CDH 20个实战案例
本文源自:http://www.fblinux.com/?p=1560
1.CCA介绍
Cloudera Certified Associate(CCA认证)是Cloudera面向初中级 Hadoop技术人员推出的认证考试。由于Cloudera的Hadoop发行版是目前 使用最广泛的版本,Cloudera的认证也因此被广泛承认。能够获得这类 证书对于技术人员求职、企业投标等都是有重要作用的。
CCA认证又分为以下三个方向:
CCA Spark and Hadoop Developer:学会使用Apache Spark和其他 Cloudera企业级工具,实现对大数据的集成、转换、处理。
CCA Data Analyst:学会对原始数据进行加载、转换、清洗、建模,从 而定义数据间的关系并抽取出有意义的结果。
CCA Administrator:学会针对部署Cloudera Hadoop发行版的企业进行 核心系统和集群运维的技能。
本文会以CCA Administrator考试中的集群配置、扩容、升级、高可用、故障排除,常用操作等20个实例来进行分享,帮助大家快速掌握CDH的使用
2.案例一
描述:某个集群的使用者需要通过客户端登录集群,请使用CM下载HDFS 和YARN的配置文件,保存到客户端机器的/home/cert/problem1目录下, 并保持文件名不变。
操作流程:
登陆CM界面,选择HDFS服务,点击操作下载客户端配置,将下载的文件移动到客户端机器的/home/cert/problem1目录下

3.案例二
描述:根据管理要求,需要限制HDFS服务的日志大小。其限制为, NameNode服务保留4个日志文件,总量不超过8GB;Secondary NameNode 服务也保留4个日志文件,总量不超过8GB;两个服务总占用的磁盘空间 量不超过16GB
解答:根据简单计算,单个服务的单个日志只要不超 过2GB,并将日志数设为4个,即可以满足要求。
操作流程:
(1)登陆CM界面,选择HDFS服务,点击配置,搜索“NameNode Max Log Size”设置namenode和secondary最大日志大小为2G

(2)分别搜索“DataNode 最大日志文件备份”和“secondary NameNode 最大日志文件备份”并设置值为4


4.案例三
描述:集群承接了日志分析需求,将保存百万、千万数量级的文件,因此需要扩大NameNode使用的堆内存,使其可以管理尽可能多的文件。物理内存的分配要求为:节点总物理内存为31GB,为系统服务保留的内存 为6.2GB;NameNode和Secondary NameNode需设置相等大小的堆内存; 所有服务的堆内存均需要除以1.3后计入总使用量中。需要为NameNode 和相关服务配置尽可能大且满足要求的内存量,且不能触发任何警告。
解答:根据计算(31 – 6.2) / 1.3 = 19,因此 NameNode和Secondary NameNode各可设置9.5GB的堆内存。
操作流程:登陆CM界面,选择HDFS服务,点击“配置“,搜索“NameNode 的 Java 堆栈大小”,分别设置NameNode和secondary Namenode的堆大小为9.5G,设置完成后重启HDFS服务。

5.案例四
描述:公司新购了一批机器,准备扩充DataNode节点。你决定使用host template功能来为新机器配置DataNode通用的服务。新节点需要作为 HDFS和YARN的工作节点,因此模版的设计如下:
名称: Temp1
HDFS roles:DataNode
YARN roles:NodeManager 要求需要套用HDFS和YARN的Default Group的配置。
考点:在企业级实战中,集群扩容是常见且重要的 操作,如果手工一台一台操作,不仅效率低下,而且容易出错。CM 供 了多种机制来简化扩容操作,其中host template就是其中重要的一种, 通过该特性,可以大大简化工作节点的配置(对于管理节点、工具节点、 边缘节点,如果有多台配置完全一样,也可以使用该特性来扩容),如 DataNode,NodeManager,Kafka Broker等。
操作流程:
1、点击CM页面最上方的“主机”–> “主机模版”–>点击创建

