo "abc" >> test.txt
-bash: test.txt: Permission denied
[root@zabbix_nginx ~]# rm -rf test.txt # 更别提删除或重命名文件了
rm: cannot remove ‘test.txt’: Operation not permitted
[root@zabbix_nginx ~]# chattr -i test.txt # 可通过 “-” 来移除 i 属性
[root@zabbix_nginx ~]# rm -rf test.txt 十五 curl命令
1 使用curl命令简单举例 :
[root@tomcat ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@tomcat ~]# cat /etc/hostname // 主机名
tomcat
[root@tomcat ~]# curl localhost:8080/1.txt
13579
02468
[root@tomcat ~]# curl tomcat:8080/1.txt //可以通过 主机名/域名/ip:port 访问服务器资源
13579
02468
[root@tomcat ~]# curl 192.168.81.220:8080/1.txt
13579
02468
[root@tomcat ~]# curl "192.168.81.220:8080/1.txt"
13579
024682 使用curl命令在products中查询 字段 p_count=1 的索引数据
[root@gx-solr1 logs]# curl "http://gx-solr2:8983/solr/products/select?q=p_count:1"3 查询 solr某个collection下的schema文件内容,执行命令 curl 'xxx' ,将其返回结果保存到 log.log 中
[root@gx-solr1 ~]# curl 'http://192.168.0.110:8983/solr/scan_detail/admin/file?_=1544066402749&contentType=text/plain;charset=utf-8&file=managed-schema&wt=json' > log.log
十六 在命令行下发邮件 -- python脚本
踏入运维这个领域,写监控脚本很常见。用的最多的告警方式就是发邮件,早期使用系统自带的sendmail或者postfix发邮件给139邮箱,因为139邮箱是带短信提醒的。但是使用这种方法发出来的邮件通常是直接拒收或者给放到垃圾邮箱里,最终效果并不好。最近又研究了一个python发邮件的脚本,同样调用第三方邮件,我使用的是163邮箱。因为可以在手机上安装邮件客户端,所以不用担心提醒的问题了,收到邮件直接在app上提醒,比短信还方便。同时,接收邮件人可以是自己,也就是说自己给自己发邮件,也不会有垃圾邮件的烦恼。
下面是发邮件的python代码:
#!/usr/local/bin/python3
print ("邮件发送中!")
#coding:utf-8
import smtplib
from email.mime.text import MIMEText
import sys
mail_host = 'smtp.163.com'
mail_user = 'qxmaker'
mail_postfix = '163.com'
mail_pass = 'your_mail_password'
def send_mail(to_list,subject,content):
me = "zabbix 监控告警平台"+"<"+mail_user+"@"+mail_postfix+">"
#me = mail_user+"@"+mail_postfix
msg = MIMEText(content,'plain','utf-8')
msg['Subject'] = subject
msg['From'] = me
msg['To'] = to_list
try:
s = smtplib.SMTP()
s.connect(mail_host)
s.login(mail_user,mail_pass)
s.sendmail(me,to_list,msg.as_string())
s.close()
return True
except Exception as e:
print (e)
return False
if __name__ == "__main__":
send_mail(sys.argv[1],sys.argv[2],sys.argv[3])
print ("发邮件结束!")
注意: 我用的163邮箱,mail_pass = 'your_mail_password' 使用的是163邮箱的授权码,而不是邮箱真实密码。
说明:该脚本会调用第三方的邮箱账户,需要你填写正确的mail_host,mail_user以及mail_pass。假如脚本名字为mail.py,则发邮件的命令为:
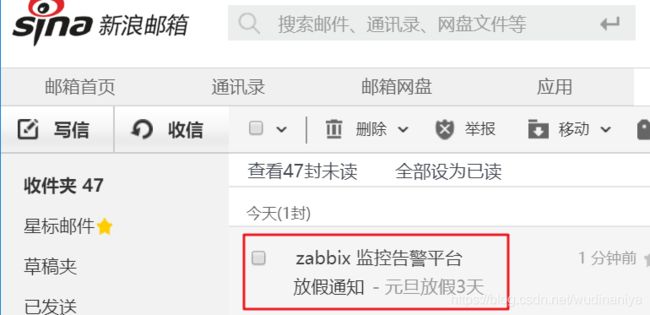
python3 mail.py [email protected] "邮件主题" "邮件内容"eg:![]()
打开我的新浪邮箱,可看到收到一条邮件主题是“放假通知”的信息。
有时,我们会看到 xxx 2>xxx 类似这样的命令
[root@slave1 ~]# python3 mail2.py [email protected] "周一例会" "今天上班第一天,大家请早上9:00准时开例会! " 2>error.log 解释:
命令会有一个错误输出信息, 2> 会把这个错误的信息写入到 2> 后面的文件中(注意:>前后不能有空格,eg:不能是 2 > error.log, 只能是2>error.log)
由于mail2.py文件不存在,因此error.log中将有出错信息:![]()