U-GAT-IT 翻译
摘要:
我们提出了一种新的无监督的图像到图像的转换方法,它以端到端的方式结合了一个新的注意力模块和一个新的可学习归一化功能。注意力模块指导我们的模型根据辅助分类器获得的注意力图,把重点放在区分源域和目标域的更重要区域。不同于以往不能处理域之间的几何变化的基于注意的方法,我们的模型可以转换需要整体变化的图像和需要大的形状变化的图像。而且,我们新提出的AdaLin(自适应图层-实例归一化)功能,通过在数据集上学习参数,帮助我们基于注意力引导的模型能够灵活的控制在形状和结构上的改变。实验结果表明,与现有的具有固定网络结构和高参数的最新模型相比,该方法具有优越性。代码和数据集在全球最大同性交友网站上可以获取,给个友情链接:https://github.com/taki0112/UGATIT 或 https://github.com/znxlwm/UGATITpytorch
介绍:(简化翻译,有些是废话,没必要翻译的很仔细)
图像到图像的转换旨在学习在两个不同域中映射图像的函数。这个话题在机器学习和计算机视觉的研究者之间获得了广泛的关注,由于它在各方面都有应用。当给予配对的数据集,模型可以用一个条件生成模型或简单回归模型以监督学习的方式训练。在没有配对数据集的时候,图像通过共享潜在空间和循环一致性假设方法也能成功转换。这些工作已进一步发展,以处理多种形式的任务。
尽管有这些进步,以前的方法根据不用域之间形状和纹理的变化量显示性能差异。举个例子,它们能成功把照片变换为梵高的风格,但是不能在把狗变成猫的任务上执行很好。因此,一些预处理会被使用,来避免数据分布的复杂性。除此之外,现存的方法,比如DRIT,在保存形状和改变形状但固定网络结构和超参数两方面不能都得到想要的结果。网络结构和超参数需要根据具体数据集来调整。
在这项工作中,我们提出了一种新的无监督的图像到图像的转换方法,它以端到端的方式结合了一个新的注意力模块和一个新的可学习归一化功能。我们的模型引导图片转换的注意力到更重要的区域,并且忽视次要区域,通过基于辅助分类器获得的注意力图来区分,这种区分在源域和目标域都有。这些注意力图被嵌入到生成器域判别器,用于关注语义上重要的区域,从而促进形状上的转换。当生成器中的注意力图将重点集中在两个域之间特定区分的区域上时,鉴别器中的注意力图通过关注目标域中真实图像和虚假图像之间的差异,来进行微调。除了注意力机制,我们发现归一化功能的选择对在形状和结构各不相同的多个数据集上的转换结果有重要的影响。受批-实例归一化(BIN)的启发,我们提出了一个自适应的图层-实例归一化,它的参数在训练阶段通过自适应地调整实例归一化(IN)和图层归一化(LN)之间的比例来学习。这个AdaLIN功能帮助我们基于注意力引导的模型灵活地控制形状和结构上的改变。因此,我们的模型,不需要修正结构或超参数,就能很好的完成图像转换任务,不管时整体的变化还是形状上的大改。在实验中,我们展示了提出的方法的优越性,通过在风格转换和目标转换领域最优的模型比较。工作的主要贡献为以下三点:
1)我们提出了一种新的无监督图像到图像转换方法,它具有新的注意模块和新的归一化函数AdaLIN。
2)我们的注意模块通过基于辅助分类器获得的注意力图来区分源域和目标域,从而帮助模型知道在何处进行密集转换。
3)AdaLIN功能帮助我们的基于注意力引导的模型在不修改模型架构或超参数的情况下灵活地控制更改形状和纹理的数量。
相关工作:
我也不知道为什么我找到的论文没有相关工作,网上看到的一个翻译有相关工作,我按照自己的来了,就不讲相关工作方面了。
讲模型之前先放图,整个网络是生成对抗网络形式,用的为类似cycle GAN的结构,图中只展示生成器和判别器的组成。我觉得以下的图与翻译不能很好的理解,得看源码(至少对我来说是这样的)。
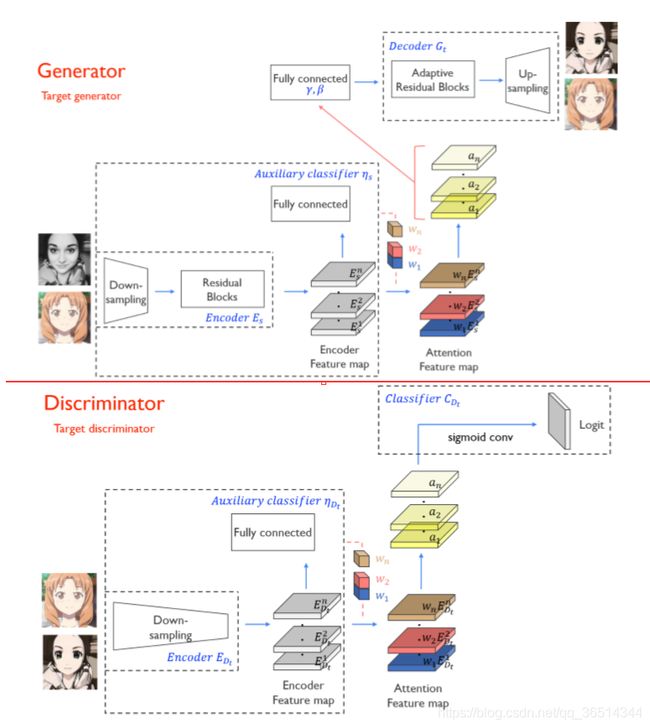
模型:
我们的的目标时训练一个函数![]() 将图片从源域
将图片从源域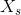 映射到目标域
映射到目标域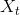 ,这个训练过程仅仅使用未配对的样本。我们的模型框架包含了两个生成器
,这个训练过程仅仅使用未配对的样本。我们的模型框架包含了两个生成器![]() 和
和![]() 以及两个判别器
以及两个判别器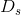 和
和 。注意力模块在生成器与判别器中都有使用,在判别器的注意力使模型重点关注更重要的区域,在生成器的注意力用来区分两域。我们只讲
。注意力模块在生成器与判别器中都有使用,在判别器的注意力使模型重点关注更重要的区域,在生成器的注意力用来区分两域。我们只讲![]() 和,另一对同理。
和,另一对同理。
生成器
定义和分别表示源域和目标域的样本集合。生成模型![]() 包含了编码器
包含了编码器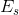 ,解码器
,解码器 和辅助分类器
和辅助分类器![]() 。
。![]() 表示x来自的可能性。定义
表示x来自的可能性。定义![]() 表示编码器输出层的第k个激活图,
表示编码器输出层的第k个激活图,![]() 表示这个激活图(i,j)处的值。由于被CAM启发(CAM使一种注意力可视化的工具吧),辅助分类器使用全局最大池化和全局平均池化来训练,用来学习源域第k层特征图的权重
表示这个激活图(i,j)处的值。由于被CAM启发(CAM使一种注意力可视化的工具吧),辅助分类器使用全局最大池化和全局平均池化来训练,用来学习源域第k层特征图的权重![]() ,其具体表达式为:
,其具体表达式为: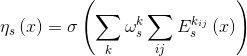 。
。
通过利用![]() ,我们可以计算得到具体域的注意力特征图
,我们可以计算得到具体域的注意力特征图![]() ,其中n是编码器输出特征图的通道数。然后生成模型就相当于
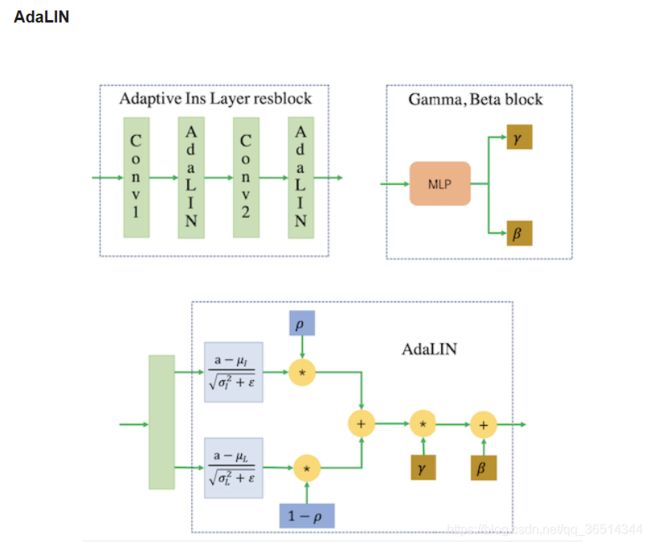
,其中n是编码器输出特征图的通道数。然后生成模型就相当于![]() 。受最近在归一化层和组合归一化函数中使用有限变换参数的工作启发,我们在残差块中添加了AdaLIN,AdaLIN的参数γ和β由注意力图中的全连接层动态计算。
。受最近在归一化层和组合归一化函数中使用有限变换参数的工作启发,我们在残差块中添加了AdaLIN,AdaLIN的参数γ和β由注意力图中的全连接层动态计算。
![]() (实际代码
(实际代码
 在括号外)
在括号外)
![]() ,
,![]()
![]()
其中![]() 和
和![]() 是通道的均值和标准差,
是通道的均值和标准差,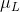 和