2、输入模板名称,并根据要求选择角色,最后点击create保存

创建完成如下所示

6.案例五
描述:公司新购了一批机器,准备扩充DataNode节点。然而,新机器的 硬件配置和旧机器有一些差异。你决定为旧机器创建一个角色组,设置 合适的配置。新机器继续使用默认的角色组(Default Group)的配置, 就如前面我们配置的模版一样。新角色组的需求为,命名为DN1,先继 承默认的角色组的配置,并使旧机器套用DN1的配置。然后要变更一些 参数,DN1和Default Group的DataNode Volume Choosing Policy参数 都必需设置为Avaliable Space。Default Group的Available Space Policy Balanced Preference参数需要设置为0.85,DN1的Available Space Policy Balanced Preference参数需要设置为0.8。
操作流程:
1、选择HDFS服务,点击配置,点击右上的“角色组”,点击“创建”,输入指定的group name,然后选择从哪个角色组复制,最后点击创建。

2、点击左侧的DateNode Default Group这个组,全选所有节点,点击“已选定的操作”,点击“移动到另一个角色组”,选中DN1, 并Move。


3、回到配置页面,搜索”DataNode Volume Choosing Policy”,改为“可用空间”,保存。

4、搜索”Available Space Policy Balanced Preference”,点击属性名下 方的编辑单个值,将DN1的这一项改为0.8,DateNode Default Group的这一项改为0.85,保存。

5、点击集群名右侧的小箭头,“部署客户端配置”,然后重启 集群。
7.案例六
描述:正式地来将新节点加入集群。我们需要将hadoop6这个节点加入 CM的托管,并套用Temp1这个host template从而加入集群。
操作流程:
1、点击“主机” -“添加新主机到集群”,根据向导,搜索主机名 hadoop6.fblinux.com并选中,接下去的步骤和集群初始安装时基本一致,直到全部完成。

2、回到Hosts界面,选中hadoop6节点,点击已选定的操作-应用主机模板,选中Temp1,并打上勾,Confirm。全部执行完后, 该节点即具备DataNode和NodeManager的功能。


3、点击集群名右侧的小箭头,Deploy Client Configuration,然后重启集群。
8.案例七
描述:公司的数据分析师过去使用hive进行数据分析,由于impala的速度比hive更快,这些分析师很感兴趣,想在工作中使用这些组件。请你按照指定的要求来安装impala:Catalog Server和StateStore安装在Hadoop2上,impala Daemons安装在hadoop3和Hadoop4上。
操作流程:
1、在CM主界面集群选项中,点击“添加服务”即可,然后选择impala服务,选择对应的节点安装即可。

2、根据要求,选择安装的节点即可

9.案例八
描述:公司希望采用Kafka作为消息队列,需要你在当前集群中部署 Kafka服务。然而,之前有另一个管理员尝试部署Kafka但失败了。请部署Kafka,并解决安装过程中遇到的各种问题。
Kafka节点分配如下,Kafka Broker安装在hadoop5和hadoop6上,Gateway 安装在hadoop5上。
提示:如果没有干净卸载Kafka并再次安装,会出现”mismatched broker ID”的错误提示,可修改log.dirs参数并重启Kafka服务解决。
操作流程:
1、点击首页顶部的“主机”- “Parcels”
2、如果没有配置Kafka的源,需要加入源地址(http:// archive.cloudera.com/kafka/parcels/latest/),然后依次执行下载、分发、激活
(1)指定Kafka按照源,Kafka默认没有在CDH的安装中

(2)指定完成Kafka的源之后,在指定的parcel后面点击下载就可以开始下载Kafka的安装程序了
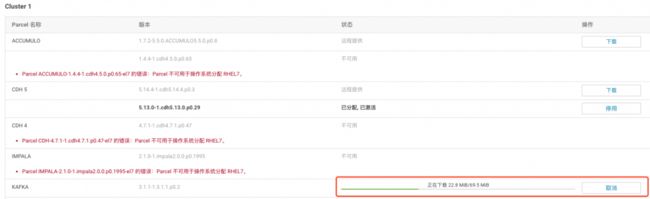
(3)下载完成之后点击分配,激活即可安装Kafka程序
3、回到首页,点击集群右侧的小箭头,添加服务,选择Kafka,根据要求选择节点,并完成服务的安装,如果遇到提示的错误,修过log.dirs参数即可。

