pandas简介及其数据结构Series详解
python高级应用与数据分析学习笔记 11
1、简介
1.1 介绍
Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
1.2 数据结构
Series:一种类似于一维数组的对象,是由一组数据(各种numpy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象,注意:Series中的索引值是可以重复的,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近,其区别是:List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。
Time- Series:以时间为索引的Series。
DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。也可以看成一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等) DataFrame既有行索引也有列索引,可以被看作是由Series组成的字典
Panel :三维的数组,可以理解为DataFrame的容器。
1.3 pandas 的三大作用
数据的引入
数据的特征提取
数据的清洗
1.4 查看以及安装步骤
先通过Anaconda Prompt 来查看是否安装了pandas
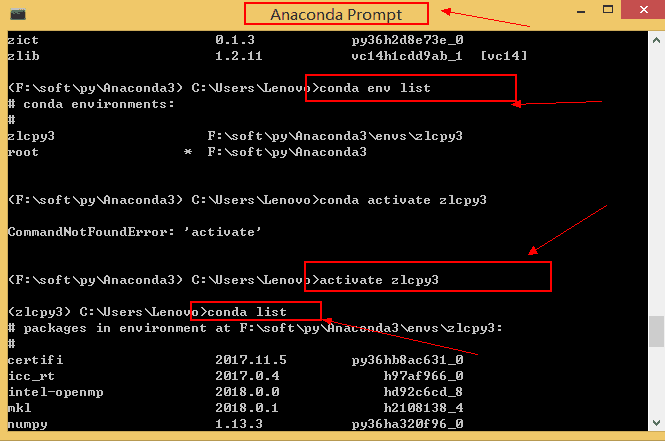
在安装列表里面可以看到已经安装pandas,如果没有安装就是用condas install pandas 或者 pip install pandas 命令来安装pandas
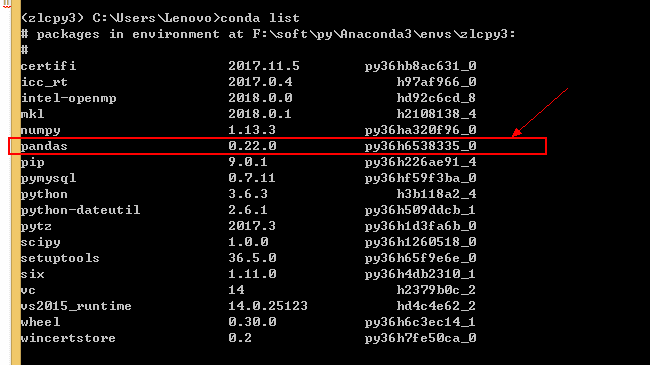
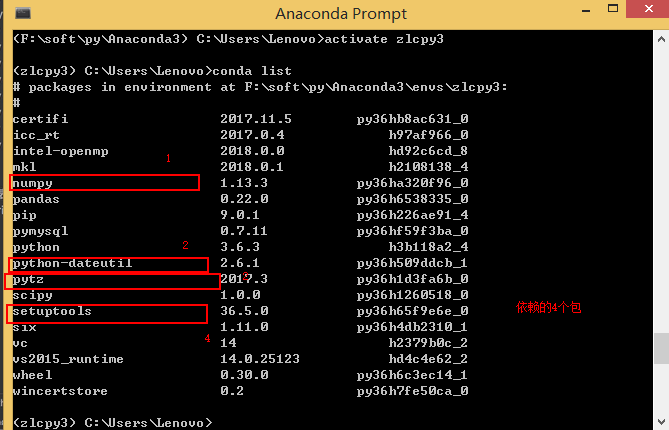
pandas依赖4个库:setuptools numpy python-dateutil pytz
1.5 有了numpy库为什么还会出现pandas库?
