TensorFlow Estimator 官方文档之----内置Estimator
Premade Estimators
本文档介绍了 TensorFlow 编程环境,并展示了怎么用 Premade Estimators 来解决 Iris 分类问题。
文章目录
- 1. TensorFlow 编程环境介绍
- 2. Iris 分类问题
- 1.1 Iris数据集简介
- 1.2 分类算法
- 1.3 进行预测
- 3. 使用 Estimator 编程实现 Iris 分类
- 3.1 创建 input 函数
- 3.2 定义 feature columns
- 3.3 实例化 estimator
- 3.4 训练、评估及预测
- 训练模型
- 评估经过训练的模型
- 使用经过训练的模型进行预测(inference)
- 总结
需要安装的包
在运行本文的代码之前,你需要安装以下包:
- 安装TensorFlow。
- 如果你是在virtualenv或Anaconda中安装的TensorFlow,请activate你的TensorFlow环境。
- 运行下面的代码安装、更新pandas包:
pip install pandas
获取本文的代码
通过以下步骤来获得本文的代码:
- 使用下面的命令将TensorFlow Model repository克隆到本地:
git clone https://github.com/tensorflow/models - 将目录切到本文使用的代码的位置:
cd models/samples/core/get_started/
本文使用的代码是 premade_estimator.py。该程序使用 iris_data.py 代码去fetch训练数据。
运行本文的代码
使用下面的方式来运行本文的代码。例如:
python premade_estimator.py
程序会在训练过程中输出训练日志,然后程序会输出在测试集上的测试结果。
...
Prediction is "Setosa" (99.6%), expected "Setosa"
Prediction is "Versicolor" (99.8%), expected "Versicolor"
Prediction is "Virginica" (97.9%), expected "Virginica"
如果程序运行的结果有误,请进行如下检查:
- TensorFlow安装有没有问题
- TensorFlow的版本是否正确
- 确定activate了安装TensorFlow的环境
1. TensorFlow 编程环境介绍
在使用 TensorFlow 编程之前,让我们首先研究下 TF 编程环境。如下图所示,TensorFlow 提供了一个包含多个 API 层的编程堆栈:
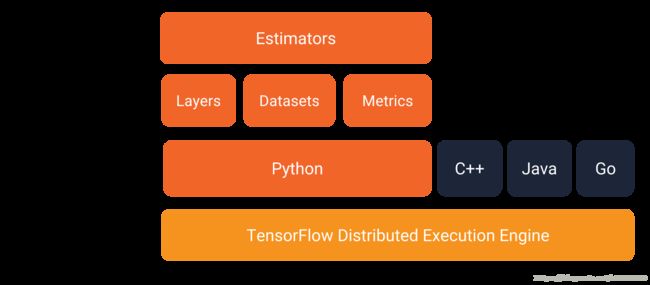
我们强烈推荐使用下列 API 编写 TF 程序:
- Estimators:代表一个完整的模型。Estimator API 提供一些方法来训练模型、评估模型性能并生成预测。
- Datasets:构建数据输入管道。Dataset API 提供了一些方法来加载数据(E),操作数据(T),并将数据馈送到您的模型中(L)。Dataset API 与 Estimator API 完美兼容。注:构建数据输入管道的过程其实就是构建 ETL 的过程。
2. Iris 分类问题
Iris数据集包含了3种鸢尾花、150个样本,每个样本包含鸢尾花的四个特征值:花蕊长度(cm)、花蕊宽度(cm)、花瓣长度(cm)、花瓣宽度(cm)。

1.1 Iris数据集简介
Iris 数据集包含4个特征和1个标签。4个特征分别为:
- 花蕊长度(sepal length)
- 花蕊宽度(sepal width)
- 花瓣长度(petal length)
- 花瓣宽度(petal width)
标签表明了 Iris 的品种,共有三个品种:
- Iris setosa (0)
- Iris versicolor (1)
- Iris virginica (2)
下面的表是数据集的一个片段:
| 花蕊长度(cm) | 花蕊宽度(cm) | 花瓣长度(cm) | 花瓣宽度(cm) | 品种(标签) |
|---|---|---|---|---|
| 5.1 | 3.3 | 1.7 | 0.5 | 0 (setosa) |
| 5.0 | 2.3 | 3.3 | 1.0 | 1 (versicolor) |
| 6.4 | 2.8 | 5.6 | 2.2 | 2 (virginica) |
1.2 分类算法
本文档使用一个 DNN 来实现对 Iris 的分类,该分类器的概况如下:
- 2 个隐藏层
- 每一个隐藏层包含 10 个节点
