DirectX 11 学习笔记-Demo-04
高斯模糊与Compute Shader
模糊是游戏中常见的一种效果。模糊算法的一般做法是,对某一点的像素,将它与它周围的m*n个像素按照一定的权值累加起来,作为该点的新的像素值。
高斯模糊是指权值根据高斯方程来确定的模糊算法。
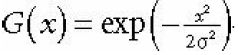
假设我们选择做一个1*5的高斯模糊计算,定义0为目标像素,则共有-2,-1,0,1,2五个像素点,它们的系数G(x)可以由以下的方程确定
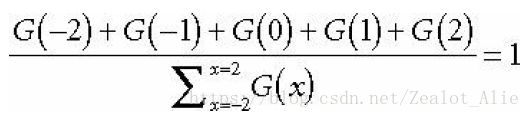
Demo中实现的算法实际上是按照横向和纵向对同一点做两次1x11的模糊,所以可以完全拆分为两个部分,即横向和纵向。
代码部分我们先看Shader代码,以横向为例。
cbuffer cbFixed
{
static const int gBlurRadius = 5;
}
#define N 256
#define CACHE_SIZE (N+2*gBlurRadius)
groupshared float4 gCache[CACHE_SIZE];
[numthreads(N,1,1)]
void HorzBlurCS(int3 groupThreadID : SV_GroupThreadID,
int3 dispatchThreadID : SV_DispatchThreadID)
{
if(groupThreadID.x < gBlurRadius)
{
int x = max(dispatchThreadID.x-gBlurRadius, 0);
gCache[groupThreadID.x] = gInput[int2(x,dispatchThreadID.y)];
}
if(groupThreadID.x >= N-gBlurRadius)
{
int x = min(dispatchThreadID.x+gBlurRadius,gInput.Length.x - 1);
gCache[groupThreadID.x+2*gBlurRadius] = gInput[int2(x, dispatchThreadID.y)];
}
gCache[groupThreadID.x+gBlurRadius] = gInput[min(dispatchThreadID.xy, gInput.Length.xy-1)];
GroupMemoryBarrierWithGroupSync();
float4 blurColor = float4(0,0,0,0);
[unroll]
for(int i = -gBlurRadius; i <= gBlurRadius;++i)
{
int k = groupThreadID.x + gBlurRadius + i;
blurColor += gWeights[i+gBlurRadius]*gCache[k];
}
gOutput[dispatchThreadID.xy] = blurColor;
} 这里定义了一个组内共有256个线程,同时定义了一个大小为256+2*gBlurRadius = 266的共享内存数组。
故对同一个线程组内的线程,SV_GroupThreadID的值为(0,0,0)到(255,0,0)。
让每个线程处理一个像素点的计算,则一个线程组最多可以处理256个像素。如果图象宽度为m,那么处理一行像素最少需要ceilf(m/256)个组。对这些像素,计算它们模糊后的值,需要的像素数量是266,我们将这些需要的像素先读入到共享内存之中。
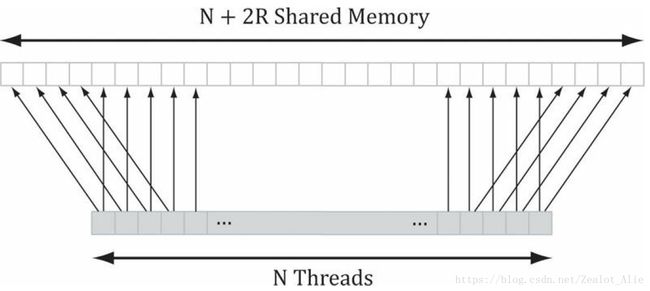 线程与共享内存数组索引的对应关系
线程与共享内存数组索引的对应关系
着色器中,第一步是纹理采样。
由于需要的纹理数量多于线程数,所以有的线程需要采样两次纹理,采样纹理和线程的对应关系如上图,采样完成之后需要调用GroupMemoryBarrierWithGroupSync()确保所有的像素都已经采样完毕。采样完毕之后根据系数求出每个像素点的最终值即可。
现考虑整个完整的图形,处理一行像素需要ceilf(m/256),纹理一共有n行,则总共需要ceilf(m/256)*n行
// How many groups do we need to dispatch to cover a row of pixels, where each
// group covers 256 pixels (the 256 is defined in the ComputeShader).
