点评网的反爬再也不是烦恼
感谢关注天善智能,走好数据之路↑↑↑
欢迎关注天善智能,我们是专注于商业智能BI,人工智能AI,大数据分析与挖掘领域的垂直社区,学习,问答、求职一站式搞定!
对商业智能BI、大数据分析挖掘、机器学习,python,R等数据领域感兴趣的同学加微信:tstoutiao,邀请你进入数据爱好者交流群,数据爱好者们都在这儿。
作者:强哥,现供职于一家大型全球电子商务网站,多年Python程序员,热爱数据,热爱AI,希望能与更多同业人交流。
个人公众号:Python与数据分析
点评网的反爬设置在我们爬取点评网页的时候给我们造成了不小的障碍。在网页上我们看到的是这样的
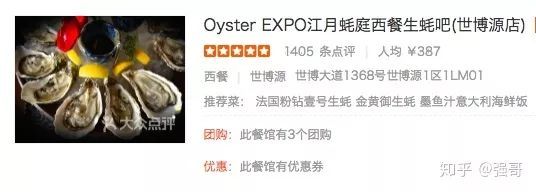
网页上可以看到这家餐厅有1405条评论,人均387。但在分析页面源码的时候,我们却看不到网页上的数字,看到是这样的代码
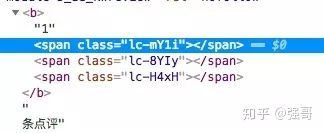
点评网对数字做了处理,一些数字的信息像评论条数、人均、评分等都做了反爬保护。上面的网页中评论条数是1405条,但在页面源码中,除了第一个数字1以外,后面的数字我们看不到,都是一些像随机编码一样的css class。
如果我们仔细分析这个css class,其实是不难发现背后的原理的。
通过开发者工具,我们找到这个css的定义,可以看到是下面这样的
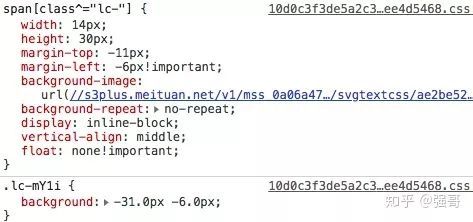
background-image属性里面是一个url,我们在浏览器里打开它,看到它的内容是
lc-mY1i 这个css class里面是一个background属性,定义了背景图片偏移的位置。
所以点评网上显示数字的原理就是通过设置不同的偏移位置,显示背景图片相应位置上的数字。我们可以想象背景图片的前面有一个窗口,窗口的大小刚好够显示一个数字。窗口是固定不动的,背景图片在后面移动,移动到不同的位置就能显示这个位置上的数字。
进一步分析背景图片,我们可以发现,这是一个SVG图片,图片中的数字可以在svg的源码中看到,如下
理解了原理后,我们用代码来实现一下解析的过程。
首先我们从点评的网页上找出css文件的url,代码如下
def get_css(): url = "http://www.dianping.com/shanghai/ch10" r = requests.get(url, headers=headers) content = r.content.decode("utf-8") matched = re.search(r'href="([^"]+svgtextcss[^"]+)"', content, re.M) if not matched: raise Exception("cannot find svgtextcss file") css_url = matched.group(1) css_url = fix_url(css_url) return css_url
随后我们从css里找到背景图片的路径,并获取SVG图片中的每个数字
def get_svg(css_url): r = requests.get(css_url, headers=headers) content = r.content.decode("utf-8") matched = re.search(r'span\[class\^="lc\-"\].*?background\-image: url\((.*?)\);', content) if not matched: raise Exception("cannot find svg file") svg_url = matched.group(1) svg_url = fix_url(svg_url) r = requests.get(svg_url, headers=headers) content = r.content.decode("utf-8") matched = re.search(r'class="textStyle">(\d+)', content) if not matched: raise Exception("cannot find digits") digits = list(matched.group(1)) return digits
这个函数返回一个数组,数组的内容是SVG图片中的所有数字。
对于点评网页中的用css class表示的数字,我们来解析一下css class和数字之间的对应关系
def get_class_offset(css_url): r = requests.get(css_url, headers=headers) content = r.content.decode("utf-8") matched = re.findall(r'(\.[a-zA-Z0-9-]+)\{background:(\-\d+\.\d+)px', content) result = {} for item in matched: css_class = item[0][1:] offset = item[1] result[css_class] = offset return result
这个函数返回的是一个字典,它的key是css class的名字,value是css class对应的数字在背景图片中的偏移量。
接下来,我们以评论条数为例,来获取点评上一个页面里每家餐厅的评论条数。先定义函数,用于获取评论条数
def get_review_num(page_url, class_offset, digits): r = requests.get(page_url, headers=headers) content = r.content.decode("utf-8") root = etree.HTML(content) shop_nodes = root.xpath('.//div[@id="shop-all-list"]/ul/li') for shop_node in shop_nodes: name_node = shop_node.xpath('.//div[@class="tit"]/a')[0] name = name_node.attrib["title"] review_num_node = shop_node.xpath('.//div[@class="comment"]/a[@class="review-num"]/b')[0] num = 0 if review_num_node.text: num = num * 10 + int(review_num_node.text) for digit_node in review_num_node: css_class = digit_node.attrib["class"] offset = class_offset[css_class] index = int((float(offset)+7)/-12) digit = int(digits[index]) num = num * 10 + digit last_digit = review_num_node[-1].tail if last_digit: num = num * 10 + int(last_digit) print("restaurant: {}, review num: {}".format(name, num))
然后调用函数,爬一下页面中每家餐厅的评论条数
css_url = get_css()digits = get_svg(css_url)class_offset = get_class_offset(css_url)url = "http://www.dianping.com/shanghai/ch10/g116"get_review_num(url, class_offset, digits)
运行代码后,得到如下的结果
restaurant: 1886汽车主题德国餐厅(环宇荟店), review num: 1021restaurant: Mia Fringe迷芬奇餐厅&酒吧, review num: 152restaurant: Oyster EXPO江月蚝庭西餐生蚝吧(世博源店), review num: 1405restaurant: 宝莱纳餐厅(陆家嘴店), review num: 7854restaurant: Pizza Marzano玛尚诺(港汇店), review num: 7527restaurant: love&salt牛排馆, review num: 86restaurant: Da Ivo 意大利魔镜餐厅, review num: 3497restaurant: Mr Nice好好先生餐厅(月星环球港店), review num: 9052restaurant: L'ATELIER de Joël Robuchon, review num: 2821restaurant: Stone Sal 言盐西餐厅, review num: 62restaurant: 夏朵花园, review num: 3031restaurant: 壳里西餐厅Coquille Seafood Bistro, review num: 322restaurant: ICHA Chateau Bar & Restaurant(酒吧创意料理), review num: 496restaurant: 菲斯特花园西餐厅, review num: 655restaurant: 宝丽嘉酒店Cafe Bellagio(宝丽嘉西餐厅), review num: 598
对照网页上的数据,可以看到,餐厅的评论条数都被正确的解析出来了。
Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
关注后在公众号内回复“课程”即可获取:
小编的转行入职数据科学(数据分析挖掘/机器学习方向)【最新免费】
小编的Python入门免费视频课程!!!
小编的Python快速上手matplotlib可视化库!!!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。