10.案例九
描述:公司的数据分析师希望将一些数据从关系型数据库中导入Hive用于查询。你知道Sqoop组件可以完成该任务,但目前集群上没有。具体需求为:源数据为mysql中lesson库的student表,需要导入到Hive中 question9库的student表,并尽可能不改变数据类型。Sqoop Gateway 安装在hadoop3上。
准备内容:mysql数据库创建相关表并插入数据。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
操作流程:
1、点击集群名右侧的小箭头,添加服务,安装Sqoop服务。
2、在hive中创建所需的库和表
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
3、使用sqoop命令导入
| 1 2 3 4 5 6 7 8 9 10 11 |
|
4、hive 下验证数据

11.案例十
描述:在讨论公司的运维策略时,有人如果误删了HDFS的文件,可能几天都不会发现,尤其是当周末前发生这样的情况时。为了提供足够的保护级别,你决定将HDFS数据删除后永久清除的时间改为4天。
操作流程:
点击hdfs,配置,搜索“Trash”设置为4day,确保“使用垃圾箱”,勾选,然后重启hdfs服务

11.案例十一
描述:公司集群的NameNode今天发生了故障,你想通过分析fsimage文件来排查问题。你需要下载最新的fsimage文件,命名为 “timestamp_xxxxxxxxxx”,其中xxxxxxxxxx为以秒为单位的Unix时间戳, 代表你操作时的当前时间。并上传到HDFS的/user/cert/problem11目录下。
操作流程:
1、进入gateway的命令行,hdfs dfsadmin -fetchImage ./
2、mv fsimage_00000xxxxx timestamp_`date +%s`
3、确认下HDFS的/user/cert/problem11目录是否存在,如不存在需要建立 hdfs dfs -mkdir -p /user/cert/problem11
4、上传fsimage文件:hdfs dfs -copyFromLocal timestamp_xxxxxxxxxx /user/cert/ problem11
12.案例十二
描述:公司的集群新扩充了一批工作节点,但是新的工作节点上没有数 据,造成整个集群数据分布不均衡。你知道HDFS的balancer功能可以解决这个问题。请将balancer操作占用的带宽限制为1G以内,并以阀值5 启动balancer操作。
操作流程:
1、点击HDFS,配置,找到” DataNode 平衡带宽”设 置为1GB,找到”重新平衡阈值”设置为5

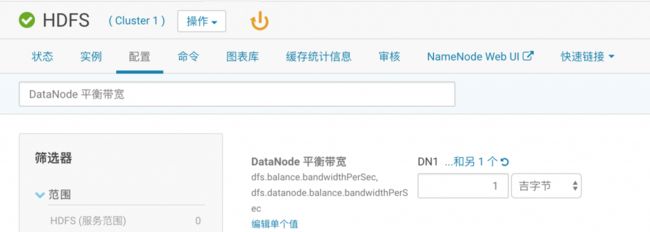

2、点击“操作”- “重新平衡”(或者进入gateway的命令行,执行hdfs balancer -threshold 5)

13.案例十三
描述:公司的某用户在HDFS上存放了重要的文件,但是不小心将其删除 了。幸运的是,该目录被设置为可快照的,并曾经创建过几次快照。请 使用最近的一个快照恢复数据。要求为恢复/user/cert/problem13目录 下的所有文件,并恢复文件原有的权限、所有者、ACL。
操作步骤:
(1)快照功能需要升级到企业版
1、在主界面,右上角点击试用cloudera enterprise 60天,按照引导操作即可。

2、升级企业版过程中,有3个服务需要安装,这里安装到空闲的节点即可。

(2)上传测试数据
| 1 2 3 4 5 |
|
(3)在CM中启用该目录的快照特性,并打快照


(4)删除之前上传的文件
| 1 |
|
(5)恢复快照


14.案例十四
描述:公司一个运维人员尝试优化集群,但反而使得一些以前可以运行 的MapReduce作业不能运行了。请你识别问题并予以纠正,并成功运行 性能测试,要求为在Linux文件系统上找到hadoop-mapreduce- examples.jar包,并使用它完成三步测试:
1、使用teragen 10000000 problem14/ts_input 生成10000000行测 试记录并输出到指定目录
2、使用terasort problem14/ts_input problem14/ts_output 进行 排序并输出到指定目录
3、使用teravalidate problem14/ts_output problem14/ ts_validate检查输出结果
操作步骤:
1、生成输入数据
| 1 2 |
|
2、排序和输出
| 1 |
|
3、验证输出
| 1 |
|
15.案例十五
描述:今天hadoop3节点的DataNode和NodeManager进程频繁死掉,你决 定临时将该节点这两个进程的日志级别调整为DEBUG,以便于进行故障 排查。
操作步骤:
1、点击“主机”—“所有主机”,点开hadoop3节点的roles,点击HDFS datanode,进入配置页面