UINT numGroupsX = (UINT)ceilf(mWidth / 256.0f);
dc->Dispatch(numGroupsX, mHeight, 1); 在着色器中,SV_DispatchThreadID.xy就是线程对应的像素的id。另外需要注意纹理边界的问题,在这里对超出纹理范围的像素点,取纹理最边缘的那个像素值(类似采样时的border color)。
计算完成后需要将离屏的纹理绘制到屏幕中,为此我们需要创建一个全屏的矩形图元,保证它能充满整个屏幕。
我们知道,在NDC(normalized device coordinates)空间中,投影窗口的高度和宽度都是2,也就是说此时屏幕的四个顶点的坐标xy分别为(-1,-1),(-1,1),(1,1),(1,-1),对应的UV的值为(0,1,)(0,0,),(1,0),(1,1)。我们只需要确保最终的NDC坐标值正确即可。在顶点着色器中,齐次裁剪坐标计算如下
// Transform to homogeneous clip space.
vout.PosH = mul(float4(vin.PosL, 1.0f), gWorldViewProj);也就是说,如果我们把gWorldViewProj矩阵直接设为单位矩阵,那么我们的本地坐标点就能直接对应到NDC中的屏幕四个顶点。
水波的计算改良
实际上学习了Compute Shader之后,我们应该很容易想到之前的Wave实际上更适合用Compute Shader来实现,因为这样能避免Dynamic资源的Map过程,而Map开销还是比较大的。
这里我们需要两个buffer,一个用于存放顶点数据,另一个用于存放前一帧的wave的高度。
RWStructuredBuffer gWaveOutput;
RWBuffer gWavePreY; 计算直接参考C++代码中关于水波的部分即可,计算完成后结果存放在gWaveOutput中,并更新gWavePreY。
之所以需要另外一个buffer是因为顶点缓冲区不能同时为RW,所以我们需要一个RW资源作为Compute Shader的输出,然后在计算完成后,使用CopyResource将输出拷贝到顶点缓冲区资源中。由于这两部分都是在GPU中的,所以拷贝速度是非常快的。
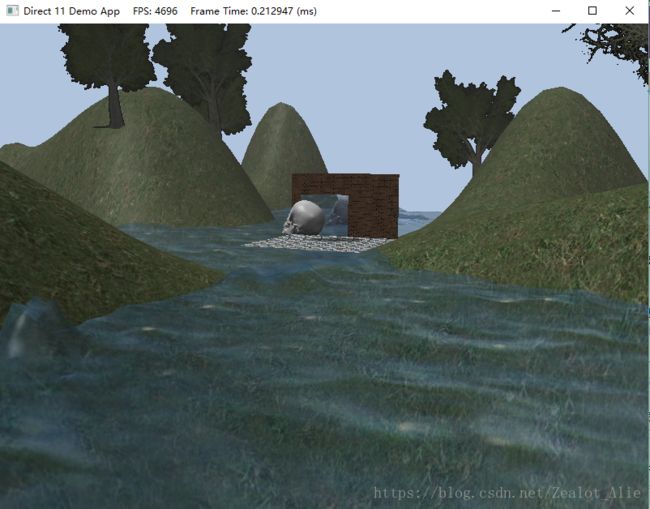 使用CS计算水波每帧时间为0.2ms左右
使用CS计算水波每帧时间为0.2ms左右
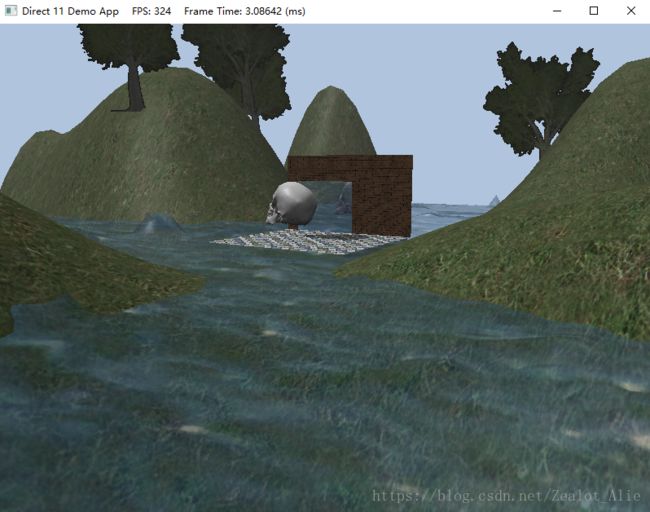 使用Dynamic Resource绘制需要3ms左右
使用Dynamic Resource绘制需要3ms左右
对比使用Dynamic Resource和Compute Shader两种方式下水波,可以明显看到Compute Shader方式极大的缩短了帧时间,提高了运行速度。