import numpy as np
import pandas as pd
# numpy创建的二维数组
arr = np.random.randint(0,10,(3,4))
print("numpy创建的二维数组===================")
print(arr)
# numpy创建的一维数组
arr = np.array([1,3,5,7,9])
print("numpy创建的一维数组===================")
print(arr,arr.dtype)
# pandas创建的一维数组
s0 = pd.Series(arr)
print("pandas创建的一维数组===================")
print(s0)

可以看出通过numpy创建的一维数组,二维数组等,比较难看懂每一个意思,而pandas创建的,可以很很形象看出每一个的意思,比较容易读懂。
2、Series创建的两种方式
2.1 通过一维数组创建
# 通过一维数组创建Series
# 通过numpy生成一维数组
arr = np.array([1,3,5,7,9])
s0 = pd.Series(arr)
print("通过numpy生成一维数组===================")
print(s0)
# 直接赋值一维数组
s0 = pd.Series(data=[80, 90, 100], dtype=np.float)
print("直接赋值一维数组,没给index的话就默认从0开始===================")
print(s0)
s0 = pd.Series(data=[80, 90, 100], index=['android', 'java', 'python'], dtype=np.float)
print("直接赋值一维数组,赋值index===================")
print(s0)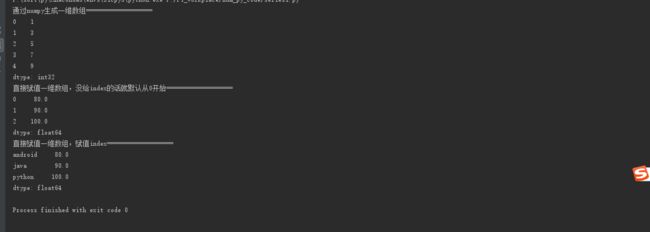
2.2 通过字典的方式创建
import numpy as np
import pandas as pd
dict0 = {'android': 80, 'java': 90, 'python': 100}
s0 = pd.Series(dict0, dtype=np.float)
print(s0)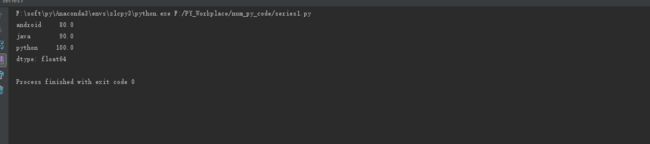
3、 Series属性的获取
3.1 dtype、index、values基本属性的获取
import numpy as np
import pandas as pd
dict0 = {'android': 80, 'java': 90, 'python': 100}
s0 = pd.Series(dict0, dtype=np.float)
print("s0===================")
print(s0)
print("s0.dtype===================")
print(s0.dtype)
print("s0.index===================")
print(s0.index)
print("s0.values===================")
print(s0.values)
print("更换series的index===================")
print("index个数一样的做法===================")
s0.index = [u'追梦', 'a2', 'a3'] #注意:index中的值可以重复,以这种方式更换index的值,个数必须与数组的个数一样
# s0.index = [u'追梦', 'a2', 'a3','a2'] #index与原数组不一样的话就会报:ValueError: Length mismatch: Expected axis has 3 elements, new values have 4 elements
print(s0)