2、搜索“DataNode 记录阈值”将其改为DEBUG并保存。
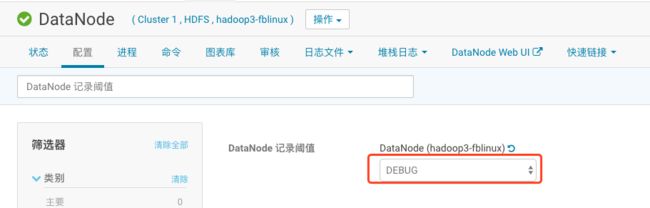
3、回到“所有主机”页面,点开hadoop3节点的roles,点击YARN NodeManager,进入配置页面

16.案例十六
描述:公司的某个开发人员尝试在集群上运行wordcount程序,但作业 执行时发生错误,请你帮助解决。请将gateway机器cert家目录下的 input.txt文件上传到HDFS上cert家目录下的problem16/input中,并执行wordcount problem16/input/input.txt problem16/output来测试是否可以运行。
操作流程:
1、上传文件
| 1 2 3 |
|
2、执行wordcount
| 1 2 |
|
发现报目录存在的Exception,于是:
| 1 2 |
|
17.案例十七
描述:对集群进行例行检查的时候,你发现有个别重要文件的副本数只 有2个,而集群默认的副本数参数为3个,并没有修改过。请解决/user/ cert/problem14/ts_input目录下的文件副本数不足的问题
操作步骤:
1、在命令行修改目录下所有文件的副本数
| 1 |
|
18.案例十八
描述:你发现,集群中一些大文件的块大小为64MB,导致MapReduce作 业使用这些文件时,默认会产生较多的map数,造成资源浪费。你决定 将这些文件以128MB的块大小备份到另一个目录中。请将/user/cert/ problem18/input下的文件以128MB的块大小备份到/user/cert/ problem18/output下。
操作:
1、确认集群默认的块大小,点击HDFS,配置,找到”HDFS Block Size”,已经是128MB了,因此备份时不需要加指定块大小的参数。

2、创建备份目录并复制
| 1 2 |
|
19.案例十九
描述:升级集群版从CDH5.13.0到CDH5.14.0: 保持集群版本处于比较新的状态,可以尽量避免已知的bug,并享受新版 本的特性。通常实践中推荐使用比最新版本的版本号中间位低1-2的集群。 另外需要注意CM只能管理不高于其版本的CDH,如CM5.13最高只能将集群 版本升级到CDH5.13。如果CM版本不够,则需要先升级CM,后升级CDH。
CM升级参见:
https://www.cloudera.com/documentation/enterprise/5-10-x/topics/ cm_ag_ug_cm5.html
CDH升级参见:
https://www.cloudera.com/documentation/enterprise/5-10-x/topics/cm_mc_upgrading_cdh.html
步骤:
1、清理一下磁盘空间,保证每个节点有20G以上的空间,集群可以不用启动。
2、主机 – Parcels – 配置,在远程parcel存储库URL下新增一项https://archive.cloudera.com/cdh5/parcels/5.14.0/

3、集群名右侧的小箭头,升级集群
4、选择CDH 5.14.0-1.cdh5.14.0.p0.24,然后一路Continue
20.案例二十
开启NameNode HA:
NameNode HA的配置参见: https://www.cloudera.com/documentation/enterprise/5-10-x/topics/ cdh_hag_hdfs_ha_config.html
操作步骤:
1、集群可以不用启动,但ZooKeeper需要先起来
2、点击HDFS服务,点击操作 – 启用High Availability

3、Nameservice Name默认即可
4、NameNode Hosts一个仍是hadoop1,另一个选hadoop2。JournalNode Hosts可选hadoop3-5

5、输入hadoop3-5上用于JN的磁盘目录,设为/dfs/jn

6、下一个页面等待运行完成即可。其中Format NameNode一步会失败,这 是符合预期的
7、HA配置完成之后,实例分布如下图所示
