tensorflow BP神经网络 波士顿房价预测
前言
啥也别说了,上代码
code
# 根据波士顿房价信息进行预测,多元线性回归 + 特征数据归一化 + 可视化 + TensorBoard可视化
#读取数据
from sklearn.metrics import mean_squared_error #均方误差
from sklearn.metrics import mean_absolute_error #平方绝对误差
from sklearn.metrics import r2_score#R square
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd # 能快速读取常规大小的文件。Pandas能提供高性能、易用的数据结构和数据分析工具
from sklearn.utils import shuffle # 随机打乱工具,将原有序列打乱,返回一个全新的顺序错乱的值
# 迭代轮次
train_epochs = 50
# 学习率
learning_rate = 0.01
# 读取数据文件
def get_data():
mydf = pd.read_excel('data.xlsx', encoding='utf-8')
df = mydf.values
# 把df转换成np的数组格式
df = np.array(df)
return df
def normal(df):
# 特征数据归一化
# 对特征数据{0到11}列 做(0-1)归一化
for i in range(13):
df[:, i] = (df[:, i] - df[:, i].min()) / (df[:, i].max() - df[:, i].min())
# x_data为归一化后的前12列特征数据
x_data = df[:, :13]
# y_data为最后1列标签数据
y_data = df[:, 13]
return x_data, y_data
def model():
# 模型定义
# 定义特征数据和标签数据的占位符
# shape中None表示行的数量未知,在实际训练时决定一次带入多少行样本,从一个样本的随机SDG到批量SDG都可以
x = tf.placeholder(tf.float32, [None, 13], name="X") # 12个特征数据(12列)
y = tf.placeholder(tf.float32, [None, 1], name="Y") # 1个标签数据(1列)
# 定义模型函数
# 定义了一个命名空间.
# 命名空间name_scope,Tensoflow计算图模型中常有数以千计节点,在可视化过程中很难一下子全部展示出来/
# 因此可用name_scope为变量划分范围,在可视化中,这表示在计算图中的一个层级
with tf.name_scope("Model"):
# w 初始化值为shape=(12,1)的随机数
w = tf.Variable(tf.random_normal([13, 1], stddev=0.01), name="W")
# b 初始化值为1.0
b = tf.Variable(1.0, name="b")
# w和x是矩阵相乘,用matmul,不能用mutiply或者*
def model(x, w, b):
return tf.matmul(x, w) + b
# 预测计算操作,前向计算节点
pred = model(x, w, b)
# 定义均方差损失函数
# 定义损失函数
with tf.name_scope("LossFunction"):
loss_function = tf.reduce_mean(tf.pow(y - pred, 2)) # 均方误差
# 创建优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function)
return loss_function, optimizer, pred, x, y, b, w
def run_model(loss_function, optimizer, pred, x_data, y_data, x, y, b, w):
# 声明会话
sess = tf.Session()
# 定义初始化变量的操作
init = tf.global_variables_initializer()
# 为TensorBoard可视化准备数据
# 设置日志存储目录
logdir = './test'
# 创建一个操作,用于记录损失值loss,后面在TensorBoard中SCALARS栏可见
sum_loss_op = tf.summary.scalar("loss", loss_function)
# 把所有需要记录摘要日志文件的合并,方便一次性写入
merged = tf.summary.merge_all()
# 启动会话
sess.run(init)
# 创建摘要的文件写入器
# 创建摘要writer,将计算图写入摘要文件,后面在Tensorflow中GRAPHS栏可见
writer = tf.summary.FileWriter(logdir, sess.graph)
# 迭代训练
loss_list = [] # 用于保存loss值的列表
Add_train_y = []
Add_predict_y = []
for epoch in range(train_epochs):
loss_sum = 0.0
for xs, ys in zip(x_data, y_data):
xs = xs.reshape(1, 13)
ys = ys.reshape(1, 1)
# feed数据必须和Placeholder的shape一致
_, summary_str, loss = sess.run([optimizer, sum_loss_op, loss_function], feed_dict={x: xs, y: ys})
writer.add_summary(summary_str, epoch)
loss_sum = loss_sum + loss
# loss_list.append(loss) #每步添加一次
# 打乱数据顺序,防止按原次序假性训练输出
x_data, y_data = shuffle(x_data, y_data)
b0temp = b.eval(session=sess) # 训练中当前变量b值
w0temp = w.eval(session=sess) # 训练中当前权重w值
loss_average = loss_sum / len(y_data) # 当前训练中的平均损失
loss_list.append(loss_average) # 每轮添加一次
print("epoch=", epoch + 1, "loss=", loss_average, "b=", b0temp, "w=", w0temp)
Add_train_y.append(np.sqrt(mean_squared_error(y_data, sess.run(pred, feed_dict={x: x_data}))))
return loss_list, pred, Add_train_y, sess
def plot_all(loss_list, x_data, y_data, pred, Add_train_y, sess, x, y):
plt.plot(loss_list)
# 模型应用
n = np.random.randint(506) # 随机确定一条来看看效果
print(n)
x_test = x_data[n]
x_test = x_test.reshape(1, 13)
predict = sess.run(pred, feed_dict={x: x_test})
print("预测值:%f" % predict)
target = y_data[n]
print("标签值:%f" % target)
plt.show()
####### 曲线拟合效果,可以看出预测效果不错 #####
test_predictions = sess.run(pred, feed_dict={x: x_data})
plt.scatter(y_data, test_predictions)
plt.xlabel('True Values [1000$]')
plt.ylabel('Predictions [1000$]')
plt.axis('equal')
plt.xlim(plt.xlim())
plt.ylim(plt.ylim())
_ = plt.plot([-100, 100], [-100, 100])
plt.show()
########## ######### ##
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Abs Error [1000$]')
plt.plot(np.arange(50), Add_train_y,
label = 'MAE')
plt.legend()
plt.ylim([0, 10])
plt.show()
####### ##############
error = test_predictions - y_data
plt.hist(error, bins = 50)
plt.xlabel("Prediction Error [1000$]")
_ = plt.ylabel("Count")
plt.show()
def main():
df = get_data() # getdata
x_data, y_data = normal(df)
loss_function, optimizer, pred, x, y, b, w = model()
loss_list, pred, Add_train_y, sess = run_model(loss_function, optimizer, pred, x_data, y_data, x, y, b, w)
plot_all(loss_list, x_data, y_data, pred, Add_train_y, sess, x, y)
if __name__ == '__main__':
main()
结语
写的有点乱,大家凑活看
运行结果如下:
①利用Tensorboard查看神经网络结构图,如图所示可以看出是单层神经元的BP神经网络:

②观察随着训练轮数的变化,loss值的变化,分别用matplotlib和tensorboard展示


③利用matplotlib作图,展示神经网络预测拟合效果,可以看出还是不错的。

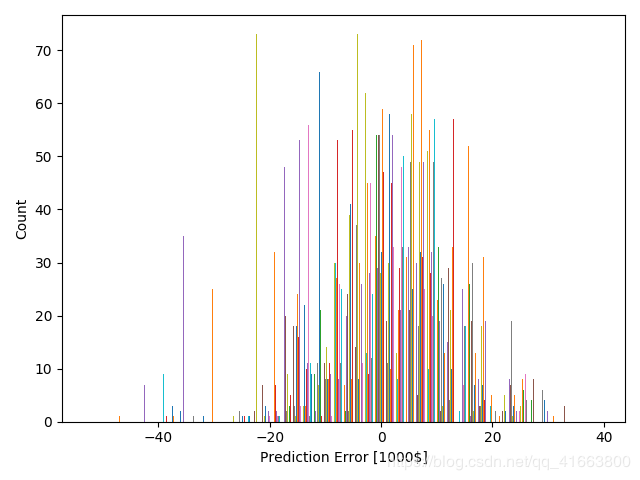
④利用matplotlib作图,查看预测失误情况的直方图,可以看出大部分预测还是准确的:
⑤利用matplotlib作图,展示平均绝对误差:MAE(Mean Absolute Error)的变化趋势,可以看出在几轮训练之后,趋于减小,最后近乎平稳。

⑥仿真测试,随机选取数据进行预测,并查看预测效果,可以看出预测效果中等偏上。
索引:375
预测值:15.012003
标签值:19.100000
402
预测值:12.718363
标签值:13.400000
10
预测值:30.206409
标签值:34.700000
239
预测值:31.967896
标签值:26.700000
51
预测值:18.368908
标签值:13.000000
120
预测值:12.289744
标签值:13.400000
参考致谢
https://blog.csdn.net/u012735708/article/details/84337262
https://blog.csdn.net/qq_36712111/article/details/87742822
https://blog.csdn.net/weixin_43737376/article/details/86718103