和![]() 是层的均值和标准差。
是层的均值和标准差。 和是全连接层生成的参数,
和是全连接层生成的参数, 是学习率,
是学习率,![]() 表示优化器确定的参数更新向量(例如梯度)。通过在参数更新步骤施加边界,将
表示优化器确定的参数更新向量(例如梯度)。通过在参数更新步骤施加边界,将 的值限制在[0,1]的范围内。在生成器中,如果实例归一化比较重要,接近1,如果层归一化比较重要,接近0。在编码器的残差块中,初始化为1,而在上采样块中,初始化为0。
的值限制在[0,1]的范围内。在生成器中,如果实例归一化比较重要,接近1,如果层归一化比较重要,接近0。在编码器的残差块中,初始化为1,而在上采样块中,初始化为0。
将内容图转换到某种风格图的最佳方法是应用白化着色变换(WCT),但计算代价很大。AdaIN比WCT快很多,它是WCT的次优方法,并且它假设了特征通道之间的不相关性,因此,转化后的特征包含了更多的内容中的模式。而LN没有假设通道的不相关性,有时候它不能很好的保存源域的内容结构,因为它只考虑特征图的全局统计。 为了克服这点,我们提出的AdaLIN通过可选择的保持或者改变内容的信息的方法把DdaIN和LN的有点联合起来,这解决了很多的图像转换问题。
判别器
定义和![]() 分别代表目标域图片和源域转换之后的图片。与其他转换模型类似,判别器包含编码器
分别代表目标域图片和源域转换之后的图片。与其他转换模型类似,判别器包含编码器![]() ,分类器
,分类器![]() 和辅助分类器
和辅助分类器![]() 。与其他模型不同的是,我们的
。与其他模型不同的是,我们的![]() 和
和![]() 都是用来判断x来自还是
都是用来判断x来自还是![]() 。给定x,
。给定x,![]() 利用
利用![]() 来工作,
来工作,![]() 由
由![]() 训练的
训练的![]() ,然后把
,然后把![]() 作用于编码器输出
作用于编码器输出![]() ,如式
,如式![]() 求得。然后我们的
求得。然后我们的![]() 就相当于
就相当于![]()
损失函数
我们模型的全部目标包括四个损失函数 。我们使用LSGAN的对抗损失来帮助平稳训练。
对抗损失:

循环一致损失:从Xs生成假的Xt,再从假的Xt到Xs,要能够恢复回来。
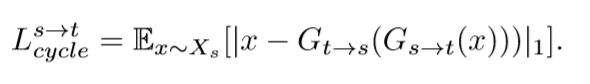
一致损失:我们的生成器能用Xs生成假的Xt,那用Xt去生成假的Xt,应该更容易且更好。
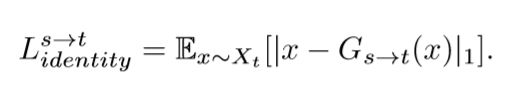
CAM损失:CAM利用了辅助分类器![]() 和
和![]() 的信息。给定一个图像x∈{Xs,Xt},
的信息。给定一个图像x∈{Xs,Xt},![]() 和知道他们需要改进的地方,或者在当前状态下两个域之间的最大区别是什么。
和知道他们需要改进的地方,或者在当前状态下两个域之间的最大区别是什么。
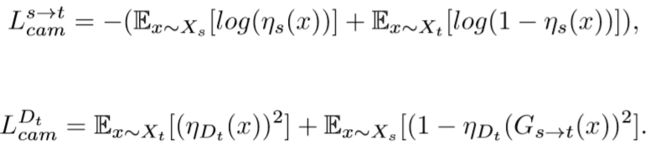
整体目标:
![]()
我们使用的参数是:λ1 = 1,λ2 = 10,λ3 = 10,λ4 = 1000。这里![]() ,其他几个部分也同样由两项。主要是和cycleGAN那样。
,其他几个部分也同样由两项。主要是和cycleGAN那样。
实验
基准模型