特征、隐藏层、预测值的概况如下图所示:

1.3 进行预测
训练好模型之后,我们便可以使用训练好的模型来预测标签未知的鸢尾花的品种。例如,预测结果的格式如下所示:
- 0.03 for Iris Setosa
- 0.95 for Iris Versicolor
- 0.02 for Iris Virginica
3. 使用 Estimator 编程实现 Iris 分类
Estimator 是 TensorFlow 中的高阶 API。它会处理 initialization、logging、saving、restoring 等细节,以便研究人员专注于模型。
Estimator API 中有不少的内置 Estimator。当然,除了这些内置 Estimator,你可以自定义 Estimator。推荐在解决问题时将内置 Estimator 作为一个 baseline。
使用内置 Estimator 解决问题时,一般遵循以下流程:
- 创建一个或多个输入函数。
- 定义模型的 feature columns。
- 实例化 Estimator,指定 feature columns 和各种超参数。
- 调用 Estimator 对象的一个或多个方法,传递合适的输入函数作为数据源。
下面详细介绍下怎么用内置 Estimator 来解决 Iris 分类问题。
3.1 创建 input 函数
首先创建输入函数来为训练、评估、预测过程提供数据。
输入函数的返回值为 tf.data.Dataset 对象,其输出一个两元素的元组:
features- Python 字典,其中:- 每个键都是特征的名称。
- 每个值都是包含此特征所有值的数组。
label- 包含每个样本的标签值的数组。
为了向您展示输入函数的格式,请查看下面这个简单的实现:
def input_evaluation_set():
features = {'SepalLength': np.array([6.4, 5.0]),
'SepalWidth': np.array([2.8, 2.3]),
'PetalLength': np.array([5.6, 3.3]),
'PetalWidth': np.array([2.2, 1.0])}
labels = np.array([2, 1])
return features, labels
输入函数可以以您需要的任何方式生成 features 字典和 label 列表。但是,我们推荐使用 TensorFlow 的 Dataset API,它可以解析各种数据。作为一个高阶 API,Dataset API 包含以下类:

各个类如下所示:
Dataset:创建、变换数据集的方法 的基类。您还可以通过该类从 内存中的数据 或 Python 生成器 初始化数据集。TextLineDataset:从文本文件读取行。TFRecordDataset:从 TFRecord 文件读取 records。FixedLengthRecordDataset:从二进制文件读取固定大小的 records。Iterator: 提供一次访问一个数据集元素的方法。
为了简化此示例,我们采用 pandas 来从 csv 文件加载数据到内存,然后从内存中构建数据输入管道。
以下是本文的示例在训练过程中使用的输入函数。详见 iris_data.py
def train_input_fn(features, labels, batch_size):
"""An input function for training"""
# Convert the inputs to a Dataset.
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels)) # 这里的 features 是一个pandas DataFrame,labels 是一个 pandas Series
# Shuffle, repeat, and batch the examples.
return dataset.shuffle(1000).repeat().batch(batch_size)
3.2 定义 feature columns
feature column 是一个对象,用于说明模型应该如何使用特征字典中的原始输入数据。在构建 Estimator 模型时,您会向其传递一个特征列的列表,其中包含您希望模型使用的每个特征。tf.feature_column 模块提供很多用于向模型表示数据的选项。
对于 Iris,4个原始的特征是数值,所以我们将构建一个 feature column 列表,以告知 Estimator 模型将这 4 个特征都表示为 32 位浮点值。因此,创建 feature column 的代码如下:
# Feature columns describe how to use the input.
my_feature_columns = []
for key in train_x.keys():
my_feature_columns.append(tf.feature_column.numeric_column(key=key))
Feature columns 的功能远超上面的示例。我们将在后面有详细的介绍。
我们已经介绍了希望模型如何表示原始特征,现在可以构建 Estimator 了。
3.3 实例化 estimator
Iris 分类问题是一个经典的分类问题。TensorFlow中内置了很多分类 Estimators,包括:
tf.estimator.DNNClassifiertf.estimator.DNNLinearCombinedClassifiertf.estimator.LinearClassifier
对于Iris问题,tf.estimator.DNNClassifier 似乎是最好的选择。
# Build a DNN with 2 hidden layers and 10 nodes in each hidden layer.
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
# Two hidden layers of 10 nodes each.
hidden_units=[10, 10],
# The model must choose between 3 classes.
n_classes=3)
3.4 训练、评估及预测
我们已经有一个 Estimator 对象,现在可以调用方法来执行下列操作:
- 训练模型
- 评估经过训练的模型
- 使用经过训练的模型进行预测
训练模型
通过调用 Estimator 的 train 方法来训练模型:
# 训练模型
classifier.train(
input_fn=lambda:iris_data.train_input_fn(train_x, train_y, args.batch_size),
steps=args.train_steps)
在上面,我们使用 lambda 来对 input_fn 函数进行了包装。steps 参数用来告诉 train 方法在指定的 training steps 后停止训练。
评估经过训练的模型
模型已经过训练,现在我们可以对模型性能进行一些统计。
# 评估模型
eval_result = classifier.evaluate(
input_fn=lambda:iris_data.eval_input_fn(test_x, test_y, args.batch_size))
print('\nTest set accuracy: {accuracy:0.3f}\n'.format(**eval_result))
与 train 方法的调用不同,我们没有给 evaluate 传递 steps 参数。因为我们的 eval_input_fn 只生成一个 epoch 的数据。
运行上面的代码,可以得到下面的结果:
Test set accuracy: 0.967
eval_result 字典也包含了 average_loss(mean loss per sample)、loss(mean loss per mini-batch)和 estimator 的 global_step (the number of training iterations it underwent)。
使用经过训练的模型进行预测(inference)
我们已经有一个经过训练的模型(在测试集有比较好的效果)。我们现在可以使用训练好的模型去预测 Iris 花的品种。与训练、评估类似,我们通过调用 predict 方法来进行预测:
# 使用训练好的模型产生预测
expected = ['Setosa', 'Versicolor', 'Virginica']
predict_x = {
'SepalLength': [5.1, 5.9, 6.9],
'SepalWidth': [3.3, 3.0, 3.1],
'PetalLength': [1.7, 4.2, 5.4],
'PetalWidth': [0.5, 1.5, 2.1],
}
predictions = classifier.predict(
input_fn=lambda:iris_data.eval_input_fn(predict_x,
batch_size=args.batch_size))
predict 方法返回一个Python迭代器,给每一个 example 生成一个预测结果字典。
template = ('\nPrediction is "{}" ({:.1f}%), expected "{}"')
for pred_dict, expec in zip(predictions, expected):
class_id = pred_dict['class_ids'][0]
probability = pred_dict['probabilities'][class_id]
print(template.format(iris_data.SPECIES[class_id],
100 * probability, expec))
运行上面的代码,产生下面的结果:
...
Prediction is "Setosa" (99.6%), expected "Setosa"
Prediction is "Versicolor" (99.8%), expected "Versicolor"
Prediction is "Virginica" (97.9%), expected "Virginica"
总结
使用内置 Estimator 可以快速创建出一个基础模型。
关于 Estimator,我们推荐以下阅读资料:
- Checkpoints:了解如何保存和恢复模型。
- Datasets:了解如何将数据导入模型中。
- Creating Custom Estimators:了解如何针对特定问题,编写自定义 Estimator。