print("index个数不一样的做法===================")
s0 = pd.Series(s0, index=['android', 'java', 'python','python'])
print(s0)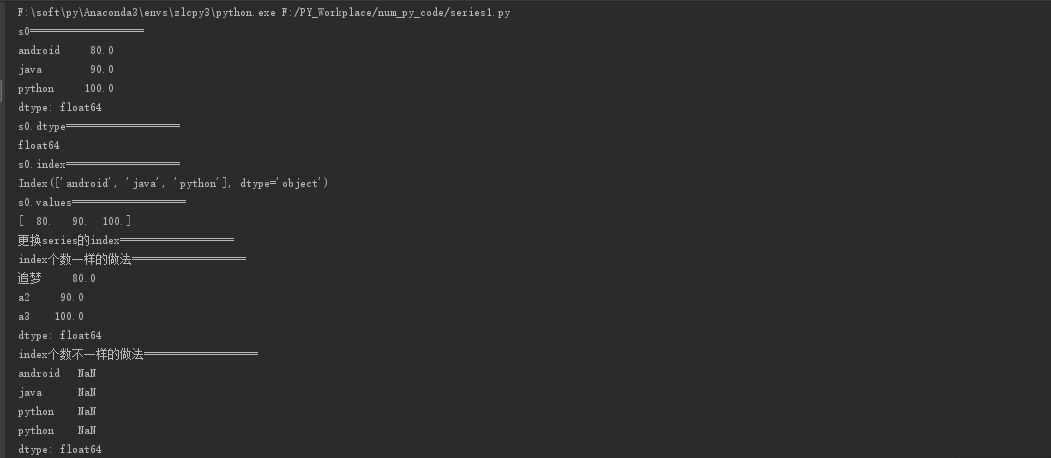
3.2 Series及其索引的name属性
import numpy as np
import pa
# name series对象 index也有name属性
s0 = pd.Series({'张伊曼': 100, '张诗诗': 88, '张巧玲': 99})
s0.name = '数学'
s0.index.name = '考试成绩'
print(s0)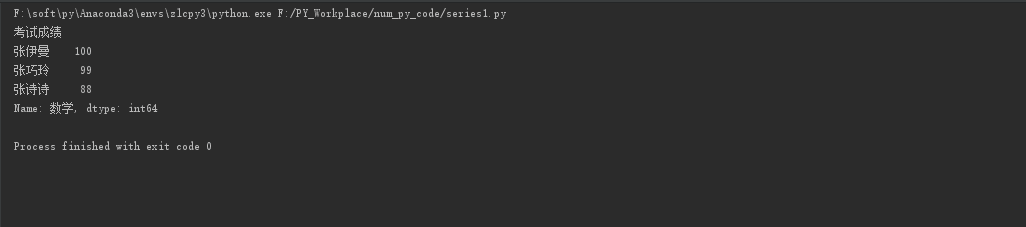
4、Series值的获取的两种方式
(1) 通过方括号+索引的方式获取对应索引的数据,可能返回多条数据
(2) 通过方括号+下标值的方式获取数据,下标值的取值范围为:[0, len(Series.values));另外下标值也可以是负数,表示从右往左获取数据
import numpy as np
import pa
dict0 = {'android': 80, 'java': 90, 'python': 100}
s0 = pd.Series(dict0, dtype=np.float)
print("s0===================")
print(s0)
print("s0['android':]===================")
print(s0['android':])
print("s0['android':'java']===================")
print(s0['android':'java']) #取值包头包尾
print("s0[0:]===================")
print(s0[0:])
print("s0[0:2]===================")
print(s0[0:2]) #取值包头不包尾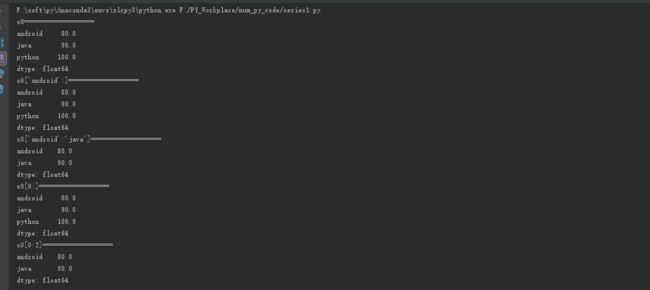
5、Series运算
# Series运算
dict0 = {'android': 80, 'java': 90, 'python': 100}
s0 = pd.Series(dict0, dtype=np.float)
print("s0===================")
print(s0)
arr0 = np.array([50, 80, 100])
print("s0===================")
print(arr0)
print("s0+arr0===================")
print(s0+arr0) #运算 + - * / 等都适合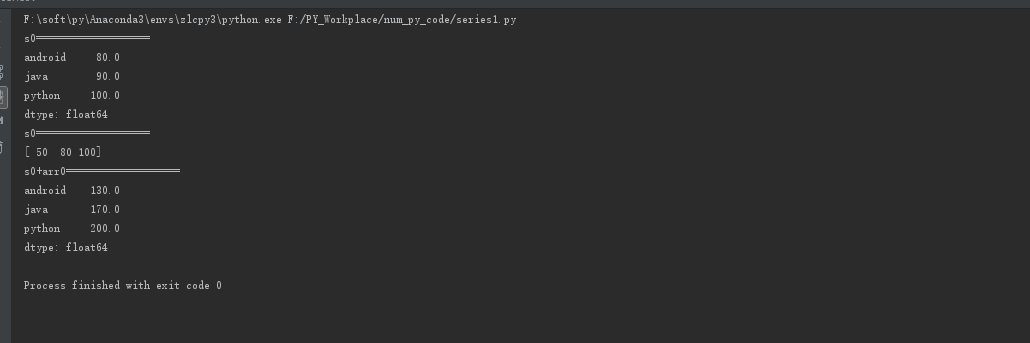
6、 自动对齐
# 自动对齐
s0 = pd.Series(data=[20, 30, 40], index=['s1', 's2', 's3'])
s1 = pd.Series(data=[60, 80, 100], index=['s3', 's4', 's2'])
print(s0+s1)
7、isnull 与 notnull
s0 = pd.Series({'android': 80, 'java': 90, 'python': 100})
s0 = pd.Series(s0, index=['android', 'java', 'python','c++'])
s0[pd.isnull(s0)] = 0
# s0[pd.notnull(s0)] = 0
print(s0)