我们用cycle GAN,UNIT,MUNIT,DRIT,AGGAN和CartoonGAN与我们的方法比较,所有的代码都用了作者提供的代码。
数据集
我们用4个有代表性的数据集和1个自建的数据集评价模型,所有的图片大小都是256*256像素。
实验结果
我们首先分析了注意力机制与AdaLIN对模型的影响,然后比较了该模型与其他模型之间性能差距。为了评估翻译图像的视觉质量,我们进行了一项用户研究。用户被要求在五种不同方法生成的图像中选择最佳图像。补充材料中包括了将我们的模型与其他模型进行比较的更多结果示例。
以下为注意力机制的可视化与它的影响:
a)原图 b)生成器注意力图 c-d)判别器的局部与全局注意力图 e)加了CAM的结果 f)没有CAM的结果

CAM分析
首先我们进行了去除研究来确定生成器与判别器的注意力的作用。正如上图b展示,注意力图帮助生成器聚焦于更易于从目标图像区别的原图区域。比如眼睛或嘴巴。同时,通过可视化鉴别器的局部和全局注意图,我们可以看到鉴别器集中注意力的区域来判断目标图像是真是假,如上图c,d。生成器可以使用判别器的注意图来微调。注意,我们结合了两个具有不同大小感受野的鉴别器的全局和局部注意图。这些地图可以帮助生成器捕获全局结构和局部区域。有了这些信息,一些地区的翻译就更加仔细了。上图e展示了使用注意力机制的优点。另一方面,可以看到眼睛未对齐,或者根本没转换,如上图f。
AdaLIN分析
下图展示不同注意力的作用:
a)原图 b)我们的结果 c)IN+CAM d)LN+CAM e)AdaIN+CAM f)GN+CAM

不想分析了,反正就是AdaLIN的效果最好就完了。
再看看别的模型和本文模型的结果评价:
a)原图 b)U-GAT-IT c)cycleGAN d)UNIT e)MUNIT f)DRIT g)AGGAN

文中有些地方需要看源码才能理解,如果有无法理解的地方,建议看源码
附录
附录中会参考其他作者的解读,侵删
以下来自:https://www.sohu.com/a/333947112_500659

由上图,我们可以看到对于图像经过下采样和残差块得到的 Encoder Feature map 经过 Global average pooling 和 Global max pooling 后得到依托通道数的特征向量。创建可学习参数 weight,经过全连接层压缩到 B×1 维,这里的 B 是 BatchSize,对于图像转换,通常取为 1。
对于学习参数 weight 和 Encoder Feature map 做 multiply(对应位想乘)也就是对于 Encoder Feature map 的每一个通道,我们赋予一个权重,这个权重决定了这一通道对应特征的重要性,这就实现了 Feature map 下的注意力机制。
对于经过全连接得到的 B×1 维,在 average 和 max pooling 下做 concat 后送入分类,做源域和目标域的分类判断,这是个无监督过程,仅仅知道的是源域和目标域,这种二分类问题在 CAM 全局和平均池化下可以实现很好的分类。
当生成器可以很好的区分出源域和目标域输入时在注意力模块下可以帮助模型知道在何处进行密集转换。将 average 和 max 得到的注意力图做 concat,经过一层卷积层还原为输入通道数,便送入 AdaLIN 下进行自适应归一化。
这边有点问题,weight其实来自fully connected,所以图中有点小错误。